野球のデータを使って分析したいなと思っていつも「サイトの必要な部分をコピーして、excelに張り付けてcsvにして保存」をしていました。がしかし、そろそろ面倒だなと思い、「スクレイピングして前処理してpostgreSQLに書き込む」までをやってみました。
必要なライブラリのインストール
スクレイピングなど
import pandas as pd
from bs4 import BeautifulSoup
import datetime
postgreSQL書きこみ
import psycopg2
from sqlalchemy import create_engine
- psycopg2
- https://www.psycopg.org/docs/install.html#installation
- sqlalchemy
- https://docs.sqlalchemy.org/en/13/core/engines.html
データの取得
今回は巨人の打者の成績データを「pandas.read_html」で取得します。
ページの表(tableタグ)を順番取ってきてdataframeのリストが返ってくるようです。
raw_data = pd.read_html("https://baseball-freak.com/audience/giants.html", flavor="bs4")
リストが返ってくるので、こんな感じになります
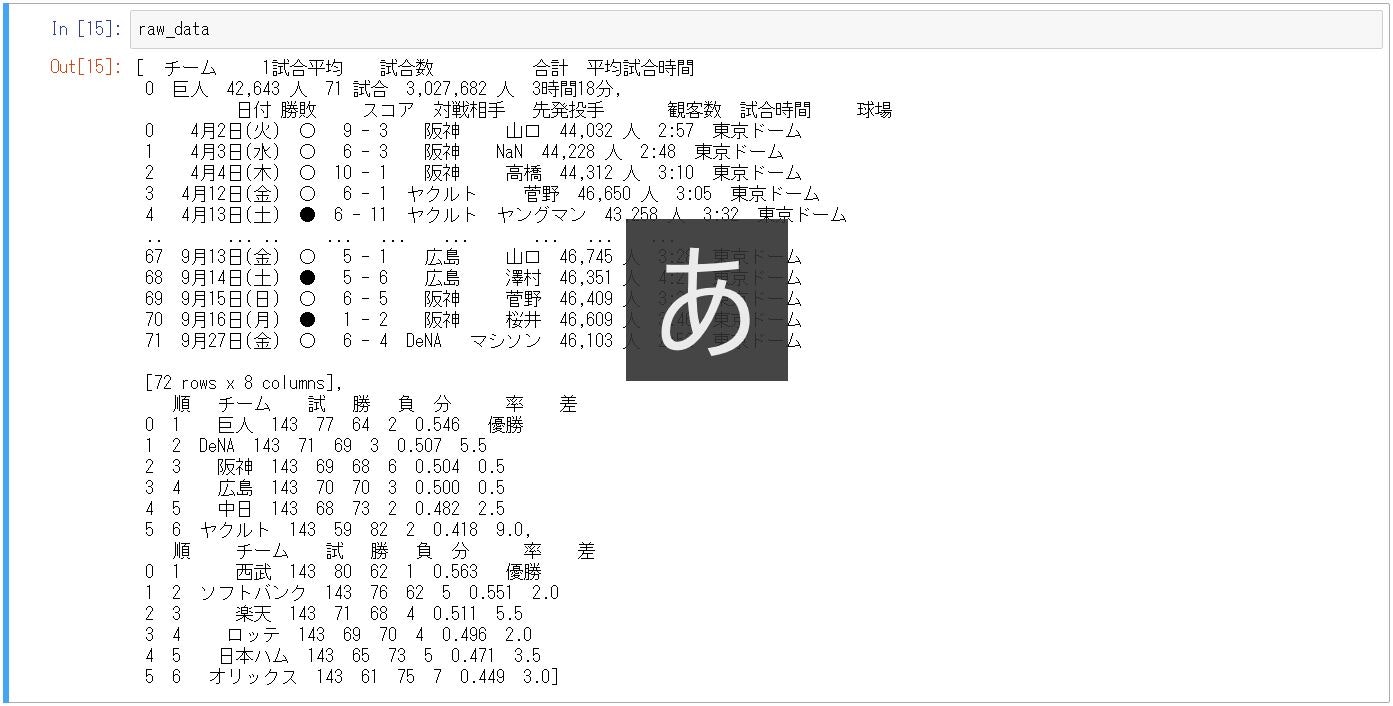
1つ目のdataframeがこんな感じ。

2つ目に今回ほしいデータが入っているはずなのでそれを確認
data_set = raw_data[1] # ページ内に複数の表があり、今回ほしいのは2つ目の表なので[1]と指定します
data_set
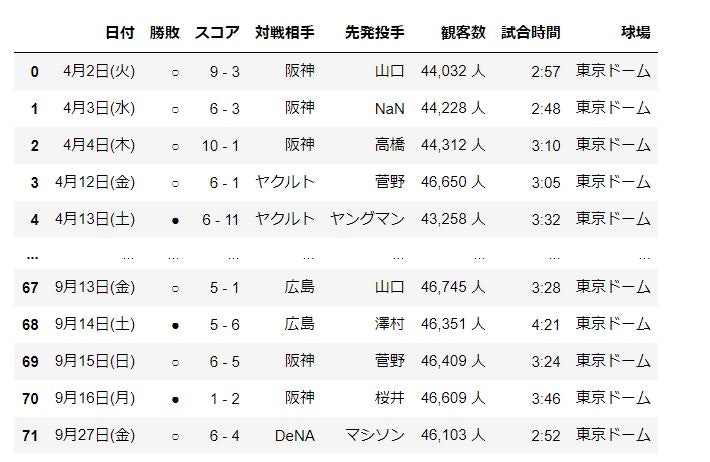
データフレームの内容確認
取得したデータの中身を確認します。
pd.concat(
[data_set.count().rename('件数'),
data_set.dtypes.rename('データ型'),
data_set.nunique().rename('ユニーク件数'),
data_set.isnull().sum().rename('null件数'),
(data_set.isnull().sum() * 100 / data_set.shape[0]).rename('欠損の割合 (%)').round(2)],
axis=1
)
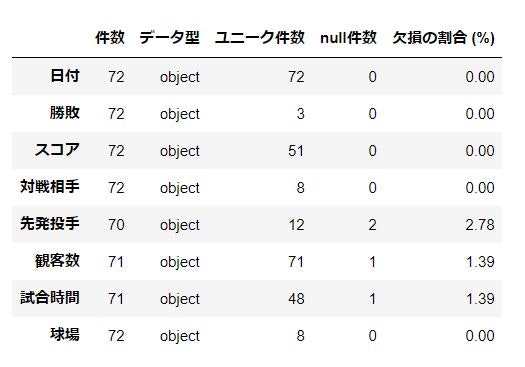
全部がobjectになっているのがわかります。また、先発投手、観客数、試合時間はnullが含まれるようです。
この中で日付、スコア、観客数について型変換などをして分析できるようにします。
日付処理
- 日付カラムを月と日のカラムに分ける
- 日付カラムを日付型にする
- 曜日を「dt.dayofweek」で算出する
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.dt.dayofweek.html
data_set["月"] = data_set["日付"].replace("月.*$", "", regex=True) # regex:正規表現
data_set["日"] = data_set["日付"].replace("日.*$", "", regex=True).replace("^.*月", "", regex=True)
for i in range(len(data_set['月'])):
data_set['日付'] = "2019/" + data_set["月"] + "/" + data_set["日"]
data_set['日付'] = pd.to_datetime(data_set['日付'])
data_set['曜日(数)'] = data_set['日付'].dt.dayofweek
data_set.head()
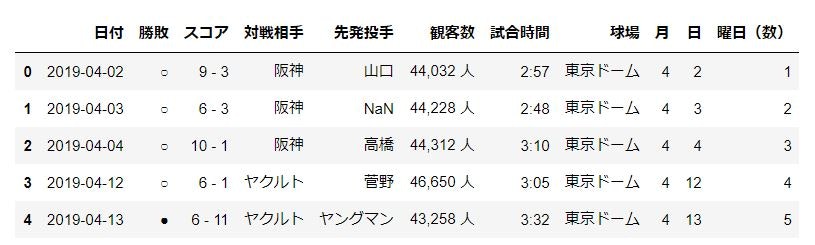
観客数の処理
- 「,」と「人」をreplace
- fillnaでNaNを0で埋める
- 型を「int」に変更する
data_set["観客数"] = data_set['観客数'].replace(',', '', regex=True).replace(' 人', '', regex=True).fillna('0').astype(int)
data_set
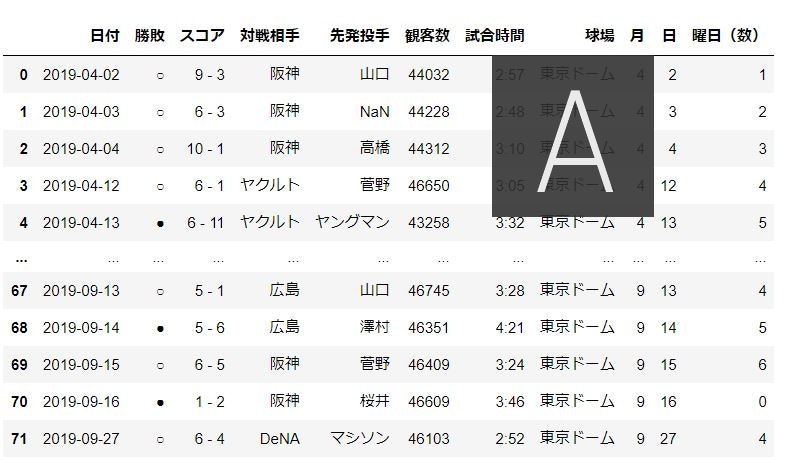
スコアの処理
- str.splitでスコアを二つに分ける
- カラムが2つに分かれるので、カラム名を付けて、int型に変換
data_set_score = pd.concat([data_set, data_set['スコア'].str.split(' - ', expand=True)], axis=1)
data_set_score_rename =data_set_score.rename(columns={0:'得点', 1:'失点'})
data_set_score_rename['得点']=data_set_rename['得点'].replace('中止', 0).astype(int)
data_set_score_rename['失点']=data_set_rename['失点'].fillna(0).astype(int)
postgreSQLへの接続
connection_config = {
'user': '*****',
'password': '*****',
'host': '*****',
'port': '****', # なくてもOK
'database': '*****'
}
engine = create_engine('postgresql://{user}:{password}@{host}:{port}/{database}'.format(**connection_config))
postgreSQLへ保存
- DataFrame.to_sql
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html
data_set_score_rename.to_sql('giants',schema='baseball_2019', con=engine, if_exists='replace', index=False)
個人的にはここでつまづきました。何につまづいたのかというと、スキーマ名を指定する方法がわからなかったです。公式ドキュメントを読んですぐに解決しましたが、解決するまで1時間くらいかかりました。わからないときってほんと、わかんないですよねー。
以上になります!記載内容で間違いなどありましたら、優しく教えていただけると嬉しいです!