はじめに
最近異常検知に関する勉強をしておりますが、奥が深くて理解がスムーズに進みません。
気分転換も兼ねて、2021年12月現在、それなりの精度を誇るSPADEの異常検知手法で間違い探しを攻略することにします。ここではサイゼリヤのキッズメニューにある大人でも難しいといわれる「間違い探し」を題材にします。
環境
- windows10 home
- python 3.10
結論
最終的な推論結果は以下のようになりました。

Questionはサイゼリヤのホームページで公開されている間違い探しの題材であり、Anomaly overlay mapは異常度におけるヒートマップを重ねた画像になります。完璧ではありませんが、間違いの個所(すなわち異常と思われる部分)が濃い赤で塗られていますね。
異常検知手法
ここ数年はAIモデルの再学習を必要としない手法が強いです。詳しくは以下の記事をご参照ください。
サイゼリヤの間違い探しを攻略するため、ここではSPADE手法を選択しました。以下、SPADEの特徴解説の抜粋です。
- 「画素」単位の異常検知 → 異常個所の表示
- ImageNetで訓練したResNetを利用する(再訓練なし)
- 正常な画像yyの各画素ppを変換した特徴量F(y,p)F(y,p)を保持する
- 推論では入力した画像の画素の特徴量ffとF(y,p)F(y,p)のk-Nearest Neighbor distanceで判定
- 解像度と深い特徴抽出を両立するために、feature pyramidの各層をconcatする

データの準備
サイゼリヤのホームページを開きます。間違い探しの問題の中で、2021年9月の最新版(創業当時のサイゼリヤの1号店)をスクショし使用します。
画像の左側(A)を特徴量抽出用として、右側(B)を検証用とします。
特徴量抽出用の画像は3枚程度コピーして、ファイル名を変えて(img0.PNG, img1.PNG, img2.PNGなど適当に)保存しておきます。

.
├── img0.PNG # 特徴量抽出用
├── img1.PNG
├── img2.PNG
└── img_val.PNG # 検証用
リポジトリのClone
SPADE含め、PaDim, PatchCoreという別の手法もまとめて実装しているリポジトリがあります。ありがたく使わせていただきます。
git clone https://github.com/h1day/ind_knn_ad.git
cd ind_knn_ad
そのままでは動かなかったのでコードの一部を変更しました。長いので折りたたんでます。
requirements.txt
streamlit==0.86.0
wget==3.2
matplotlib==3.3.4
timm==0.4.12
click==7.1.2
torch==1.9.0
tqdm==4.61.2
numpy==1.19.5
torchvision==0.10.0
# faiss
Pillow==8.3.1
PyYAML==5.4.1
scikit_learn==0.24.2
data.py
import os
from os.path import isdir
import tarfile
import wget
from pathlib import Path
from PIL import Image
from torch import tensor
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
DATASETS_PATH = Path("./datasets")
IMAGENET_MEAN = tensor([.485, .456, .406])
IMAGENET_STD = tensor([.229, .224, .225])
# def mvtec_classes():
# return [
# "bottle",
# "cable",
# "capsule",
# "carpet",
# "grid",
# "hazelnut",
# "leather",
# "metal_nut",
# "pill",
# "screw",
# "tile",
# "toothbrush",
# "transistor",
# "wood",
# "zipper",
# ]
def mvtec_classes():
return [
"bottle",
]
class MVTecDataset:
def __init__(self, cls : str, size : int = 224):
self.cls = cls
self.size = size
if cls in mvtec_classes():
self._download()
self.train_ds = MVTecTrainDataset(cls, size)
self.test_ds = MVTecTestDataset(cls, size)
def _download(self):
if not isdir(DATASETS_PATH / self.cls):
print(f" Could not find '{self.cls}' in '{DATASETS_PATH}/'. Downloading ... ")
url = f"ftp://guest:GU.205dldo@ftp.softronics.ch/mvtec_anomaly_detection/{self.cls}.tar.xz"
wget.download(url)
with tarfile.open(f"{self.cls}.tar.xz") as tar:
tar.extractall(DATASETS_PATH)
os.remove(f"{self.cls}.tar.xz")
print("") # force newline
else:
print(f" Found '{self.cls}' in '{DATASETS_PATH}/'\n")
def get_datasets(self):
return self.train_ds, self.test_ds
def get_dataloaders(self):
return DataLoader(self.train_ds), DataLoader(self.test_ds)
class MVTecTrainDataset(ImageFolder):
def __init__(self, cls : str, size : int):
super().__init__(
root=DATASETS_PATH / cls / "train",
transform=transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD),
])
)
self.cls = cls
self.size = size
class MVTecTestDataset(ImageFolder):
def __init__(self, cls : str, size : int):
super().__init__(
root=DATASETS_PATH / cls / "test",
transform=transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD),
]),
target_transform=transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.NEAREST
),
transforms.CenterCrop(size),
transforms.ToTensor(),
]),
)
self.cls = cls
self.size = size
def __getitem__(self, index):
path, _ = self.samples[index]
sample = self.loader(path)
if "good" in path:
target = Image.new('L', (self.size, self.size))
sample_class = 0
else:
target_path = path.replace("test", "ground_truth")
target_path = target_path.replace(".png", "_mask.png")
target = self.loader(target_path)
sample_class = 1
if self.transform is not None:
sample = self.transform(sample)
if self.target_transform is not None:
target = self.target_transform(target)
return sample, target[:1], sample_class
class StreamingDataset:
"""This dataset is made specifically for the streamlit app."""
def __init__(self, size: int = 256): # __init__(self, size: int = 224):
self.size = size
self.transform=transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_MEAN, IMAGENET_STD),
])
self.samples = []
def add_pil_image(self, image : Image):
image = image.convert('RGB')
self.samples.append(image)
def __len__(self):
return len(self.samples)
def __getitem__(self, index):
sample = self.samples[index]
return (self.transform(sample), tensor(0.))
streamlit_app.py
from contextlib import contextmanager
from io import StringIO
from streamlit.report_thread import REPORT_CONTEXT_ATTR_NAME
from threading import current_thread
import streamlit as st
import sys
from time import sleep
from PIL import Image
import io
import numpy as np
import cv2
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
sys.path.append('./indad')
from indad.data import MVTecDataset, StreamingDataset
from indad.models import SPADE, PaDiM, PatchCore
from indad.data import IMAGENET_MEAN, IMAGENET_STD
N_IMAGE_GALLERY = 4
N_PREDICTIONS = 2
METHODS = ["SPADE", "PaDiM", "PatchCore"]
BACKBONES = ["efficientnet_b0", "tf_mobilenetv3_small_100"]
# keep the two smallest datasets
mvtec_classes = ["hazelnut_reduced", "transistor_reduced"]
def tensor_to_img(x, normalize=False):
if normalize:
x *= IMAGENET_STD.unsqueeze(-1).unsqueeze(-1)
x += IMAGENET_MEAN.unsqueeze(-1).unsqueeze(-1)
x = x.clip(0.,1.).permute(1,2,0).detach().numpy()
return x
def pred_to_img(x, range):
range_min, range_max = range
x -= range_min
if (range_max - range_min) > 0:
x /= (range_max - range_min)
return tensor_to_img(x)
def show_pred(sample, score, fmap, range):
sample_img = tensor_to_img(sample, normalize=True)
height, width = sample_img.shape[:2]
fmap_img_tmp = pred_to_img(fmap, range)
fmap_img_tmp = cv2.resize(fmap_img_tmp[:,:,0], (height, width), interpolation = cv2.INTER_CUBIC)
fmap_img = (np.reshape(fmap_img_tmp, (height, width, 1))*255).astype(np.uint8)
# overlay
plt.imshow(sample_img)
plt.imshow(fmap_img, cmap="jet", alpha=0.7)
plt.axis('off')
buf = io.BytesIO()
plt.savefig(buf, format='png', bbox_inches='tight', pad_inches=0, transparent=True)
buf.seek(0)
overlay_img = Image.open(buf)
# actual display
cols = st.columns(3)
cols[0].subheader("Test sample")
cols[0].image(sample_img)
cols[1].subheader("Anomaly map")
cols[1].image(fmap_img)
cols[2].subheader("Overlay")
cols[2].image(overlay_img)
def get_sample_images(dataset, n):
n_data = len(dataset)
ans = []
if n < n_data:
indexes = np.random.choice(n_data, n, replace=False)
else:
indexes = list(range(n_data))
for index in indexes:
sample, _ = dataset[index]
ans.append(tensor_to_img(sample, normalize=True))
return ans
def main():
with open("./docs/streamlit_instructions.md","r") as file:
md_file = file.read()
st.markdown(md_file)
st.sidebar.title("Config")
app_custom_dataset = st.sidebar.checkbox("Custom dataset", False)
if app_custom_dataset:
app_custom_train_images = st.sidebar.file_uploader(
"Select 3 or more TRAINING images.",
accept_multiple_files=True
)
app_custom_test_images = st.sidebar.file_uploader(
"Select 1 or more TEST images.",
accept_multiple_files=True
)
# null other elements
app_mvtec_dataset = None
else:
app_mvtec_dataset = st.sidebar.selectbox("Choose an MVTec dataset", mvtec_classes)
# null other elements
app_custom_train_images = []
app_custom_test_images = None
app_method = st.sidebar.selectbox("Choose a method",
METHODS)
app_backbone = st.sidebar.selectbox("Choose a backbone",
BACKBONES)
manualRange = st.sidebar.checkbox('Manually set color range', value=False)
if manualRange:
app_color_min = st.sidebar.number_input("set color min ",-1000,1000, 0)
app_color_max = st.sidebar.number_input("set color max ",-1000,1000, 200)
color_range = app_color_min, app_color_max
app_start = st.sidebar.button("Start")
if app_start or "reached_test_phase" not in st.session_state:
st.session_state.train_dataset = None
st.session_state.test_dataset = None
st.session_state.sample_images = None
st.session_state.model = None
st.session_state.reached_test_phase = False
st.session_state.test_idx = 0
# test_cols = None
if app_start or st.session_state.reached_test_phase:
# LOAD DATA
# ---------
if not st.session_state.reached_test_phase:
flag_data_ok = False
if app_custom_dataset:
if len(app_custom_train_images) > 2 and \
len(app_custom_test_images) > 0:
# test dataset will contain 1 test image
train_dataset = StreamingDataset()
test_dataset = StreamingDataset()
# train images
for training_image in app_custom_train_images:
bytes_data = training_image.getvalue()
train_dataset.add_pil_image(
Image.open(io.BytesIO(bytes_data))
)
# test image
for test_image in app_custom_test_images:
bytes_data = test_image.getvalue()
test_dataset.add_pil_image(
Image.open(io.BytesIO(bytes_data))
)
flag_data_ok = True
else:
st.error("Please upload 3 or more training images and 1 test image.")
else:
with st_stdout("info", "Checking or downloading dataset ..."):
train_dataset, test_dataset = MVTecDataset(app_mvtec_dataset).get_datasets()
st.success(f"Loaded '{app_mvtec_dataset}' dataset.")
flag_data_ok = True
if not flag_data_ok:
st.stop()
else:
train_dataset = st.session_state.train_dataset
test_dataset = st.session_state.test_dataset
st.header("Random (healthy) training samples")
cols = st.columns(N_IMAGE_GALLERY)
if not st.session_state.reached_test_phase:
col_imgs = get_sample_images(train_dataset, N_IMAGE_GALLERY)
else:
col_imgs = st.session_state.sample_images
for col, img in zip(cols, col_imgs):
col.image(img, use_column_width=True)
# LOAD MODEL
# ----------
if not st.session_state.reached_test_phase:
if app_method == "SPADE":
model = SPADE(
k=3,
backbone_name=app_backbone,
)
elif app_method == "PaDiM":
model = PaDiM(
d_reduced=75,
backbone_name=app_backbone,
)
elif app_method == "PatchCore":
model = PatchCore(
f_coreset=.01,
backbone_name=app_backbone,
coreset_eps=.95,
)
st.success(f"Loaded {app_method} model.")
else:
model = st.session_state.model
# TRAINING
# --------
if not st.session_state.reached_test_phase:
with st_stdout("info", "Setting up training ..."):
model.fit(DataLoader(train_dataset))
# TESTING
# -------
if not st.session_state.reached_test_phase:
st.session_state.reached_test_phase = True
st.session_state.sample_images = col_imgs
st.session_state.model = model
st.session_state.train_dataset = train_dataset
st.session_state.test_dataset = test_dataset
st.session_state.test_idx = st.number_input(
"Test sample index",
min_value = 0,
max_value = len(test_dataset)-1,
)
sample, *_ = test_dataset[st.session_state.test_idx]
img_lvl_anom_score, pxl_lvl_anom_score = model.predict(sample.unsqueeze(0))
score_range = pxl_lvl_anom_score.min(), pxl_lvl_anom_score.max()
if not manualRange:
color_range = score_range
show_pred(sample, img_lvl_anom_score, pxl_lvl_anom_score, color_range)
st.write("pixel score min:{:.0f}".format(score_range[0]))
st.write("pixel score max:{:.0f}".format(score_range[1]))
@contextmanager
def st_redirect(src, dst, msg):
"""https://discuss.streamlit.io/t/cannot-print-the-terminal-output-in-streamlit/6602"""
placeholder = st.info(msg)
sleep(3)
output_func = getattr(placeholder, dst)
with StringIO() as buffer:
old_write = src.write
def new_write(b):
if getattr(current_thread(), REPORT_CONTEXT_ATTR_NAME, None):
buffer.write(b)
output_func(b)
else:
old_write(b)
try:
src.write = new_write
yield
finally:
src.write = old_write
placeholder.empty()
@contextmanager
def st_stdout(dst, msg):
"""https://discuss.streamlit.io/t/cannot-print-the-terminal-output-in-streamlit/6602"""
with st_redirect(sys.stdout, dst, msg):
yield
@contextmanager
def st_stderr(dst):
"""https://discuss.streamlit.io/t/cannot-print-the-terminal-output-in-streamlit/6602"""
with st_redirect(sys.stderr, dst):
yield
if __name__ == "__main__":
main()
コードの実行
必要なモジュールをインストールしてアプリを立ち上げます。
python3 -m venv venv
.\venv\Scripts\activate
pip install opencv-python
pip install -r requirements.txt
streamlit run streamlit_app.py
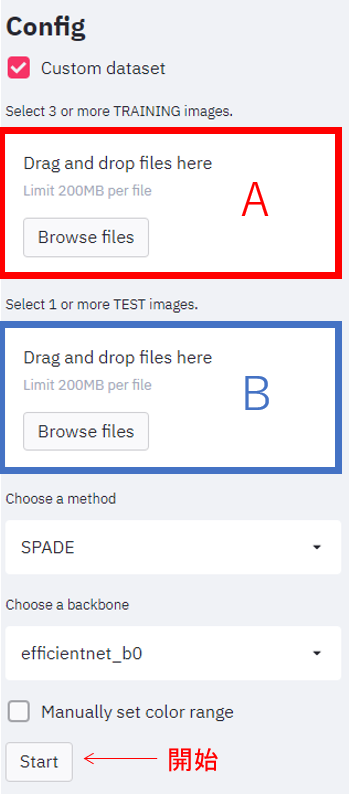
サイドバーにある「Custom dataset」にチェックを入れると、ドロップボックスが表示されます。Aに特徴量抽出用の画像(3枚以上)を、Bに検証用の画像をドラッグ&ドロップしてデータを登録します。データ登録後、Startボタンを押して推論を開始します。
推論結果が以下のように表示されます。

答え合わせ
右上の瓶や左の鍋の違いに対する感度は低いようですが、その他の間違いは検知できているようです。間違いではない部分も検知してしまっているので、間違い探しの攻略率は7割といったところでしょうか。

おわりに
最近の異常検知手法でサイゼリヤの間違い探しをやってみました。AIモデルの再学習を必要としないので、真に検知したい現実のケースでも簡単に試すことができますね。