株や競馬など、**直接的にお金に絡むデータは、ネット上を探せばすぐに見つかりますが、そうでないものは意外と見つかりにくいものです。**例えば今回の題材、「吹奏楽」についてもそう。
**吹奏楽の全国大会は、高校野球でいうところの甲子園とも言われます。**本気で吹奏楽をやっている学生なら誰しも憧れる、夢の舞台。テレビや漫画やアニメなど、様々な形でしばしば取り上げられています(2019年春にも『劇場版 響け!ユーフォニアム~誓いのフィナーレ~』が公開とか)。
それなのに、具体的なデータは少なく、活用しようにもピンとこないものばかり。平成も終わりが近づいてきましたので、今回は吹奏楽コンクールの情報(平成1年〜30年分)を集めてデータ分析してみようと思います。
分析したこと
- 何割の高校が全国へ行けるの?
- どこの都道府県が強いの?
- 全国へ行きやすい曲ってあるの?
-
演奏順は結果に関係するの?
その他もろもろ
全国を目指す吹奏楽部の学生や顧問の方々だけでなく、吹奏楽を知らない人やエンジニアの方々にも楽しめそうな内容を意識して書いてみましたので、ぜひご覧ください。
分析対象
Musica Bellaさんの吹奏楽コンクールデータベースから、**高校(A部門)の支部大会30年分のデータを抽出(スクレイピング)**し、活用させていただきました。調べてみてわかりましたが、このサイト、データがすごく綺麗にまとまっています…圧倒的感謝…!!
吹奏楽に詳しくない方向けに補足すると、吹奏楽コンクールは
- 地区大会
- 都道府県大会
- 支部大会
- 全国大会
といった流れで大会があり、支部大会で代表に選ばれた者のみが全国大会に出場できます。詳しく解説されているサイトもあるので興味があればご覧ください。今回の分析対象は3の支部大会のデータです。
下準備(スクレイピング)
最初に、スクレイピングして必要なデータを集めます。特別なことはしていませんので、ポイントだけ記しておきます。
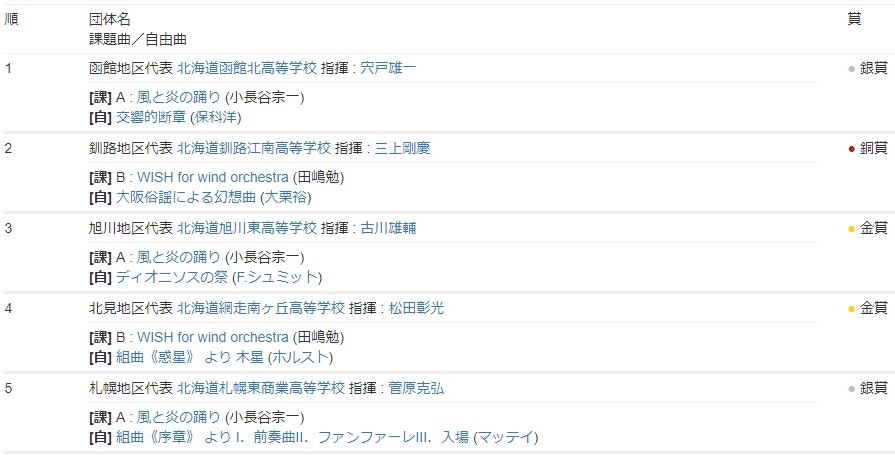
サイト上はこんなテーブルになっています。スクレイピング後、下記のようなDataFrame(トップ5行を表示)になりました。ちなみにサイトの表はtableタグではなくdivタグで書かれているので、自分で規則性を見つけてマッチングする必要がありました。
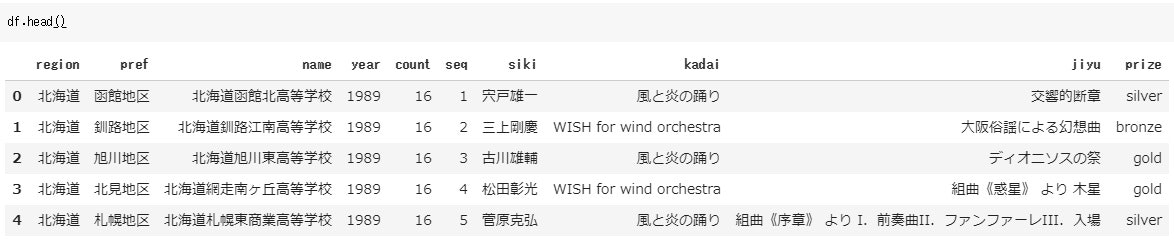
また、prize(賞)は「silver」や「gold」のままだと集計しにくいので、**ダミー変数(1 or 0 の変数)に変換。**加えて、高校名が変わった高校については高校名を統一しておきます。
# 賞をダミー変数へ
df = pd.get_dummies(df, columns=['prize'], prefix='', prefix_sep='')
# 高校名称統一(わかっているものだけ)
df = df.replace('大阪府立淀川工業高等学校', '大阪府立淀川工科高等学校')
これで下準備が整いました。DataFrameはこんな感じ。
ではここから分析結果を見ていきます。
※コードは最低限結果が表示できる程度のシンプルな形で書いていますが、結果は見やすいようにさらにラベル等を加工したものを貼り付けていますのでご認識ください。
支部大会の総出場校数(2018年)
df2018 = df.query('year == "2018"')
len(df2018)
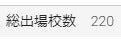
今年の支部大会全ての総出場校数は220校です。**仮に47都道府県で割っても1県につき4〜5校。**支部大会に出るだけでも、かなり厳選されているのがわかります。
全国出場校の割合(2018年)
# 代表(全国大会進出)数、金賞数、銀賞数、銅賞数
df2018[['zenkoku', 'gold', 'silver', 'bronze']].sum()
# 円グラフで表示
df2018[['zenkoku', 'gold', 'silver', 'bronze']].sum().plot.pie(counterclock=False, startangle=90, subplots=True, autopct="%1.1f%%")

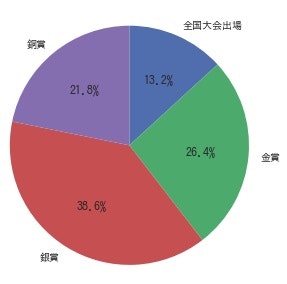
そのうち**全国へ行けるのは13%です。やっとの思いで支部大会まで漕ぎ着けても、代表になれるのは10校中1〜2校。**ちなみに30年トータルで見ると…
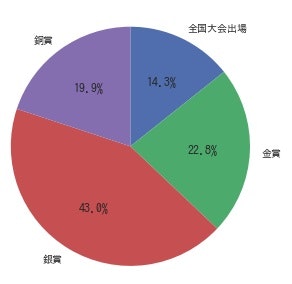
やっぱり**14%**程度。大して変わっていないようですね。
※ちなみに「全国大会出場」は「金賞」には含めていません。
全国経験有無の割合(過去30年)
# 高校名で集計
zenkoku_sum = df.groupby('name')[['zenkoku']].sum()
# 全国経験校数を合計
zenkoku_rate = pd.Series([
len(zenkoku_sum.query('zenkoku > 0')),
len(zenkoku_sum.query('zenkoku == 0'))
], index=['経験あり', '経験なし'])
zenkoku_rate
# 円グラフで表示
zenkoku_rate.plot.pie(counterclock=False, startangle=90, subplots=True, autopct="%1.1f%%")

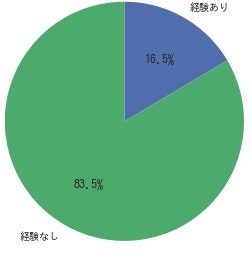
**過去30年間で、支部大会まで出場している全ての高校のうち、全国まで行けた高校は、たったの16.5%。**常連が幅を利かせているんですね。思ったより狭き門。
※以降は全て過去30年のトータルの分析結果です。
強豪校の全国出場回数と出場率
全国への道のりの厳しさを理解したところで、強豪校と呼ばれる高校について調べてみます。
# 集計対象年度数(1989~2018)
year_count = df['year'].value_counts().count()
# 高校名で集計
byname = df.groupby('name')[['zenkoku', 'gold', 'silver', 'bronze']].sum()
# 全国割合の列追加
byname = byname.assign(zenkoku_rate = round(byname['zenkoku'] / year_count * 100, 1))
# ソートして表示
byname.sort_values((['zenkoku', 'gold', 'silver', 'bronze']), ascending=False)[:15]
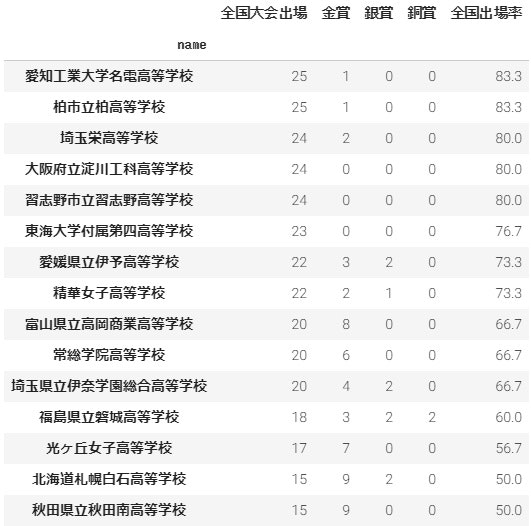
トップは「愛知工業大学名電高校」と「柏市立柏高校」で、80%超え。**5回に4回は全国に行っているわけです。**他にも「埼玉栄高校」や「淀川工科高校」、「習志野高校」といった実力校が名を連ねました。
支部ごとの全国出場校の割合
支部単位で、全国出場校の割合の差異を比較してみます。
※関東支部は1995年より東関東と西関東に別れたので、1994年までのデータです。
# 支部で集計
byregion_sum = df.groupby('region')[['zenkoku', 'gold', 'silver', 'bronze']].sum()
# 全国割合の列追加
byregion_rate = byregion_sum.assign(
total = byregion_sum['zenkoku'] + byregion_sum['gold'] + byregion_sum['silver'] + byregion_sum['bronze'],
zenkoku_rate = round((byregion_sum['zenkoku'] / (byregion_sum['zenkoku'] + byregion_sum['gold'] + byregion_sum['silver'] + byregion_sum['bronze'])) * 100, 1)
)
# ソートして表示
byregion_rate.sort_values((['zenkoku_rate']), ascending=False)
# 棒グラフ表示
byregion_rate['zenkoku_rate'].sort_values(ascending=False).plot.bar(alpha=1.0, figsize=(12,5))
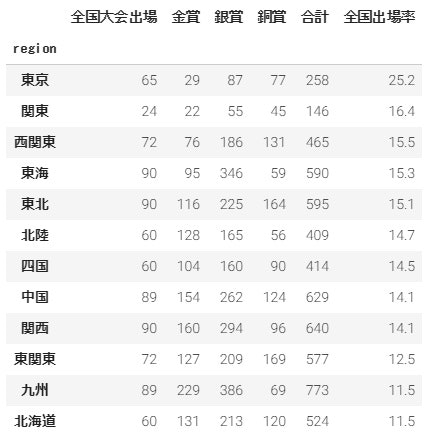
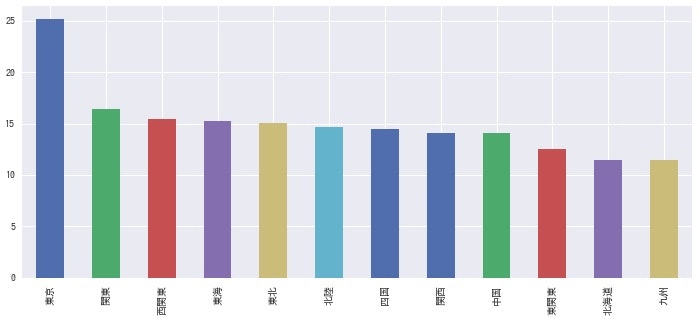
なぜか東京支部だけ全国出場率が高いのが気になります。確かに2018年の東京支部だけで見ても12校中3校が代表なので、25%でした。高校数が多い故の配慮?
都道府県ごとの全国出場回数
都道府県単位で、全国出場数を比較してみます。
# 北海道(prefに「~地区」を含む)のSeries作成
hokkaido_sum = df[df['pref'].str.contains('地区')]['zenkoku'].sum()
hokkaido = pd.Series(['北海道', hokkaido_sum], ['pref', 'zenkoku'])
# 北海道以外を都道府県で集計
bypref = df[~df['pref'].str.contains('地区')].groupby('pref')['zenkoku'].sum().reset_index()
# 北海道分を追加
bypref = bypref.append(hokkaido, ignore_index=True)
# ソートして表示
bypref.sort_values(by='zenkoku', ascending=False).plot.bar(y='zenkoku', alpha=1.0, figsize=(17,5), x='pref')
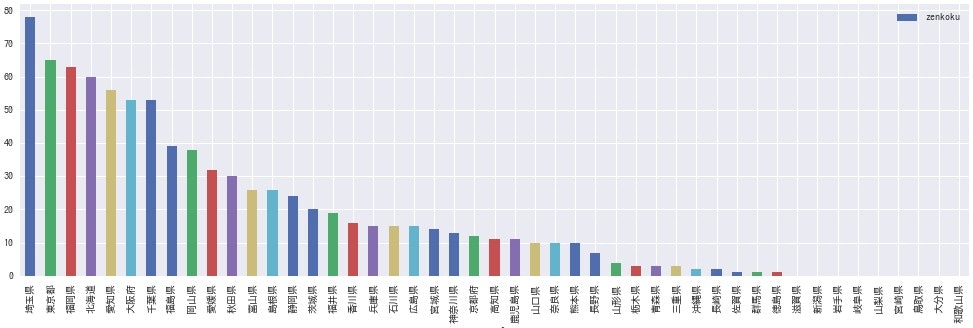
都道府県別で見ると、こんなに差があるんですね(見にくければ画像を拡大してご覧ください)。やっぱり**高校数が多い県は強い高校が多いと考えられるので、全国大会出場回数も多いのかな?**と思ったので、各県の高校数(吹奏楽部有無を考慮せず全て)を折れ線グラフでプロットしてみます。
# 高校数のDataFrame作成
school_count = pd.DataFrame({
'pref': ['北海道','青森県','秋田県','岩手県','宮城県','山形県','福島県','栃木県','群馬県','茨城県','埼玉県','千葉県','東京都','神奈川県','山梨県','長野県','新潟県','富山県','石川県','福井県','静岡県','愛知県','岐阜県','三重県','滋賀県','京都府','大阪府','兵庫県','奈良県','和歌山県','岡山県','広島県','山口県','鳥取県','島根県','徳島県','香川県','愛媛県','高知県','福岡県','佐賀県','長崎県','熊本県','大分県','宮崎県','鹿児島県','沖縄県'],
'sc_count': [283,78,55,80,95,62,111,75,81,120,196,183,429,235,42,99,103,53,56,35,138,222,81,72,60,106,258,207,53,48,86,130,80,32,47,38,40,66,46,165,45,79,76,55,53,89,64]
})
# 上のDataFrameと結合
merge = pd.merge(bypref, school_count, left_on='pref', right_on='pref').sort_values(by='zenkoku', ascending=False)
# 同じグラフにプロット
ax = merge.plot.bar(x='pref', y='zenkoku', ylim=(0, 80), legend=False)
ax2 = ax.twinx()
merge.plot(x='pref', y='sc_count', ax=ax2, ylim=(0, 450), color="green", figsize=(17,5), label = '高校数')
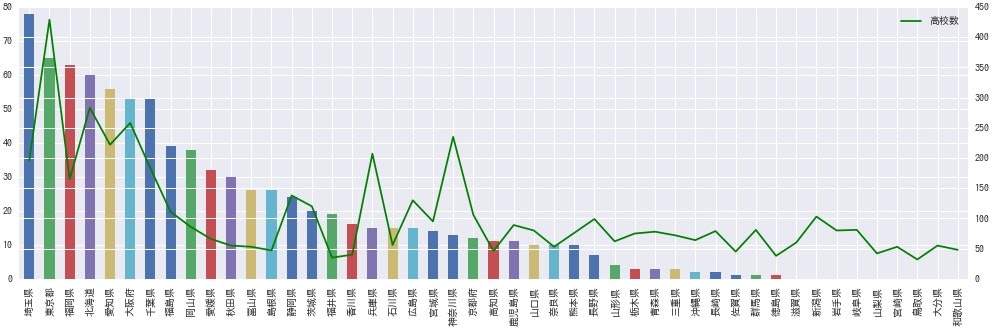
上位の都道府県は、全国出場回数と高校数がやや関係してそうにも見えますが、**思ったより相関はないみたい。**また、兵庫県や神奈川県は、高校数の割には全国に行けていないのが気になります。支部大会に出る前の時点で絞られてしまうのでしょうか。枠を増やした方が良いようにも見えます。
全国出場率の高い自由曲
演奏者たちの悩みどころとなる自由曲。30年間で演奏された全1585曲の自由曲のうち、全国大会に行った高校が多い曲を調べてみました。なお、対象は20回以上演奏されている曲に絞っています。
# 自由曲で集計
byjiyu_sum = df.groupby('jiyu')[['zenkoku', 'gold', 'silver', 'bronze']].sum()
# 全国割合の列追加
byjiyu_rate = byjiyu_sum.assign(
total = byjiyu_sum['zenkoku'] + byjiyu_sum['gold'] + byjiyu_sum['silver'] + byjiyu_sum['bronze'],
zenkoku_rate = round((byjiyu_sum['zenkoku']/(byjiyu_sum['zenkoku'] + byjiyu_sum['gold'] + byjiyu_sum['silver'] + byjiyu_sum['bronze'])) * 100, 1)
)
# 20回以上の曲をソートして表示
byjiyu_rate.query('total > 20').sort_values(['zenkoku_rate'], ascending=False)[:20]
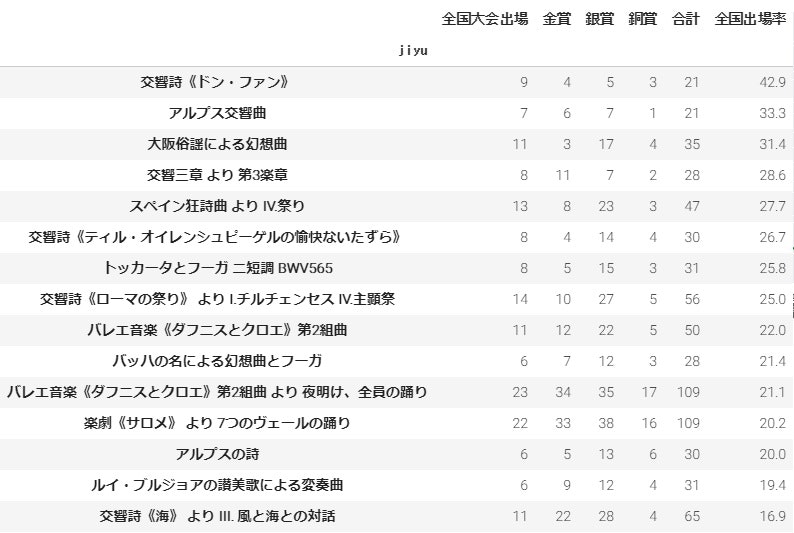
**『交響詩《ドンファン》』、『アルプス交響曲』などが上位に。全国出場回数という意味では、『バレエ音楽《ダフニスとクロエ》第2組曲 より 夜明け、全員の踊り』や『楽劇《サロメ》 より 7つのヴェールの踊り』**なども多いですね。
もちろん、実力のある高校がよく演奏する曲は上位に来るので、どの高校にも当てはまるというわけではないですが、参考情報としては面白いと思います。
全国出場率の高い演奏順
くじ引きで決まる演奏順。自分で決めることができないとはいえ、実データとして結果に影響するものなのか気になるところです。早い順番だと不利という話はよく聞きますが、果たして本当なのでしょうか。
まずは十分なデータのある、出場校数が12の場合の結果を散布図で見てみます。横軸が演奏順、縦軸が全国出場率(%)です。
# 出場校が12の場合
byseq_sum = df.query('count == 12').groupby('seq')[['zenkoku', 'gold', 'silver', 'bronze']].sum()
# 演奏順で集計(12校出場)
byseq_rate = byseq_sum.assign(
total = byseq_sum['zenkoku'] + byseq_sum['gold'] + byseq_sum['silver'] + byseq_sum['bronze'],
zenkoku_rate = round((byseq_sum['zenkoku']/(byseq_sum['zenkoku'] + byseq_sum['gold'] + byseq_sum['silver'] + byseq_sum['bronze'])) * 100, 1)
).reset_index()
# 散布図で表示
byseq_rate.plot.scatter(x='seq', y='zenkoku_rate')
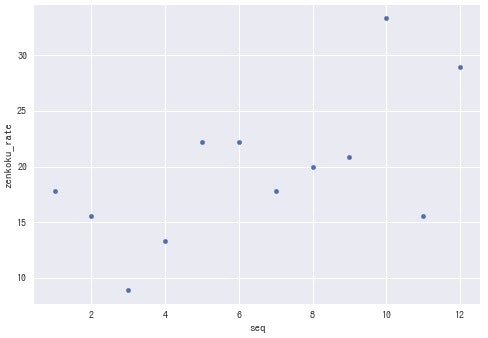
確かに、**演奏順が早い方(左側)が全国出場率が低く、遅い方(右側)は高く見えますね。**では、同様に出場校数が21の場合の結果を見てみます。
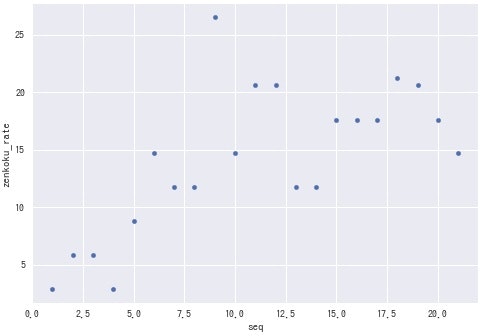
こちらも演奏順が後半なるにつれて、全国出場率が高くなっているように見えます。では最後に、演奏順を出場校数で割った値で全データをプロットしてみます。(演奏順を0~1の値に変換したものを横軸にしたもの)
# 順番/出場校数の列で集計
tmp = df.assign(seq2 = df['seq'] / df['count'])
byseq2_sum = tmp.groupby('seq2')[['zenkoku', 'gold', 'silver', 'bronze']].sum()
# 全国出場率列を追加
byseq2_rate = byseq2_sum.assign(
total = byseq2_sum['zenkoku'] + byseq2_sum['gold'] + byseq2_sum['silver'] + byseq2_sum['bronze'],
zenkoku_rate = round((byseq2_sum['zenkoku'] / (byseq2_sum['zenkoku'] + byseq2_sum['gold'] + byseq2_sum['silver'] + byseq2_sum['bronze'])) * 100, 1)
).reset_index()
# ソートして表示
byseq2_rate.plot.scatter(x='seq2', y='zenkoku_rate')
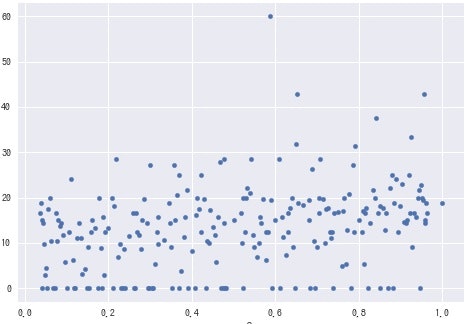
全体で見ても、わずかですが、**やや右肩上がりには見えますね。**確かにM-1グランプリなどを見ても、前半の点数は後半に比べてやや低めに採点されているように見えますからね。人間の心理が多少働くのはやむを得ないのでしょう。
ただ、**結局は演奏順は運で決まりますし、気にするほどの相関ではないと考えた方がいいでしょう。**早ければ気にしない、遅ければラッキー、程度ですね。
※スピアマンの相関係数でも優位性があるようでしたが、詳しくなく今回のケースに適しているのかわからなかったので載せてはいません。
おまけ:全国常連の指揮者トップ10
最後に、恐らく吹奏楽に携わる人なら気になる全国常連の指揮者トップ10を集計してみました。
# 指揮者で集計
bysiki_sum = df.groupby('siki')[['zenkoku', 'gold', 'silver', 'bronze']].sum()
# 全国出場率の列追加
bysiki_rate = bysiki_sum.assign(
total = bysiki_sum['zenkoku'] + bysiki_sum['gold'] + bysiki_sum['silver'] + bysiki_sum['bronze'],
zenkoku_rate = round((bysiki_sum['zenkoku']/(bysiki_sum['zenkoku'] + bysiki_sum['gold'] + bysiki_sum['silver'] + bysiki_sum['bronze'])) * 100, 1)
)
# ソートして表示
bysiki_rate.sort_values(['zenkoku', 'zenkoku_rate'], ascending=False)[:10]
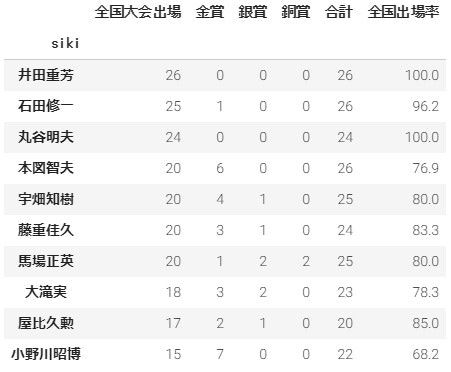
**100%とか実現できるものなんですね。**きっと彼らが指揮する高校は、全国に行くのは当然で、その先が目標なのでしょう。なかなか全国に行けず悩んでいる高校は、彼らの情報を調査してみると良いかもしれません。
あとがき
以上、吹奏楽コンクールの支部大会データをもとに、全国大会への道のりの難しさや、全国出場に相関しそうなものを調べてみました。
データ分析と書いておきながら、集計して可視化したぐらいなんですが、最近の機械学習の投稿は、似たような内容だったり、難しくてあまり一般向けに楽しめる内容じゃなかったりするものが多いので、まずは誰でもそれなりに楽しめるシンプルな内容を意識しました。
最後に「全国大会の金賞校を機械学習で予測」みたいなこともできるかなと思ったんですが、野暮かなと思ってやめました。賞の結果が全てではないですし、やっぱり最終的に結果を左右するのは、生徒たちの情熱ですので、それに水を差すのもよくないかと。
※細かく見ると多少のデータの抜けもありそうなのですが、大まかな結果には影響しないと思うのでご了承ください。