AWS re:Invent 2022にてInformatica Data Loader for Amazon RedshiftがGAされました。
本記事はこれからInformatica Data Loaderを使ってみたい方を対象とし、機能の概要やセットアップの手順、裏側の動きについて記載します。内容は基本的にAWS公式ブログ: Simplify data loading on the Amazon Redshift console with Informatica Data Loader
の手順をなぞっていますが、IAMやセキュリティグループの設定まわりで迷ったポイントを独自に追記しています。
本記事ではInformatica Data Loaderの機能の詳細までは触れないため、差分ロードやフィルタリング等の各種機能については公式マニュアルInformatica Online Helpも合わせて参照してください。
特徴
Informatica Data Loader for Redshiftは様々なデータソースからAmazon Redshiftへサーバレスなデータ連携が行える機能です。無料で提供されているため、気軽に使い始めることができます。
利用可能なデータソースは以下の41種類で(2022年12月現在)、各種SaaS、OSS/商用データベース、オブジェクトストレージに対応しています。有名どころだとAmazon Aurora, Google Analytics, Google Cloud Spanner, Jira, MongoDB, MySQL, OData, Oracle, PostgreSQL, Salesforce, SqlServerあたりでしょうか。BigQuery, Snowflake, Teradataには対応していませんでした。
連携先はRedshiftのみで、ProvisionedとServerlessいずれも対応しています。


Redshift以外の連携先を使いたい場合はSnowflake, BigQuery, Databricks, Azure用のInformatica Data Loaderも用意されています。
データ連携に特化した様々なオプションが使用できます。ただし、集計や結合などの複雑なETL操作は対応していません。
- オブジェクトレベル、列レベル、行レベルのフィルタリング
- 全件・差分ロード
- 差分キャプチャ (CDC)
- スキーマドリフトの検知
準備
以下ではAWS公式ブログの手順に沿いSalesforceデータソースをRedshiftに連携してみます。
- Redshiftクラスターもしくはワークグループを作成します。
- プライベートサブネットにある場合はそのままだとInformaticaから接続できないため、パブリックアクセスを有効化します。
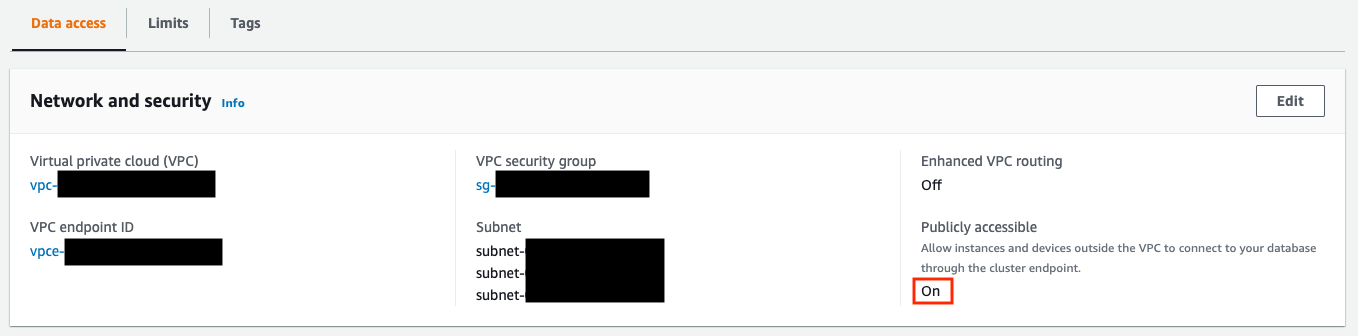
- 上記はRedshift Serverlessの設定画面ですが、Provisionedクラスターでも同様です。
- プライベートサブネットにある場合はそのままだとInformaticaから接続できないため、パブリックアクセスを有効化します。
- Redshiftのセキュリティグループを編集し、Informaticaからのインバウンド通信を許可します。
- 許可するIPアドレスは、Informaticaのリージョンとホワイトリスト対象のIPアドレスに記載があります。Informaticaのリージョン(NA/EMEA/APAC/UK)によってIPアドレスが異なるので、データソース及び使用するAWSリージョンとの距離を考慮しつつInformaticaのリージョンを選んでおきます。NA (North America) は必要なIPアドレスが多いので設定が少々大変ですね。ここではEMEAリージョンを選択しました。
- インバウンドルールはType: Redshiftを選びます。InformaticaはRedshiftのPort: 5439へJDBCでアクセスするためです。

- Redshiftと同じリージョンにS3バケットを作成します。データをロードする前のステージングに使用します。
- (データソースがSalesforceの場合)Salesforceの開発者用アカウントを作成します。
- Salesforceの開発者用アカウントは最初からダミーデータが入っているのでテストするのに便利です。
- 初回はセキュリティトークンの再発行が必要です。Informaticaから接続する際に使用します。
- IAMユーザを作成し、アクセスキーを発行します。InformaticaからS3へデータを送る際に使用します。
- ポリシーはAmazonS3FullAccessをアタッチします。実際はもう少し権限を絞れると思いますが、検証環境のため既存のAWS管理ポリシーを使用しました。
Informatica Data Loaderへ登録
この機能はAWSコンソールからではなくInformatica Data LoaderのWebコンソールに登録・ログインして利用するため、初回は登録が必要です。
Provisonedクラスター用のRedshiftコンソールへ行き、Informatica Data Loaderをクリックします。Redshift Serverlessを使う場合でも入り口はProvisionedのコンソールです。
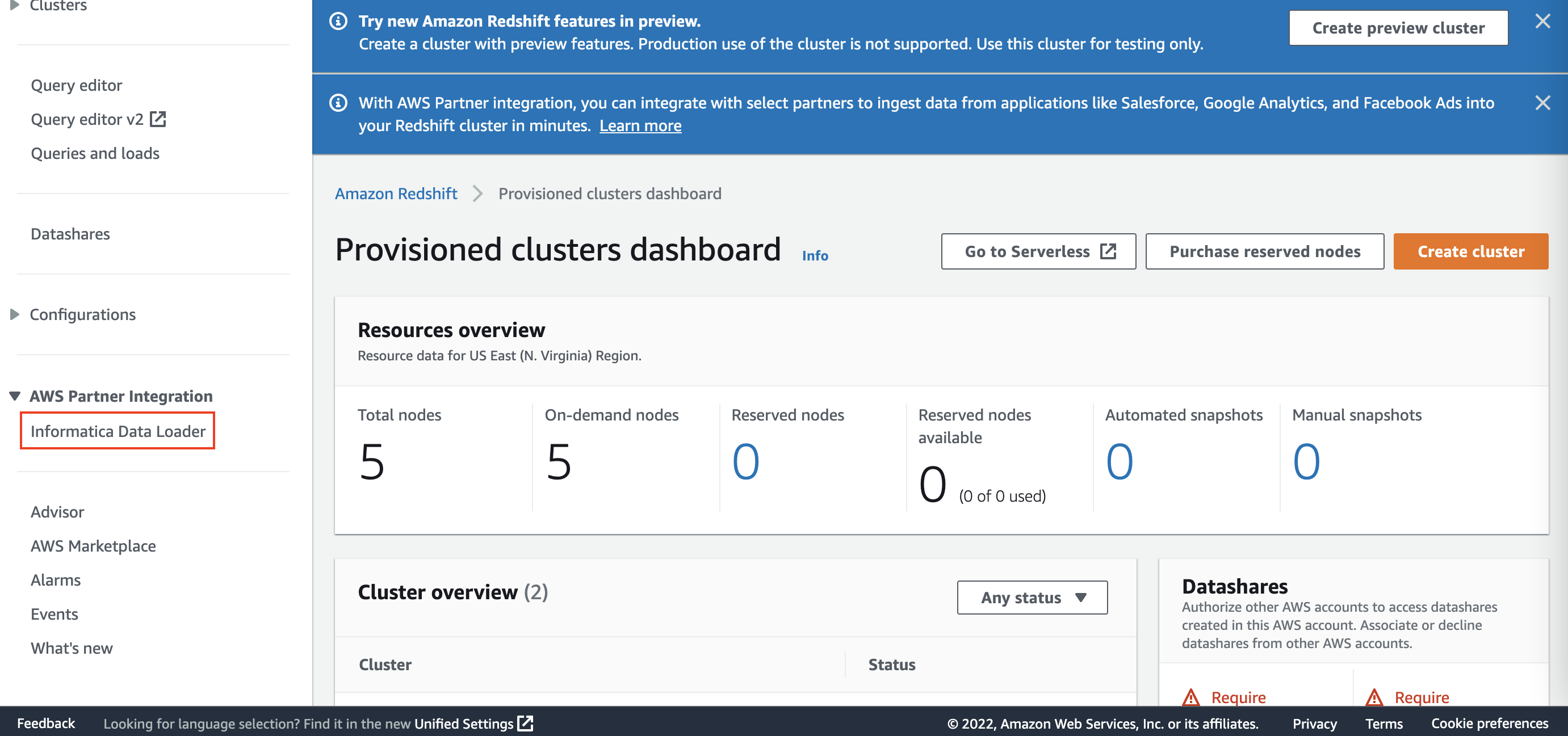
Complete Informatica IntegrationをクリックするとInformaticaのサイトが開きます。
必要な情報を入力し、SUBMITするとメールが飛んできます。メールのリンクをクリックすると登録完了となりInformaticaにログインされます。

データソースへ接続
左上のNewをクリックすると新しいデータ連携タスクを作成する画面になります。New Connectionをクリックします。
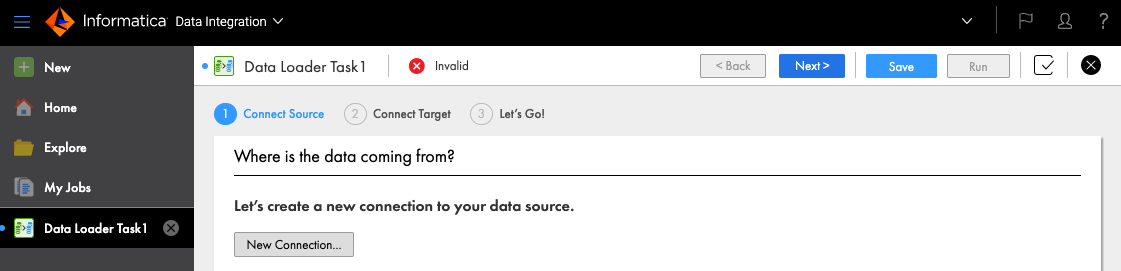
接続したいデータソースを選びます。ここではSalesforceを選びました。
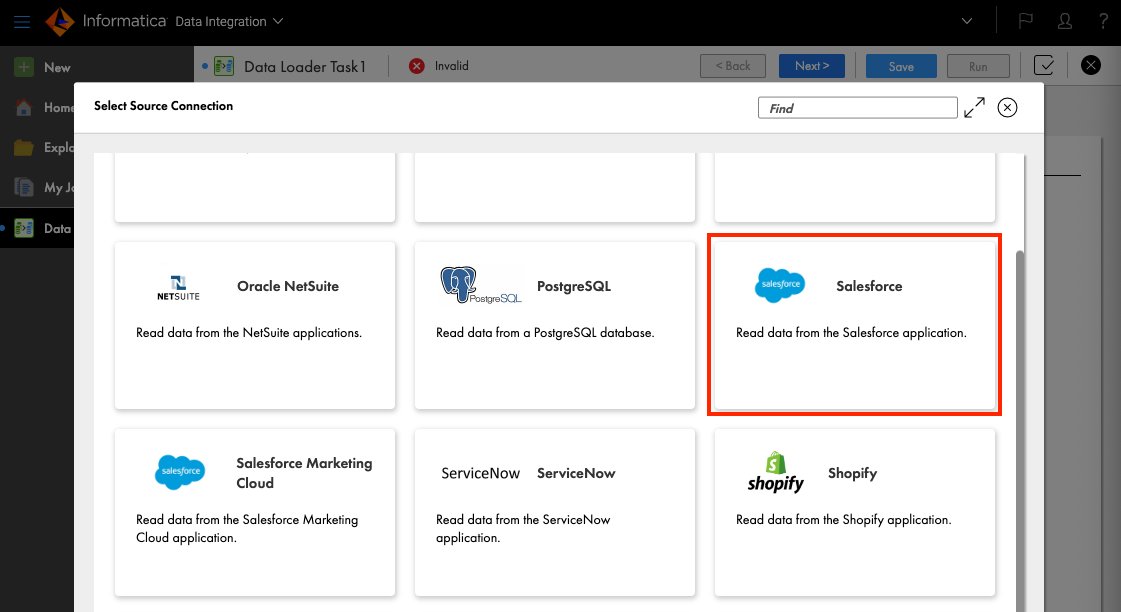
以下の項目を入力します。
- Connection Name: 任意の接続名
- User Name: Salesforceのユーザ名
- Password: Salesforceのパスワード
- Security Token: Salesforceのセキュリティトークン
Testをクリックして接続できることを確認し、Addします。
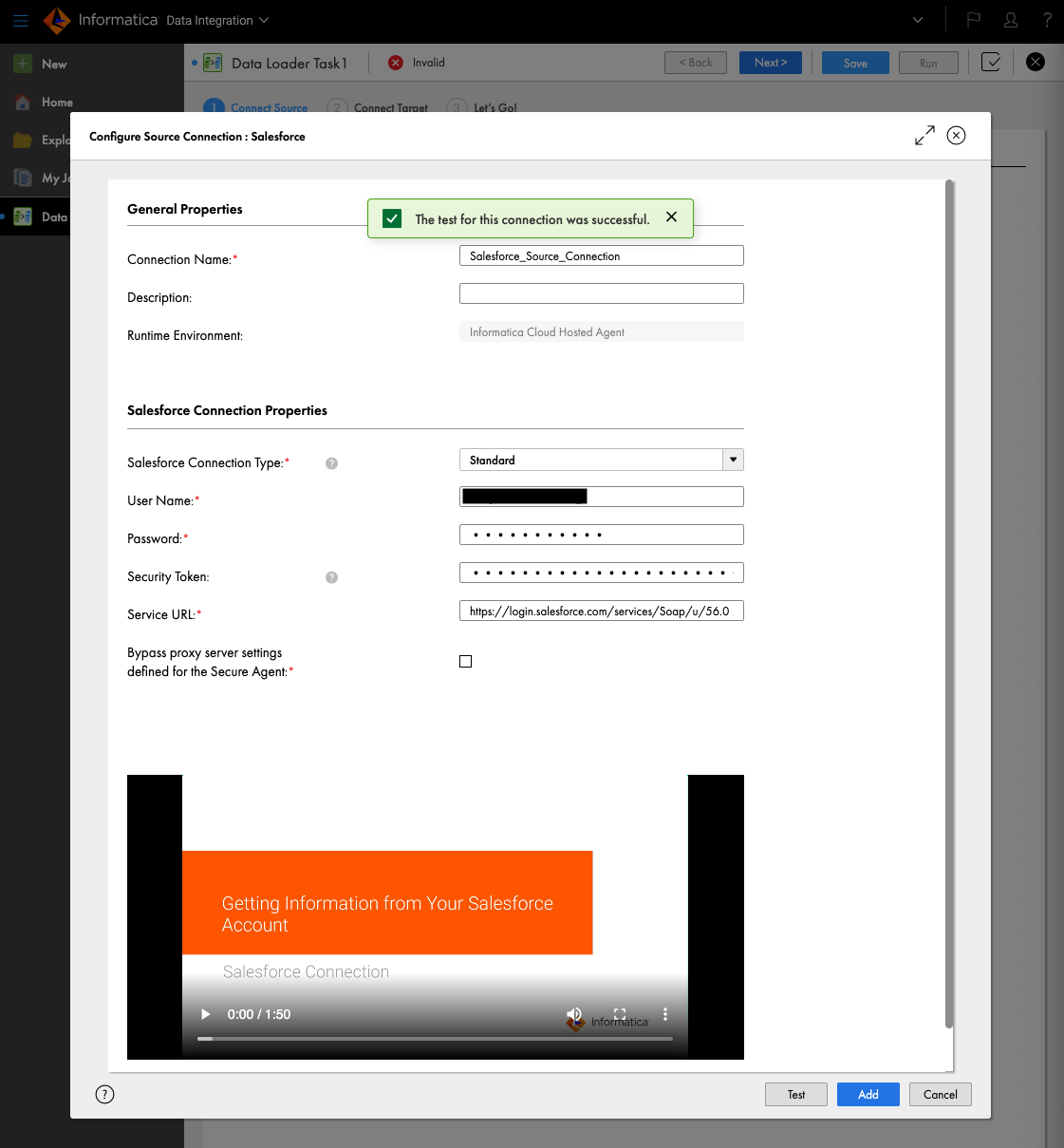
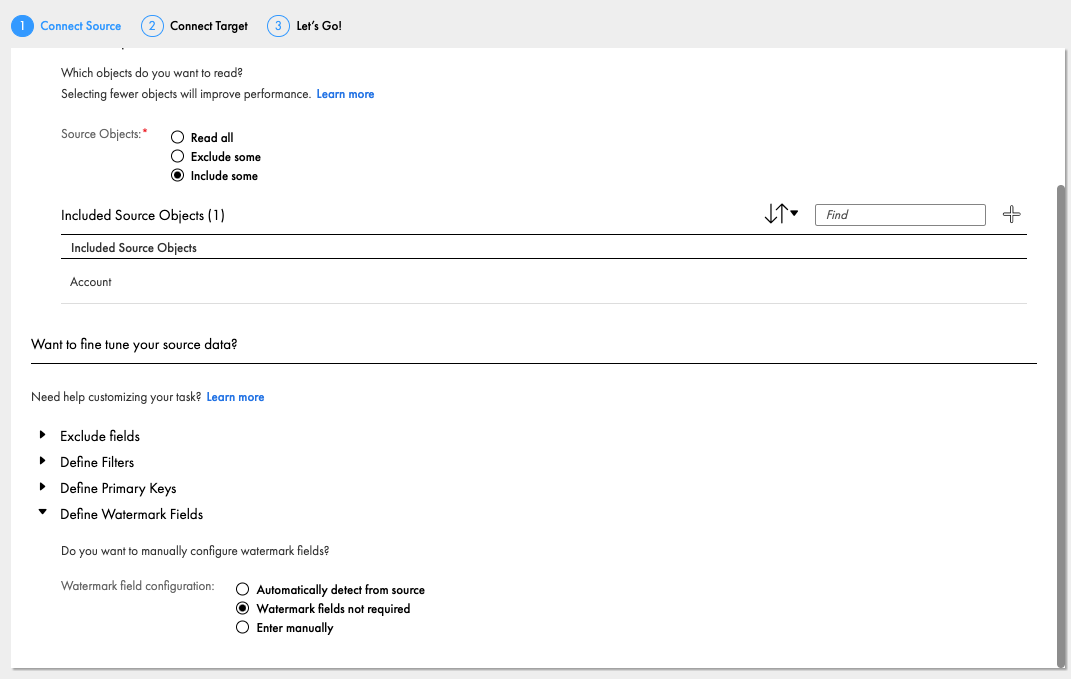
データを取ってくる際に特定のオブジェクトやフィールドの除外、データのフィルタ、Primary Keyの定義、ウォーターマークの定義が設定可能です。例として特定のオブジェクトのみを取ってきたい場合はDefine Objectsの"+"をクリックします。
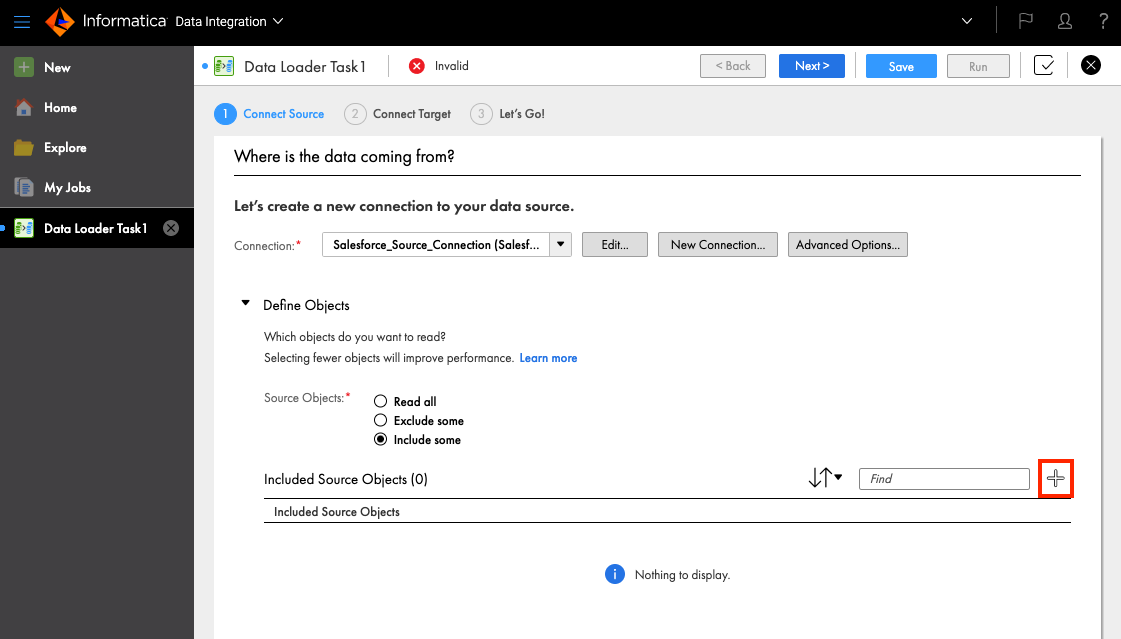
Salesforceから特定オブジェクトのみチェックボックスを入れることで、他のオブジェクトはRedshiftへの連携対象外となります。ここではAccountのみチェックします。
ちなみにデフォルトだとウォーターマーク(処理済のレコードを識別する情報)がオンになっているため、同じタスクを複数回実行してもRedshiftへは1回しかレコード連携されません。これを無効にしたい場合はDefine Watermark FieldsでWatermark fields not requiredを指定します。
Redshiftへの接続
続いてConnect TargetにてNew Connectionをクリックし、Redshiftへの接続を作成します。
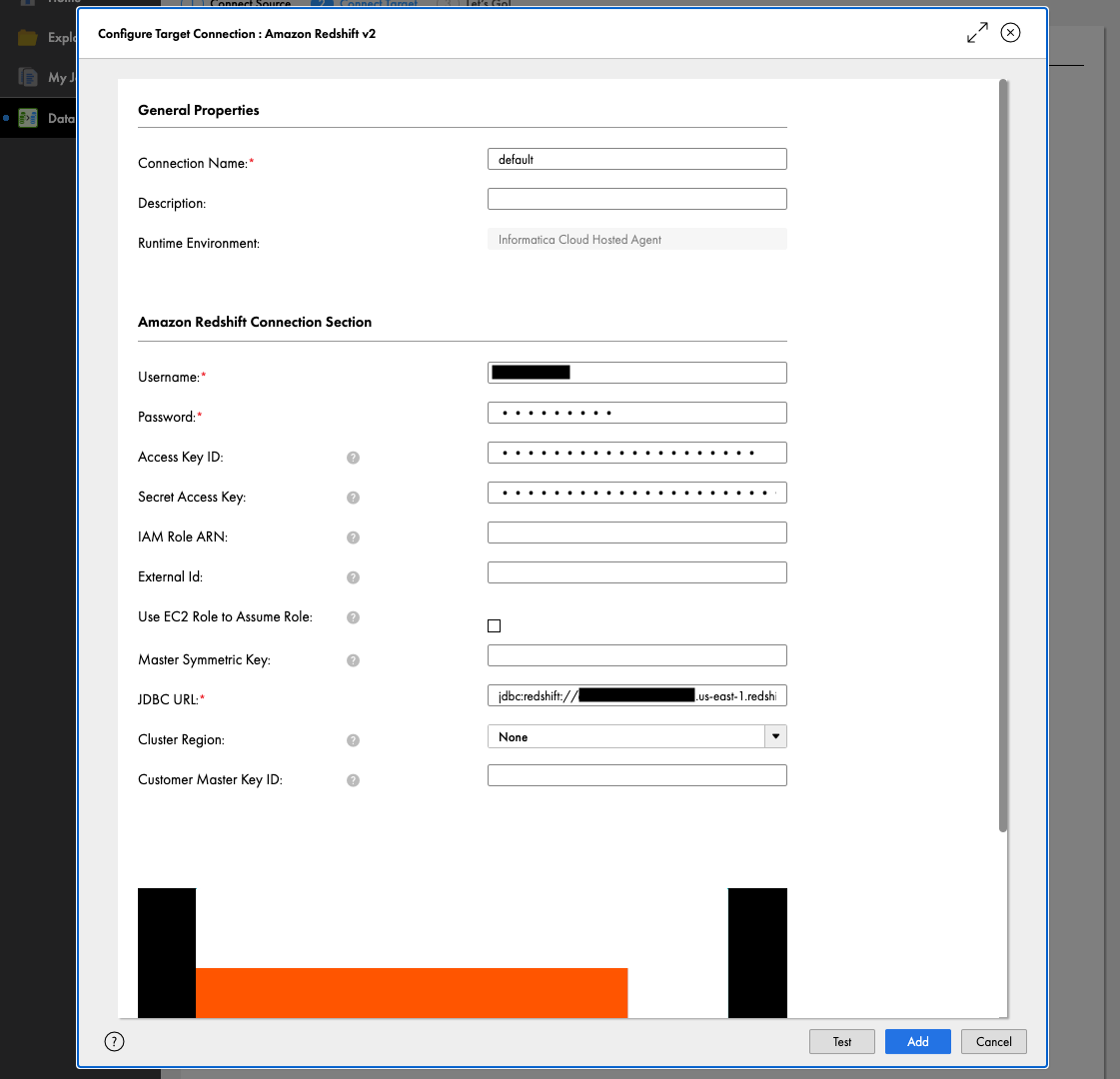
以下の項目を入力したらTestをクリックして接続できることを確認し、Addします。
- Connection Name: 任意の接続名
- Username: Redshiftのデータベースユーザ名
- Password: Redshiftのデータベースユーザのパスワード
- Access Key ID: IAMユーザのアクセスキーID
- Secret Access Key: IAMユーザのシークレットアクセスキー
-
JDBC URL: RedshiftのJDBC接続用URL(jdbc:redshift://*:5439/dev)
Pathはテーブルを作りたいスキーマ名を指定します。Load to existing tables? は No, create new tables every time を選択しました。
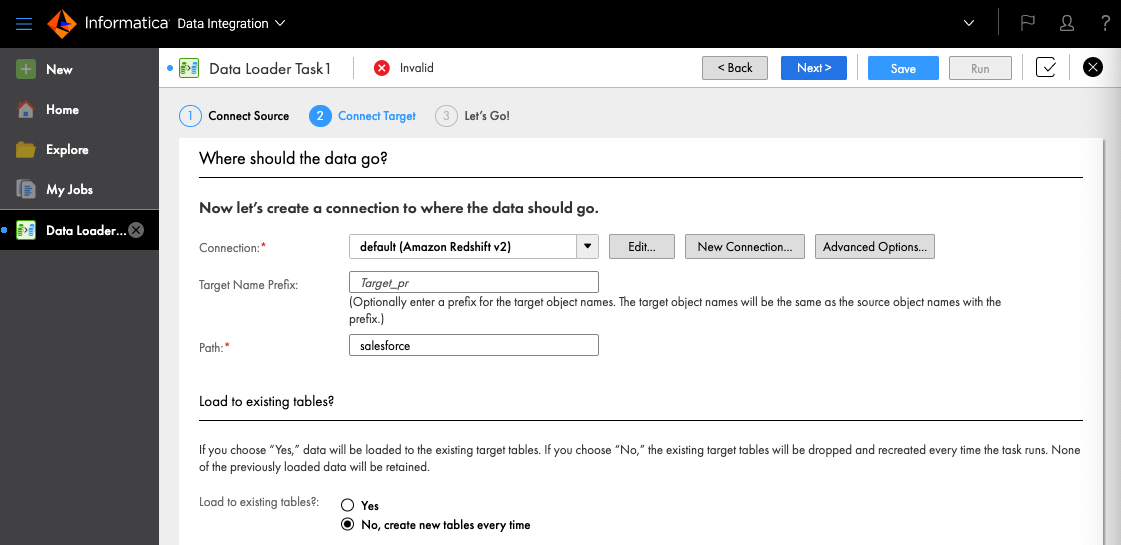
続いてAdvanced Optionsでステージング用のS3バケットを指定し(s3://は不要)、NextをクリックしてからSaveします。
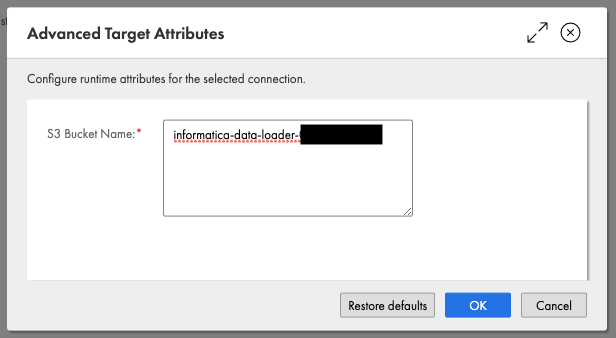
InformaticaはJDBCでRedshiftに接続しているので、INSERTを何度も発行することもできますがデータセットが大きい場合はクエリを何度も発行することになり非効率です。S3バケットを使用することで、Informaticaはデータソースから抽出したデータをS3にステージングし、COPYコマンドを発行してS3からRedshiftへまとめてデータをロードしてくれます。
ジョブ実行
Runをクリックするとジョブが開始されます。完了するとStatusがSuccessに変わります。

作成されたテーブルを見てみる
AWSコンソールでQuery Editor V2を開き、テーブルの中身を確認します。
select * from スキーマ名."Account";
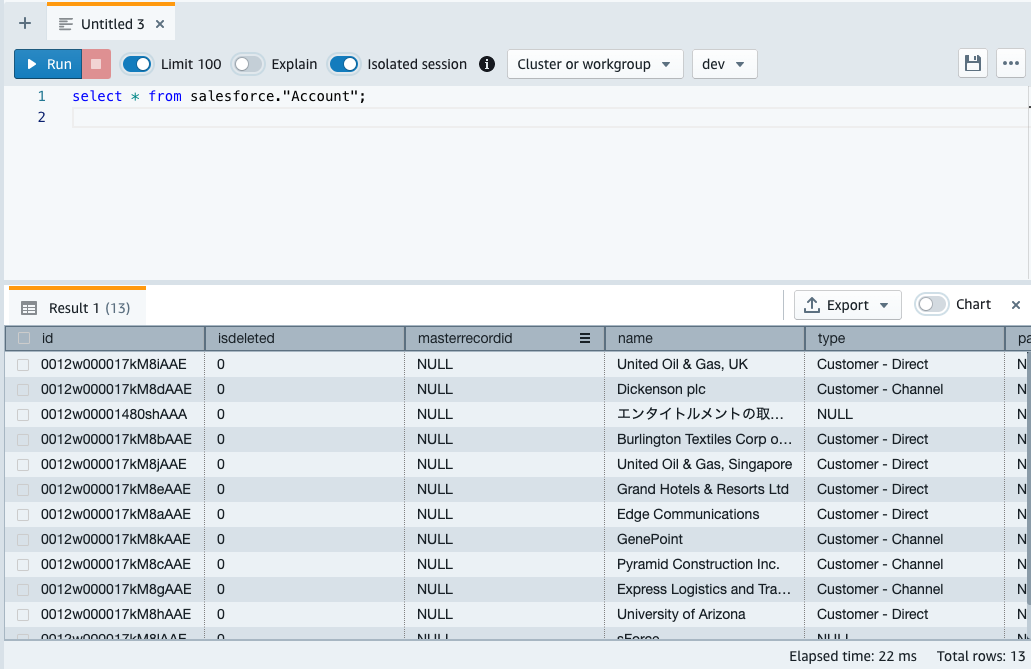
無事データが入っていることが確認できました。
Redshift側のテーブルは、Informatica Data LoaderがデータソースのスキーマをRedshiftにマッピングして自動生成してくれています。念のためテーブルのDDLを確認してみます。
show table スキーマ名."Account";
CREATE TABLE salesforce.account (
id character varying(18) NOT NULL ENCODE lzo distkey,
isdeleted integer NOT NULL ENCODE az64,
masterrecordid character varying(18) ENCODE lzo,
name character varying(255) NOT NULL ENCODE lzo,
type character varying(255) ENCODE lzo,
parentid character varying(18) ENCODE lzo,
billingstreet character varying(255) ENCODE lzo,
billingcity character varying(40) ENCODE lzo,
billingstate character varying(80) ENCODE lzo,
billingpostalcode character varying(20) ENCODE lzo,
billingcountry character varying(80) ENCODE lzo,
billinglatitude numeric(18,15) ENCODE az64,
billinglongitude numeric(18,15) ENCODE az64,
-- ~~ 長いので中略 ~~
slaserialnumber__c character varying(10) ENCODE lzo,
slaexpirationdate__c timestamp without time zone ENCODE az64,
PRIMARY KEY (id)
)
DISTSTYLE AUTO;
列ごとに適切なデータ型が使い分けられており良さそうです。
InformaticaがRedshiftに発行しているクエリ
Informaticaはデータロード時に追加・更新があったレコードだけターゲットのテーブルに反映できるのですが、裏側でどんなクエリを流しているか見てみます。Redshift Serverlessの場合はSYS_QUERY_HISTORY、Provisionedの場合はSTL_QUERYシステムテーブルのquerytxt列で発行されたクエリが取得できます。要約すると以下の流れでした。
- 適当な名前のTEMPテーブルを作る(ターゲットテーブルと同じスキーマ)
- TEMPテーブルにS3からデータをCOPYする
- トランザクション開始
- ターゲットテーブルのレコードをTEMPテーブルでUPDATEする
- ターゲットテーブルにないレコードをTEMPテーブルからINSERTする
- コミット
気を付けること
- Informatica Data Loader自体は無料で使えますが、Redshift等の周辺サービスへの課金は発生します。例えばRedshift Serverlessへ定期的にデータをロードする場合、Informatica側でジョブが動くたびにRedshift側でクエリが発行されるので定期的にRPU時間課金が発生します。
- Informatica Data Loaderを使用するには以下の設定が必要なので、セキュリティ要件を満たせるか確認するとよいでしょう。
- APIキー付きのIAMユーザの作成
- Redshiftのパブリックアクセス設定(プライベートサブネットの場合)
- 外部IPアドレスからRedshiftへのインバウンド通信設定
- データが一度Informaticaの管理するインスタンスを経由する(データソース→Informaticaインスタンス→S3→Redshift)
まとめ
Informatica Data Loaderを使ってRedshiftへデータを連携する方法について検証しました。Informaticaを触るのは初めてでしたが、特に迷うことなくデータを連携することができました。データ型のマッピングやターゲットテーブルの作成はデータ連携のしくみを作るときに手間がかかる部分なのですが、Informatica側でやってくれるのは楽ですね。外部DBのデータをクイックに持ってきてRedshiftで分析したり、SaaSからRedshiftへ定期的にデータを取り込むなど色々な使い方ができそうです。