はじめに
DB TECH SHOWCASE 2024
2024年7月11~12日、今年もDB TECH SHOWCASEが開催されました。
昨年、一昨年と、スポンサー側で参加させていただきましたが、今年は一般参加者としての参加となりました。イベント全体の変化として、個人的に目を引いたのは、ここ数年は設けられていなかった展示会ブースが再開されたことでした。
この記事の成立事情
今回、初日の17日の12:30からROOM Bで開催されたAWS社によるセッション「Aurora PostgreSQL x 生成AI: 既存データの力を最大限引き出す新しい仕掛け」に参加しました。セッションの最後に、「このセッションについてのブログを書きませんか?」というスピーカーの新久保浩二氏からの呼びかけがあり、良い機会なので、またなによりセッションの内容が興味深いものだったので、手を挙げた、というのがこの記事の成立の経緯です。
生成AIとデータベースの関わり
「生成AIとデータベースの関わり」、これ自体、このようなイベントで参加者の背景に前提を置かない場面では、それなりに時間をとられるテーマであり、実際セッションでは、そこから始められましたが、この部分は、ある種典型的な部分で、また特にAWS、Aurora、あるいはPostgreSQLに固有なものでもないため、この記事では割愛します。代わりに手前味噌ですが、いくつか私の発表した記事等を紹介しておきます(昨今では、ほかにもいろいろと有用な記事を探すことが簡単にできるでしょう)。
「名寄せ」について
新久保氏のセッションでは、典型的なよくある(関連ドキュメントを検索してLLMのプロンプトに含めるという)RAGの構成とは異なる視点を提供してくれています。それ、すなわち(本記事のタイトルに含めた)「名寄せ」のユースケースということですが、この「名寄せ」という用語にも、一応説明が必要かと思いますので、ここで簡単に。
「名寄せ」という言葉の本来の(元々の)意味、使われ方としては、以下のWikipediaにもあるように「金融機関において、複数口座を開設している顧客の預金額を一つにとりまとめる業務」であり、「転じて、金融機関や預金額に限らないデータのとりまとめ全般を指す場合もある」というものだとして…
…つまりこのレベルでは、テクノロジーの要素は関わらないわけですが、現在ではむしろ、以下の記事などに代表されるように「名寄せとは、複数のデータベースに登録されている顧客情報から、重複する部分を洗い出し、一つに統合する作業」といったように、まずデータベースありきの文脈で使われることが一般になっている印象です(とはいえ、これもあくまで界隈の業界に身を置くものとしての「印象」であって、こういったことを触れずに進めるのはフェアではないという意識で冗長と思う人も多いと思いますが、記しています)。
Aurora PostgreSQL x 生成AI
AWSの生成AI関連サービス
まず、AWSの生成AI関連サービスについては、公式のサイト以外にも、様々な記事を見つけることができると思いますが、ここでは自分なりに整理してみます。これは次のように整理できると思います。
- 独自の(AWSプロプライエタリの)LLM
- ベクトル検索機能を提供する複数のサービス(サードパーティーを含む)
- 上のふたつを統合する生成AIアプリケーション開発プラットフォーム(Bedrock)。ここでは、以下が利用可能
- AWSプロプライエタリのLLMとサードパーティーのLLM
- AWSプラットフォームで利用できるベクトル検索機能を提供するサービス(の一部)
発展の早い分野として、モデルやサービスのラインアップは、将来的に変わる(増える)と思いますが、まずは上のように整理できるかと思います。ここで重要なのは、 AWSプロプライエタリのLLMをBedrockと組み合わせずに利用することもでき、それはベクトル検索サービスについても同様ということと、加えてBedrockで利用できるベクトル検索サービスは、AWSが提供するベクトル検索サービス全体と一致しているわけではい、ということかと思います。
技術者としては、このような境界を意識していることは、重要かとも思い(例えば、以下で取り上げる要素としては、PostgreSQLのクエリ構文と、Bedrockに関連した関数は、異なるレベルにある、というようなこと)、スタート地点として上記記しました。
生成AI関連技術を「名寄せ」に用いる試み
それでは、ここから本題に入ります。
ここからは、セッションで用いられたスライドから抜粋し、説明(ブログ筆者としての)を加える形で進めます。
さて、まずここで活用される「生成AI関連技術」としては、以下に大別できます。
- ベクトル検索
- エンベディング
- LLM
ベクトルデータベースの利用
まずは、ベクトルデータを保存するテーブルが必要です。

エンベディングの利用
そして、元データからベクトルデータに変換するためのエンベディングモデルが必要になります。


ここでは、データベースに格納されているデータをBedrockの機能を活用して、SQLのUPDATEクエリ中でエンベディング化し、同じレコードの別のカラムに格納しています。
Bedrockの関数呼び出しの例としてはわかりやすいですが、個人的にはエンベディングモデルを大量データに対して使う場合には、多くのエンベディングモデルでバッチ処理による変換のAPIが用意されているように、エンベディングとデータベース更新は、別個に行うのが実践的かという気がしています。
(多くのRAGでは、ユーザーインプットをエンベディングして、DBに格納されているエンベディング済みデータと比較することが多いので、このようなインプット単体のデータのエンベディングには、関数呼び出しが活躍するかと思います)
可能性としては、AWSのサービス間の連携がプラットフォーム内部で最適化されるというもあるかもしれませんが...
ベクトル検索の利用
そして、追加されたベクトルデータ同士の比較により類似度のスコアを求めます。

そして、類似度を基準にデータの同一性を判断する、というのが基本の考え方になります。
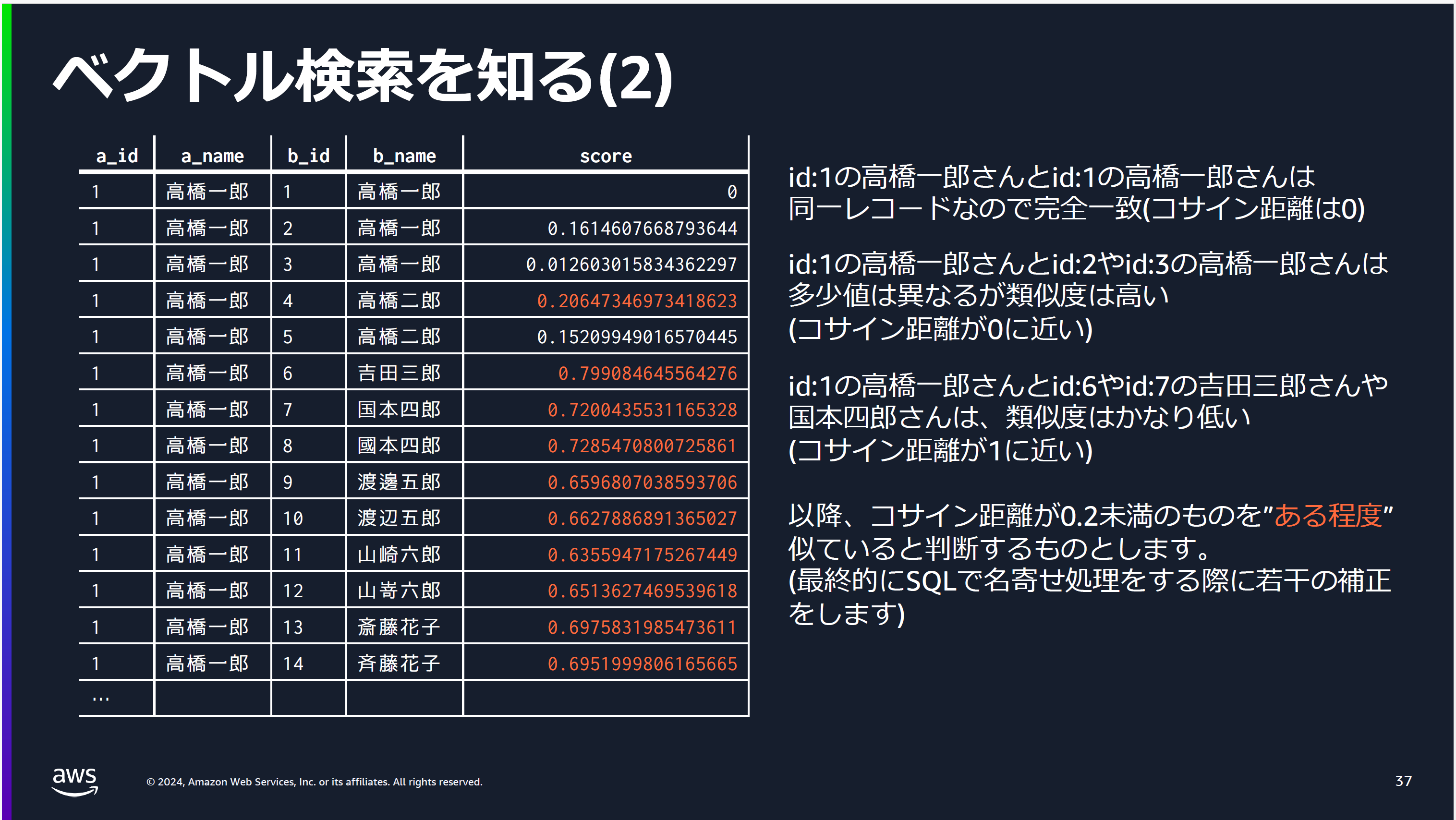

ここまでは、エンベディングモデルとベクトルデータベースが提供する自然言語同士の比較という能力を借りて、名寄せを行うというものでした。
あくまで、これらの技術を使った概念検証というところで、名寄せの専門家から見ると(わたしがそうだというのではありません)、いろいろと意見はあるのだろうという気もしますが、なかなか他ではお目にかかることのできない貴重な試みだと思います。
LLMの利用
次のステップとしてLLMを名寄せに用いる方法も紹介されています。


このスライドのみでは、(割と見かけるLLMの使い方の変奏として)ふうん、と感じるかもしれません。後で紹介しますが、新久保氏は、これらの一連の処理をストアドプロシージャとして実現するという力業を実際に行われており、単純にすごいと思わされます。
おわりに
本セッションで紹介されたのは、あくまでひとつの例、ないし提唱とでもいうものだと思います。セッションでは住所録の名寄せのほかに、より類似性の判定においてLLMの知識を前提にすることのできる例(医薬品の成分による類似性)についても紹介されていました。ここで行われていることそのものを、そのままの形で実行しようとされる方はいないかと思いますし、新久保氏も想定されていないと思いますが、こういった他にみないユースケースを、コンセプトのみではなく、実際のコードとして示されることは、非常に示唆的と感じます。
ご注意
AWS新久保氏もセッションのはじめにお話しされていましたが、この記事で提供する情報については、その正確性に注意を払われてはいるものの、誤りが含まれている可能性もあり、またブログ記事として、読者の閲覧時点の最新の情報に対して更新されるものではありません。最新かつ正確な情報について、つねにAWS社の公式ウェブサイト(https://aws.amazon.com)に当たっていただきますようお願いいたします。
補足情報など
以下、新久保氏よりご提供いただいた情報を中心に、補足情報を提供させていただきます。
AWS環境設定参考情報
クラウドサービスである、Bedrockで基盤モデルを利用する際には、事前にBedrock側で利用したい基盤モデルのアクセスを設定しておく必要があり、また、どんなモデルが利用できるかは、各リージョンにより異なっています。その点について、以下が参考になります。
詳細な内容については、先述したようにドキュメント本編にあたっていただきたいと思いますが、例えば、Aurora PostgreSQLのpublic accessが設定されていない場合は、Bedrockに対するVPC Endpointの設定が必要になる、といったサービス間の関連を意識している必要があります。
また特に、Aurora PostgreSQLからBedrock APIへアクセスするためには固有の事前準備があり、この点については、Classmethod社による、以下のブログが参考になります。
参考スクリプト
今回紹介させていただいたセッションに強い興味をひかれた理由として、単なるサービスの紹介あるいは一般的な技術動向の紹介に終わるのではなく、実践的なユースケースへの適用の試みが含まれていることでした。今回新久保氏から、氏が実際に動かされた以下のストアドプロシージャをご提供いただきました。各構成要素を個別にみることでもたいへん参考になると思いますので、全体の解説などは割愛しますが、ここに掲載させていただきます(スクリプトとしての動作や副作用に対して何等か保証されるものではないため、利用に関しては、ご自身の責任でお願いします)。「構成要素」として、以下のような点に注目できます。
- LLMへのプロンプトの書き方
- pgvectorベクトル検索クエリの構文
- 名寄せ情報生成のための複数SQLクエリの組み合わせ
create or replace procedure nayose(distance float default 0.2, rag_feature boolean default false)
language plpgsql
as $$
declare
currow record;
prompt text := '';
prompt_start text := '{"anthropic_version": "bedrock-2023-05-31", "system": "", "messages":[{"role": "user", "content": "以下<list></list>タグの中に氏名,住所,性別,電話番号のリストがあります。\n<list>\n';
prompt_end text := '</list>\nこのリストを氏名、住所、性別、電話番号で名寄せしてください。その際に表記ゆれを考慮してください。また回答では住所の番地をハイフンで表記する方法に統一してください。電話番号もハイフンを使う方式に統一してください。回答は名寄せ後のカンマ区切り形式のリストを表示してください。また、前置きなしで回答を出力して下さい。"}], "max_tokens": 4096, "temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}';
msg text;
cur CURSOR for WITH
t1 AS (
select a.id a_id
,b.id b_id
,a.name a_name
,a.addr a_addr
,a.sex a_sex
,a.phone a_phone
,a.embedding <=> b.embedding as score
from address a, address b
where a.embedding <=> b.embedding > 0
and a.embedding <=> b.embedding < distance
and a.id < b.id)
,t2 AS (
select a.a_id
,a.b_id
,a.a_name
,a.a_addr
,a.a_sex
,a.a_phone
,a.score
from t1 a
where a.a_id not in (select b_id from t1))
,t3 AS (
select t.a_id
,array_agg(t.b_id) b_id
,max(t.a_name) a_name
,max(t.a_addr) a_addr
,max(t.a_sex) a_sex
,max(t.a_phone) a_phone
,min(t.score) min_score
,max(t.score) max_score
from t2 t
group by a_id)
select t1.id id
,t1.name name
,t1.addr addr
,t1.sex sex
,t1.phone
,cast(null as double precision) min_score
,cast(null as double precision) max_score
from address t1
where t1.id not in (select a_id from t3)
except
select t1.id id
,t1.name name
,t1.addr addr
,t1.sex sex
,t1.phone
,cast(null as double precision) min_score
,cast(null as double precision) max_score
from address t1
where t1.id in (select unnest(b_id) from t3)
union all
select a_id id
,a_name name
,a_addr addr
,a_sex sex
,a_phone phone
,min_score
,max_score
from t3
order by 1;
begin
open cur;
loop
fetch cur into currow;
if not found then
exit;
end if;
raise info '%,%,%,%', currow.name, currow.addr, currow.sex, currow.phone;
prompt := prompt||currow.name||','||currow.addr||','||currow.sex||','||currow.phone||'\n';
end loop;
close cur;
if (rag_feature = true) then
select regexp_replace(replace((aws_bedrock.invoke_model (
model_id := 'anthropic.claude-3-sonnet-20240229-v1:0',
content_type:= 'application/json',
accept_type := 'application/json',
model_input := prompt_start||prompt||prompt_end
)::json#>'{content,0,text}')::text, '"', ''), '\\n', chr(10), 'g') into msg;
raise info '%', msg;
end if;
end
$$;