はじめに
Nature Remoは赤外線を利用して普通の家電をスマート家電にするスマートリモコンです。
テレビ、照明、エアコンなどをスケジュールや条件でオン、オフできたりする製品ですが、
温度、湿度、照度、人感センサーなどが搭載されており、
公式のAPIが公開されているので、APIを叩いて取得してみることにします。
また取得した情報を、継続的に記録していくための仕組みも構築してみます。
構成
- Google Cloud Functions (Python 3.7)
- Nature Remo API
- Google BigQuery
構成は単純ですが、APIを叩いて情報を取得しDBに書き込むプログラムを
GoogleCloudFunctionで定期的に動かす、というつくりです。
Pythonは使い慣れているからという理由ですが、JavaやNode.jsなども対応しています。
データベースは、APIで取得したJSON形式のままFirestoreに保存する方法もありますが、
実際やってみたところ、後々のデータ可視化で面倒ということがわかったので、
表形式のBigQueryを使うことにしました。(各種BIツールも多く対応しています。)
また、他のPaaS系のDBと違ってインスタンスを立ち上げるという概念がなく、
フルマネージドのため、発行したクエリに対してのみの課金となります。
このような個人のデータ蓄積程度であれば、ほぼ無料に近い料金で済みます。
準備
以下について事前に準備しておきます。
他にたくさん記事があるため、手順は説明しません。
・Nature Remo APIのアクセストークン取得
(公式サイト https://home.nature.global/ にログインして発行)
・Google Cloud Platformを使うための利用開始登録
・Google Cloud Platformで新規プロジェクトを作成
手順
以下の順番で進めていきます。
① Cloud Functionsに関数をデプロイ
② BigQueryの準備
③ Cloud Scheduler でスケジュール実行の設定
GCP上の設定画面は度々変更があるため、
本記事で掲載している表示とは異なる場合がありますのでご了承ください。
① Cloud Functionsに関数をデプロイ
GCP上で新しいプロジェクトを作成したら、
左のメニューからコンピューティング>Google Cloud Functionsを選択します。
「関数を作成」をクリック
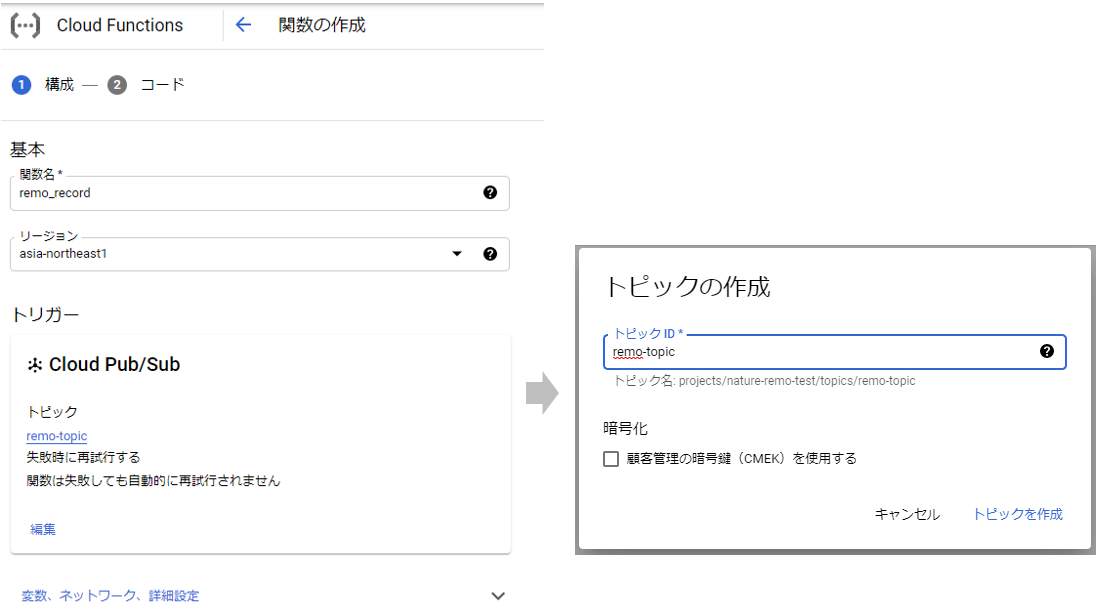
基本
関数名を入力し、リージョンを選択します。
トリガー
スケジュール実行は「Cloud Scheduler」を使用しますが、
「Pub/Sub」という非同期メッセージングのサービスを介して、関数をトリガーします。
トリガーのタイプで「Cloud Pub/Sub」を選択し、
「トピックを作成する」を選択して、適当なトピックIDを入力して作成しておきます。
スケジュール自体は後でCloud Scheduler側で設定するので、ここはトピック作成までです。
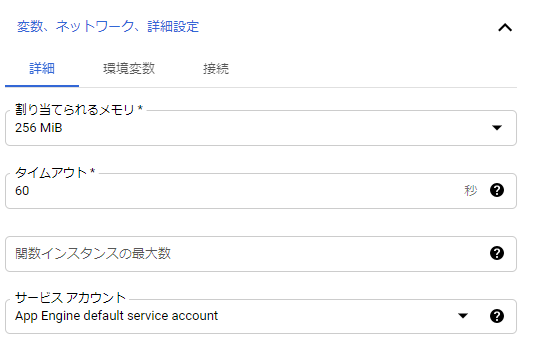
変数、ネットワーク、詳細設定
割り当てメモリやタイムアウトを設定できます。
今回のような軽い処理はデフォルトで大丈夫ですが、必要に応じて変更します。
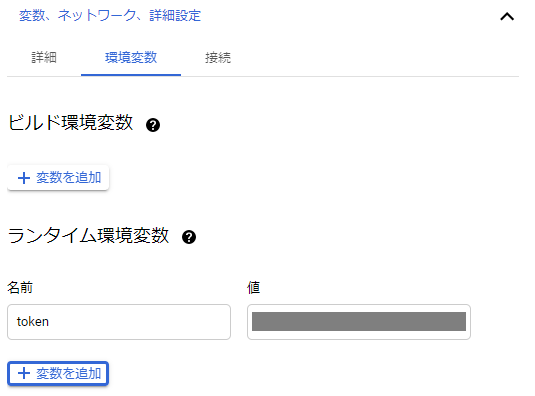
環境変数のタブで、
事前に入手したNature Remo APIのトークンを、ランタイム環境変数に設定しておきます。
トークンは機密情報なので、ソース内には書かず環境変数に指定します。
万が一、ソースに書いたのをGitHubなどの公開リポジトリにあげたりして漏れてしまうと、
世界中の誰でも、あなたの家の電気を点けたり消したりできるようになります。
コード
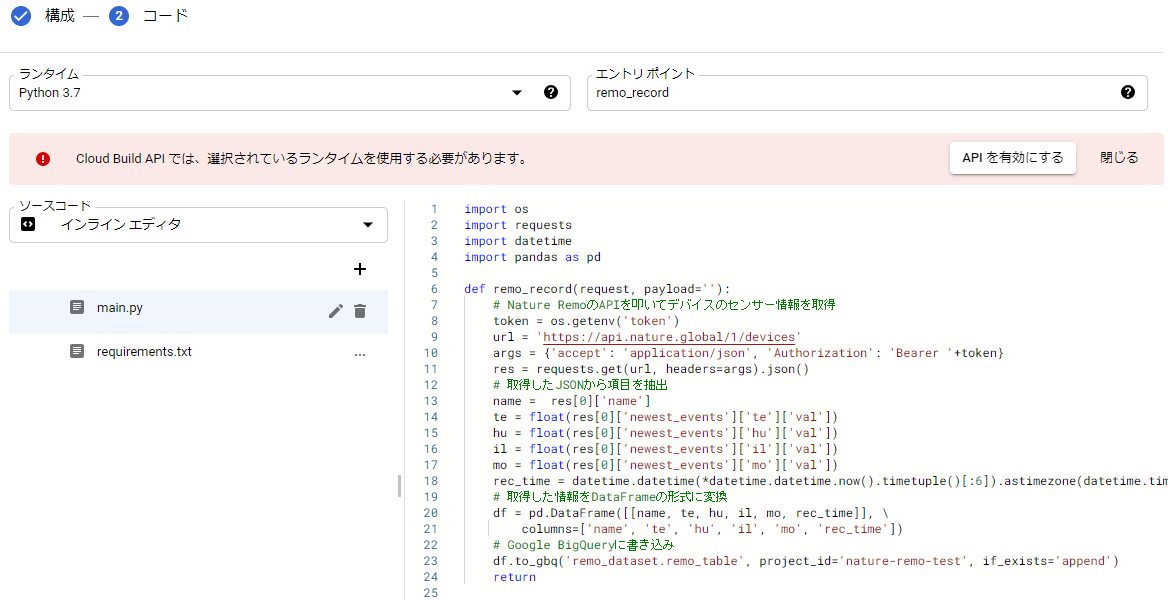
次の画面で実際に動かすコードを入力します。
- ランタイムで「Python 3.7」を選択
- エントリポイントには、ソースコード中の呼び出す関数名を入力
- main.py にメインのソースコード
- requirements.txt に必要なライブラリを記載
- Cloud Build APIを有効にするようアラートが出ているので有効にしておきます
継続的に開発する場合は、インラインエディタよりリポジトリからのデプロイがお勧めです。
Googleのリポジトリが利用でき、各種Gitクライアントからプッシュすることができます。
ソースコードは以下の通り
import os
import requests
import datetime
import pandas as pd
def remo_record(request, payload=''):
# Nature RemoのAPIを叩いてデバイスのセンサー情報を取得
token = os.getenv('token')
url = 'https://api.nature.global/1/devices'
args = {'accept': 'application/json', 'Authorization': 'Bearer '+token}
res = requests.get(url, headers=args).json()
# 取得したJSONから項目を抽出
name = res[0]['name']
te = float(res[0]['newest_events']['te']['val'])
hu = float(res[0]['newest_events']['hu']['val'])
il = float(res[0]['newest_events']['il']['val'])
mo = float(res[0]['newest_events']['mo']['val'])
rec_time = datetime.datetime(*datetime.datetime.now().timetuple()[:6]).astimezone(datetime.timezone(datetime.timedelta(hours=+9)))
# 取得した情報をDataFrameの形式に変換
df = pd.DataFrame([[name, te, hu, il, mo, rec_time]], \
columns=['name', 'te', 'hu', 'il', 'mo', 'rec_time'])
# Google BigQueryに書き込み
df.to_gbq('remo_dataset.remo_table', project_id='nature-remo-test', if_exists='append')
return
APIを叩いて取得したJSONから各項目の値を抽出し、
pandasのDataFrame形式に変換し、DBに書き込むという単純なものです。
pandasのto_gbqでBigQueryに一発で書き込みができます。(pandas-gbqのインストールが必要)
引数は、データセット名.テーブル名、プロジェクトID、書き込み方式を指定します。
GoogleCloudFunctionと同じアカウント内で行うので、認証などの記述は必要ありません。
家にNature Remoが1台だけある前提でのソースコードです。
複数台のデバイスがある場合は識別するロジックが必要かも知れません。
詳細は公式のAPI仕様を確認してください。
https://developer.nature.global/
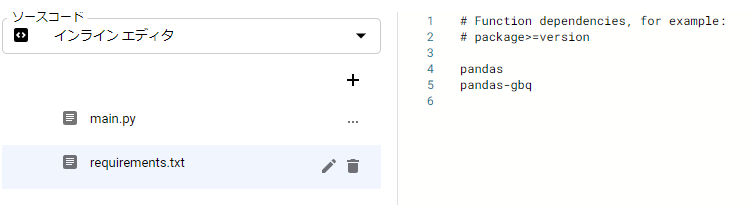
requirements.txtに記載したライブラリが、デプロイ時にインストールされます。
pandas の他、Google BigQueryに接続するためのpandas-gbqを入れておきます。
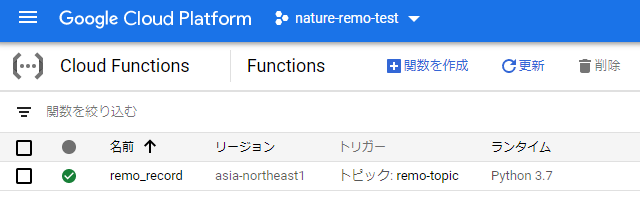
ここまでできたら、「デプロイ」をクリックして関数をデプロイします。
しばらくして、関数の左に緑色のチェックマークが付いたら無事デプロイ完了です。
② BigQueryの準備
メニューからビッグデータ>BigQueryを選択します。
初めての場合でBigQueryを有効にするような画面が出る場合は、有効にします。
BigQueryが有効になったら、まずは「データセット」を作成します。
BigQueryでは、プロジェクト > データセット > テーブル のような関係になっています。
データセットのID等を入力します。
データセットIDはCloudFunctionsのソース中のデータセット名と一致させてください。

データセットの作成だけで、準備はとりあえず完了です。
テーブルは関数を実行した際に、無ければ作成されます。
スキーマを決めてテーブルを作成しておくこともできます。
その場合は、スキーマと挿入しようとしたデータで型などが違う場合にエラーとなります。
③ Cloud Scheduler でスケジュール実行の設定
メニューからツール>Cloud Schedulerを選択します。
「ジョブを作成」を選択
リージョンを選択します。
(なぜかSchedulerの時だけ世界地図が出てきます)
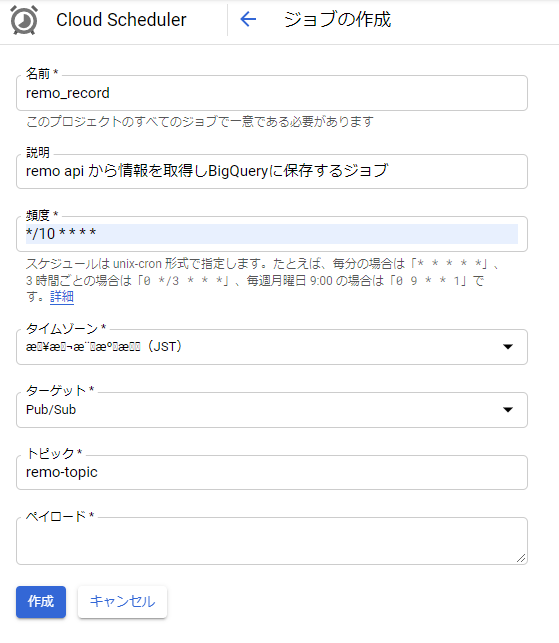
名前: ジョブ名を入力します。(関数名と同じにしましたが何でも構いません)
説明: ジョブの説明を分かりやすく記載します。
頻度: cron形式で入力します。 10分間隔で実行されるように記載しています。
タイムゾーン: JSTを選択(なぜかこの時文字化けしていますが、日本で検索できます)
ターゲット: Pub/Subを選択
トピック: 関数作成時に作成したトピックIDを入力
ペイロード: 関数に引数を渡すことができるようです。必須入力ですがスペースでOKです。
作成するとすでに有効になっているので、次の10分間隔からジョブが実行されます。
ちなみにここでログの表示とありますが、
Schedulerでジョブが起動したか(Pub/Subにメッセージを発行できたか)のみの内容です。
このログでOKでも、関数の処理が正常終了したかどうかは別なので、注意してください。

CloudFunctions側で関数を開いてログを確認すると正常終了していることが確認できました。

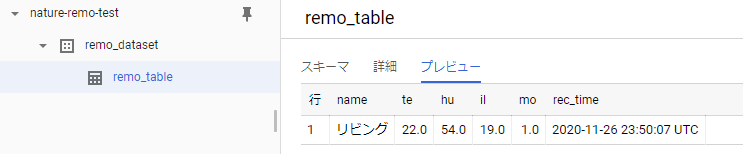
実行後にBigQueryを確認すると、データセットの下にテーブルが作成されています。
プレビューを開くと1行レコードが追加されていることが確認できました。
気温22℃、湿度54%、照度19(単位はよくわかりませんが・・・)とのことです。
moは人感センサーとのことですが、記録を見る限りは不在時でも常に1となってたので、
機能していないように思えます。
終わりに
Google Cloud Platform の各種サービスを使って、
クラウド上でNatureRemoのデータを蓄積する仕組みを作ることができました。
貯めたデータがどうだったかについても、可視化して後日記載してみたいと思います。