はじめに
「サーバがなんか思い」ということで調査しました。
解決には至っていませんのでまだ道半ばです。
こちらの記事が日々非常に参考になっています。
http://qiita.com/yuku_t/items/2f5341e4aa635800a0a1
サーバ構成
サーバはGMOクラウドのALTUS
https://www.gmocloud.com/isolate/
後発型、日本製ということもあってかコンパネがすごく便利。
担当者も親切に対応してくれるしなかなか良いサーバ。
- 12コア メモリは16G
- 目的はウェブサーバ(nginx + php-fpm + mysql)
- OSはCentOS
なんか重い
このサーバはウェブサーバなのでページを表示させているんだけど、とにかく「なんか重い」。
夜はアクセスが多かったり昼は空いていたりするけど、時間にかかわらず「なんか重い」。
キャッシュを使ったりもしてるけど、いきなりふっと「なんか重い」。
うーんこれはMySQLか…、と思いながら調査を始めました。
LAがあがる
「なんか思い」現象が始まってからデータを取るためにmuninを導入していました。
またtopの画面を見ていたところ定期的にLAがあがっていました。

- LA8ぐらいでなんか重い
- 1ぐらいの時もあれば8ぐらいの時もあって、重い時は15ぐらいまであがっちゃう
- 「夜は毎晩20を超える」とか「ウェブサイトの記事が公開されたら跳ね上がる」とかじゃなくてtopみてると急に上がったり下がったりする
- 現在のサーバはコア数が12なので12以下なら大丈夫なはずなんだけど、12を超えなくても重い時は重い。
そういう情況でした。
「LAはCPUのコア数まで大丈夫」なんていうんだけれど経験的にそうではない変な感じでした。
(ちなみにチューニング不足、スペック不足のサーバではLA500とか行ってました。IO刺さっててもそんなんなりました)
LAについて
LAについてしらべていると naoyaさんの良い記事が出てきました。
負荷が全く均一になっていません。Linux カーネルは、L2 キャッシュやスレッドローカルバッファの効率を高めるために同じプロセスは同じ CPU にタスクを割り当てつつ、全体としては負荷が均等になるように極力がんばるというのがスケジューラの原則のようですが、あまり均等にはなっていないようです。
マルチコア時代のロードアベレージの見方
http://d.hatena.ne.jp/naoya/20070518/1179492085
ということで負荷が均一になっていないかどうかについて調べてみました。
記事を参考にしてCPUごとのsarを見てみます。
shell> sar -P ALL | less
Linux 2.6.32-431(example) 10/21/2015 _x86_64_ (12 CPU)
12:00:01 AM CPU %user %nice %system %iowait %steal %idle
12:10:01 AM all 1.94 0.00 1.06 6.92 0.05 90.03
12:10:01 AM 0 3.75 0.00 4.52 69.81 0.53 21.39
12:10:01 AM 1 1.96 0.00 0.79 0.92 0.01 96.33
12:10:01 AM 2 1.86 0.00 1.00 1.00 0.01 96.14
12:10:01 AM 3 2.73 0.00 1.10 1.29 0.01 94.87
12:10:01 AM 4 1.49 0.00 0.60 2.30 0.01 95.61
12:10:01 AM 5 1.76 0.00 0.69 1.29 0.01 96.26
12:10:01 AM 6 1.88 0.00 0.81 0.99 0.01 96.31
12:10:01 AM 7 2.20 0.00 0.90 3.96 0.01 92.94
12:10:01 AM 8 1.15 0.00 0.45 1.23 0.00 97.17
12:10:01 AM 9 1.79 0.00 0.82 0.60 0.01 96.78
12:10:01 AM 10 0.87 0.00 0.36 0.11 0.00 98.66
12:10:01 AM 11 1.93 0.00 0.77 0.64 0.01 96.66
CPU0だけiowaitが異様に高いですね。
shell> sar -P 0 | less
Linux 2.6.32-431(example) 10/21/2015 _x86_64_ (12 CPU)
12:00:01 AM CPU %user %nice %system %iowait %steal %idle
12:10:01 AM 0 3.75 0.00 4.52 69.81 0.53 21.39
12:20:01 AM 0 4.46 0.00 4.16 62.54 0.49 28.35
12:30:17 AM 0 2.56 0.00 2.55 66.30 0.45 28.14
12:40:01 AM 0 3.39 0.00 4.06 71.56 0.53 20.45
12:50:05 AM 0 3.33 0.00 3.99 68.55 0.50 23.63
01:00:18 AM 0 4.24 0.00 4.56 61.22 0.53 29.46
01:10:01 AM 0 3.38 0.00 4.66 61.14 0.59 30.24
やはりiowaitがめっちゃ高いですね。
CPU12個の平均だとiowaitは6.92%とかなんですが、個別に見ると非常に高い値を示しています。
top
topではリアルタイムに現在の状態を見ることができます。
namikawaさんの良い記事がありました。
topコマンドでマルチコアなCPUの状況を確認する
http://d.hatena.ne.jp/rx7/20080802/p3
topで1を押すとコアごとの状態を見ることが出来ます。実際に見てみました。
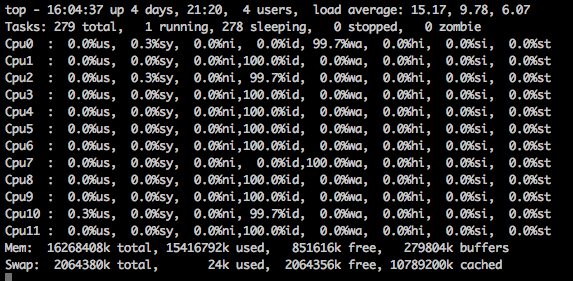
特定のCPUコアでiowaitが重くなっていますね。通常状態なのですがこれはI/Oが詰まっているように見えます。
IO負荷試験
dd
伝統的(?)なddでの負荷試験を行いました。
shell> dd of=hoge if=/dev/zero bs=1M count=10
10+0 records in
10+0 records out
10485760 bytes (10 MB) copied, 0.0119063 s, 881 MB/s
shell> dd of=hoge if=/dev/zero bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 3.69445 s, 28.4 MB/s
shell> dd of=hoge if=/dev/zero bs=1MB count=1000
Write failed: Broken pipe
100MBまではフツーに出来てたのですが1GBをやったところsshごと切れました。
fio
こちらを参考に試験しました。
ランダムリード、ランダムライトを1GBぐらいやったのですが 4IOPS という結果でした。
対策
とりあえずサポートの方に今回の結果を基に問い合わせを行いました。
私見ではIOに負荷を掛けすぎるとダメなのかな、と思っています。
今のところ連絡待ちです。
解決したら記事を補記します。
まとめ
というわけで「サーバがなんか重い」のでsarやvmstatやiostatをしていたのですがそれだけでは解決しませんでした。
マルチコアの場合にはもう一歩必要なようでした。
「topの1」「sar -P ALL」を使うとどこかのプロセスが詰まっているのも見抜くことができます。