この記事はIceberg Advent Calendar 2025 11日目の投稿です。
はじめに
LLM全盛の時代において、半構造化データを効率的に扱えることはデータレイクにおいても重要な要件となっています。
先日EMR ServerlessがApache Spark 4.0.1 (preview) をサポートしたことで、AWSのマネージドサービスからIceberg V3のVARIANT型が扱えるようになりました。この記事ではEMR Serverlessを使ってVARIANT型への読み書きを検証します。
VARIANT型とは
VARIANT型はIceberg V3から導入された半構造化データを保存するためのデータ型です。
従来、Icebergにおいて半構造化データを扱うには以下のような方法がありました。
-
MAP<K, V>型に格納する: Key, Valueの型が全ての要素に対し一律で固定となるため、Key, Valueの型が異なる場合に対処することが難しい({"key1": "foo", "key2": 1}など)。特定のKey, Valueだけをディスクから読み取ることができないためディスクIO・メモリ効率が低下する。 - シリアライズして
STRING型等に格納する: 読み取り時に都度デシリアライズ (JSON_PARSE等) する必要がありパフォーマンスが低下する。特定のKey, Valueだけをディスクから読み取ることができないためディスクIO・メモリ効率が低下する。 - キー毎に要素をフラット化し個別の列に格納する: 事前にスキーマを決める必要があり、スキーマが不定の場合は採用が難しい。
例えば、Iceberg Summit 2025におけるのDoordash社のセッションでは、キーが数百あるMAPに関するTrinoの性能課題の事例が報告されています (27:37~)。Doordash社では対策としてフラット化もしくはTrino側のコンピュート増強の二択を検討し、実施の容易さから後者を選択しています。
V3で導入されたVARIANT型を使うことにより、事前にスキーマを決めずにデータを書き込むことができるようになります。また、読み取り時は Variant Shredding というParquetの機能を活用することにより、VARIANT列から特定のKeyだけを読み込むことができるようになります。
For example, the query
SELECT variant_get(event, '$.event_ts', 'timestamp') FROM tblonly needs to load fieldevent_ts, and if that column is shredded, it can be read by columnar projection without reading or deserializing the rest of theeventVariant
DWHの世界ではIcebergのVARIANTと同等のデータ型は以前から存在しており、RedshiftではSUPER型、BigQueryではJSON型、SnowflakeではVARIANT型がこれに相当します。IcebergがVARIANT型を導入することで、データレイクにおいてもログやドキュメント等の半構造化データの取り扱いがより容易になると期待されます。
検証内容
今回はEMR ServerlessからGlue Data Catalogを介してS3上のIceberg V3テーブルへ読み書きしてみます。
手順は公式ドキュメントおよび以下のブログを参考にさせていただきました。
上記ブログではhadoopカタログを指定していますが、本記事ではGlue Data Catalogを使用した場合の設定方法やカタログ上の表示について説明します。
まずはEMR Serverless applicationを作成します。現時点ではGUIから該当バージョンが選択できないため、CLIから作成する必要があります。
export AWS_REGION=us-east-1
$ aws emr-serverless create-application --type spark \
--release-label emr-spark-8.0-preview \
--region us-east-1 --name spark4-preview
EMR StudioからApplicationが作成されていることが確認できました。
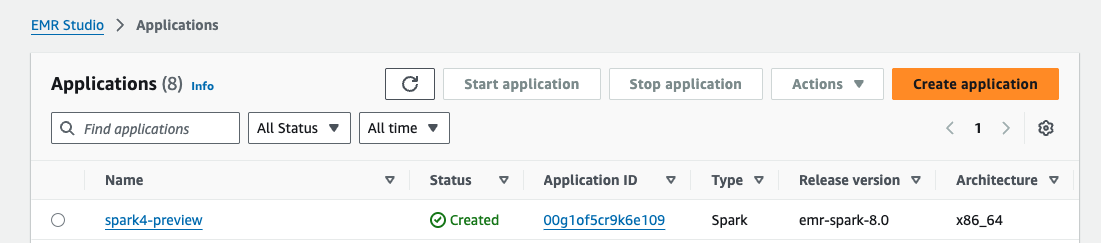
バッチジョブ用のスクリプトを作成します。スクリプトは先述のブログ から引用させていただきました。
※ プレビューリリース (emr-spark-8.0-preview) はインタラクティブワークロードをサポートしていないため、EMR Studio NotebookやLivyエンドポイントからクエリを実行することはできません。従って今回はバッチジョブを作成する必要があります。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, parse_json
# Initialize Spark session with Spark 4.0
spark = SparkSession.builder \
.appName("VariantTypeSupportApp") \
.getOrCreate()
# Create Iceberg table with a VARIANT type column if it doesn't exist
spark.sql("""
CREATE TABLE IF NOT EXISTS dev.default.test_table (
id BIGINT,
properties VARIANT
)
USING iceberg
TBLPROPERTIES (
'format-version' = '3'
)
""")
# Complex JSON string to insert into the VARIANT column
json_string = '''{
"user": {
"name": "Alice",
"age": 30,
"hobbies": ["reading", "swimming", "hiking"],
"address": {
"city": "Wonderland",
"zip": "12345"
}
},
"status": "active",
"tags": ["admin", "user", "editor"]
}'''
# Create a DataFrame with columns 'id' and the JSON string
df = spark.createDataFrame([(1, json_string)], ["id", "json_string"])
# Convert the JSON string column to VARIANT type using parse_json and drop original JSON string column
df_variant = df.withColumn("properties", parse_json(col("json_string"))) \
.drop("json_string")
# Append the data to the Iceberg table
df_variant.writeTo("dev.default.test_table").append()
# Read the data back from the Iceberg table
df_read = spark.table("dev.default.test_table")
print("Reading back data from Iceberg table:")
df_read.show(truncate=False)
print("Schema of the Iceberg table:")
df_read.printSchema()
spark.stop()
作成したスクリプトをS3へアップロードします。
export BUCKET="your-s3-bucket-name"
aws s3 cp ./write.py s3://$BUCKET/jobs/write.py
カタログにはGlue Data Catalogを使用します。sparkSubmitParametersでカタログ等の指定を行っています。
export AWS_ACCOUNT_ID=<your-account-id>
aws emr-serverless start-job-run \
--application-id $APPLICATION_ID \
--name "SimplePySparkVariantJob" \
--execution-role-arn $IAM_ROLE_ARN \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://'"$BUCKET"'/jobs/write.py",
"sparkSubmitParameters": "--jars s3://'"$BUCKET"'/jars/* --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.dev=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.dev.type=glue --conf spark.sql.catalog.glue.id='"$AWS_ACCOUNT_ID"' --conf spark.sql.catalog.dev.warehouse=s3://'"$BUCKET"'/warehouse/ --conf spark.sql.catalog.dev.format-version=3"
}
}' \
--configuration-overrides '{
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://'"$BUCKET"'/logs/"
}
}
}'
Submitして数分するとジョブが完了しました。
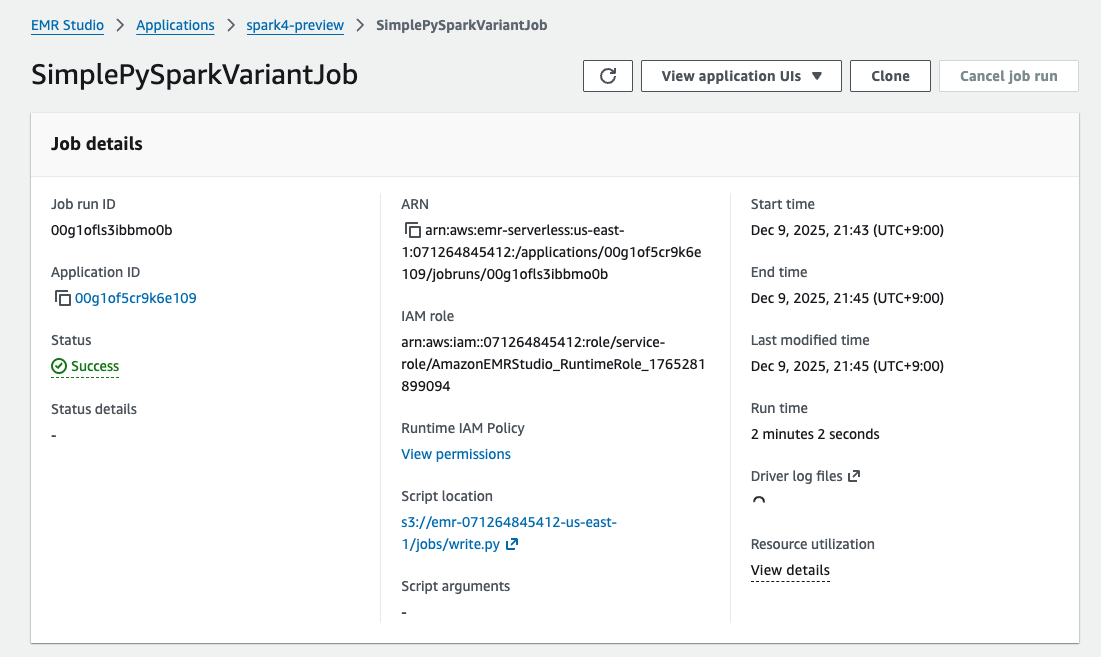
Glue Data Catalogを参照すると、Icebergテーブルが作成されていることが確認できます。
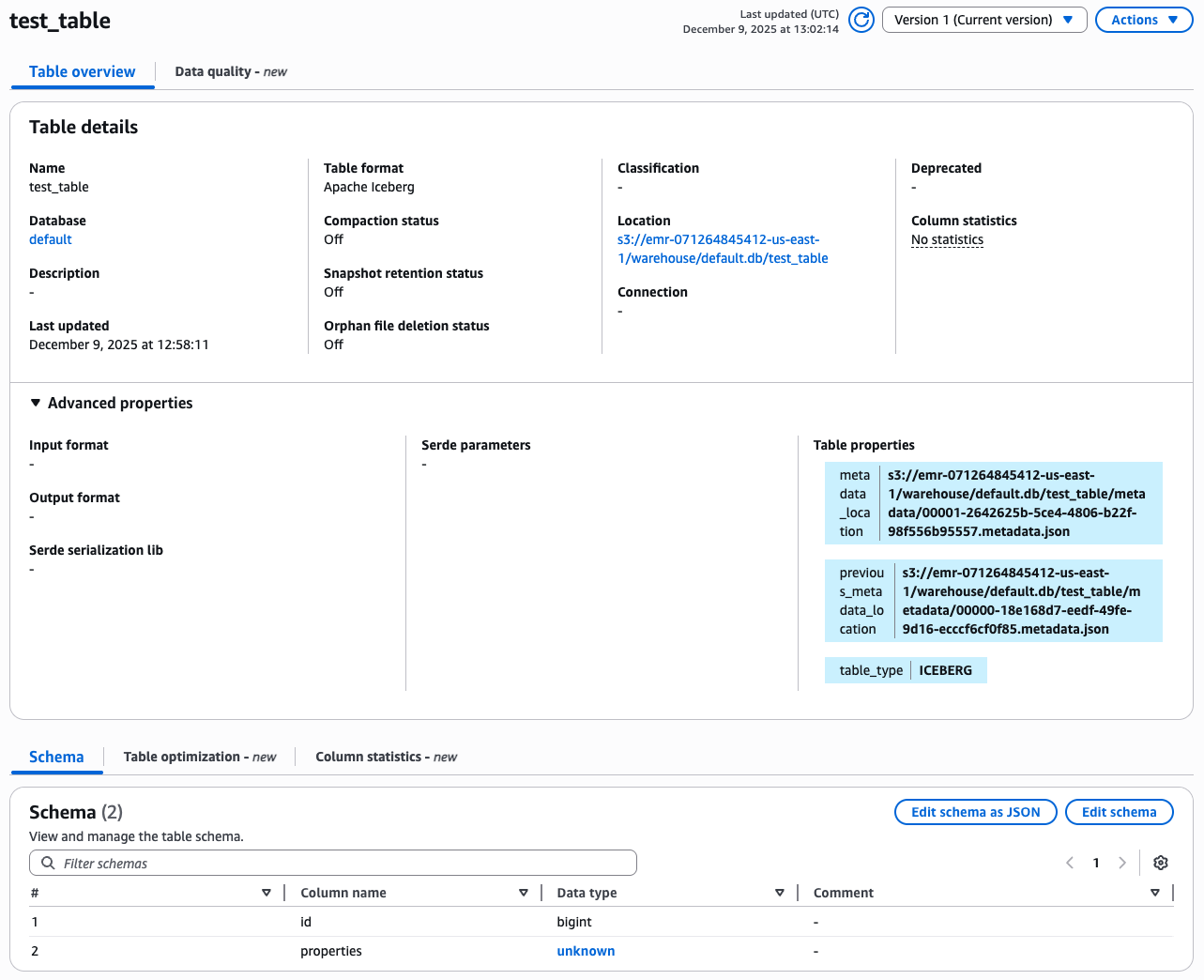
AWSコンソール上は properties のData typeがunknownと表示されていますが、Edit schema as JSONを選択し、Glue Data Catalogが認識しているスキーマ定義を確認するとvariantで定義されていることがわかります。

※尚、この画面からはIcebergテーブルのスキーマの変更を行うことはできないことに注意してください。Icebergテーブルのスキーマ変更はSpark等のクエリエンジンからALTER TABLE等のコマンドを発行する必要があります。
S3上のmetadata/配下に出力されているメタデータのJSONの中身を参照すると "format-version": 3 となっており、確かにV3のフォーマットでテーブルが作成されていることが確認できました。properties列の型もvariant となっています。
{
"format-version": 3,
"table-uuid": "5e377364-a700-4838-b842-743d1f303223",
"location": "s3://emr-071264845412-us-east-1/warehouse/default.db/test_table",
"last-sequence-number": 1,
"last-updated-ms": 1765285091784,
"last-column-id": 2,
"current-schema-id": 0,
"schemas": [
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "id",
"required": false,
"type": "long"
},
{
"id": 2,
"name": "properties",
"required": false,
"type": "variant"
}
]
}
],
...(略)...
}
注意点
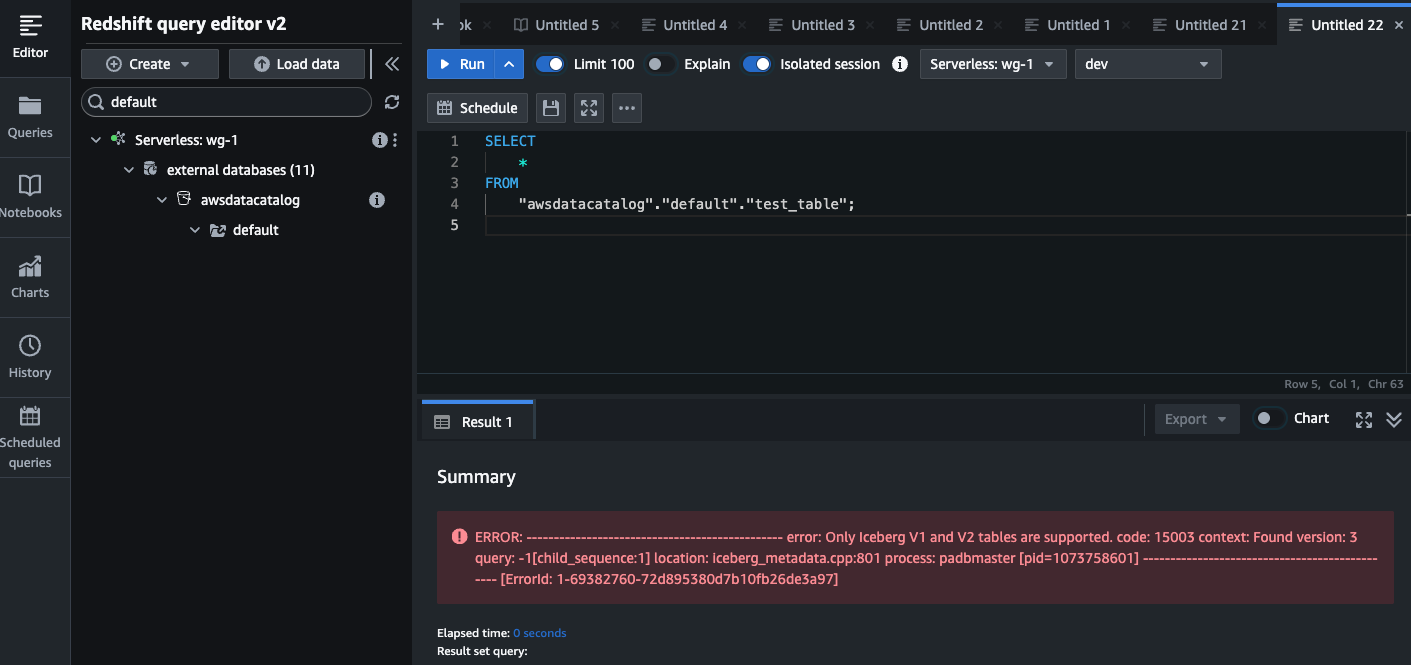
Iceberg V3フォーマットで書きこまれたテーブルを読みとるにはV3に対応したクエリエンジンが必要です。例えばAthenaやRedshiftは2025/12時点でIceberg V3に対応していないため、クエリしようとすると以下のようなエラーとなります。従って、V3の利用にあたってはまず読み取り側のクエリエンジンのV3対応を待ってから、書き込み側のエンジンをV3にアップグレードする必要があります。TrinoやFlinkなどOSSのエンジンを使用する場合も同様です。
Athena

Redshift
まとめ
EMR Serverless (emr-spark-8.0-preview) からIcebergテーブルへVARIANT型のテーブルの作成と読み書きができることを確認しました。また、作成したIceberg V3テーブルがGlue Data Catalog上で表示されることを確認しました。
今後各エンジンのV3・VARIANT対応が進み、IcebergテーブルへのログやJSONドキュメントの保管がより簡単に実現できるようになることに期待したいですね。