この記事はCrowdWorks Advent Calendar 2016、15日目の記事です。
今回はCrowdWorksにおけるElasticsearch利用について紹介したいと思います。
はじめに
CrowdWorksはRailsで作られた仕事のマッチングサービスです。
働くワーカーさんがお仕事を探す場合や、お仕事を依頼したいクライアントさんがワーカーさんを探すための検索にElasticsearchを利用しています。
検索対象のデータはMySQL(Amazon RDS)に永続化されており、これをElasticsearchに同期する形で利用しています。
Elasticsearchの運用
Elasticsearchの運用はElastic Cloudを利用しています。
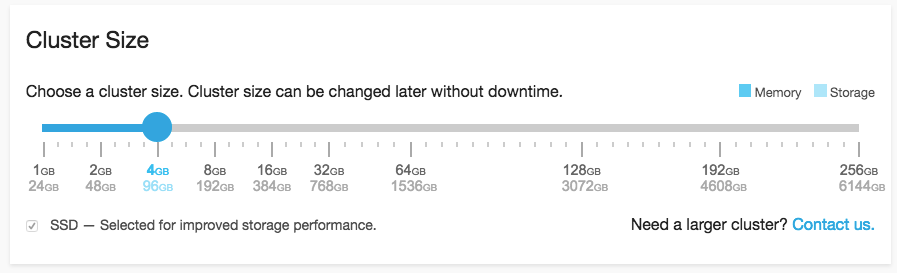
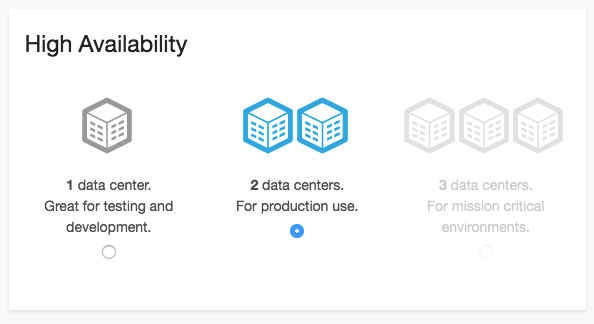
クラスタのスケールアップやバージョンアップ、プラグインの管理やセキュリティ設定がブラウザから簡単に設定できて便利です。
Elastic社本家のサービスだけあって新バージョンがリリースされた場合はリリースとほぼ同時に使うことができます(現在利用可能な最新バージョンは5.1.1)。
サポートは英語ですが問い合わせするとちゃんと対応してくれます。つい先日までElasticsearchがHTTPステータス502などでつながらないことがときどき起きており、こちら側では対処できないため問合せたところ調査していただき直してもらいました。
その他、ユーザー辞書のアップロードを可能にするといったこともサポート経由でお願いしています。こちらはデフォルトですべてのアカウントで有効にすべきかElastic社内で検討中のようですが、直近の対応はないようです(参考)。
バージョンアップ時の注意
UIで簡単にバージョンアップできるのは便利なのですが、実行するとマイナーアップデートであっても短い時間ですがサービスに繋がらなくなるので危険です。実際に先日、バージョン2.4.1から2.4.2へのアップデート時にこれをやってしまい10秒〜1分程度サービスが利用できないという障害になってしまいました。
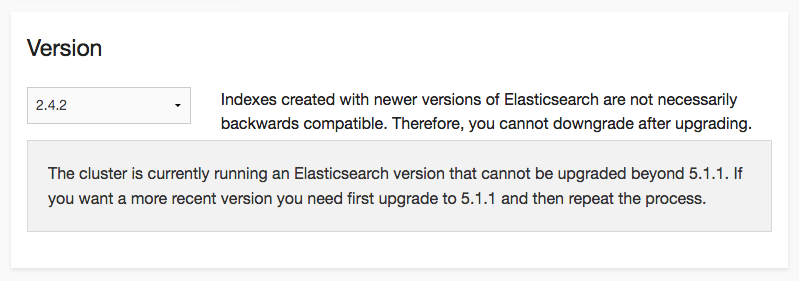
※追記: Elastic Cloudのエンジニアの方に聞いたところマイナーバージョンアップでは通常起こらないので原因調査のためフォーラムで問い合わせて欲しいとのことでした。
Railsアプリケーション側の実装
RailsからのElasticsearch利用はelasticsearch-rails、elasticsearch-modelを利用しています。
特にelasticsearch-modelによってマッピングを定義することで、メタデータとしてのマッピングの反映とそのマッピングを元にした実データの登録を一貫して行うことができて便利です。
データ更新と同期
検索対象のデータが更新された場合は、各レコードの更新毎にElasticsearch側に同期しています。
更新用のジョブを登録し、そのジョブをアプリケーションとは別のワーカープロセスが実行する形です。
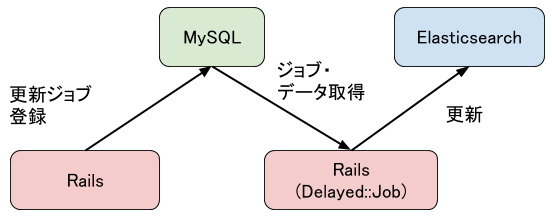
ただ、上記の同期がうまくいかないことがあるためデータがきちんと同期されているかをチェックし、同期されていなければ同期するバッチを定期的に流しています(20分ごと)。現状のデータ同期はこれに頼っていることが多いです。
マッピングの更新
検索対象のフィールドを追加したいなどマッピングの更新したい場合は再度インデックスを作り直す必要があるため、アプリケーション側では直接インデックス名を参照せず、エイリアスを参照するようにしています(インデックスにはタイムスタンプ付きで名前を付ける)。
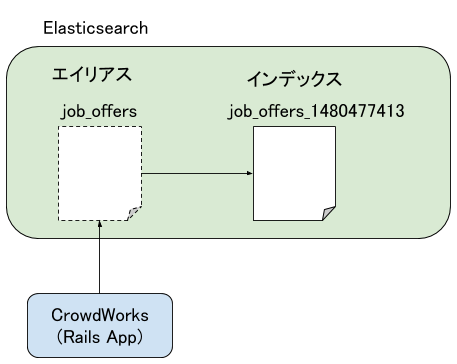
マッピング変更によるインデックス再作成は、次のような処理をスクリプトで行っています。
- 新しいマッピングで新たにインデックスを作る(データはMySQLから同期)
- このとき開始時間を記憶しておく
- インデックス生成がおわったらエイリアスを新インデックスを指すようにする
- 新インデックス作成開始時点から更新されたレコードがないかをチェックし、更新されたレコードは新インデックスに反映させる
- すぐ検索できるようRefreshを実行する
検索の実行
検索に関してはアナライザにkuromojiプラグインを利用したキーワード検索とその他フィルタリング条件を加えたシンプルなもので、これまで特にチューニングせずにやってきました。
現在スコアリングやユーザー辞書による検索精度の向上を進めていますので、何か成果が出た際にまた紹介できればと思います。
また、条件の数や組み合わせが増えてメンテナンスしにくくなっているのが現状の課題としてあります。
まとめ
簡単にですがCrowdWorksのElasticsearch利用について紹介しました。
明日は@ouraさんによる「いろいろやるチーム」です。よろしくお願いします。