はじめに
モバイルアプリケーション上でLLMを動作させる試みをしている時の備忘録です。
llama.cppを用いてgemma-3n系のモデルをggufに変換し、量子化を行います。
一部のモデルでは.gguf形式のものがhuggingface上に存在しているので、基本的にはそちらを利用すれば問題ありません。しかし、一部のモデルは.gguf形式のものが公開されていません。また、量子化の設定を細かく触れる場合には自前で変換をする必要があります。
本記事の内容の誤りや誤字脱字等がありましたら 編集リクエスト または コメント で 優しく ご指摘いただけますと幸いです☺️
筆者はllama.cpp等の扱いに精通しているわけではないので もっと良いやり方 などがあればご教示いただける嬉しいです〜!
本記事の内容は先日行った【オンライン参加可】【モバイル】学生エンジニア3団体合同×ディップLT会 で行ったLTの準備の過程の一部抜粋となります。
本編!
実行環境
M3 macbook airで動かしています。
同様の手順で M2 macbook air, Ubuntu 24.04.3 LTSでも実行できることを確認しています。
llama.cppのcloneとbuild
llama.cppのリポジトリをcloneします。
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
huggingfaceモデルを.ggufに変換するためにはpythonの環境が必要です。
今回は仮想環境を作成して作業します。
# 仮想環境作成
python -m venv .venv
# 仮想環境に入る
source .venv/bin/activate
仮想環境に入った後、依存関係をインストールします。
pip install -r requirements/requirements-convert_hf_to_gguf_update.txt
続いて、llama.cppをビルドします。
こちらに書いてある通りに実行します。
ビルドにはcmakeが必要です。筆者はbrew install cmakeでインストールを行いました。
cmake -B build
cmake --build build --config Release -j 8
huggingfaceからのモデルのクローン
今回はgoogle/gemma-3n-E2B-itを対象に.ggufモデルを作成してきます。
画像のClone repositoryを押すと使用するコマンドが表示されます。
以下のコマンドでcloneできます。その際にユーザ名とパスワードを聞かれます。
どちらもhuggingfaceで登録しているユーザ名とAPIキーを入力するとできます。(パスワードはアカウントのパスワードではないことに注意‼️)
git clone https://huggingface.co/google/gemma-3n-E2B-it
.ggufの作成
いよいよ.gguf拡張子への変換を行います。
変換用のスクリプトはllama.cpp側に同梱されているのでそちらを利用します。
llama.cpp/のディレクトリで以下を実行しましょう。
python convert_hf_to_gguf.py ../gemma-3n-E2B-it \
--outfile ../gemma-3n-E2B-it/gemma-3n-E2B-it.gguf \
--outtype bf16
この実行では引数にcloneしてきたモデルディレクトリへのパスを指定します。
--outfileオプションでは.ggufの出力先を、--outtypeオプションではモデルの数値精度を指定します。
これはcloneしてきたファイルで確認することが可能であり、gemma-3n-E2B-it/config.json内のtorch_dtypeフィールドから確認することができます。
エラーが出る場合
次のようなエラーが出る場合はモデルのcloneに問題がある場合が多いです。
Traceback (most recent call last):
File "/Users/you22fy/dev/llama_cpp/llama.cpp/convert_hf_to_gguf.py", line 11106, in <module>
main()
File "/Users/you22fy/dev/llama_cpp/llama.cpp/convert_hf_to_gguf.py", line 11083, in main
model_instance = model_class(dir_model, output_type, fname_out,
File "/Users/you22fy/dev/llama_cpp/llama.cpp/convert_hf_to_gguf.py", line 6042, in __init__
super().__init__(*args, **kwargs)
File "/Users/you22fy/dev/llama_cpp/llama.cpp/convert_hf_to_gguf.py", line 759, in __init__
super().__init__(*args, **kwargs)
File "/Users/you22fy/dev/llama_cpp/llama.cpp/convert_hf_to_gguf.py", line 139, in __init__
self.model_tensors = self.index_tensors(remote_hf_model_id=remote_hf_model_id)
File "/Users/you22fy/dev/llama_cpp/llama.cpp/convert_hf_to_gguf.py", line 231, in index_tensors
ctx = cast(ContextManager[Any], gguf.utility.SafetensorsLocal(self.dir_model / part_name))
File "/Users/you22fy/dev/llama_cpp/llama.cpp/gguf-py/gguf/utility.py", line 305, in __init__
raise ValueError(f"Could not read complete metadata. Need {8 + metadata_length} bytes, got {file_size}")
ValueError: Could not read complete metadata. Need 2336927755350992254 bytes, got 135
マシンにgit lfsがインストールされているかをご確認ください!
https://git-lfs.com/
.ggufの量子化
量子化を行います。先ほど行ったllama.cppのビルドでllama-quantizeが作成されているのでそれを利用します。
./build/bin/llama-quantize \
../gemma-3n-E2B-it/gemma-3n-E2B-it.gguf \
../gemma-3n-E2B-it/gemma-3n-E2B-it-Q4_0.gguf Q4_0
量子化オプションについてはhttps://note.com/bakushu/n/n1badaf7a91a0にわかりやすくまとまっているのでこちらに譲ります。
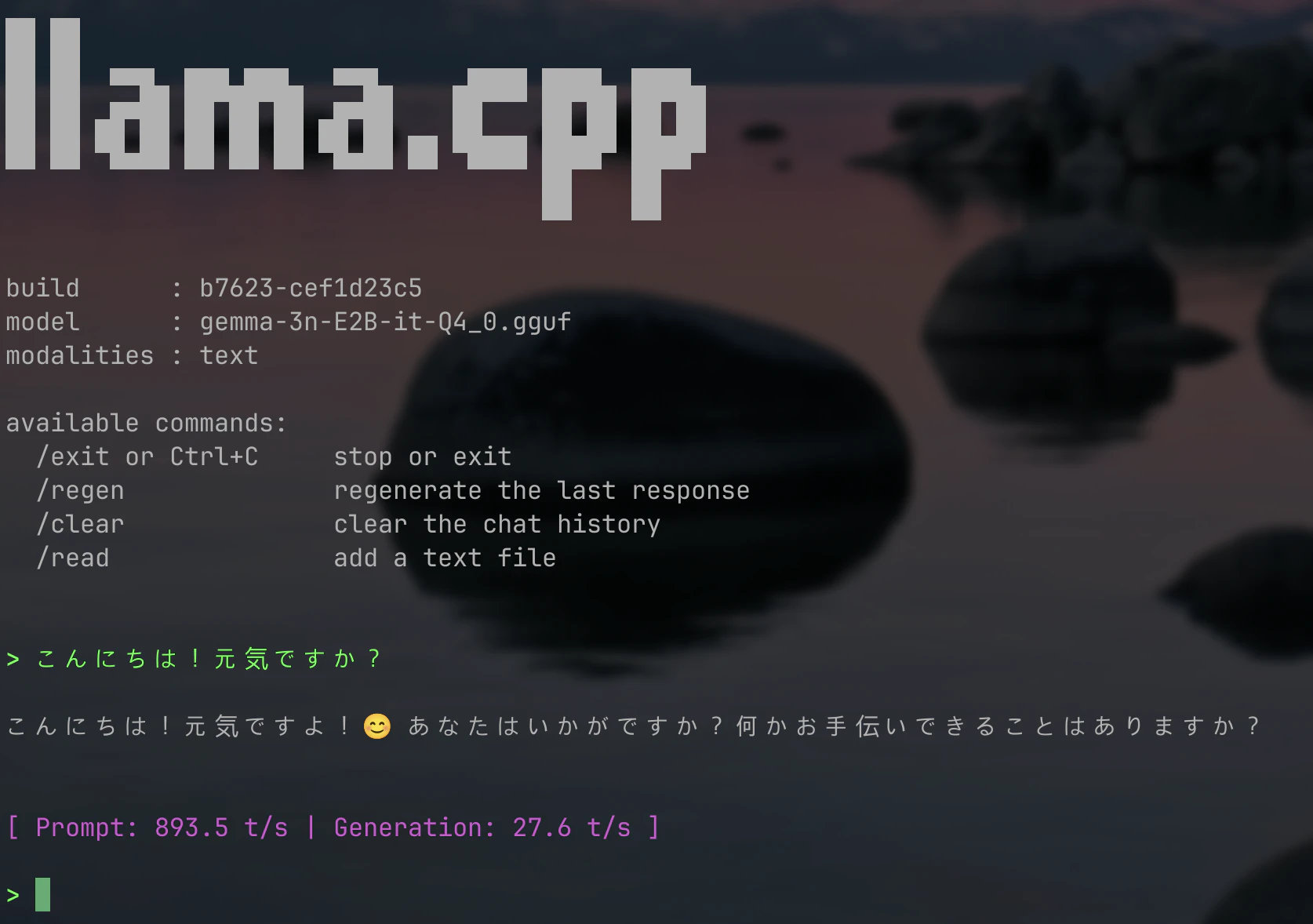
llama.cppでの推論実行
最後にllama-cliを用いて作成した量子化済みモデルで推論を動かしてみます。
./build/bin/llama-cli -m ../gemma-3n-E2B-it/gemma-3n-E2B-it-Q4_0.gguf
無事応答してくれることが確認できます👀