はじめに
Pythonを本格的に学習し始めてから3ヶ月くらいが経ち、そのアウトプットの場として活用していくつもりです。
今回の記事は自分のやりたいことのほんの一部でもあり、やりたいことは機械学習に取り組むことです。
機械学習を使ってどんなことをやるか決めていませんが、ざっくりとした流れは以下のようになってます。
1.機械学習のデータを集めるためにWebからデータをスクレイピング ←今ここ!
2.スクレイピングしたデータの整形(特徴量)
3.学習モデルの作成、検証
今回は食べログからバーとそれに準ずるお店の口コミデータを収集してみました。
なぜ上記のお店の口コミデータを取得しようと考えた理由としては、美味しいお酒が好きだからです。
自分の好きなことであればモチベーションも維持しやすいしね!
ちなみに、個人的には数あるお酒の中でもクラフトジンがアツいです!
スクレイピングの流れ
1.ランキング一覧ページから店名、ジャンル、評価点、口コミ件数を取得
2.各店舗の口コミページから口コミを取得
※「各店舗の口コミページ」のリンク先は例として、「サンルーカルバー」を設定しています。
3.取得したデータをpandasのデータフレームに格納する
スクレイピングについて詳しく知りたい方は以下の記事が参考になると思います。
・【保存版】Pythonでスクレイピングする方法を初心者向けに徹底解説!【サンプルコードあり】
スクレイピングの注意点
スクレイピングを行う際は、対象となるサイトの利用規約やrobots.txtを確認し、アクセス頻度も考慮した上で実行してください。
こちらのサイトでスクレイピングを行う際の注意点などまとめてありますので、確認してください。
Pythonソース
from bs4 import BeautifulSoup
import os
import re
import requests
import pandas as pd
import time
class TabelogScraping:
"""
食べログから店名、ジャンル、評価点、口コミ件数、最新20件の口コミを取得する
"""
def __init__(self, max_num):
"""
インスタンス化した時点でスクレイピングを開始する
食べログ(検索条件:東京都、バー、ランキング順)にアクセスする
取得するページ件数は1ページ目からmax_numページ目までとする。
"""
# スクレイピング対象となるお店のタグ
self.TAGS = {'バー', 'ワインバー', 'バー・お酒(その他)', 'ラウンジ', 'ダイニングバー'}
# スクレイピング対象となる評価点の下限値
self.LOWER_LIMIT = 3.0
# 口コミのURLへの不足部分
self.RVW = 'dtlrvwlst/'
# 取得したデータ一覧の保存場所
self.RESULT_PATH = '/Users/Yuji/Workspace_python/WebScraping/Data'
# 取得したデータ一覧名
self.RESULT_NAME = 'data_summary.csv'
# 取得した口コミデータフレームの列名
self.COLUMNS = ['store_id', 'store_name', 'genre', 'rate', 'review_cnt', 'review']
# 検索するページ上限数
self.max_num = max_num + 1
self.shop_id = ''
self.id_num = 1
self.df = pd.DataFrame(columns = self.COLUMNS)
try:
first_time = time.time()
for page_num in range(1, self.max_num):
if page_num == 1:
# ランキング1ページ目
response = self.connect_url('https://tabelog.com/tokyo/rstLst/BC01/?SrtT=rt&Srt=D&sort_mode=1')
else:
# ランキング2ページ目以降
response = self.connect_url('https://tabelog.com/tokyo/rstLst/BC01/' + str(page_num) + '/?SrtT=rt&Srt=D&sort_mode=1')
# HTML解析用の変数
soup = BeautifulSoup(response.text, 'lxml')
# 一覧ページから以下の情報を取得する
# ジャンルの取得
genre_info = [genre.text.rstrip() for genre in soup.find_all('div', class_='list-rst__area-genre cpy-area-genre')]
# 評価点の取得
rate_list = [float(rate.text) for rate in soup.find_all('span', class_='c-rating__val c-rating__val--strong list-rst__rating-val')]
# 口コミ件数の取得
count_list = [count.text for count in soup.find_all('em', class_='list-rst__rvw-count-num cpy-review-count')]
# 店名の取得
raw_data = soup.find_all('a', class_='list-rst__rst-name-target cpy-rst-name js-ranking-num')
shop_list = [name.text for name in raw_data]
shop_url_list = [shop_url.get('href') for shop_url in raw_data]
for i in range(20):
genre_tags = set(re.split('[\\s/、]+', genre_info[i].strip())[2:])
# ジャンル文字列が「バー、ワインバー、バー・お酒(その他)、ラウンジ、カフェ、ダイニングバー」の部分集合の場合、
# かつ評価点が「3.0以上」の場合、かつ、口コミ件数が1件以上存在する場合に処理を続ける
if not (genre_tags.issubset(self.TAGS) and rate_list[i] >= self.LOWER_LIMIT and int(count_list[i]) > 0):
continue
start_time = time.time()
self.shop_id = str(self.id_num).zfill(5)
# お店のURLに遷移し、口コミを20件(1ページ分)取得する
response = self.connect_url(shop_url_list[i] + self.RVW)
soup = BeautifulSoup(response.text, 'lxml')
review_url_list = soup.find_all('div', class_='rvw-item js-rvw-item-clickable-area')
# 各口コミページに遷移し、最新の口コミを取得する
for url in review_url_list:
review_detail_url = 'https://tabelog.com' + url.get('data-detail-url')
response = self.connect_url(review_detail_url)
soup = BeautifulSoup(response.text, 'lxml')
review = soup.find_all('div', class_='rvw-item__rvw-comment')
review = review[0].p.text.strip()
# pandasのデータフレームに格納
self.add_df(shop_list[i], genre_info[i].strip(), rate_list[i], count_list[i], review)
# 1つのお店のスクレイピングが終了したら、その結果を保存する
self.write_result(shop_list[i], genre_info[i].strip(), rate_list[i], count_list[i])
process_time = time.time() - start_time
print('{}件目完了: 処理時間:{:.3f}秒'.format(self.id_num, process_time))
self.id_num += 1
except requests.exceptions.HTTPError as e:
print(e)
except requests.exceptions.ConnectTimeout as e:
print(e)
finally:
end_time = time.time() - first_time
print('終了、処理時間:{:.3f}秒'.format(end_time))
def connect_url(self, target_url):
"""
対象のURLにアクセスする関数
アクセスできない等のエラーが発生したら例外を投げる
"""
# 接続確立の待機時間、応答待機時間を10秒とし、それぞれの値を超えた場合は例外が発生(ConnectTimeout)
data = requests.get(target_url, timeout=10)
data.encoding = data.apparent_encoding
# アクセス過多を避けるため、2秒スリープ
time.sleep(2)
# レスポンスのステータスコードが正常(200番台)以外の場合は、例外を発生させる(HTTPError)
if data.status_code == requests.codes.ok:
return data
else:
data.raise_for_status()
def write_result(self, name, genre, rate, count):
"""
スクレイピング対象となるお店の一覧をログとして出力する関数
"""
file_path = os.path.join(self.RESULT_PATH, self.RESULT_NAME)
with open(file_path, mode='a', encoding='utf-8') as f:
f.write('{}, {}, {}, 評価:{}, 口コミ:{}件\n'.format(self.shop_id, name, genre, rate, count))
def add_df(self, name, genre, rate, count, comment):
"""
取得した口コミデータをデータフレームに格納する関数
"""
se = pd.Series([self.shop_id, name, genre, rate, count, comment], self.COLUMNS)
self.df = self.df.append(se, self.COLUMNS)
if __name__ == '__main__':
result = TabelogScraping(1)
print(result.df)
上記のソースコード内で、各自変更する箇所としては以下があります。
「データ一覧名」はログファイル名になります。
# 取得したデータ一覧の保存場所
self.RESULT_PATH = 'ローカルの任意のフォルダへの絶対パス'
# 取得したデータ一覧名
self.RESULT_NAME = '任意のファイル名'
このコードではバーとそれに準ずるお店、かつ評価が3.0、かつ口コミが1件以上のお店を抽出するために以下のコード選別しています。
コード上では条件に当てはまらないお店は除外します。
# スクレイピング対象となるお店のタグ
self.TAGS = {'バー', 'ワインバー', 'バー・お酒(その他)', 'ラウンジ', 'ダイニングバー'}
# 中略
# ジャンル文字列が「バー、ワインバー、バー・お酒(その他)、ラウンジ、カフェ、ダイニングバー」の部分集合の場合、
# かつ評価点が「3.0以上」の場合、かつ、口コミ件数が1件以上存在する場合に処理を続ける
if not (genre_tags.issubset(self.TAGS) and rate_list[i] >= self.LOWER_LIMIT and int(count_list[i]) > 0):
continue
実行してみる
今回は以下の実行環境で動かしてみました。
・macOS 10.13.6
・Python 3.8
・Jupyter NoteBook
ソースコードはエディタ(Atom)で実装して、実行はJupyter NoteBookです。
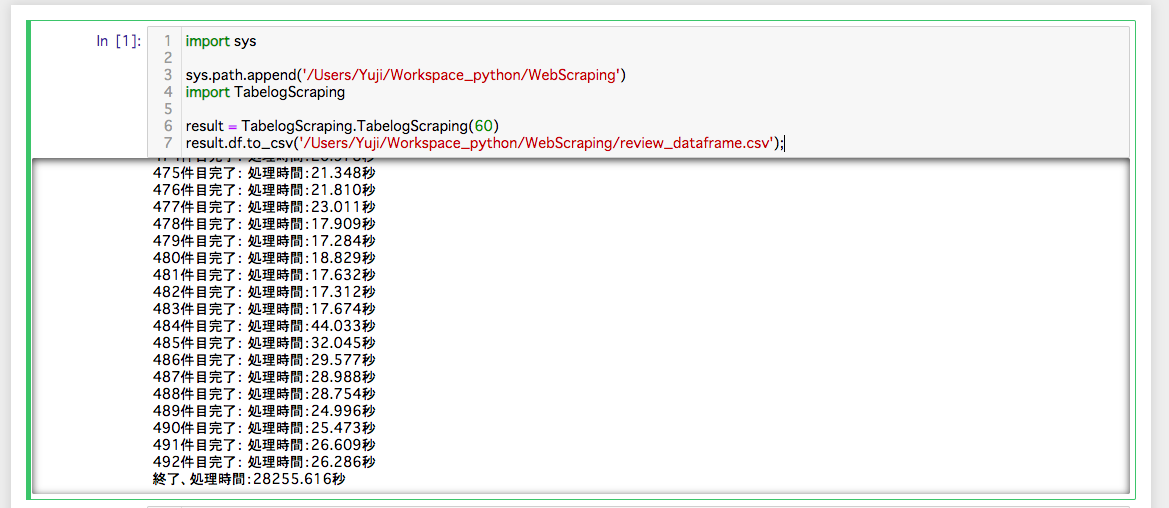
めっちゃ時間かかった...
8時間くらいかかってますね...
肝心の中身を確認してみましょう!
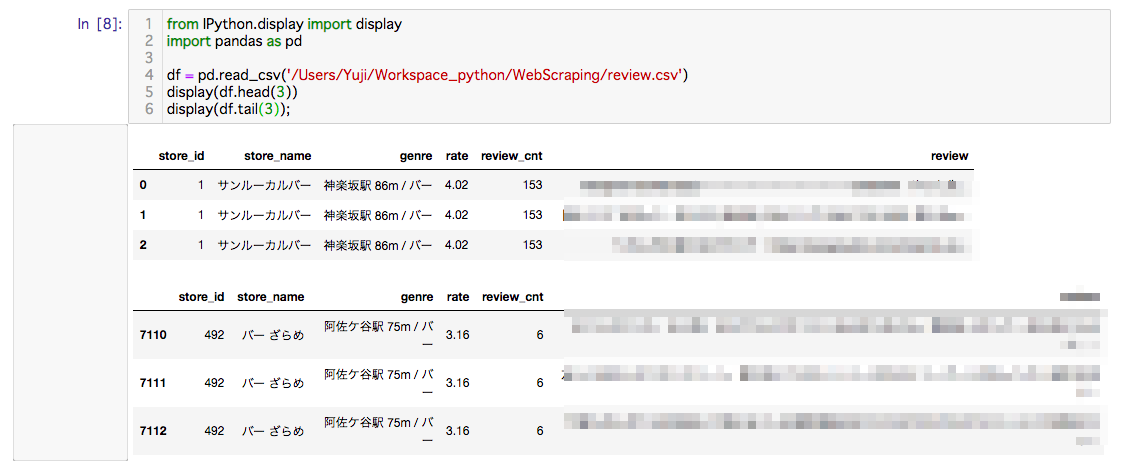
良い感じに取得できてますね!
※食べログ規約にもとづき口コミに関する箇所にはモザイクをいれています。
結果としては、「東京都」で「バー」のお店を食べログでランキング検索して1200件中492件のデータを取得し、総口コミ数は7113件となりました。
1200件中492件だけを抽出した理由は上記でも述べているように、バーとそれに準ずるお店を選別したためです。
ランキングの中にはイタリアンや、フレンチなどのお店も含まれていました。
まとめ
今回は食べログからスクレイピングしてお店の情報や口コミを取得することができました。
取得したデータからお店の特徴量は抽出できると思うが、カクテルの種類に対するデータが少ないため、他のサイトからカクテルレシピデータを取得する必要がありそうです。
スクレイピングのために、今までにないくらい食べログのサイトを見たのでバーに行きたい欲が高まってしまいました。
参考
【Python】🍜ラーメンガチ勢によるガチ勢のための食べログスクレイピング🍜
【完全版】PythonとSeleniumでブラウザを自動操作(クローリング/スクレイピング)するチートシート