Textheroというpythonライブラリを使って、テキストデータのワードクラウドや主成分分析によるデータの散布図を表示してみる
自分でまとめたもの → https://github.com/youichiro/texthero-sample
準備
プロジェクトディレクトリを作成する
$ mkdir texthero-sample
$ cd texthero-sample
必要なライブラリをインストールする
$ pip install texthero
mecabを使えるようにする
$ pip install mecab-python3 ipadic
ワードクラウドを表示するときに日本語が文字化けしたので、日本語フォントをダウンロードする
$ mkdir fonts
$ cd fonts
$ wget https://noto-website-2.storage.googleapis.com/pkgs/NotoSansCJKjp-hinted.zip
$ unzip NotoSansCJKjp-hinted.zip -d NotoSansCJKJP
$ cd ..
ストップワードを用意する
調べたらよく出てきたストップワードリストをダウンロードする
$ mkdir dicts
$ cd dicts
$ wget http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt -O stopwords.txt
$ cd ..
試す用にlivedoorニュースコーパスを取得する
ダウンロードするためのpythonスクリプトがあったのでそれを使う
$ wget https://gist.githubusercontent.com/nxdataka/48a27b2e1c3f029e7f25e66dba4b6dde/raw/75b56c34869c6b290cdb54a0925f34baeace021a/ldn2csv.py
$ python ldn2csv.py -o data/livedoornews.csv
前処理
import texthero as hero
import pandas as pd
import MeCab
import ipadic
# DataFrameの用意
df = pd.read_csv('data/livedoornews.csv')
df.rename(columns={'body': 'text'}, inplace=True)
df.rename(columns={'media': 'topic'}, inplace=True)
df.dropna(how='any', inplace=True)
df = df[['topic', 'text']]
# ストップワードを用意する
stopwords = pd.read_csv('dicts/stopwords.txt', squeeze=True)
stopwords = stopwords.values.tolist()
# mecabで形態素解析し、指定した品詞の単語のみ抽出した分かち書きを行う関数を用意する
tagger = MeCab.Tagger(ipadic.MECAB_ARGS)
pos_list = ['名詞', '動詞', '形容詞']
def wakati(text):
node = tagger.parseToNode(text)
words = []
while node:
pos = node.feature.split(',')[0]
surface = node.surface
if pos in pos_list and surface not in stopwords:
words.append(surface)
node = node.next
return ' '.join(words)
# 分かち書きを行う
df['wakati_text'] = df['text'].apply(lambda x: wakati(x))
# 前処理を行う
df['wakati_text'] = hero.clean(df['wakati_text'], pipeline=[
hero.preprocessing.remove_digits, # 数字を削除
hero.preprocessing.remove_whitespace, # 余計な空白を削除
])
ワードクラウドを表示する
映画に関する記事のワードクラウド
movie_text = df[df['topic'] == 'movie-enter']]['wakati_text']
hero.visualization.wordcloud(movie_text, font_path='fonts/NotoSansCJKJP/NotoSansCJKjp-Regular.otf', colormap='viridis', width=500, height=400, background_color='White')

スマホに関する記事のワードクラウド
movie_text = df[df['topic'] == 'smax']]['wakati_text']
hero.visualization.wordcloud(movie_text, font_path='fonts/NotoSansCJKJP/NotoSansCJKjp-Regular.otf', colormap='viridis', width=500, height=400, background_color='White')

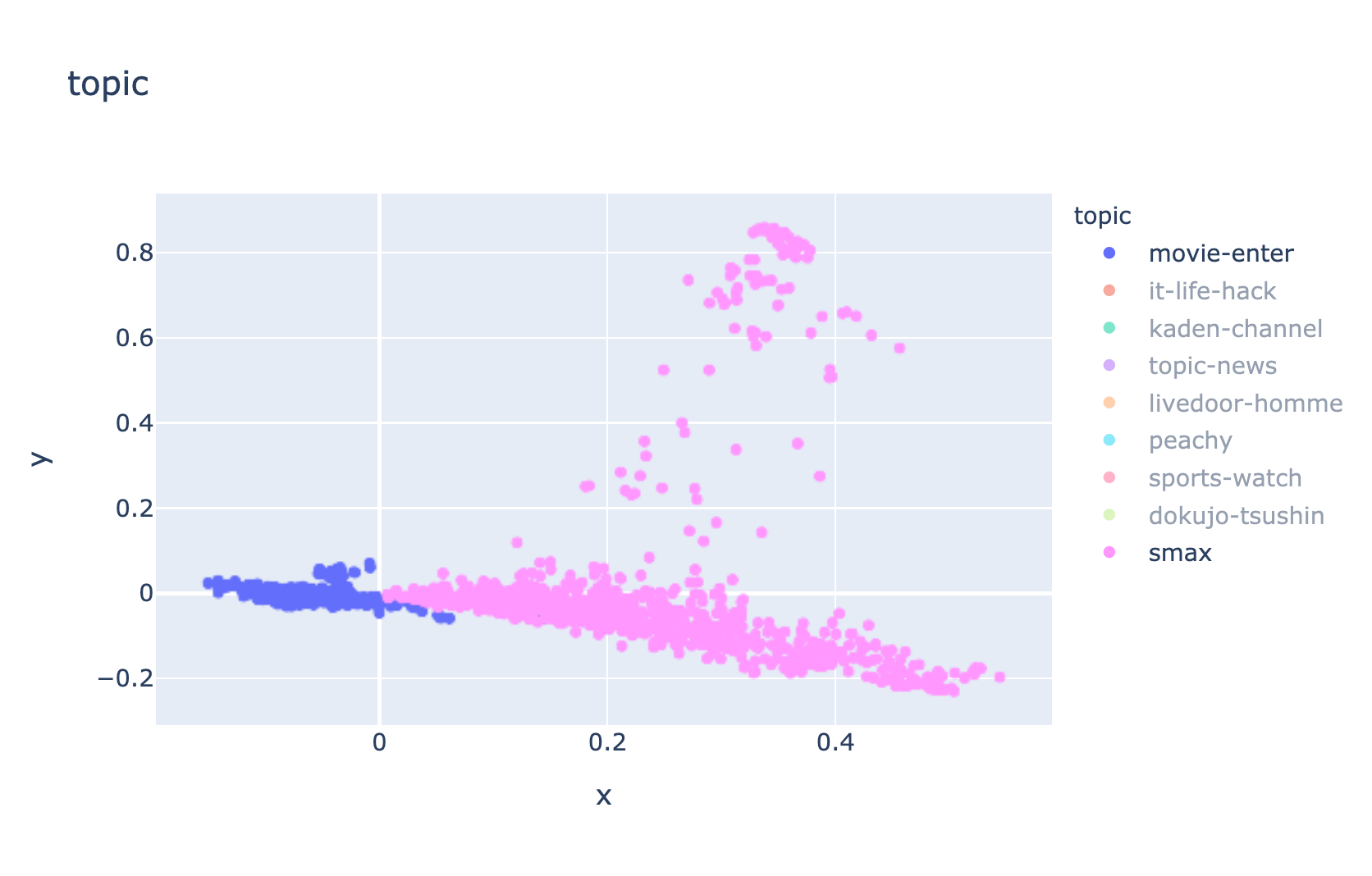
主成分分析(PCA)による散布図を表示する
df['pca'] = df['wakati_text'].pipe(hero.tfidf).pipe(hero.pca)
hero.scatterplot(df, 'pca', color='topic', title='topic')