はじめに
下記の記事では、Cassandraデータベースの利用によるKappaアーキテクチャーについての情報を整理しました。
また、下記の記事では、LambdaアーキテクチャーからKappaアーキテクチャーへの移行についての情報を整理しました。
上記の記事は下記のKai Waehnerによる記事の内容を元にしていました。
本稿では、同記事から、「イベントストリーミングプラットフォームの活用によるKappa アーキテクチャ実装」についての情報を整理し、記事では特に掘り下げられていない、KafkaとPulsarの違いについての情報を追記したいと思います。
費用対効果が高くスケーラブルな Kappa アーキテクチャ
これまでイベントストリーミングプラットフォームを活用して、Kappa アーキテクチャを実現する上での大きな問題は、イベント ストリーミング プラットフォームに膨大な量のデータを格納することになることでした。
このアプローチはコストがかかり、テラバイトまたはペタバイト規模でのスケーラビリティに問題がありました。
反面、データレイクは最初から膨大な量のために設計されていたため、初期段階では、Hadoop と HDFS がオンプレミスで使用され、またさらに、パブリック クラウドにより、AWS S3 や Google Cloud Storage などの完全に管理されたオブジェクト ストレージへの移行が可能になり、データ レイクのスケーラビリティとビッグ データのコスト効率がさらに向上しました。
1 つのアプローチは、イベント ストリーミング プラットフォームに格納されるデータを削減することです。ログの圧縮は、ストレージ サイズを削減するための実行可能なアプローチです。ただし、圧縮されたトピックはデータ セットを縮小し、各メッセージ キーの最新の値のみを格納します。したがって、この回避策はすべてのユース ケースに適用できるわけではありません。
実際に多く見られる別の回避策は、Kafka をストリーミング レイヤーとして使用し、長期保存用のオブジェクト ストレージを使用して「ストリーミング データ レイク」を構築することです。双方向の統合は、Kafka Connect とシンクおよびソース コネクタで構築されました。実際、これは、Confluent社 が頻繁に使用される S3 Sink コネクタに加えて、Kafka Connect 用の S3 Source コネクタを構築した主な理由でした。
イベント ストリーミング用の階層型ストレージ
その後、ストリーミング プラットフォームは、上の問題に答えるために進化しました。
それが階層型ストレージです。階層型ストレージを使用すると、Kafka や Pulsar などのイベント ストリーミング プラットフォームのコンピューティングからストレージを切り離すことができます。
階層型ストレージは、Kappa アーキテクチャのゲームチェンジャーです。
これにより、リアルタイム コンシューマーのパフォーマンスに影響を与えることなく、ストレージを管理することができます。さらに、これにより、従来のデータ レイクを必要とせずに、非常にコスト効率が高く弾力性のある Kappa アーキテクチャが可能になります。
Uber は、最近の Kafka Summit の講演で、Kafka の階層型ストレージ ( KIP-405 )の動機と利点について語っています。
Kappa アーキテクチャは、基盤となるストレージ テクノロジに関して非常に柔軟です。Uber は Hadoop の HDFS をストレージとして使用していますが、Confluent は別の方法を採用しています。Kafka 用の Confluent 階層型ストレージは、オブジェクト ストレージを利用する S3 インターフェイスに基づいており、AWS S3 や GCS などのパブリック クラウド プロバイダー オブジェクト ストアとPureStorage や Kubernetes の MinIO などオンプレミス オブジェクト ストアの両方で機能します。
履歴データのデジタル フォレンジックのための Kafka 用の Confluent 階層型ストレージ
言い換えれば、Kafka の階層型ストレージは、最新のクラウド データ レイク(または、AWS が今日、Lake House と呼んでいるもの) と同じ最新のデータ ストレージを活用できます。したがって、Kappa アーキテクチャは、リアルタイムのデータ処理と、履歴データを再生するための費用対効果の高いスケーラブルな長期ストレージという両方の長所を提供します。
Kappa アーキテクチャの実例
ほとんどのユースケースでは、リアルタイム データがスローデータよりも優れています。しかし、バッチ処理は依然として必要であり、なくなることはありません。
そのことを踏まえ、Uber、Shopify、Disney における Kappa アーキテクチャの実例をいくつか見てみましょう。
Uber の Kappa は 1 日あたり何兆ものメッセージとペタバイトを処理
Uber は非常に著名なテクノロジーの巨人です。彼らは、ソフトウェア アーキテクチャと展開について、定期的に公の場で多くのことを話します。Uber は、世界で最も重要な Kafka ユーザーの 1 つです。その間、彼らは1 日あたり 4 兆件以上のメッセージと 3PB を処理しています。
Uber は最近の Kafka Summit でKappa アーキテクチャについて発表しました。
Uber の Kafka を使用したアーキテクチャ
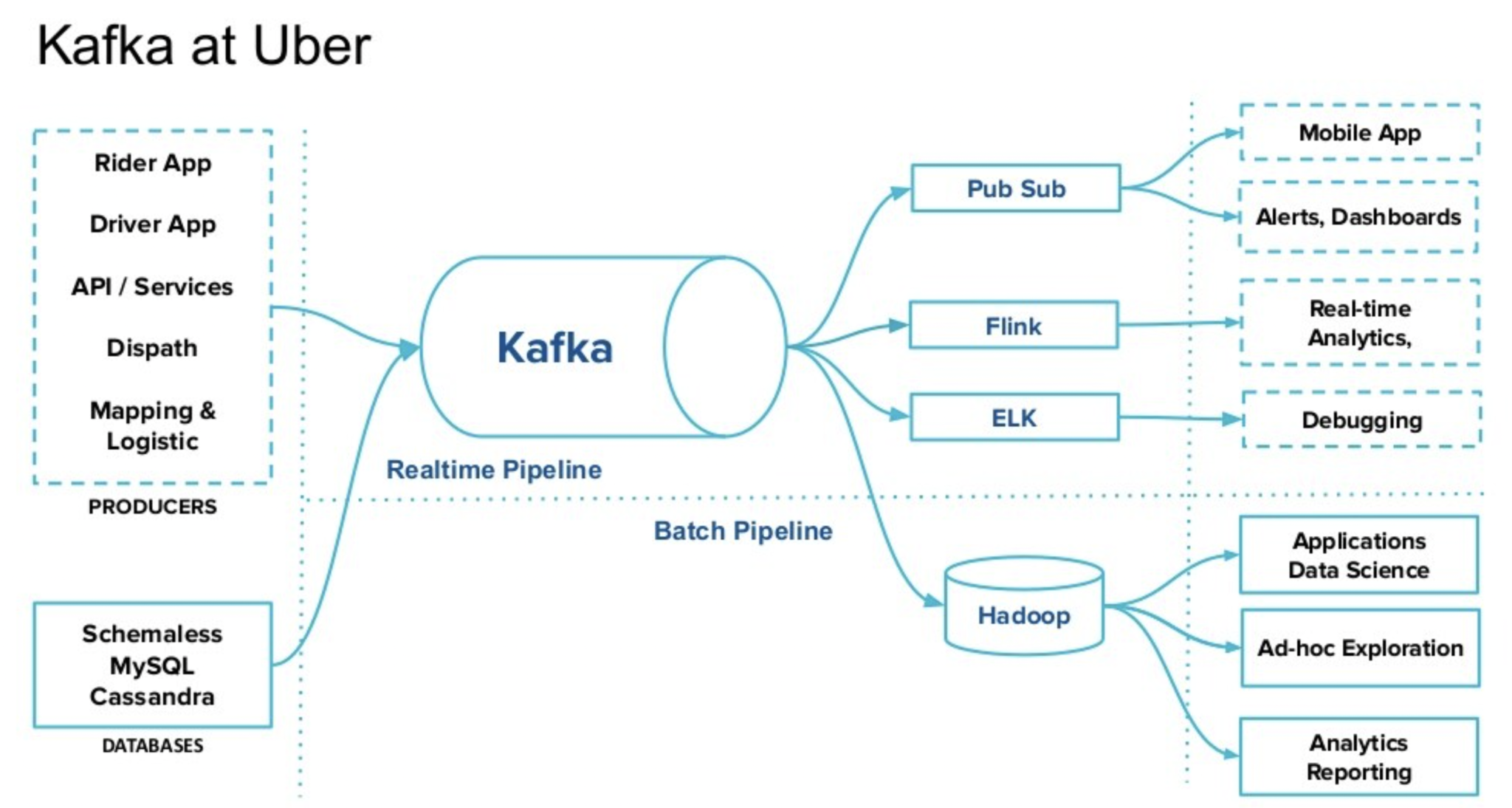
ご覧のとおり、Uber のアーキテクチャは、まさに上記のセクションで説明したとおりに進化しました。中枢神経系は、Kafka ベースのリアルタイム インフラストラクチャです。Uber にはまだバッチ パイプラインがあります。Uber は API も提供します (モバイル アプリなど)。また、驚くことではありませんが、従来の SQL および NoSQL データベース、ビジネス インテリジェンス レポート ツール、ダッシュボードなども備えています。
Uber のアーキテクチャは、Kappa の大きな利点を示しています。インフラストラクチャの中心は、リアルタイム、スケーラブル、フォールト トレラント、およびリアルアブル(信頼性を有する)です。
あらゆる目的のための単一のパイプラインが実現されており、Lambda アーキテクチャは必要ありません。 Kappaアーキテクチャ は、トランザクションおよび分析ワークロードを可能にします。データ メッシュ内の各マイクロサービスは、アプリケーションごとにそのテクノロジと通信パラダイムを使用できます。
ステートレスおよびステートフル データ ストリーミングのための Shopify の Kappa
Shopify は、最近のKafka Summit トークで Kappa アーキテクチャを紹介しました。
「ラムダ アーキテクチャの使用をやめる時が来ました」と題されたこのセッションでは、Kappa アーキテクチャの懸念と、Shopify がさまざまなビルディング ブロックでそれらをどのように解決したかについて説明されています。
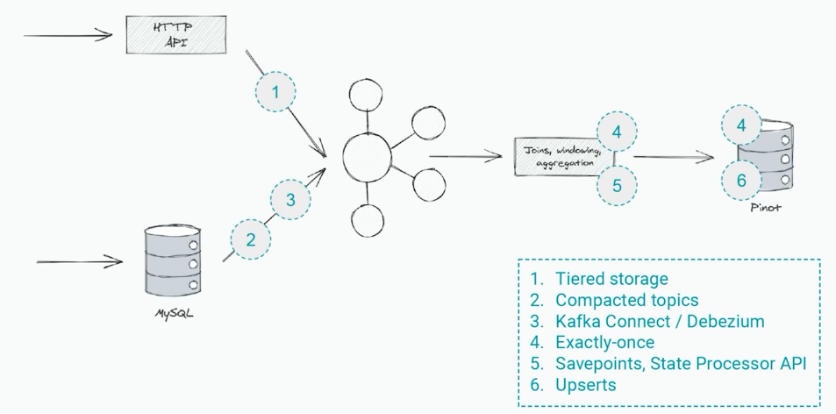
3 つの主要コンポーネントは、ログ (Kafka)、ストリーミング フレームワーク (Kafka Streams および Apache Flink)、およびデータ シンク (任意のリアルタイム コンシューマーまたはデータ ストア) です。
以下は、Shopify でのステートフルな Kappa シナリオの一例です。
Shopify での Kafka を使用した Kappa Architecture
真実の唯一の情報源(Single Source of Truth)としてのディズニーのKappa
ディズニーのKafkaサミットトーク「ビッグデータカッパ」はとても刺激的です。
これには、実際の Kappa 展開から学んだ教訓とトレードオフがおそらく最も多く含まれています。
オンデマンド ビデオを見ることをお勧めします。独自の Kappa アーキテクチャを構築するための多くの洞察とガイダンスが含まれています。
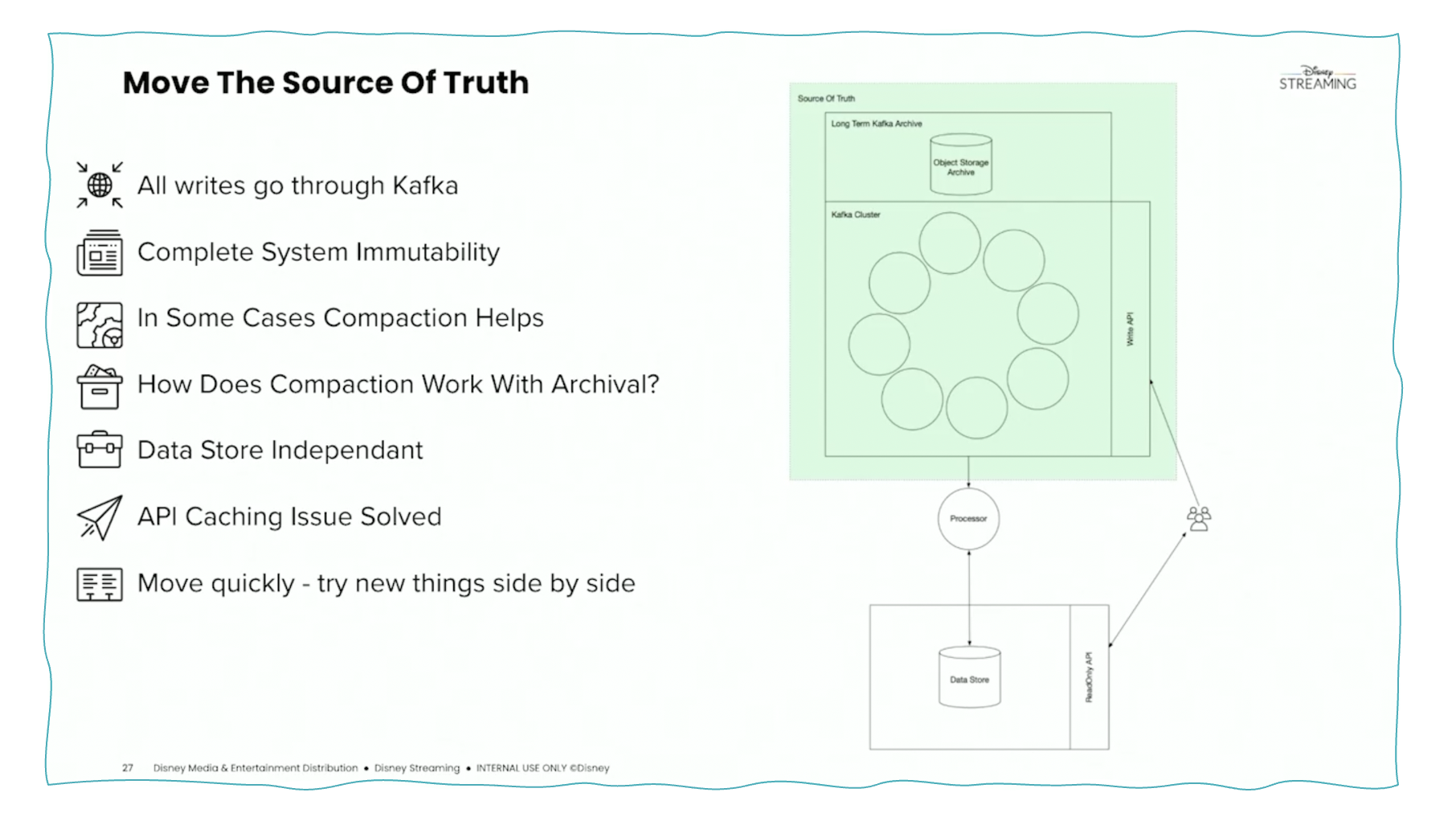
Disney でのすべてのデータ書き込みは、Single Source of Truthとして Kafka を経由します。
次のスクリーンショットをご覧ください。
緑色のボックスは Kafka クラスターであり、信頼できる唯一の情報源として階層型ストレージが含まれています。すべてのアプリケーションは、さらなる処理とオプションの外部ストレージのために Kafka からのデータを使用します。
ディズニーの Apache Kafka を使用した Kappa アーキテクチャ
TwitterにおけるLambdaからKappaアーキテクチャへの移行
Twitter は約4,000 億のイベントをリアルタイムで処理し、ペタバイト (PB) 規模のデータを毎日生成しています。Lambda アーキテクチャを使用した Hadoop と Kafka によるオンプレミス アーキテクチャは十分に効率的ではありませんでした。
Hadoop と Kafka を使用した古い Twitter Lambda アーキテクチャ
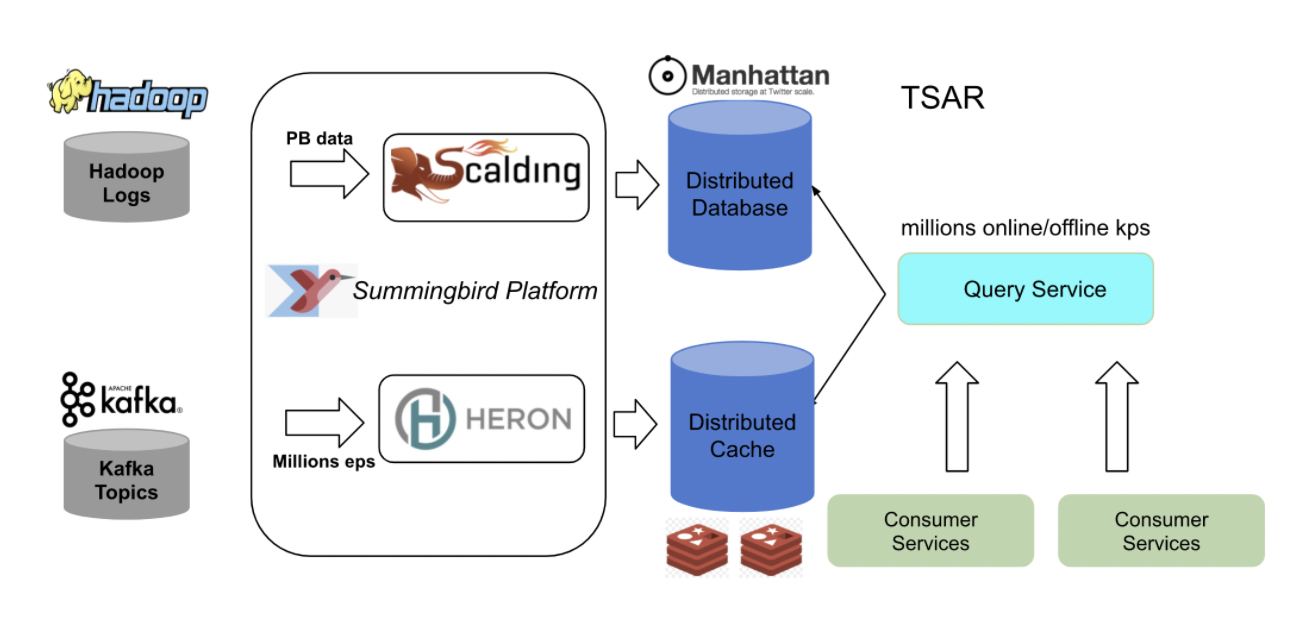
そのため、Twitter はKappa アーキテクチャを使用する Kafka で GCP 上のクラウドに移行しました。
Kafka と GCP Dataflow を使用した新しい Twitter Kappa アーキテクチャ
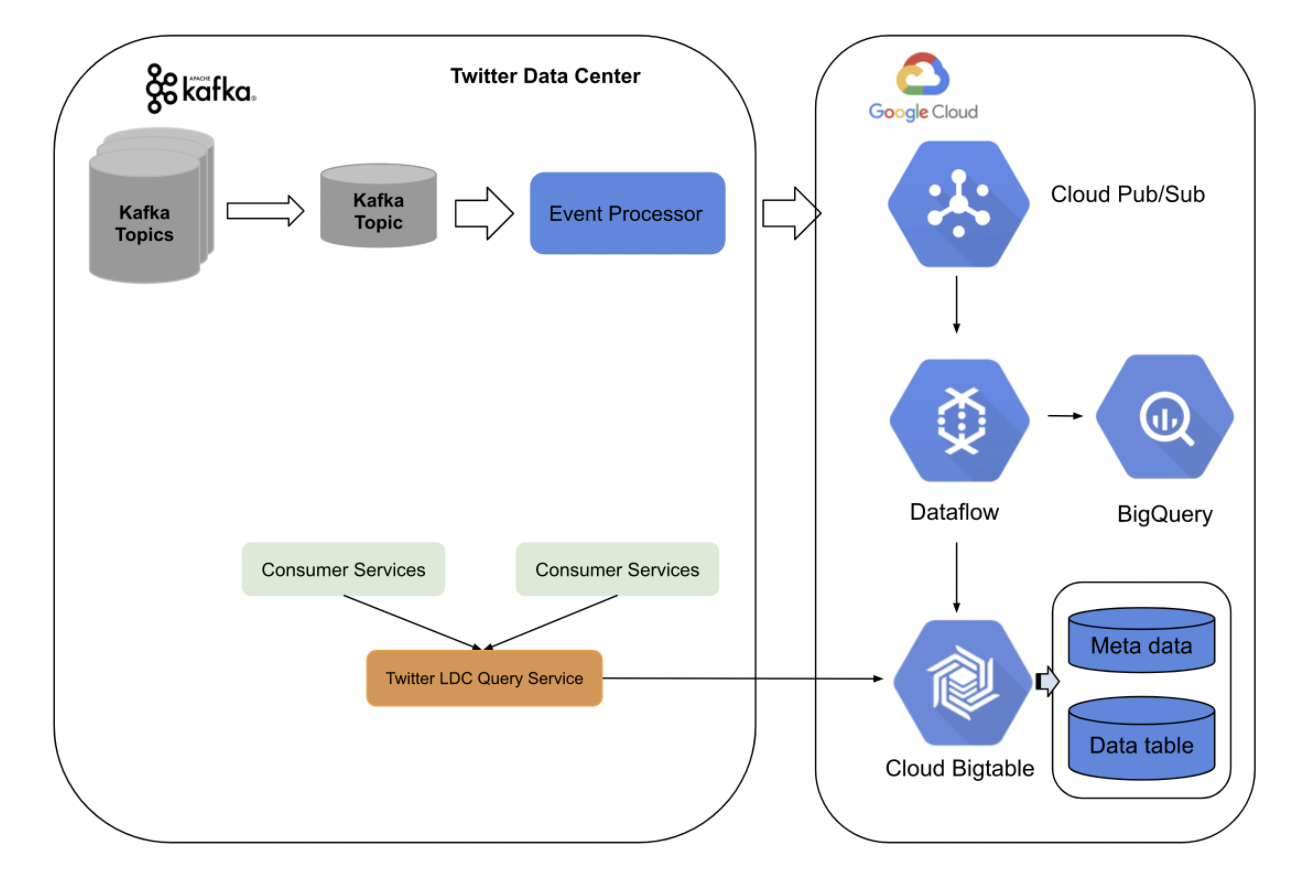
Lambda から Kappa への移行に関する下記の詳細なブログ投稿では、Twitter Data Center と Google Cloud Platform の両方で新しいハイブリッド アーキテクチャを使用することで、「数十億のイベントをリアルタイムで処理し、低レイテンシ、高精度、安定性、アーキテクチャのシンプルさ、およびエンジニアの運用コストの削減を実現できます」といわれています。
サンプル プロジェクト: モデルのトレーニング、スコアリング、モニタリングを含む機械学習用の Kappa
Uber、Shopify、Disney の実際の例に続いて、もう 1 つの実用的なコード例を共有したいと思います。それは、ストリーミング機械学習を行うために 100,000 個の IoT デバイスに接続する技術デモです。
ユースケースは、 数万または数十万の IoT デバイスを統合し、データをリアルタイムで処理することです。デモのユース ケースは、モーター エンジンの故障を予測するためのコネクテッド カー インフラストラクチャでの予知保全 (異常検出) です。
機械学習をストリーミングするための Apache Kafka MQTT Kubernetes と Tensorflow を使用した Kappa アーキテクチャ
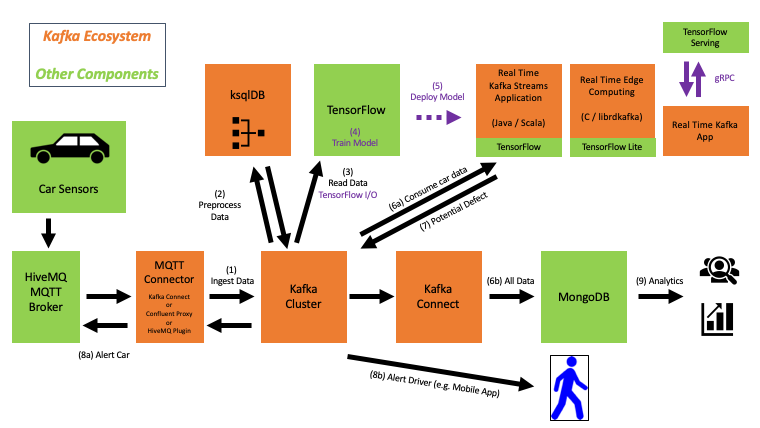
実装された Kappa アーキテクチャは、さまざまな非常に異なるユース ケースと処理パラダイムに単一のリアルタイム インフラストラクチャを提供します。
- MQTT プロキシーを介した IoT デバイスからの高スループットでのリアルタイムのデータ取り込み: 数百万のインターフェース (この場合はシミュレートされた車両) との統合。
- モデル トレーニングのバッチ処理: データ サイエンティストの TensorFlow Python アプリケーションは、Kafka ログの履歴データを使用して分析モデルをトレーニングします。
- モデル スコアリングのためのリアルタイム ストリーム処理: Java ベースのストリーミング アプリケーションは、Kafka Streams / ksqlDB によって強化され、ミッション クリティカルな SLA と低レイテンシーを備えたプロダクション エンジニアによって運用されます。
- 分析用のデジタル ツインへのほぼリアルタイムの取り込み: Kafka Connect は、データをさまざまなデータベースとアプリケーション (この場合は MongoDB Atlas クラウド サービス) に取り込みます。
- モバイル アプリの統合とトランザクション ワークロードのための同期要求応答/RPC 通信: Confluent REST Proxy (またはその他の Web/モバイル プロキシ) は、人間にリアルタイムのアラートを送信します。
このサンプルでは、インフラストラクチャ全体がクラウドネイティブです。これは Kubernetes 上で実行され、データ センターまたは任意のハイパースケーラーにデプロイできます。
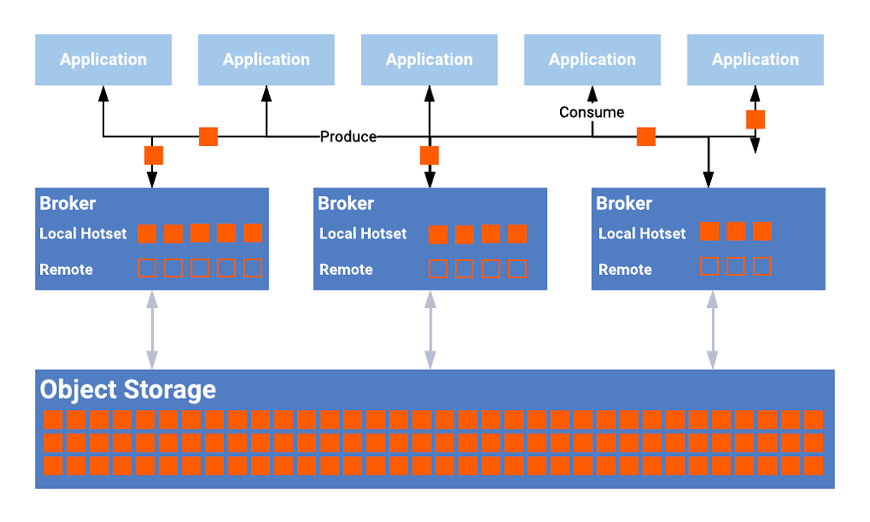
PulsarとKafkaのストレージ層実装の違い
ブローカーの役割
まず、メッセージングプラットフォームの特徴として、ブローカーの存在があります。
メッセージの永続化機能をもつためには、ブローカーは、プロデューサーやコンシューマーに対してサービスを提供する、コンピューティングレイヤーだけでなく、メッセージ永続化を司るストレージ機能を持つ必要があります。
Pulsarのアーキテクチャーの特徴として、プロデューサーやコンシューマーのようなクライアントのアクセスポイントとなるサービスレイヤーと、ストレージレイヤーとが、分離していることがあります。
なおPulsarのストレージレイヤーは、Apache Book KeeperというOSSが用いられており、ブッキーとも呼ばれます。
これに対して、Kafkaでは、ブローカーが内部にストレージ機能を持っています。
ここで、付け加えると、Pulsarの特徴の一つとして、コンテナテクノロジーを想定したクラウドネイティブな設計があります。ここで見たような、Pulsarのコンポーネント化の粒度は、このような背景と考え合わせると、よりよく理解することができます。
なお、Kafkaでは分散環境におけるブローカー間の関係はリーダーとフォロワーからなります。
Pulsarでは、ブローカーはステートレスであるという特徴があります。
つまり、分散環境におけるデータレプリケーションのコントロールは、ブッキーのレベルで発生することになります。
Pulsar:ステートレスブローカー
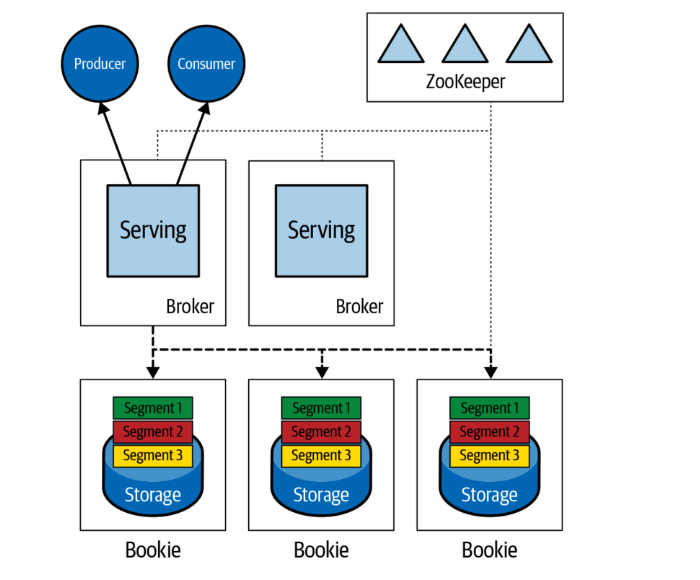
Kafka:リーダー・フォロワーモデルによるメッセージレプリケーション
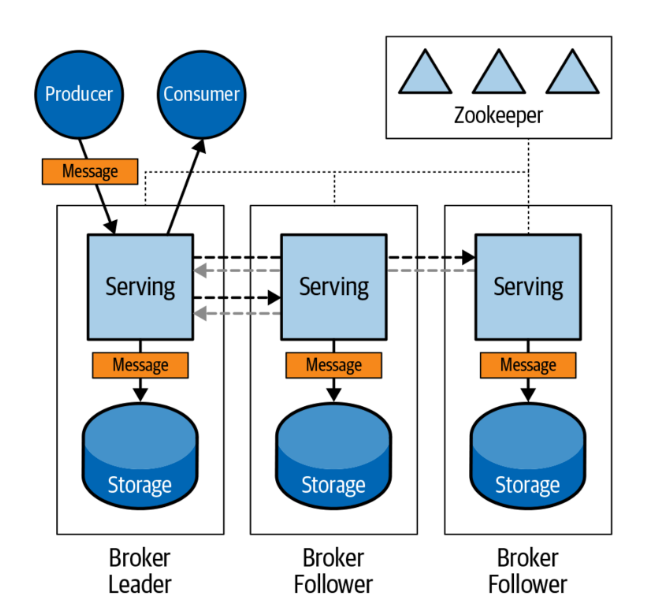
画像は、「Apache Pulsar Versus Apache Kafka」 (Chris Bartholomew著 O'Reilly Media, Inc.刊)より
階層型ストレージ
ここで、さらに永続化層の効率を高めるPulsarの特徴として、階層型ストレージについて紹介します。
Pulsar はコンピューティングとストレージで階層化されているだけでなく、永続化層についても、いわばホットデータとコールドデータとの間を階層化することが可能です。
つまり、頻繁に使われないデータを、より安価なストレージ環境にオフロードすることができます。
これは、自動または手動で実行するように構成可能であり、クライアントに対しては透過的です。クライアントは、データがどこに保存されているかを意識する必要がありません。
Pulsarの機能として階層化ステレージ機能がネイティブに実装されています。
Kafkaについては、 Confluent社が提供するKafkaプラットフォームでは、階層化ストレージ機能が提供されます。
Apache Kafkaにおける階層化ストレージについては、以下のように、実装提案(Improvement Proposal)の段階です。
最後に
本稿では、イベントストリーミングプラットフォームの活用によるKappaアーキテクチャ実装について、特に企業における実際の取り組みに焦点を当てて、紹介しました。
詳細については、各リンクを参照いただくものとし、本記事が、(執筆者にとって自分の中での情報整理の役に立ったように)読者にとって、興味をそそる情報を知る機会となったのであれば幸いです。