GMOクラウド ALTUSにフラッシュディスクが追加されていました(2018年8月29日追記)
少し前からですが、GMOクラウドのディスクでフラッシュディスク(SSD)が選択できるようになっていました。
この記事を書いたとき(2015年)の状況は再現できないですが、恐らくディスクアクセスに関する悩みからは開放されそうですね。
はじめに
これまでの経緯はこちらにあります。
マルチコアサーバがなんか重い時に原因究明しかけていました。
管理に携わっているサーバが「なんか重い」症状に陥った件についての解決編です。
- LAがちょくちょくあがって問題認識
- 対象サーバはマルチコアでコア別に見ると特定のコアで普段からiowaitが高い
- ddやfioなどでディスク負荷を掛けるとめっちゃ重い
という状態でした。
調査
サポセンからの連絡
GMOのクラウドを使っていますがここサポートセンターは優しいです。ddとfioの結果を以て質問したところ返答がありました。
要約して引用すると
- ストレージ側の負荷を緩和するための設定を加えた。
- fioやDDの値はストレージの負荷などの環境のみが影響しているとは考えにくい
- iotopコマンドや
pidstat -dなどはどうか
ということでした。何らかの設定を施してもらったようです。
fioやddが重いのはディスクに引っ張られたということではないとのことでした。
またiotopやpidstatというコマンドを紹介してもらいました。結果的にこれが非常に助かりました。
dstat
iotopは入っていなかったのでdstatにて代用しました。
dstatに--top-io --top-bioを付けることでioの激しいプロセスを見る事ができるようです。
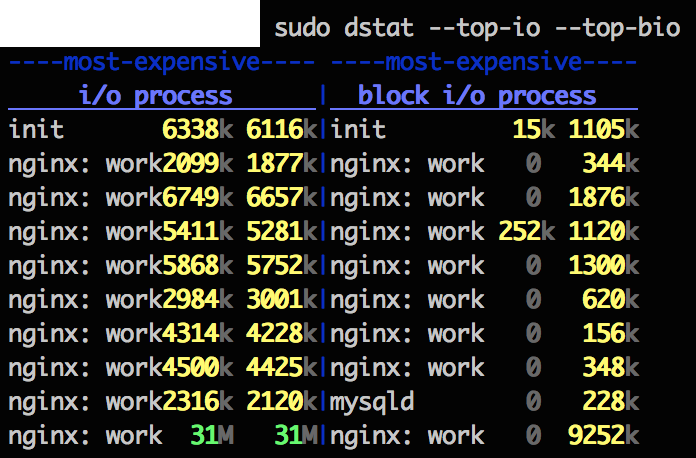
こちらで見たところほぼnginxがIOを持って行っていました。
(経験上mysqlのI/Oで詰まることが多かったので意外でした。ただし数日前にmysqlのメモリ割り当てを増やしたのでそれによってIOが緩衝されていたのかもしれません。)
pidstat
nginxプロセスが重そうだったのでpidstatを利用して調べてみました。
shell> pidstat -d | head -3; sudo pidstat -d | grep nginx
Linux 2.6.32 (example) 10/22/2015 _x86_64_ (12 CPU)
01:42:02 PM PID kB_rd/s kB_wr/s kB_ccwr/s Command
01:42:02 PM 1966 0.03 0.00 0.00 nginx
01:42:02 PM 1967 2.56 212.14 5.02 nginx
01:42:02 PM 1968 2.36 209.00 5.00 nginx
01:42:02 PM 1970 2.45 214.96 4.93 nginx
01:42:02 PM 1971 2.44 211.16 5.06 nginx
01:42:02 PM 1972 2.27 209.88 4.68 nginx
01:42:02 PM 1973 2.39 211.16 5.32 nginx
01:42:02 PM 1975 2.36 214.67 6.83 nginx
01:42:02 PM 1976 2.41 213.86 4.53 nginx
01:42:02 PM 1977 0.00 0.00 687.19 nginx
確かに10個あるプロセスのうち9個は結構頻繁にディスクアクセスを起こしているようです。
ディスクアクセスが無いプロセスはPIDが最も若いことから親プロセスのようです。
平均するとnginx全体では2MB/sぐらいの書き込みがあるようです。
kB_ccwr/sの目立つプロセスがありますが、これについては「キャンセルされた書き込み」のようです。ダーティページキャッシュの発生が疑われる、ようですね。
Number of kilobytes whose writing to disk has been cancelled by the task. This may occur when the task truncates some dirty pagecache. In this case, some IO which another task has been accounted for will not be happening.
http://sebastien.godard.pagesperso-orange.fr/man_pidstat.html
PIDが分かったので累積情報も見てみます。Linuxは/procが便利ですね。UNIX系ではデフォルトでは無い気がします。
shell> cat /proc/1967/io
rchar: 614816861415
wchar: 596872806957
syscr: 27363750
syscw: 24706330
read_bytes: 1311608832
write_bytes: 108693970944
cancelled_write_bytes: 2570178560
とのことで、書き込みが108GBとあります。システムのuptimeとプロセスのuptimeが一緒で5日ほどですので、一日あたり20GBほど書いているようです。
20GB / 24hour / 3600sec = 0.2MB/s
となり先ほどのpid値と一致しますね。
10プロセスで計算するとやはり2MB/sの書き込みを起こしているようです。
iotop
今回はiotopは使いませんでした。
解決編
というわけで問題は「nginxの書き込みが遅い」という目星をつけました。
ここを改善します。
nginxの書き込み
基本的にはHTTPリクエストが来たらディスクから内容を読みだして出力か、PHPなどのバックエンドに投げてレスポンスを返します。この動作では書き込み動作は発生しません。
となると書き込みを起こしている原因は通常の処理ではないと考え、頻繁に書き込みを行っているであろうnginxのキャッシュであると検討をつけました。
今回のサーバではnginxのリバースプロキシとキャッシュを利用していました。
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=czone:4m max_size=50m inactive=120m;
ここを原因と仮定して対策を打つことにしました。
ramディスク
今回はキャッシュにramディスクを利用する事で解決する事にしました。
現在利用されているディレクトリは500MBぐらいでしたのでramディスクに十分載るサイズです。
mysqlから少しメモリを分けてもらって1GBほどのramディスクを作成しました。
他のサイトを参考にしながらramディスクを作成し書き込み試験を行いました。
shell> sudo mount -t tmpfs -o size=1200m tmpfs /mnt/nginxcache
shell> dd if=/dev/zero of=/mnt/nginxcache/hoge bs=1MB count=1000
1000+0 records in
1000+0 records out
1000000000 bytes (1.0 GB) copied, 0.622355 s, 1.6 GB/s
書き込み速度が1.6GB/sという値が出ました。めっちゃ早いですね。
再起動しても大丈夫なようにfstabに書いておきます。
tmpfs /mnt/nginxcache tmpfs size=1000m 0 0
今回は実稼働のサーバでしたので再起動試験を行わないということになりました。
fstabで引っかかると再起動で止まるかramディスクが作成されないか、となります。
念のためディスク自身にディレクトリを作っておきnginxがキャッシュディレクトリが無い、といって起動しない事を避けれるようにしておきます。
shell> sudo mkdir /mnt/nginxcache
ここまで来たらnginxのキャッシュを先ほど作成したramディスクに設定し直して再起動します。
proxy_cache_path /mnt/nginxcache levels=1:2 keys_zone=czone:4m max_size=50m inactive=120m;
shell> sudo service nginx restart
結果
結果、LAが3~20とバラつきがあってさまよってた症状はかなり改善されました。
現在ではLAは0.5~5となっています。
top, vmstat, sarだけでは今回の解決は出来なかったです。
マルチコアではコア別に状態を見てあげないとダメなんだな、と思いました。
pidstatやsar -P ALLを使えなかったことは反省ですが、今後は積極的に見ていきます。
感想など
今回の件はディスクアクセスに絞って書きましたが、この以前にも施策は打っていました。
特に当初はMySQLの性能限界で頭打ちになっていたので、クエリの見直しを行い削減していました。
こちらも一定の効果があったので安心していたのですが、今回のramディスクの割り当てを通じて振り返ってみるとMySQL自体もIOが詰まっていたのではないかと思っています。
最近(2015年)のHDDはとても高速で、シーケンシャルでは50MB/sから、良い物では200MB/sぐらい出ます。
(5万円とかの物理サーバしか作ってないですけど100万とかならたぶんもっと出ますよね)
ちゃんと実測値を計らないとダメだと思いました。
特にクラウドやVPSでは物理HDDとは違った値が出るようです。小さいファイルではVPSやクラウドのミドルウェア(?)によってメモリに載ってしまうと思うので色々と疑っていった方が良いですね。
必要なディスクサイズとの相談になりますがramディスクはかなり良い解決になりました。
数年前にmysqlをramディスクに載せた経験が生きたと思います。
また今回はtopなどのiowaitn値が高い所からスタートしてその解決の為にramディスクを利用しました。
今回はこれで解決しましたが、併せてnginxのキャッシュ設定のチューニングなども行うと効果は高いですね。
参考
http://qiita.com/yuku_t/items/2f5341e4aa635800a0a1
http://higherhope.net/?p=1267
http://lequinharay-development.tumblr.com/post/53420425901/iotopコマンドでディスクioの激しいプロセスを特定する-osx編
IO Accounting 機能で I/O 負荷の高いプロセスを特定
http://www.drk7.jp/MT/archives/001784.html
https://wiki.centos.org/TipsAndTricks/TmpOnTmpfs