はじめに
このページではKubernetes v1.30 における SIG-Apps に関連する変更内容をまとめています。
SIG-AppsはKubernetesのワークロードの扱いなどの変更を主に扱っているため、他のSIGと関係する変更が多くなっております。
- 直近での過去の変更内容は以下になります。
SIG / SIG-Apps とは?
-
SIGとは?
- Special Interest Groups の略称
- 各 SIG には Subproject が与えられていて、 Subproject に対して独立して開発できるようになっています。
- Kubernetes は巨大なプロジェクトなので、各SIG 毎に担当(Subproject)が割り当てられていて、各SIG は独立して開発をしています。
- SIG 間を跨って話し合いをする必要が生じた場合は Working Groups が一時的に作られ、その枠組みの中で話し合うことになります。
-
SIG-Appsとは?
- Apps Special Interest Group の略称
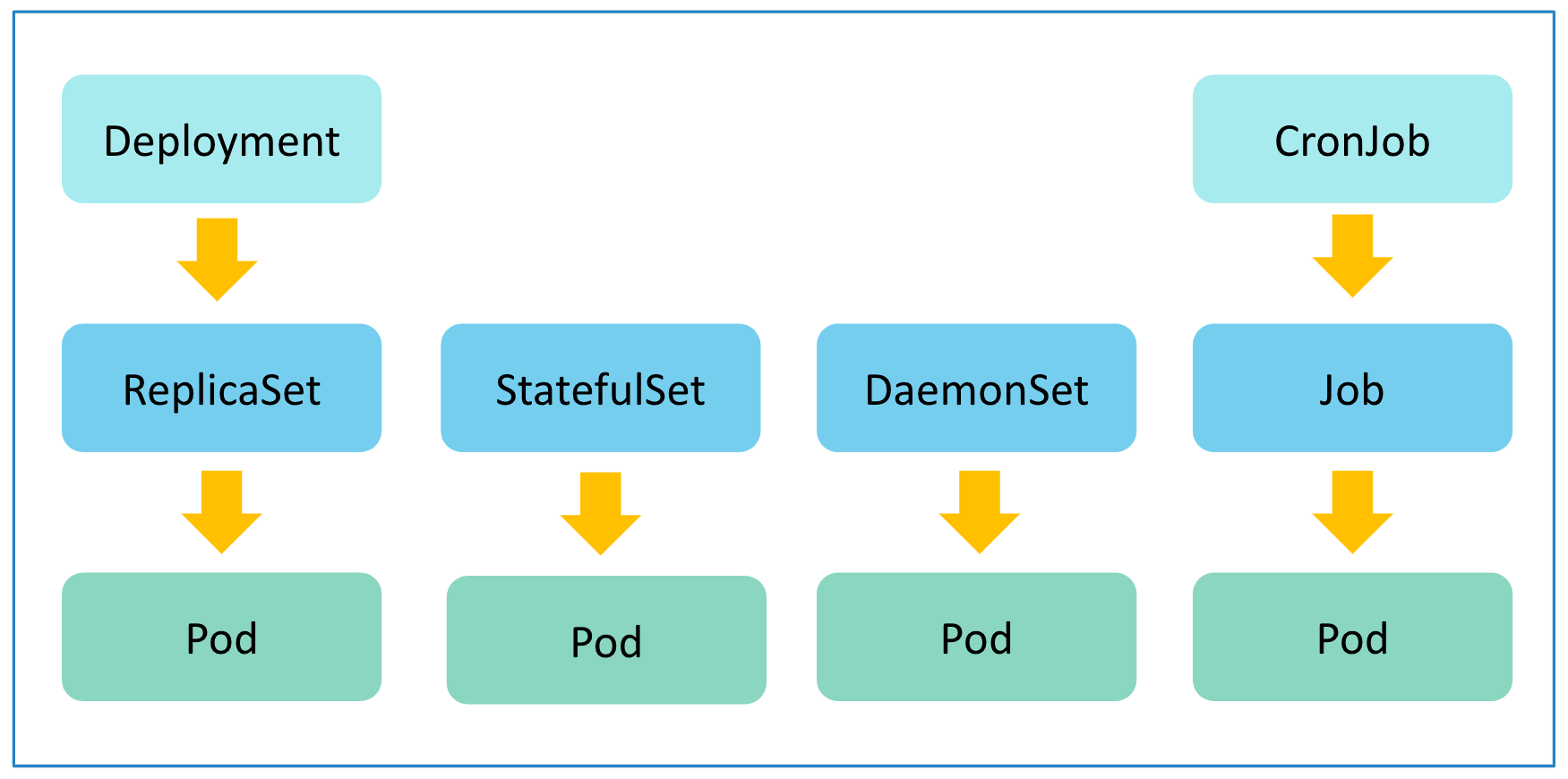
- Kubernetes に対して、application を deploy したりすることに関することが対象。具体的には Pod, ReplicaSet, Deployments, DaemonSet, StatefulSet, Jobs, CronJob が対象。
- 詳細について知りたい方はこちらをご参照ください。
SIG-Apps 以外の SIG に関する変更は以下にまとめてありますので、合わせてご参照下さい。
注目の変更
Feature Gatesの中で今回Stageに変更のあったSig-Appsに関連する機能は以下になります。
- Job
-
JobManagedBy:Alphahttps://github.com/kubernetes/enhancements/issues/4368 -
JobSuccessPolicy:Alphahttps://github.com/kubernetes/enhancements/issues/3998
-
今回新規された機能の詳細について以下で説明します。
Job
JobManagedBy
Job リソースの管理を既存の Job Controller ではなく、他のコントローラーに移譲できるように、Job のリソースに管理するコントローラーを指定するフィールドを追加します。
- 関連情報
| KEP | KEP-4368 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | JobManagedBy |
| issue | #4368 |
| 参考 | 公式ドキュメント |
機能しては Ingeress に対する IngressClass や GatewayAPI における GatewayClass のような機能の Job リソース版になります。
Kueueのプロジェクトの中で、Job のリソースの管理を Kueue controller に移譲したい要望があり追加されました。
詳しい内容の説明 (クリックすると開きます)
JobManagedBy が有効化されている場合に spec.managedBy が利用できるようになります。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
+ managedBy: "kubernetes.io/job-controller"
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
kubernetes.io/job-controller は予約された文字列になっていて、これを指定した場合は Job リソースは既存の Job Controller で管理されます。Kueue などで利用する場合は、ここに移譲させたいコントローラーで指定された文字列を設定します。
該当のフィールドを利用するユースケースは、Kueue など Job リソースを操作するカスタムコントローラーを独自に用意する場合になります。
- 参考:該当のフィールドの説明は以下になります。
$ kubectl explain job.spec.managedBy
GROUP: batch
KIND: Job
VERSION: v1
FIELD: managedBy <string>
DESCRIPTION:
ManagedBy field indicates the controller that manages a Job. The k8s Job
controller reconciles jobs which don't have this field at all or the field
value is the reserved string `kubernetes.io/job-controller`, but skips
reconciling Jobs with a custom value for this field. The value must be a
valid domain-prefixed path (e.g. acme.io/foo) - all characters before the
first "/" must be a valid subdomain as defined by RFC 1123. All characters
trailing the first "/" must be valid HTTP Path characters as defined by RFC
3986. The value cannot exceed 64 characters.
This field is alpha-level. The job controller accepts setting the field when
the feature gate JobManagedBy is enabled (disabled by default).
JobSuccessPolicy
Index 付きの Job 実行時の成功の条件を柔軟に設定できるようになります。
- 関連情報
| KEP | KEP-3998 |
|---|---|
| Feature stage | Alpha |
| Feature Gate | JobSuccessPolicy |
| issue | #3998 |
| 参考 | 公式ドキュメント |
Job で sepec.completionMode=Indexed ようにして、Index 付きの Job を実行する場合には、全ての Index 付き Pod の実行が成功しないと Job として成功になりませんが、成功とするための判定条件をもう少し柔軟に設定するための機能になります。
詳しい内容の説明 (クリックすると開きます)
sepec.completionMode=Indexed を指定して Index 付き Job を実行する場合に、sepec.successPolicy で成功の条件を追加することができます。
apiVersion: batch/v1
kind: Job
spec:
parallelism: 10
completions: 10
+ completionMode: Indexed
+ successPolicy:
+ rules:
+ - succeededIndexes: 0,2-3
+ succeededCount: 1
template:
spec:
containers:
- name: main
image: python
command:
- python3
- -c
- |
import os, sys
if os.environ.get("JOB_COMPLETION_INDEX") == "2":
sys.exit(0)
else:
sys.exit(1)
successPolicy には以下の 3 つのパターンのルールを設定できます。
-
succeededIndexesのみを指定 : Index の番号を指定します。指定した index の番号の Pod の処理が成功したら Job を成功と判定します -
succeededCountのみを指定 : 成功に必要な個数を指定します。index の番号付きの Pod の処理が成功した回数が指定した数を超えたら Job を成功と判定します。 -
succeededIndexesとsucceededCountの両方を指定 :succeededIndexesで指定した index の番号付きの Pod の処理が成功した回数がsucceededCountで指定した数を超えたら Job を成功と判定します。
successPolicy を利用する場合は 1つ以上のルールを設定する必要があり、最大で 20 個までルールを設定することができます。複数のルールが設定されている場合は、どれか 1 つのルールを満たした時点で Job は成功として判定されます。Job が成功と判定されると、該当の Job で管理されている実行中の Pod は中断されます(Terminating に移行する)
以下に実際に動作させた場合の例を以下に記載します。
- 以下の Job を作成します
apiVersion: batch/v1
kind: Job
metadata:
name: job-success
spec:
parallelism: 5
completions: 5
completionMode: Indexed # Required for the success policy
successPolicy:
rules:
- succeededIndexes: 0,2-3
succeededCount: 1
template:
spec:
containers:
- name: main
image: python
command: # Provided that at least one of the Pods with 0, 2, and 3 indexes has succeeded,
# the overall Job is a success.
- python3
- -c
- |
import os, sys
if os.environ.get("JOB_COMPLETION_INDEX") == "2":
sys.exit(0)
else:
sys.exit(1)
restartPolicy: Never
- Job を作成した場合に作成される Pod の Status の推移を観察します
$ get po -w
NAME READY STATUS RESTARTS AGE
# Pod の作成開始
job-success-0-gfvz2 0/1 ContainerCreating 0 0s
job-success-1-qfwxs 0/1 ContainerCreating 0 0s
job-success-2-7knk8 0/1 ContainerCreating 0 0s
job-success-3-8sr7l 0/1 ContainerCreating 0 0s
job-success-4-px8tr 0/1 ContainerCreating 0 0s
# `2` が Completed
job-success-0-gfvz2 0/1 Error 0 3s
job-success-1-qfwxs 0/1 Error 0 4s
job-success-2-7knk8 0/1 Completed 0 4s
# JobSuccessPolicy 指定して成功条件を満たしたので、実行中だった他の Pod たちが Terminating になります。
job-success-0-gfvz2 0/1 Error 0 4s
job-success-1-qfwxs 0/1 Terminating 0 4s
job-success-2-7knk8 0/1 Completed 0 4s
job-success-3-8sr7l 0/1 Terminating 0 4s
job-success-4-px8tr 0/1 Terminating 0 4s
successPolicy で指定した成功条件を満たしたタイミングで、該当の Job が管理する残りの実行中の Pod たちが Terminating になることに注意してください
- Job の Stasus を確認します。
$ kubectl get job -w
NAME STATUS COMPLETIONS DURATION AGE
job-success Running 0/5 0s
job-success Running 0/5 0s 0s
job-success Running 1/5 4s 4s
job-success Complete 1/5 4s 4s
今までは Job の Status が Complete になっている場合は Completions が 5/5 のように分母と分子が同数になっていましたが、 1/5 のような状態でも Complete になるようになりました。
- Job リソース側の Status の詳細を確認します
$ kubectl get job -o yaml
:
status:
completedIndexes: "2"
completionTime: "2024-05-16T08:55:40Z"
conditions:
+ - lastProbeTime: "2024-05-16T08:55:40Z"
+ lastTransitionTime: "2024-05-16T08:55:40Z"
+ message: Matched rules at index 0
+ reason: SuccessPolicy
+ status: "True"
+ type: SuccessCriteriaMet
+ - lastProbeTime: "2024-05-16T08:55:40Z"
+ lastTransitionTime: "2024-05-16T08:55:40Z"
+ message: Matched rules at index 0
+ reason: SuccessPolicy
+ status: "True"
+ type: Complete
failed: 1
ready: 0
startTime: "2024-05-16T08:55:36Z"
succeeded: 1
reason: SuccessPolicy によって Job が成功したことが確認できます。
- 参考:該当のフィールドの説明は以下になります。
$ kubectl explain job.spec.successPolicy
GROUP: batch
KIND: Job
VERSION: v1
FIELD: successPolicy <SuccessPolicy>
DESCRIPTION:
successPolicy specifies the policy when the Job can be declared as
succeeded. If empty, the default behavior applies - the Job is declared as
succeeded only when the number of succeeded pods equals to the completions.
When the field is specified, it must be immutable and works only for the
Indexed Jobs. Once the Job meets the SuccessPolicy, the lingering pods are
terminated.
This field is alpha-level. To use this field, you must enable the
`JobSuccessPolicy` feature gate (disabled by default).
SuccessPolicy describes when a Job can be declared as succeeded based on the
success of some indexes.
FIELDS:
rules <[]SuccessPolicyRule> -required-
rules represents the list of alternative rules for the declaring the Jobs as
successful before `.status.succeeded >= .spec.completions`. Once any of the
rules are met, the "SucceededCriteriaMet" condition is added, and the
lingering pods are removed. The terminal state for such a Job has the
"Complete" condition. Additionally, these rules are evaluated in order; Once
the Job meets one of the rules, other rules are ignored. At most 20 elements
are allowed.
おまけ
今回の紹介したアルファ機能は以下の kind の YAML で検証できます。
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: kind
featureGates:
"JobManagedBy": true
"JobSuccessPolicy": true
nodes:
- role: control-plane
image: kindest/node:v1.30.0
- role: worker
image: kindest/node:v1.30.0
- role: worker
image: kindest/node:v1.30.0
v1.30 Release Notes
v1.30 Release Notes の中で SIG-Apps に関するものについて以下に和訳したものを記載します。
がついた文章は、CHANGELOGの公式内容ではなく筆者の補足です。
 Deprecation(非推奨)
Deprecation(非推奨)
なし
 API Changes(変更)
API Changes(変更)
-
Job のフィールドに
managedByがアルファ機能として追加されました。 このフィールドは Job をカスタムできるもので、kubernetes.io/job-controller以外の値が設定されている場合は job controller からスキップされ、フィールドで指定されている external controller でリコンサイルを実施するようになります。Job はこのフィールドに何も設定されていないか、 予約文字列であるkubernetes.io/job-controllerが指定されている場合に job controller によってリコンサイルが実施されます。
(#123273, @mimowo) [sig/api-machinery,sig/apps,sig/testing]-
新しくカスタムコントローラーを用意した上で、リコンサイルの対象のリソースを CRD で新たに定義せずに、既存の Job リソースを対象とした場合に使うフィールドになります。このフィールドによって、 既存の job controller と並行して独自に Job 用のコントローラーを用意することができるようになりました。
-
-
Job で SuccessPolicy がアルファ機能としてサポートされました。
(#123412, @tenzen-y) [sig/api-machinery,sig/apps,sig/testing]-
index 付きの Job を実行する際の Job の成功条件をより柔軟に設定できるようになりました。
-
-
Dynamic Resource Allocation: DRA drivers は "structured parameters" を使用して、 scheduler がリソースの要求を割り当てできるようになりました。
(#123516, @pohly) [sig/scheduling,sig/storage,sig/node,sig/api-machinery,sig/cluster-lifecycle,sig/auth,sig/apps,sig/cli,sig/instrumentation,sig/testing,sig/release] -
StorageVersionMigrationAPI は以前は CRD を利用していましたが、Kubernetes の built-in API となりました。
(#123344, @nilekhc) [sig/api-machinery,sig/auth,sig/apps,sig/cli,sig/testing] -
readOnlyvolumes は kernel versions >= 5.12 の場合に、再起的な read-only mounts をサポートするようになりました。
(#123180, @AkihiroSuda) [sig/node,sig/api-machinery,sig/apps,sig/testing] -
RelaxedEnvironmentVariableValidationfeature gate がアルファで追加されました、この機能が有効化されている場合に Kubernetes で印字可能なすべての ASCII 文字が Pod 内の環境変数の名前に使用できるようになリます。 (#123385, @HirazawaUi) [sig/node,sig/apps,sig/testing] -
trafficDistributionが Service のspecにアルファ機能のフィールドとして追加され、この設定は traffic の endpoints への分散を表現します。ServiceTrafficDistributionfeature gate 有効化することで利用できます。(#123487, @gauravkghildiyal) [sig/network,sig/api-machinery,sig/apps] -
kube-controller-managerの CLI にdisable-force-detachを追加しました。デフォルトではfalseに設定されています。有効化された場合には maximum unmount time と node status の状態に応じて、強制的にボリュームがデタッチされます。実行された場合にはノード障害から復帰するために、non-graceful node shutdown 機能を使用しなければなりません。 また、リスクを冒して Pod 強制終了する場合には適切な VolumeAttachment オブジェクトを削除する必要があります。 (#120344, @rohitssingh) [sig/storage,sig/api-machinery,sig/apps,sig/testing] -
AppArmor profiles は
PodSecurityContextとコンテナのSecurityContextで設定できるようになりました。ベータの AppArmor annotations は非推奨になりました。 AppArmor status は node の ready condition に含まれなくなります。 (#123435, @tallclair) [sig/node,sig/api-machinery,sig/auth,sig/apps,sig/testing] -
topology spread constraints の Pod の
minDomainsが GA になりました。MinDomainsInPodTopologySpreadfeature gate は機能しなくなり、該当のフィールドは Pod と PodTemplate APIs で常に利用できるようになります。 (#123481, @sanposhiho) [sig/scheduling,sig/api-machinery,sig/apps,sig/testing] -
PodSpec API の hostNetwork Pods から
hostAliasesがサポートされなくなります。 該当機能は v1.8 からサポートされていました。 (#122422, @neolit123) [sig/api-machinery,sig/apps]
 Feature(機能追加)
Feature(機能追加)
-
Pod API ではアルファ機能である
procMountフィールドにUnmasked設定する場合はspec.hostUsers=falseも設定する必要があるようになりました。
(#123520, @haircommander) [sig/auth,sig/apps,sig/testing] -
kubectl get jobで Job の status が表示されるようになりました。
(#123226, @ivanvc) [sig/apps,sig/cli] -
HorizontalPodAutoscaler で per-container metrics が GA になりました。 (#123482, @sanposhiho) [sig/api-machinery,sig/autoscaling,sig/apps]
-
Pod の
status.hostIPsフィールドが GA になりました。PodHostIPsfeature gate は機能しなくなり、 Pod API のstatus.hostIPsフィールドは常に利用できるようになります。 (#122870, @wzshiming) [sig/network,sig/node,sig/apps,sig/testing]
 Bug or Regression(バグ修正)
Bug or Regression(バグ修正)
-
syncCronJobのエラーログの誤りを修正しました。
(#122493, @mengjiao-liu) [sig/apps]-
エラー時に
syncErrの変数に格納されるようになっていましたが、チェックする箇所がerrの変数をチェックしていて、syncErrのチェックが今まで漏れていたのが修正されました。
-
-
更新中に PDB の状態を維持するために、disruption controller が PDB status への同期が修正されました。
(#122056, @dhenkel92) [sig/apps]-
disruption controller が更新するときに、現状の Status.Conditions コピーして保持するように修正されました。これによって、disruption controller 以外で変更されているものが、同期によって削除されることを防ぐようになったようです。
-
-
restartPolicy が
NeverかOnFailureに設定されている Pod で containerRestartPolicy がAlwaysに設定された init container の ステータスを terminated から non-terminated に更新できない不具合を修正しました。 (#123323, @gjkim42) [sig/node,sig/apps]-
1.29 から beta になった Sidecar 機能に関する不具合の修正になります。
-
-
不要な node events を無視するようにして、daemonset controller のパフォーマンスが良くなるように修正しました。 (#121669, @xigang) [sig/apps]
-
conditionType ready が誤ってパッチによって
nilが設定された場合に、node lifecycle controller がパニックになる不具合を修正しました。 (#122874, @fusida) [sig/network,sig/node,sig/apps]-
NWプラグインや、node の conditionType を操作するカスタムコントローラーが誤って、nil を設定した場合に、node lifecycle controller がパニックになる可能性があるので、nil のチェックが追加されました。
-
-
volume source が CSI type かマイグレーションされた annotation がある静的にプロビジョニングした PV が削除される場合に PersistentVolume controller はその状態を Failed state に変更しません。 この patch を適用すると external provisioner は次の reconcile loop で finalizer を削除できるようになります。残念ながら、既に既存の PV が Failed state にこの patch の効果は適用されせん。 ユーザは手動で finalizer を削除する必要があります。 (#122030, @carlory) [sig/storage,sig/apps]
-
Persistent Volume Claims (PVCs) は
storageClassNameが空だった場合に、PersistentVolume controller 自動でデフォルトのStorageClassを設定しなくなります。
(#122704, @carlory) [sig/storage,sig/apps]
 Other (その他の修正)
Other (その他の修正)
なし
所感
今回の変更で Job の機能が新たに 2つ追加されることとなりました、また、sig-apps が所管ではないですが、Pod リソースに関する変更としては最近では SideCar や PreStop での Sleep を利用できる機能などの大きな変更が続々と追加されてここに来て機能追加が活発になってきた印象があります。しかし、既存の Pod リソースの互換性を維持しながら機能を追加する必要があるため、設定方法がわかりにくかったり、使い勝手の面でも少し痒い所に手が届いていないようなものもあります。PreStop で Sleep を実施する機能も PreStop に一つしか指定できないので、Sleep の後に Exec で何かの処理を実施したい場合には、今までのようにシェル等で自分で処理を用意しないといけないなど、印象と違う番勝手になっている面もあります。
そろそろ Pod の v2 の議論があっても良さそうですが、互換性の維持を考えると現実的にはこの状態がずっと続くのかなと思いあmした。