自分はジャニーズの曲をたまに聴くんですが、周りの友達や同僚と話していても、ジャニーズの曲を聴いてる男性ってあまりいないんですよね。もちろん好みなんて人それぞれですが、ジャニーズにも結構いい曲あるのにな、なんて思ったりします。
そのせいか、真面目にジャニーズの情報を数字でまとめているサイトって少ないです。多くの男性エンジニア(というか多分アフィリエイター)が、ジャニーズに**「興味がない」ことに加え、ウェブ上で「お金にしにくい(広告案件がない)」**ので、モチベーションが湧かないのかもしれません。
でも日本中にジャニーズファンはたくさんいますし、自分も気になったぐらいですから、情報としては大いに需要があるはずなんですよね。なので、今回はジャニーズの主要グループのCD売上枚数をグラフで可視化してみました。
対象グループ
年代流行のサイトでまとめられている以下のグループを対象とします。
- SMAP
- TOKIO
- KinkiKids
- V6
- 嵐
- NEWS
- 関ジャニ∞
- KAT-TUN
- Hey! Say! JUMP
- Kis-My-Ft2
※前提事項
・上記以外にもいくつか主要グループがあると思いますが、上のサイトに載ってないので対象外にしました。
・サイト上に載っていない曲やデータが不正(枚数データが整数でない、日付がおかしいなど)な場合は、計算の対象外としていますので、載せている結果は精緻な値ではありません。あくまで傾向を知る程度の参考情報としてご覧ください。
・J-POP全体ではネット配信が伸びてきてますが、ジャニーズの曲はネット配信はほとんどないので、CDに絞ってます。
シングルCD売上枚数の取得
たったこれだけのコードで取得できます。このあたりのPythonの手軽さと充実さが良いですね。
import pandas as pd
df = pd.read_html('https://nendai-ryuukou.com/artist/003.html')[0] #データ取得
df.columns = ['date', 'title', 'count'] #列名を指定
df = df.drop([0]) #不要な行を削除
例えば嵐のCD売上枚数一覧はこんな感じ。
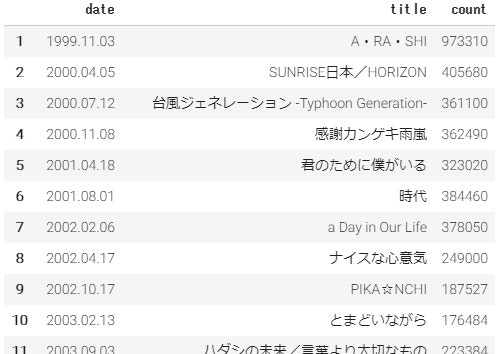
ちなみにたまに枚数データに文字列「万」が入っていますが、「万」を省いて1万倍してあげれば数値化できます。
def to_integer(count_str):
if '万' not in count_str:
return int(count_str)
else:
return int(float(count_str.replace('万', '')) * 10000)
to_integer('12.3万') # → 123000
df['count'] = df['count'].map(to_integer) #売上枚数文字列を数値に変換
各グループのシングルCD売上枚数一覧
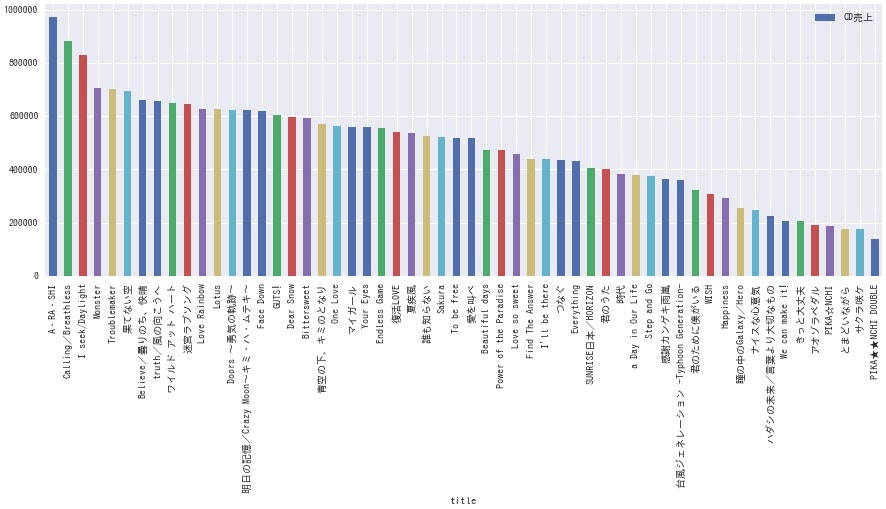
ここで、各グループごとに各シングルのCD売上枚数を棒グラフにしてみます。
df.sort_values(by='count', ascending=False).plot.bar(x='title', y='count', label='CD売上', figsize=(15, 5))
<嵐>
<SMAP>
<TOKIO>
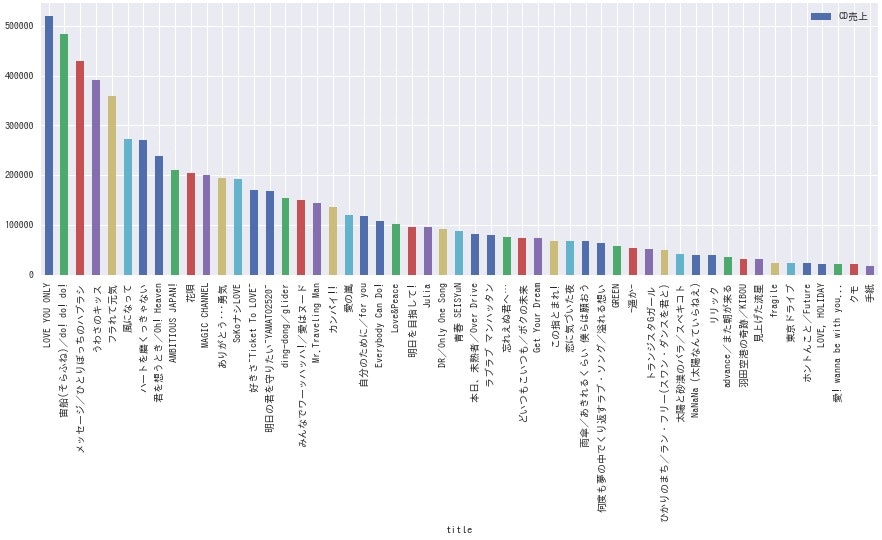
<KinkiKids>
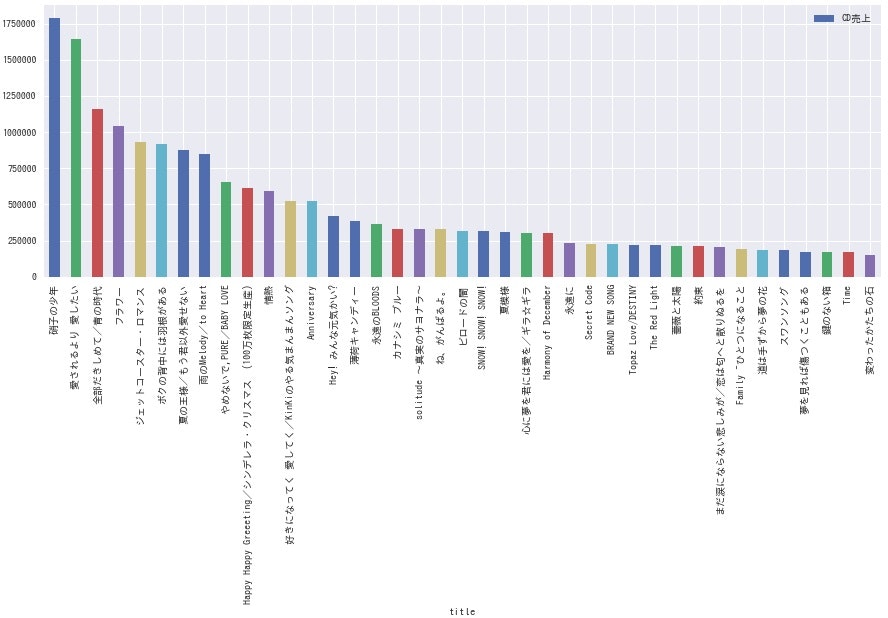
<V6>
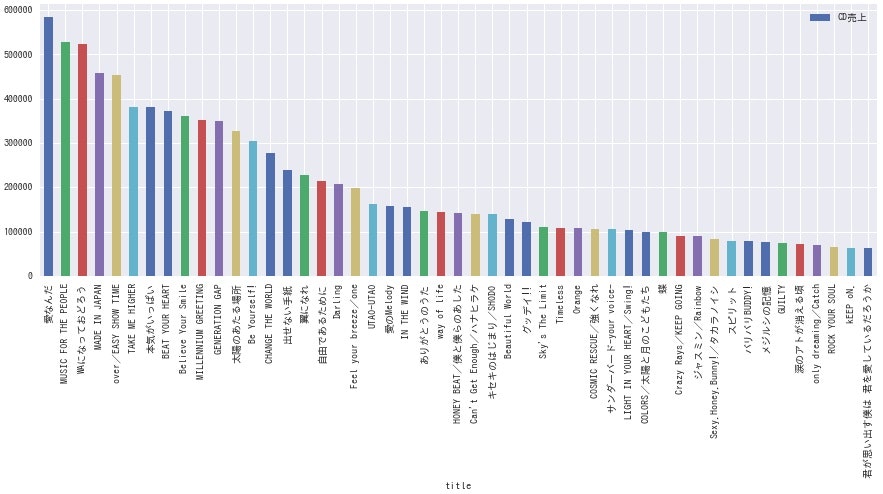
<NEWS>
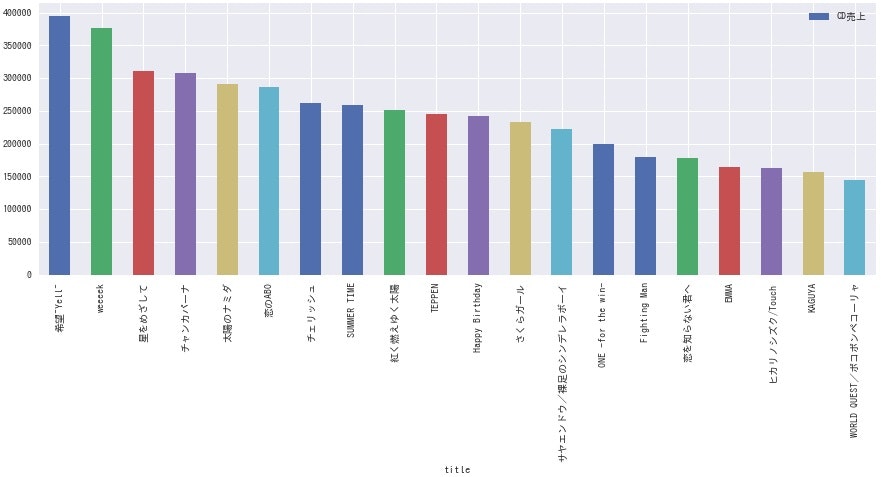
<関ジャニ∞>
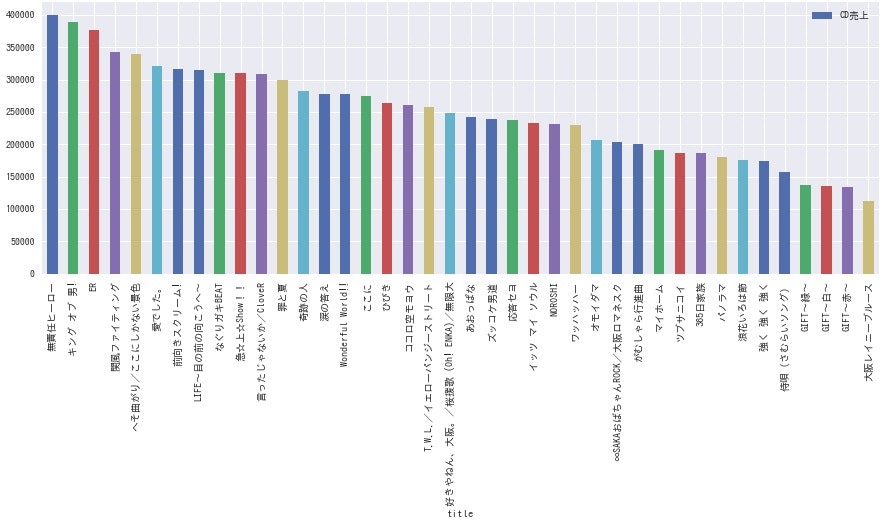
<KAT-TUN>
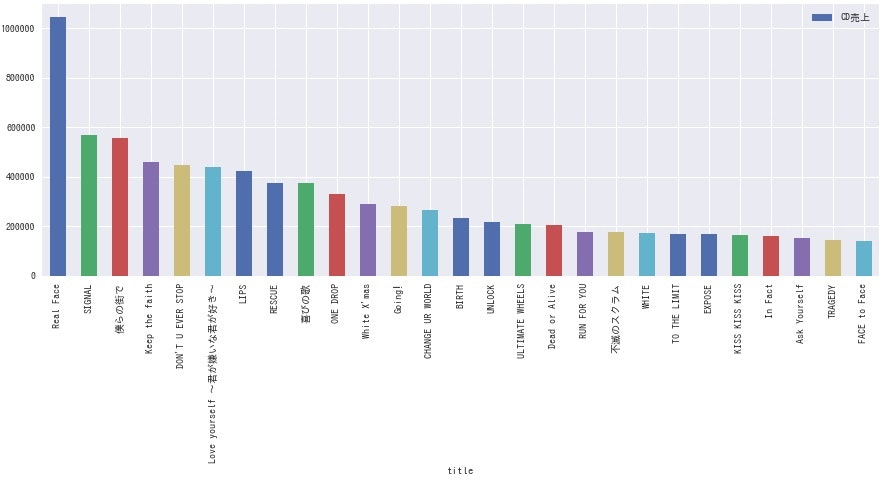
<Hey! Say! JUMP>
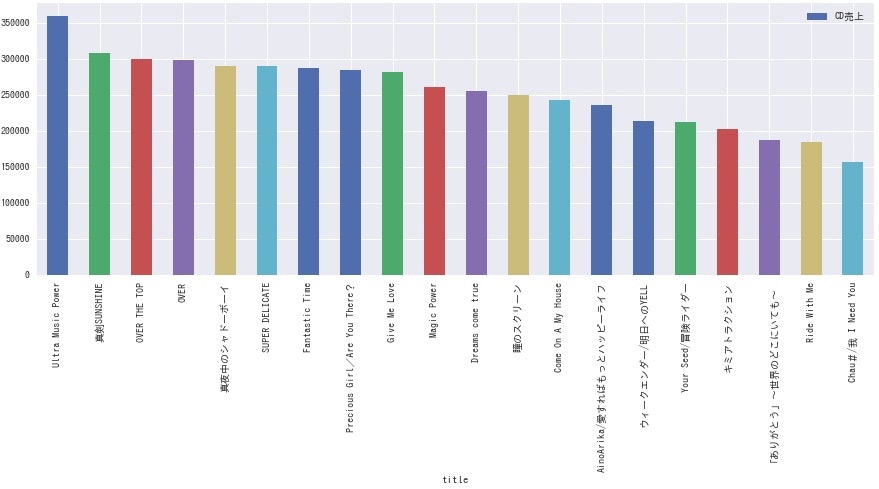
<Kis-My-Ft2>
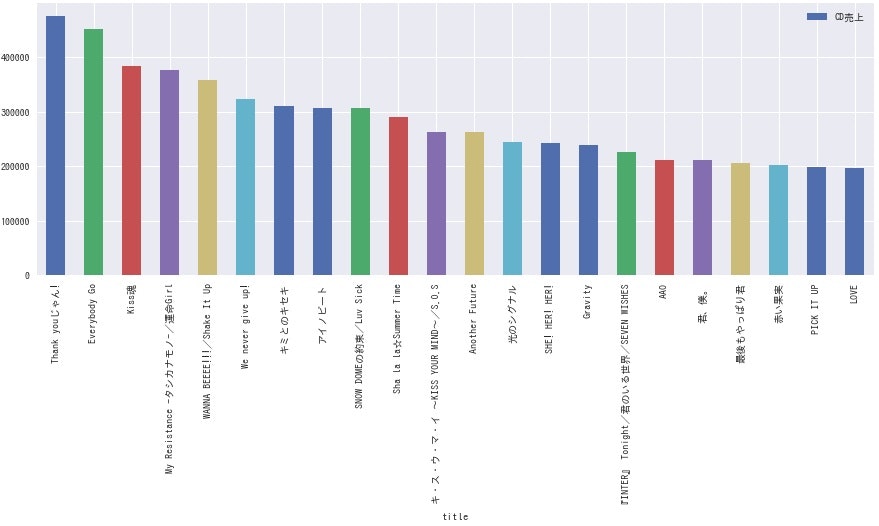
**どのグループも、曲によって結構な差がありますね。**全体的にデビュー曲の売上が高いようなので、デビュー時は事務所をあげて盛大に売り出している様子が伺えます。
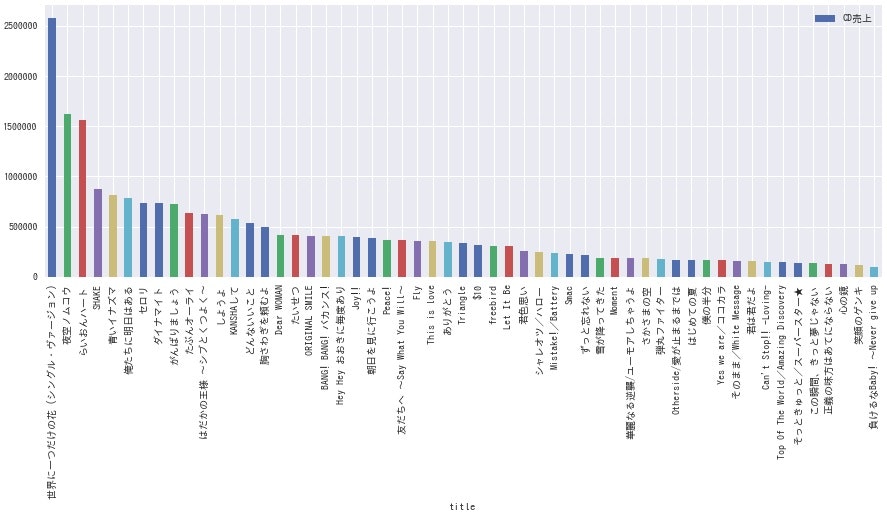
全グループまとめて売上枚数が多い順に20曲並べるとこうなります。
dfs = [df_arashi, df_v6, df_tokio, df_hey, df_kan, df_kat, df_kinki, df_news, df_kis, df_smap]
df = pd.concat(dfs) #各グループのDataframeを結合
df.sort_values(by='count', ascending=False)[:20].plot.bar(x='title', y='count', label='CD売上', figsize=(15, 5)) #ソートして上位20件取得
<全グループ売上トップ20曲>
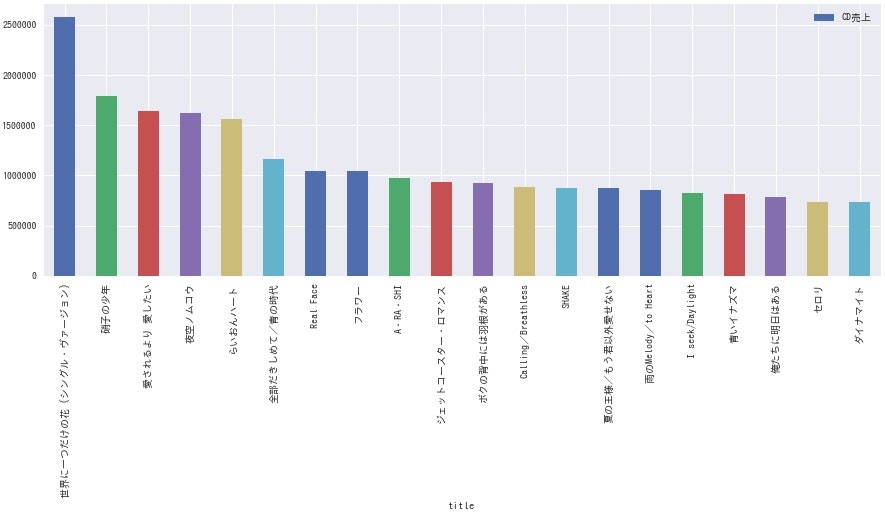
誰もが聴いたことのあるレベルの曲が上位に並びました。最近の曲は少ないですね。
各グループのシングルCD平均売上枚数
次に、各グループの売上枚数に対して平均をとってみます。
df.groupby('artist').mean().round().sort_values(by='count', ascending=False)
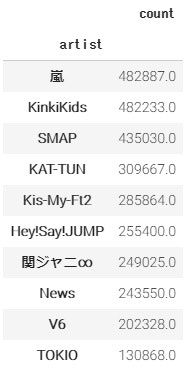
1曲ずつ見るとSMAPやKinkiKidsが圧倒的に強い曲を持っているにもかかわらず、平均で見ると嵐の底力が伺える結果になりました。
各グループのシングルCD売上推移
発売日の情報もあるので、各シングルの売上を時系列で見てみます。「発売日」にプロットしているので、継続的に売れている曲などはわかりませんが、大きな流れは見えるはず。
df['date'] = pd.to_datetime(df['date']) #日付文字列をDatetime型に変換(ここ重要)
df.plot(x='date', y='count', label='CD売上', figsize=(15, 5))
<嵐>
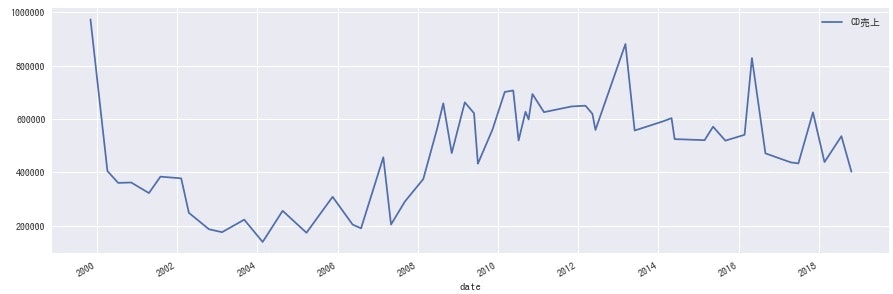
<SMAP>
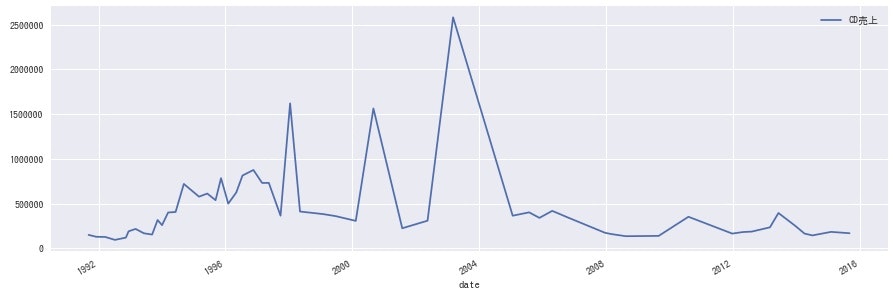
<TOKIO>
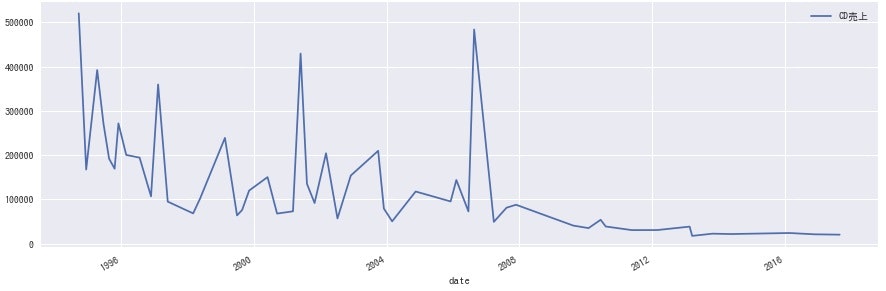
<KinkiKids>
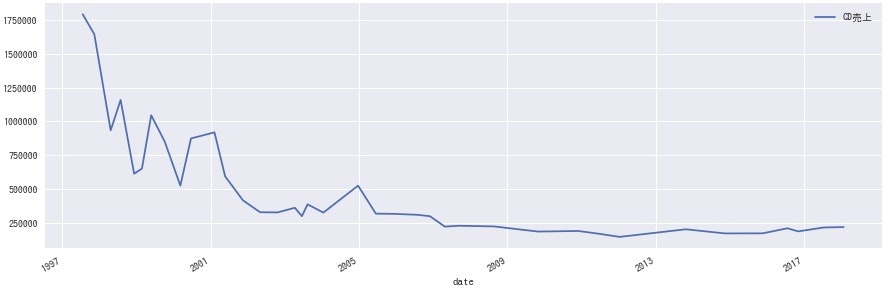
<V6>
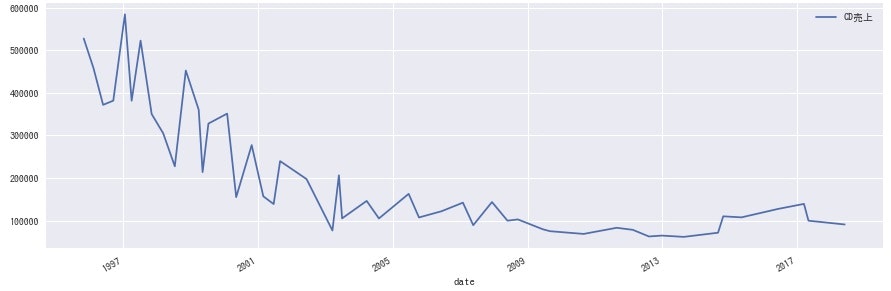
<NEWS>
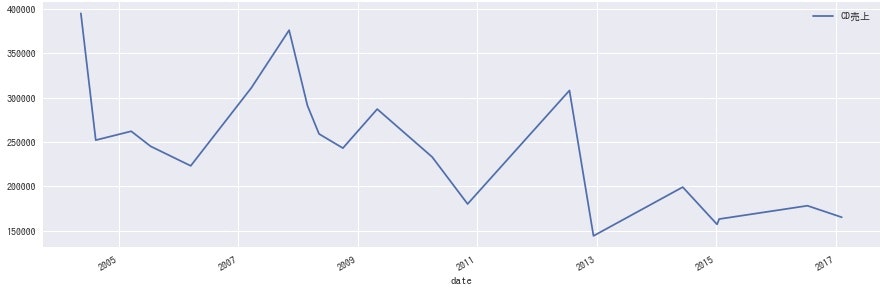
<関ジャニ∞>
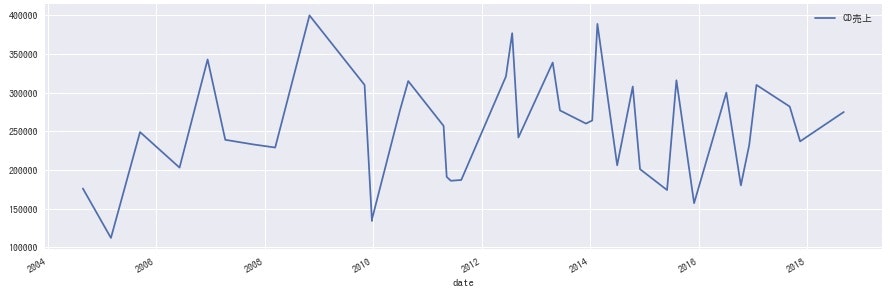
<KAT-TUN>
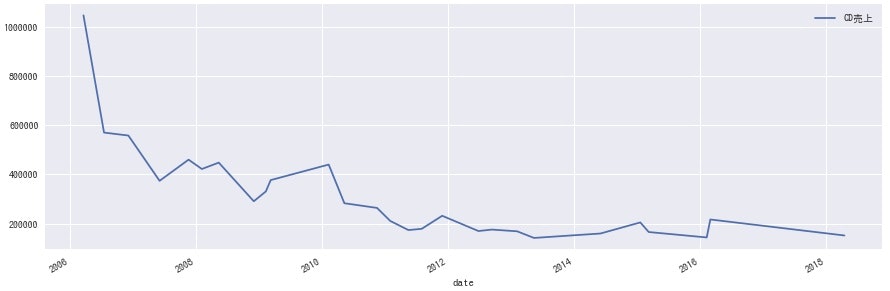
<Hey! Say! JUMP>
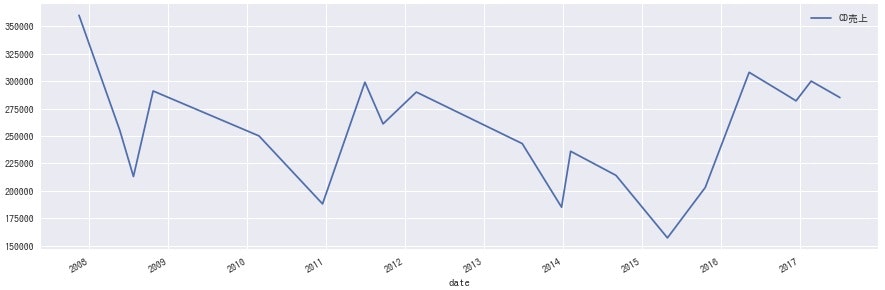
<Kis-My-Ft2>
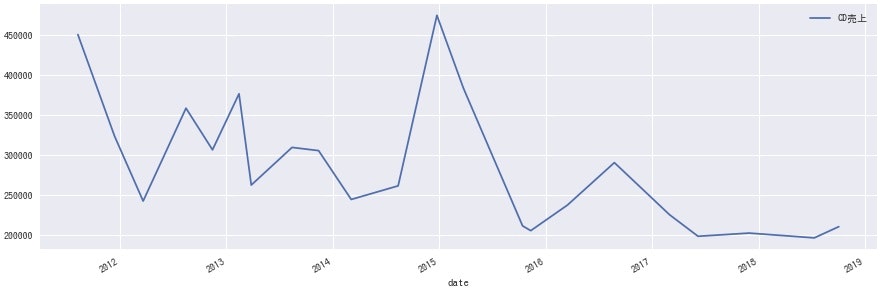
どのグループにも同じような波があるのかと思いきや、各グループ全然違うのは興味深いですね。事務所としての売り出し方が違うのか、数年経って熟成される良さに違いがあるのかなど、詳しい方に聞けたら面白そうです。
こちらも最後に、全グループまとめてプロットしてみます。時系列は揃えています。
def show_all_chart(dfs):
ax = None
for df in dfs:
if ax is None:
ax = df.plot(x='date', y='count', figsize=(15, 10))
else:
ax = df.plot(x='date', y='count', figsize=(15, 10), ax=ax)
plt.show
show_all_chart(dfs)
<全グループ時系列グラフ>
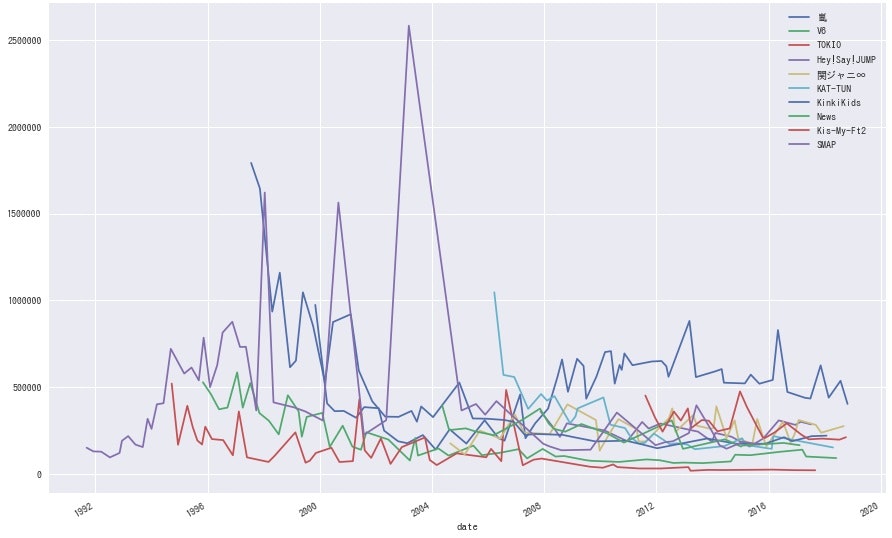
SMAPの山でかいなコレ。。全体で見ると、今より昔のほうがヒット曲の波がとてつもなく大きかったことがわかります。そして後半は、やはり嵐の安定した強さが際立っています。
全アーティストのシングルCD売上推移
もう少し分析っぽく、発売月と売上の散布図なんかも作ってみたんですが、特に傾向っぽいものがなかったので載せるのは控えます。
とはいえこれで終わるのも寂しいので、**最後におまけとして、ジャニーズ以外も含めた全てのアーティストの時系列データを調べてみます。**対象は先程のページに載っていたアーティストです。(最近VSCodeにjupyter notebookがデフォルト入りしたようなので、使ってみました)
<全アーティスト時系列グラフ>
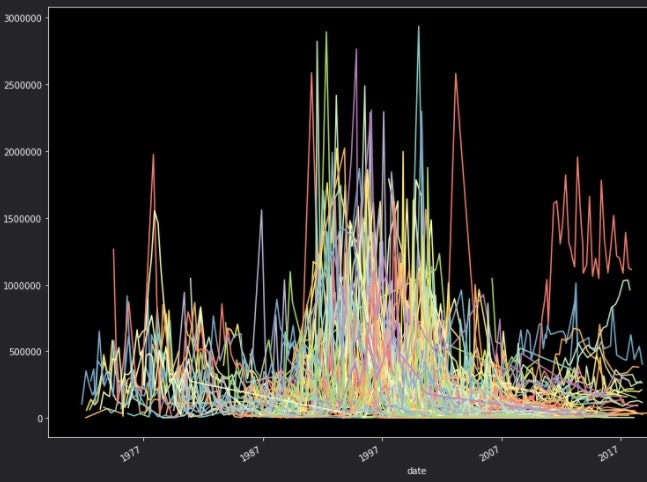
なんか花火みたいできれいですね。
全体で見るとよりハッキリとわかりますが、**真ん中あたりに大きな山があります。**CD市場の変化が如実に現れた結果でしょう。**後半は市場低迷(ネット配信の増加)により小さくなるのは当然とはいえ、ここまで違うとは。**テレビの影響力が落ちてきているのも大きいような気がします。
あとがき
コード的には数分で書けて技術的に珍しくもない記事でしたが、その分コスパは良い内容かなと思い、試しに書いてみました。前回の簡易版みたいなものです。
今回はCDだけでしたが、**ネット配信の増加傾向も含めて全アーティストをデータ分析できたら、今後の見通しなども見えてもっと面白くなると思います。**アーティストの人数、平均年齢、活動年数、発売タイミングやその他もろもろの違いから、売上との相関を見つけたりもできるかも(僕はやりませんけど!)。
なお、今回まとめた情報は、あくまで「シングルCDの売上枚数」です。それは、音楽アーティストの数ある収入源(シングル/アルバムCD・DVD・ネット配信、テレビ番組・CM・雑誌などのメディア出演、ライブのチケットやグッズ、ファンクラブ会費など)の中のごく一部です。きっとグループごとに注力しているポイントが違うので、他の売上を見たら全然違う結果が見えてくるかもしれません。