TL;DR
- ニューラルネットワークを使っても過学習の問題は起こるので、これを避けるために色々なアプローチがある
5.4 ヘッセ行列
省略
5.5 ニューラルネットワークの正則化
ニューラルネットワークの入力ユニットの数は入力データの次元数、出力ユニットの数は出力したいデータの次元数で決まる。
一方、隠れユニットの数$M$は調整可能なハイパーパラメータである。
$M$は重みとバイアスの数を制御することに注意すると、$M$が小さすぎると真の関数を表現することができず、適合不足となり、$M$が大きすぎると過学習が起きてしまうことが想像できる。
正弦関数の回帰問題で$M$の値がどのように影響するかを表したものが下図である。
$M$が小さすぎると適合不足、$M$が大きすぎると過学習していることが分かる。
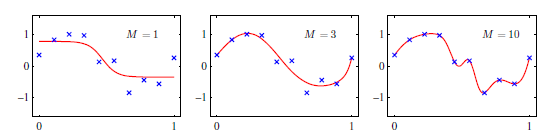
しかしながら、誤差関数には局所的極小点が存在するため、誤差の値は$M$の単純な関数にならない。
そこで、過学習を避けるための一方法として、比較的大きめな$M$を選んでおいて正則化項を誤差関数に追加するアプローチがある。
最も単純な正則化項は2次式であり、正則化誤差は:
$$
\tilde{E}(w) = E(w) + \frac{ \lambda }{2} w^T w \tag{5.112}
$$
で与えられる。この正則化項はweight decay (荷重減衰) として知られる。
5.5.1 無矛盾なガウス事前分布
ニューラルネットワークは入力変数の集合$ \{ x_i \} $を出力変数の集合$ \{ y_k \}$に写像するものという見方をし、2層のネットワークを考えよう。出力ユニットの活性化関数は恒等写像とする。
以下の式(5.113), (5.114), (A)での変数の右上の数字は、べき乗でなく何層目かを表す数字である。
第1層の隠れユニットの出力は
$$
z_j^1 = h \left( \sum_i w_{ji}^1 x_i + w_{j0}^1 \right) \tag{5.113}
$$
であり、出力ユニットの出力は
$$
y_k = \sum_j w_{kj}^2 z_j^1 + w_{k0}^2 \tag{5.114}
$$
である。今後の計算のため、この2式を1つにまとめると:
$$
y_k = \sum_j w_{kj}^2 \cdot h \left(
\sum_i w_{ji}^1 x_i + w_{j0}^1
\right) + w_{k0}^2 \tag{A}
$$
である。
さて、入力データや出力変数を以下のように線形変換した場合、その線形変換に応じてニューラルネットワークの重みとバイアスも線形変換すれば写像は変化しない(証明は以下の演習5.24で)。
(気持ち:入力を$a$倍に変換したならば、入力層から隠れ層への重みを$1/a$倍すれば出力は同じになる。また、出力を$c$倍に変換したならば、隠れ層から出力層への重みも$c$倍すれば変換後の出力になる)
同じ入力ユニット数、隠れユニット数、出力ユニット数のニューラルネットワークが2つあるとしよう。
(線形変換していない)もとのデータで訓練して得られたネットワークの重みとバイアスと、線形変換したデータで訓練して得られたネットワークの重みとバイアスが線形変換分だけ異なっているときに無矛盾であるという。
本質的には線形変換前も後も同じ解のはずなので、どんな正則化項でもこの無矛盾性を持つべきである。
しかし、式(5.112)の2次式による正則化項は無矛盾性をもっていない。
線形変換前のバイアスが0であるとき、正則化の影響を受けないのに対し、線形変換で非ゼロになると正則化の影響を受けることから明らかである。
無矛盾性をもつ正則化項を探したいという動機付けは以上である。
どうやって導出したかはテキストから省略されており、よく分からないが無矛盾性をもつ正則化項は下式で与えられるそうだ。
$$
\frac{ \lambda_1 }{2} \sum_{w \in W_1} w^2 + \frac{ \lambda_2 }{2} \sum_{w \in W_2} w^2
\tag{5.121}
$$
ここで、$W_1$は第1層の重みの集合、$W_2$は第2層の重みの集合である。
式(5.112)のようにすべての重みのベクトルの2乗$ w^T w $を層ごとに分けて、ハイパーパラメータ$ \lambda $も分ければうまくいくんだな~、ぐらいに理解しておく。
演習5.24:入力の線形変換に応じて重みとバイアスを線形変換すれば写像は変化しないことを示せ
入力データを
$$
x_i \rightarrow \tilde{x_i} = a x_i + b \tag{5.115}
$$
と線形変換する場合に、入力層から隠れ層への重みとバイアスを
\begin{align}
w_{ji} &\rightarrow \tilde{ w_{ji} } = \frac{1}{a} w_{ji} \tag{5.116} \\
w_{j0} &\rightarrow \tilde{ w_{j0} } = w_{j0} - \frac{b}{a} \sum_i w_{ji} \tag{5.117}
\end{align}
と線形変化することでネットワークの写像が変化しないことを示す。
式(5.115)~(5.117)を式(A)に代入すると
\begin{align}
y_k &= \sum_j w_{kj} \cdot h \left(
\sum_i \frac{1}{a} w_{ji}( a x_i + b ) + w_{j0} - \frac{b}{a} \sum_i w_{ji}
\right) + w_{k0} \\
&= \sum_j w_{kj} \cdot h \left(
\sum_i ( w_{ji} x_i + \frac{b}{a} w_{ji} ) + w_{j0} - \frac{b}{a} \sum_i w_{ji}
\right) + w_{k0} \\
&= \sum_j w_{kj} \cdot h \left(
\sum_i ( w_{ji} x_i + w_{j0} ) + \frac{b}{a} \sum_i w_{ji} - \frac{b}{a} \sum_i w_{ji}
\right) + w_{k0} \\
&= \sum_j w_{kj} \cdot h \left(
\sum_i w_{ji} x_i + w_{j0}
\right) + w_{k0} \tag{A}
\end{align}
となり、式(A)と同じになることから同じ写像である。
演習5.24:出力の線形変換に応じて重みとバイアスを線形変換すれば写像は変化しないことを示せ
出力データを
$$
y_k \rightarrow \tilde{y_k} = c y_k + d \tag{5.118}
$$
と線形変換する場合に、入力層から隠れ層への重みとバイアスを
\begin{align}
w_{kj} &\rightarrow \tilde{ w_{kj} } = c w_{kj} \tag{5.119} \\
w_{k0} &\rightarrow \tilde{ w_{k0} } = c w_{k0} + d \tag{5.120}
\end{align}
と線形変化することでネットワークの写像が変化しないことを示す。
こちらは簡単である。式(5.118)~(5.120)を式(A)に代入すると
\begin{align}
c y_k + d &= \sum_j c w_{kj} \cdot h \left(
\sum_i w_{ji} x_i + w_{j0}
\right) + c w_{k0} + d \\
両辺からdを引いてcで割れば \\
y_k &= \sum_j w_{kj} \cdot h \left(
\sum_i w_{ji} x_i + w_{j0}
\right) + w_{k0} \tag{A}
\end{align}
となり、式(A)と同じになることから同じ写像である。
5.5.2 早期終了 (early stopping)
正則化とは別の、過学習を抑えるテクニックとして早期終了 (early stopping) がある。
誤差関数の勾配$ \nabla E(w) $を使って重み$w$を更新するステップを反復すると、学習データ集合に対する誤差は減少していくことが期待できる。
しかし、(学習データとは別の)検証用データ集合に対する誤差ははじめのうちは減少していくものの、が途中から増加することがある。これは、ネットワークが過学習を起こしていることに起因する。
下図はその様子を示したもの。縦軸が誤差で横軸が学習の回数を示す。左の赤線は学習データ集合に対する誤差の変化であり、学習回数が増えるにつれ、減少したのちにほぼ一定になる。
右の青線は検証用データ集合に対する誤差。破線の位置までは誤差が減少しているものの破線を超えるとネットワークの過学習が始まり、誤差が増加している。
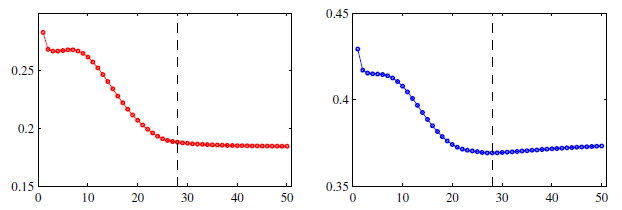
そのため、検証用データ集合での誤差が最小となったところで学習を終了するのが早期終了である。
Deep Learningライブラリでも検証用データ集合での誤差が数回連続で増加するようであれば、学習を終了させるといったようなことが行えるようになっている。
5.5.3 不変性
ニューラルネットワークに入力されるデータに多少の変化があっても、出力(判定結果)が変化しない、すなわち不変であることが求められるニーズは大きい。
例えば、手書き数字が書かれた画像を入力してその数字が何か(0から9までの10通り)を分類したい場合、書かれた数字が画像内のどのあたりであろうが同じ数字と分類する必要がある(平行移動不変性)。
あるいは、手書き数字のサイズにかかわらず同じ数字と分類する必要がある(尺度不変性)。
そのためには大きく4つのアプローチがある。
アプローチ1:学習データ集合を増やす
手書き数字が大きく映ろうが小さく映ろうが同じ数字と分類してほしいなら、手持ちの学習データから大きな数字の学習データと小さな数字の学習データを複製して、全部学習させればいい、というアプローチ。
Deep Learning領域ではごく一般的に使われているアプローチであり、data augmentation (データ拡張) と呼ばれる。
デメリットは(学習データ数が増えるので)計算量が増えること。
アプローチ2:前処理で不変な特徴量を抽出する
例えば数字の「8」を書かれた位置やサイズに関わらず分類したいなら、画像から数字の輪っかの数を抽出して特徴量とすることを思いつく(8の輪っかの数は2)。
こうすれば位置やサイズに関わらず特徴量の値は変わらないので、分類結果も変わらない。
ただし、必要な普遍性を持ち、かつ分類に有用な情報を失わない特徴量への変換を行う前処理の設計は職人芸であり、難しい。
5.5.4 接線伝播法
アプローチ3:入力の変化に対する出力の変化にペナルティ
入力データへの変化が連続(例えば平行移動や回転)ならば、入力空間上で変換前後のデータ座標も連続的に変化する。
入力次元(入力空間)が2次元である入力データ$x_n$を入力空間上に点を打った後、$x_n$を$\xi$だけ少しずつ回転させたときの$x_n$の座標点の軌跡は下図のようになるとイメージしよう。
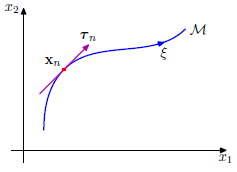
入力データが変化すると一般に出力も変化する。入力データへの微小な変化$\xi$を作用させたときの出力ユニット$k$の変化度合いは以下の微分で与えられる1。
\begin{align}
\left. \frac{ \partial y_k }{ \partial \xi } \right|_{ \xi=0}
= \left. \sum_{i=1}^D \frac{ \partial y_k }{ \partial x_i } \frac{\partial x_i}{\partial \xi} \right|_{\xi=0}
= \sum_{i=1}^D J_{ki} \tau_i \tag{5.126}
\end{align}
ここで$D$は入力データの次元である。
真ん中の辺の$ \partial y_k / \partial x_i $は出力の入力に関する微分であり、ヤコビ行列$J$で書き直すことができる。$J_{ki} $は$J$の$(k,i)$成分である。
また、真ん中の辺の$ \partial x_i / \partial \xi $は上図でいう赤線の接ベクトル$\mathbf{\tau}$の$x_i$方向の成分を表しており、実装上は差分による近似で求められる(⇒part19)。
以上により、入力の変化に対する出力の変化具合を数式化できた。
あとは、これをもとの誤差関数$E$に正則化関数$ \Omega $として追加して
$$
\tilde{E} = E + \lambda \Omega \tag{5.127}
$$
とすればよい。$ \lambda $は正則化係数で、訓練データに対するフィッティングと不変性の学習のバランスを決定する。
式(5.126)の変化に対するペナルティはある1つのデータ点での、ある出力ユニット$k$についての値なので、データ点と出力ユニットに関して総和をとったものを$ \Omega $としよう。ここで:
- データ点が変わると入力空間上の座標が変わるので接ベクトルが変化する(上図も参照)ので、接ベクトル$ \mathbf{\tau} $にデータ点に関するインデックス$n$をつけて$ \mathbf{ \tau } _ n $と表記する。
$ \mathbf{\tau} _ n $の$ x_i $方向成分は$ \tau_{ni} $と表記。 - 訓練済みのニューラルネットワークは非線形になるので、入力データが新しくなるたびにヤコビ行列を再評価する必要がある(⇒part19)ことから、ヤコビ行列$J$にもデータ点に関するインデックス$n$をつけて$ J_n $と表記。$ J_{nki} $は入力データ$ x_n $に関するヤコビ行列の$(k,i)$成分を表す。
以上の表記を使って正則化関数$ \Omega $は
\begin{align}
\Omega = \frac{1}{2} \sum_n \sum_k \left(
\left. \frac{ \partial y_{nk} }{ \partial \xi } \right|_{ \xi=0}
\right)^2
=
\frac{1}{2} \sum_n \sum_k \left(
\sum_{i=1}^D J_{nki} \tau_{ni}
\right)^2 \tag{5.128}
\end{align}
となる。
5.5.5 変換されたデータを用いた訓練
簡単にだけ。
不変性を持たせるアプローチとして、アプローチ3「入力の変化に対する出力の変化にペナルティ(接線伝播法)」を紹介したが、入力データを$\xi$だけ微小に変化させたものを学習データ集合に追加しているとしよう。
学習データ集合の追加は、アプローチ1「学習データ集合を増やす」で紹介したもの。
このような考え方をして小難しい式変形を行うと、アプローチ1の誤差関数はアプローチ3の誤差関数の形(式(5.127))で書ける。
なので、アプローチ1とアプローチ3は密接な関係があるんですよ~、とのことらしい。
5.5.6 たたみ込みニューラルネットワーク
アプローチ4:ニューラルネットワークネットワークの構造に不変性を構築
画像データを扱うケースにおいて、平行移動や拡大縮小、小さな回転に対して不変性をもたせるためにたたみ込みニューラルネットワーク (convolutional neural network, CNN) という構造のニューラルネットがある。
CNNは、deep learningでも非常によく用いられている構造のネットワーク。
ただ、テキストの内容だけでは十分に理解できないので、もっと勉強する場合は別の資料を参考にしよう。
CNNがやろうとしているのは以下の概念である。
- 局所的受容野:近くにある画素どおしは遠くにある画素どおしより強い相関を持っている(例:ある赤色の画素の隣は赤に近い色であることが多い。遠い画素になるほど赤とは異なる色になる)。そこで、画像全体でなく小さな部分領域だけに依存する局所的な特徴を抽出する
- 重み共有:画像のある部分領域で有用な局所的な特徴(例:顔認識のケースでの目という特徴量)は、画像の別の部分領域でも有用である可能性が高い(例:左目の特徴量は右目でも使える)
- 部分サンプリング:画像に映っている対象が多少上下左右に平行移動していても同じ結果になってほしい
これらの概念を図にしたものが以下である。
(こちらのサイトから引用しました:https://saitoxu.io/2017/01/01/convolution-and-pooling.html)
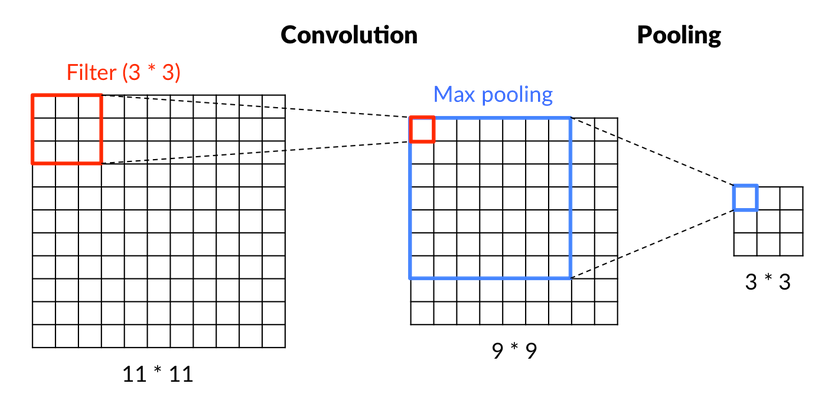
11画素×11画素の入力画像のある3画素×3画素の部分領域に注目する(図の11×11の赤四角)。3画素×3画素=9個の輝度値(入力)と9次元の重みの線形和から1次元の値(図の9×9の赤四角)を計算する【局所的受容野】。
9次元の重みはこのCNNの学習で求める数値パラメータであり、計算された1次元の値は特徴量の一部である。
この計算を入力画像の左上から右下までまんべんなく繰り返す。繰り返しの際の9次元の重みは共通である【重み共有】。
こうして求められた9×9の特徴量の7画素×7画素の部分領域に注目する(図の9×9の青四角)。この部分領域の最大値や平均値を抽出して出力値とする【部分サンプリング】。画像に映っている対象が多少移動することで特徴量の値も移動することになるが、部分サンプリングによりこの移動の影響を吸収することができる。よって、画像に映っている対象の平行移動に対して比較的鈍感になる。
5.5.7 ソフト重み共有
多くの重みをもつネットワークの有効な複雑さを削減する方法の1つに、一定のグループに属する重みを等しくするという制限を加える手法がある。
これを同じグループに属する重みが似たような値をとったときに小さくなるような正則化項の導入により実現しよう。
weight decay (荷重減衰) として導入した正則化誤差は:
$$
\tilde{E}(w) = E(w) + \frac{ \lambda }{2} w^T w \tag{5.112}
$$
であった。この正則化項$ \frac{ \lambda }{2} w^T w $は、重みの事前分布にガウス分布を仮定した際の負の対数尤度とみなせる(詳細は割愛)。
そこで、重みの値が1つのグループでなく複数のグループを構成するように、事前分布をガウス分布から($M$個の)混合ガウス分布に変更しよう。重みの事前分布は:
\begin{align}
p(w) &= \prod_i p(w_i) \tag{5.136} \\
p(w_i) &= \sum_{j=1}^M \pi_j N(w_i | \mu_j, \sigma_j^2) \tag{5.137}
\end{align}
であり、$ \pi_j $は混合係数2である。負の対数をとると
$$
\Omega(w) = - \sum_i \ln \left( \sum_{j=1}^M \pi_j N(w_i | \mu_j, \sigma_j^2 ) \right) \tag{5.138 }
$$
という形の正則化関数が導かれる。したがって、誤差関数全体は
$$
\tilde{E}(w) = E(w) + \Omega(w) \tag{5.139}
$$
で与えられる。
誤差関数の微分
誤差関数の調整可能なパラメータに関する微分が求まれば、準ニュートン法などの数学テクニックを使うことで誤差関数を最小化できるらしい。
なので、最後に誤差関数のパラメータに関する微分を確認しよう。
この後の計算を便利にするため、以下の式を導入しておこう。
$$
\gamma_j(w) = \frac{ \pi_j N(w | \mu_j, \sigma^2_j) }{ \sum_k \pi_k N(w | \mu_k, \sigma^2_k)} \tag{5.140}
$$
誤差関数の重みに関する微分(演習5.29)
\begin{align}
\tilde{E}(w) &= E(w) + \Omega(w) の微分が \tag{5.139} \\
\frac{ \partial \tilde{E} }{ \partial w_i } &= \frac{ \partial E}{ \partial w_i } + \sum_j \gamma_j(w_i) \frac{ (w_i - \mu_j) }{ \sigma_j^2 } \tag{5.141}
\end{align}
となることを示そう。
$E(w)$に関する微分はそのままなので、$ \Omega(w) $に関する微分を考えればよい。
式(5.138)の一番外側に$i$に関するシグマがあるが、$i$以外の$w_{*}$は$w_i$についての微分には関係ないので無視できる。なので、$i$に関するシグマは外すことができ、
$$
- \ln \left( \sum_{j=1}^M \pi_j N(w_i | \mu_j, \sigma_j^2 ) \right)
$$
となる。これを微分すると対数の微分の公式によりlnの中身が分母に出てくる。つまり、分母に$ - \sum_k \pi_k N(w | \mu_k, \sigma^2_k) $が現れる。
続いて分子にはlnの中身の$w_i$に関する項を微分したものになるので
\begin{align}
& \frac{ \partial }{ \partial w_i} \left(
\sum_j \pi_j \cdot \frac{1}{(2 \pi \sigma^2_j)^{1/2} } \exp \left\{
- \frac{1}{2 \sigma_j^2} (w_i - \mu_j)^2
\right\}
\right) \\
=& \sum_j \pi_j \cdot \frac{1}{(2 \pi \sigma^2_j)^{1/2} } \exp \left\{
- \frac{1}{2 \sigma_j^2} (w_i - \mu_j)^2
\right\} \cdot \left(
2 \cdot - \frac{1}{2 \sigma_j^2} (w_i - \mu_j)
\right) \\
=& \sum_j \pi_j \cdot \frac{1}{(2 \pi \sigma^2_j)^{1/2} } \exp \left\{
- \frac{1}{2 \sigma_j^2} (w_i - \mu_j)^2
\right\} \cdot \left(
- \frac{1}{\sigma_j^2} (w_i - \mu_j)
\right) \\
=& \sum_j \pi_j N(w_i | \mu_j, \sigma_j^2) \cdot \left(
- \frac{1}{\sigma_j^2} (w_i - \mu_j)
\right) \\
\end{align}
よって
\begin{align}
\frac{ \partial \Omega}{ \partial w_i} &= \frac{ \sum_j \pi_j N(w_i | \mu_j, \sigma_j^2) \cdot \left(
- \frac{1}{\sigma_j^2} (w_i - \mu_j)
\right) }{ - \sum_k \pi_k N(w | \mu_k, \sigma^2_k) } \\
&= \frac{ \sum_j \pi_j N(w_i | \mu_j, \sigma_j^2) }{ \sum_k \pi_k N(w | \mu_k, \sigma^2_k) } \cdot \frac{(w_i - \mu_j)}{\sigma_j^2} \\
&= \sum_j \gamma_j(w_i) \cdot \frac{(w_i - \mu_j)}{\sigma_j^2} \\
\end{align}
となり、式(5.141)となることを示せた。
この正則化項は重み$w_i$が$j$番目のガウス分布の平均$ \mu_j $から離れるほど大きくなることから、各重みを$ \mu_j $へ引き寄せる(似たような値をとりやすく)する効果がある。
どの程度引き寄せるかの係数が$ \gamma_j(w_i) $であると解釈できる。
誤差関数のガウス分布の平均に関する微分(演習5.30)
$$
\frac{ \partial \tilde{E} }{\partial \mu_j} = \sum_i \gamma_j (w_i) \frac{(\mu_j - w_i )}{\sigma_j^2}
$$
となることを示そう。
元々の誤差関数$E(w)$は$ \mu_j $と無関係なので$ \Omega(w) $に関する微分を考えればよい。
式(5.138)のlnの中身に$j$に関するシグマがあるが、$j$以外の$\mu_{*}$は$\mu_j$についての微分には関係ないので無視できる。なので、$j$に関するシグマは外すことができる。また、対数の足し算は掛け算にできるので
\begin{align}
& - \sum_i \ln \left( \pi_j N(w_i | \mu_j, \sigma_j^2 ) \right) \\
=& - \ln \left( \sum_i \pi_j N(w_i | \mu_j, \sigma_j^2 ) \right)
\end{align}
となり、$w_i$に関する微分の導出過程とほぼ同じ式がでてくる($i$についてのシグマか$j$についてのシグマかが異なるのみ)。
以降の微分も$w_i$に関する微分と同じように進めればできるが、ガウス分布のexpの中身の$ \mu_j $の符号は負で$ w_i$の符号と反対である。
そのため、微分の結果も正負が反転するので式(5.141)の$ (w_i - \mu_j) $の部分が$ (\mu_j - w_i ) $となっている。
これは$ \mu_j $を重みの平均値方向へ引っ張っていると解釈できる。
誤差関数のガウス分布の分散に関する微分
疲れたので結果だけ示す。同様に微分を進めると
$$
\frac{ \partial \tilde{E} }{ \partial \sigma_j } = \sum_i \gamma_j (w_i) \left(
\frac{1}{ \sigma_j} - \frac{ (w_i - \mu_j)^2}{ \sigma_j^3}
\right) \tag{5.143}
$$