先月、2026年2月3日にDatabricks LakebaseのAWS版がGAされました。
https://www.databricks.com/jp/blog/databricks-lakebase-generally-available
本記事ではLakebaseの試してみた記事となります。
以下のようにDatabricks Appsを介してユーザーがLakebaseのデータを取得できるまでを試してみます。

Lakebaseとは
DatabricksのLakebaseは、レイクハウス(分析基盤)に統合されたフルマネージドのPostgresデータベースサービスです。従来、OLTPデータベースと分析基盤は別々に管理する必要があり、データの同期やETL処理が必要でした。LakebaseはストレージとコンピュートをDatabricks上で分離・統合することで、アプリケーションのトランザクション処理と分析処理を同一プラットフォームで扱えます。オートスケーリングやゼロスケール、データベースのブランチングといった機能も備えており、AIエージェントやアプリ開発のバックエンドとして使うことを主なユースケースとして想定しています。
※ちなみに現在Free Editionでは提供されていないようです。
Lakebaseの立ち上げ
databricksのコンピュート画面からデータベースプロジェクトを作成
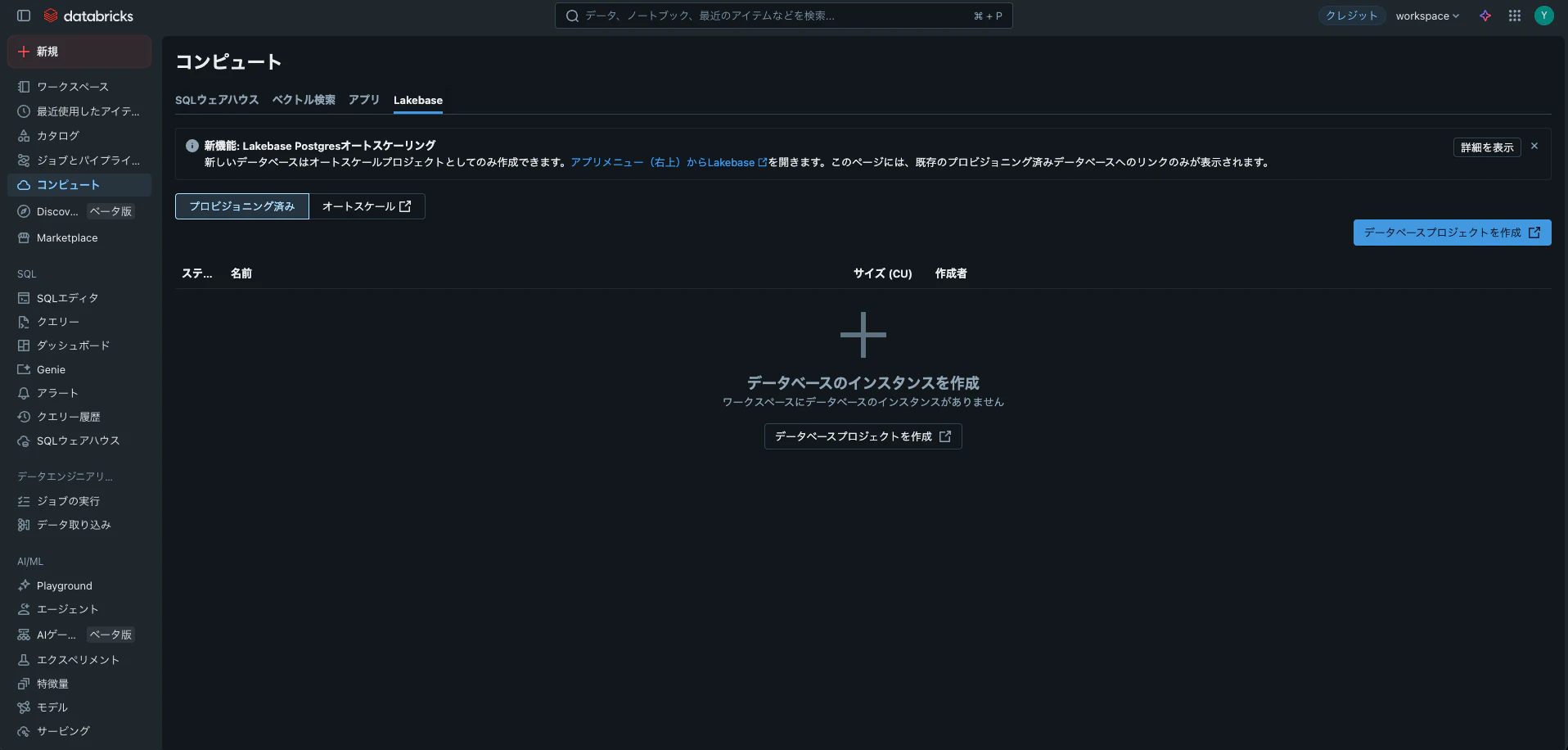
今回はjunjun-lakebase-projectという名前のプロジェクト名で作成します。
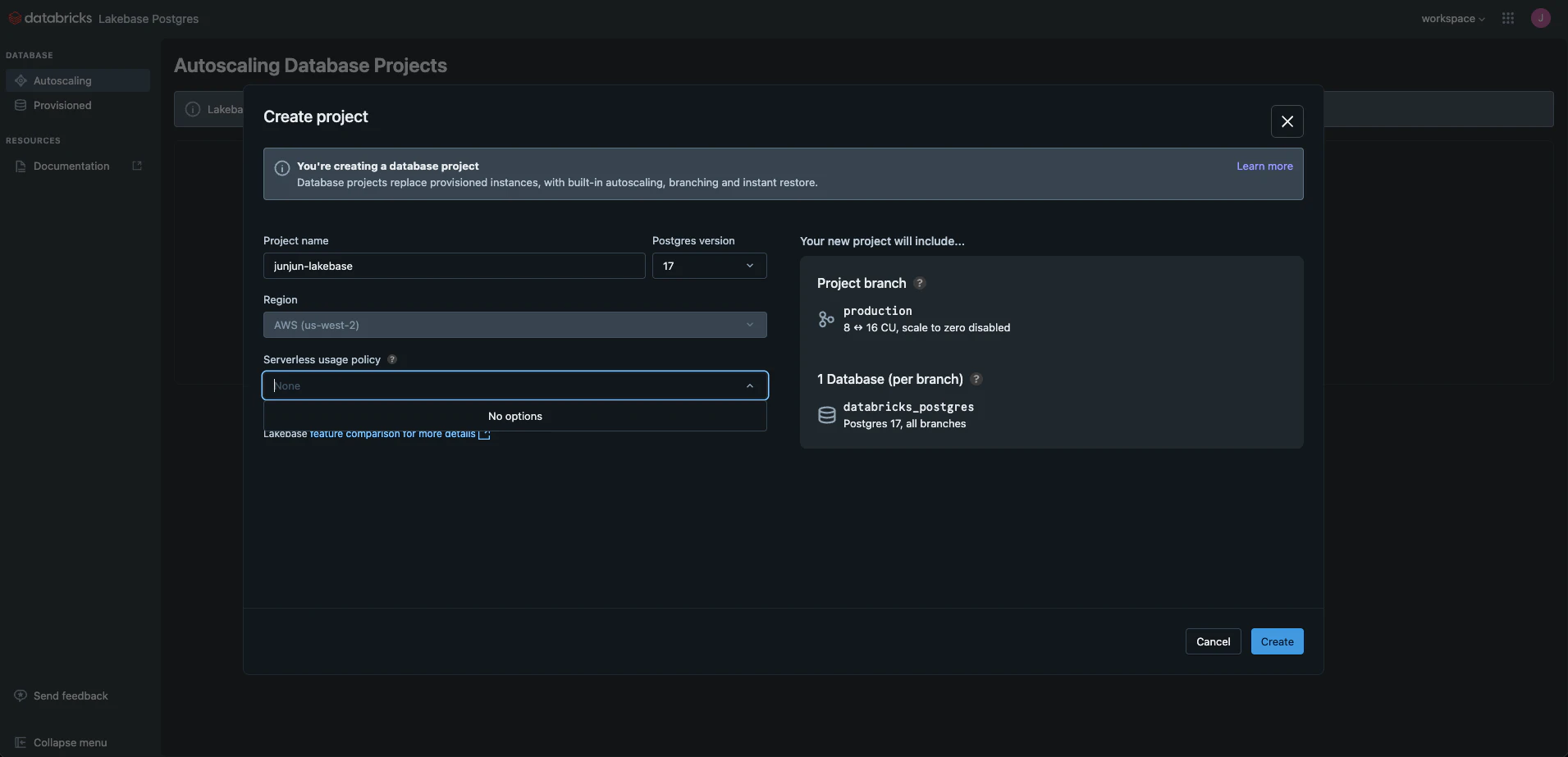
これでプロジェクト(PostgresDB)が作成されました。
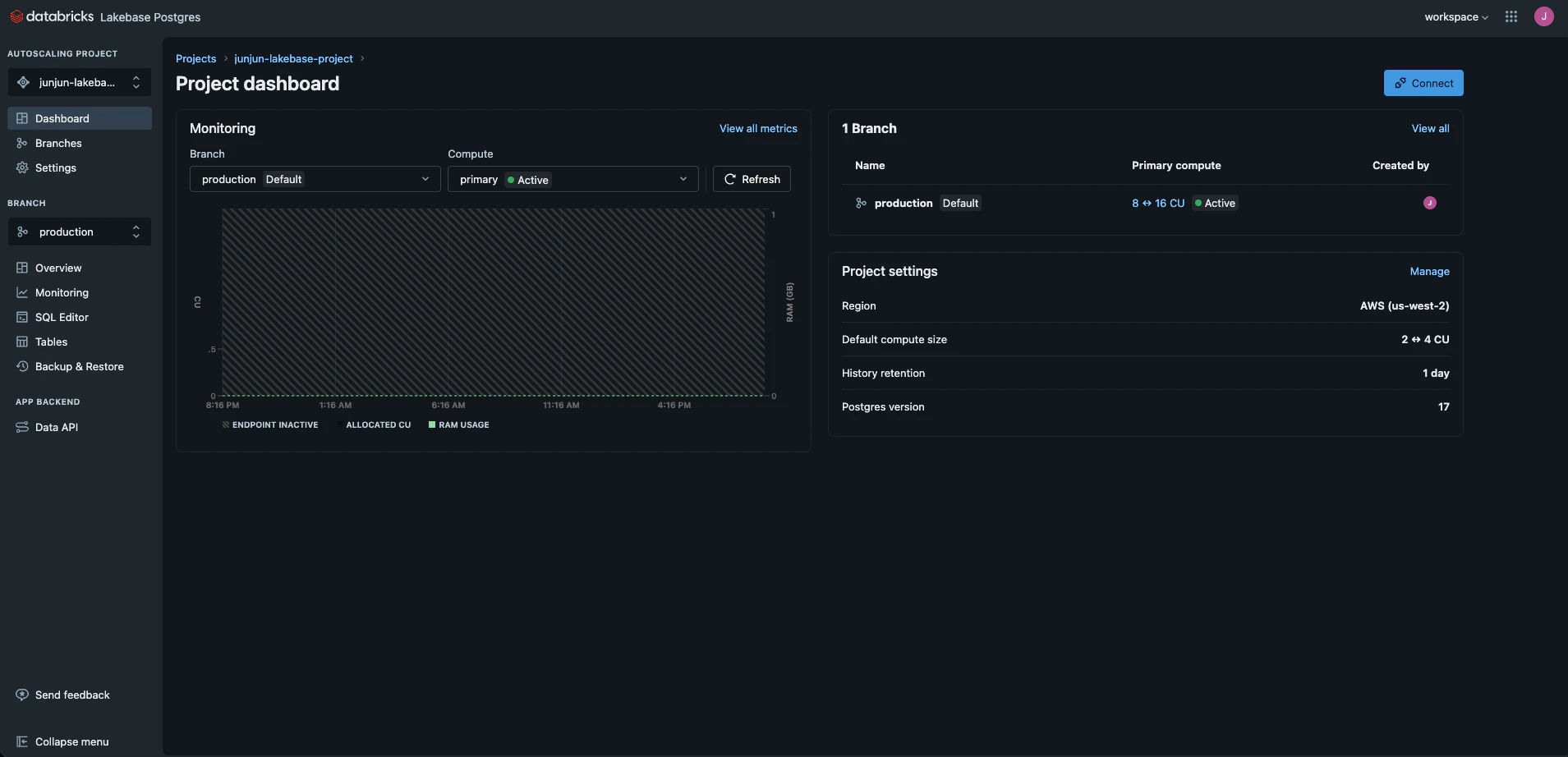
Overviewの画面です。
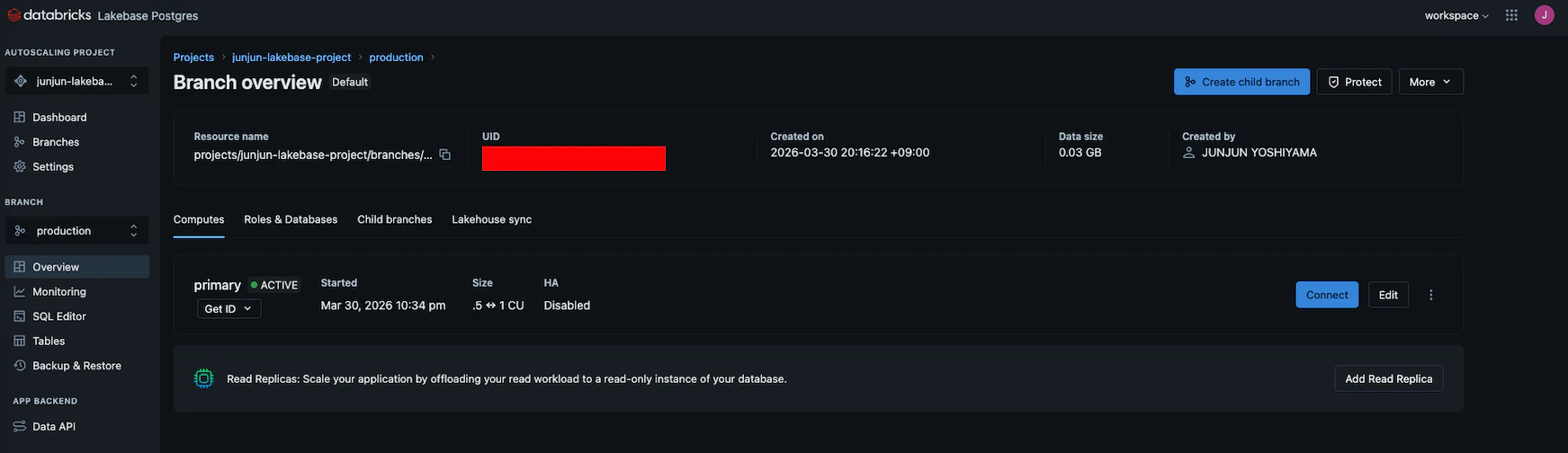
Editのボタンを押すとLakebaseのコンピューティングリソースの設定画面が開かれます。
この画面でオートスケールやスケールゼロの設定ができます。また静的パスワードを利用する場合はこちらのチェックが必要なようです。
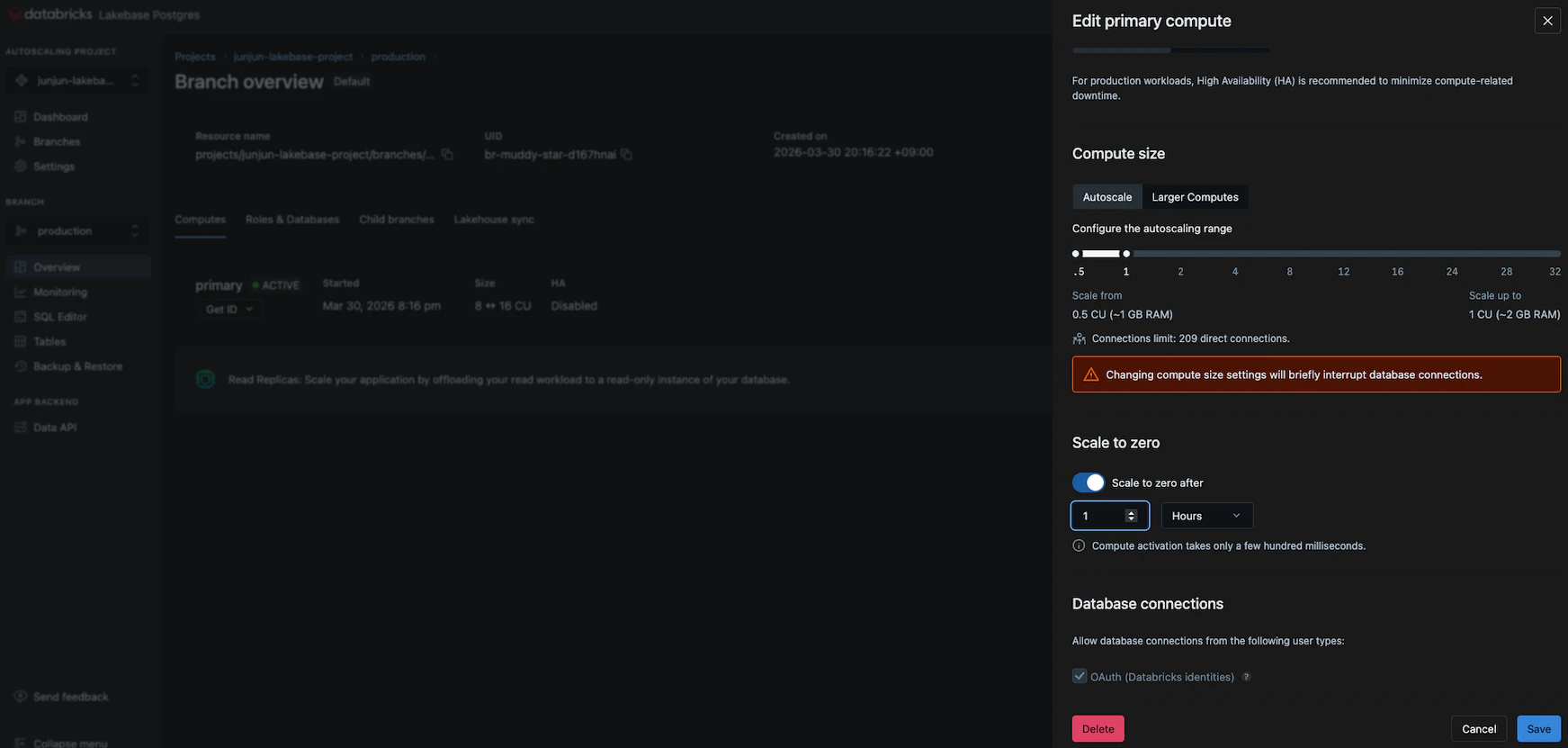
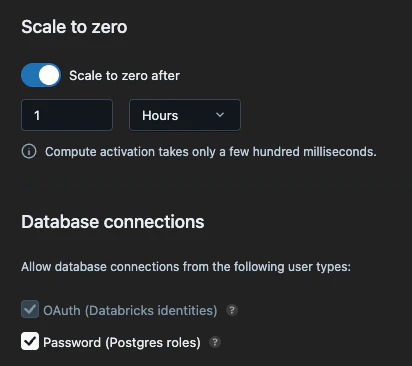
Connectのボタンを押すと接続の設定画面が開かれます。
Lakebase の認証は通常のパスワードではなく OAuth トークンで行われ、このトークンの有効期限は 60 分です。
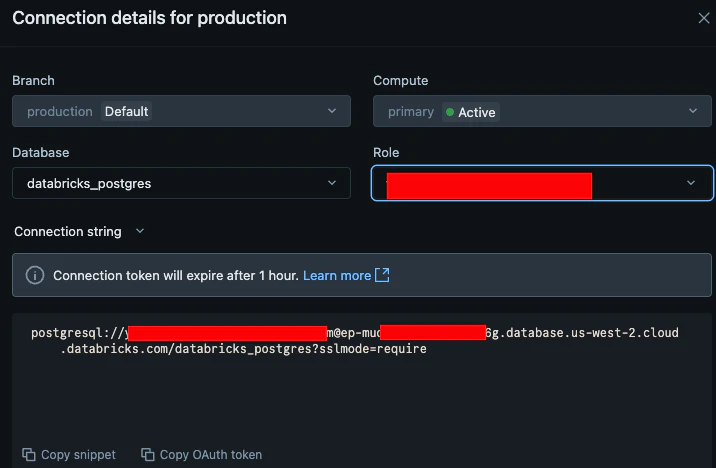
ここで設定画面にて表示された接続コマンドを試してみます
% psql 'postgresql://XXXX@XXXX.database.us-west-2.cloud.databricks.com/databricks_postgres?sslmode=require'
ユーザー XXXXX のパスワード:
psql (18.3 (Homebrew)、サーバー 17.8 (6108b59))
SSL接続(プロトコル: TLSv1.3、暗号化方式: TLS_AES_256_GCM_SHA384、圧縮: オフ、ALPN: なし)
"help"でヘルプを表示します。
databricks_postgres=>
※パスワードはOAuth Tokenになります。
psqlコマンドでDBと接続できたことを確認できました。
検証用のテーブル作成
LakebaseでPostgreDBを立ち上げられましたが、まだDB内にテーブルがないのでデータを作成していきます。
databricks上のクエリでサンプルデータセットのデータをつかって同期させるためのテーブル(5000行分)を作成します。
※testというカタログを事前に作成する必要があります。
CREATE TABLE test.default.orders_for_sync
AS SELECT * FROM samples.tpch.orders limit 5000;
作成したテーブルのカタログから作成→同期テーブル
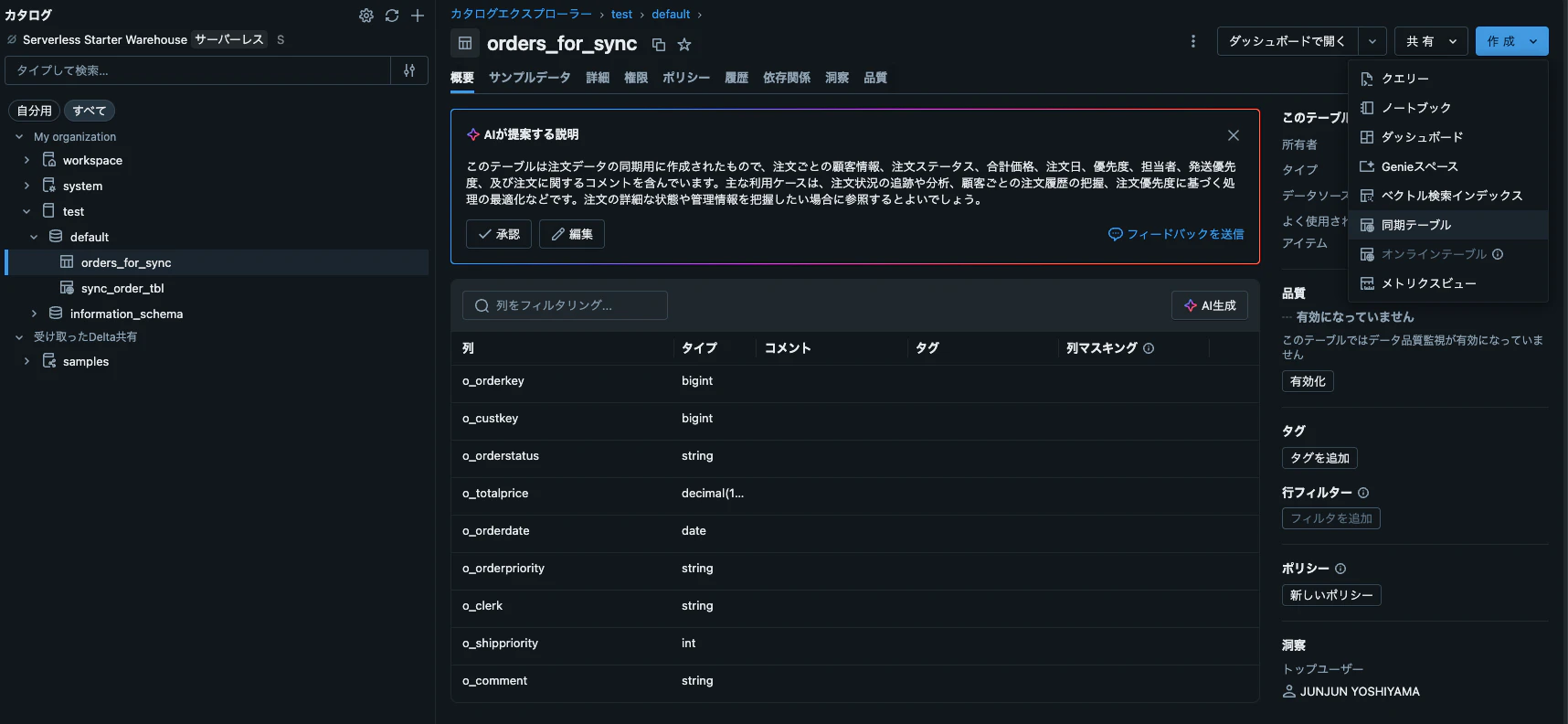
先ほど作成したLakebaseの情報を入力します。
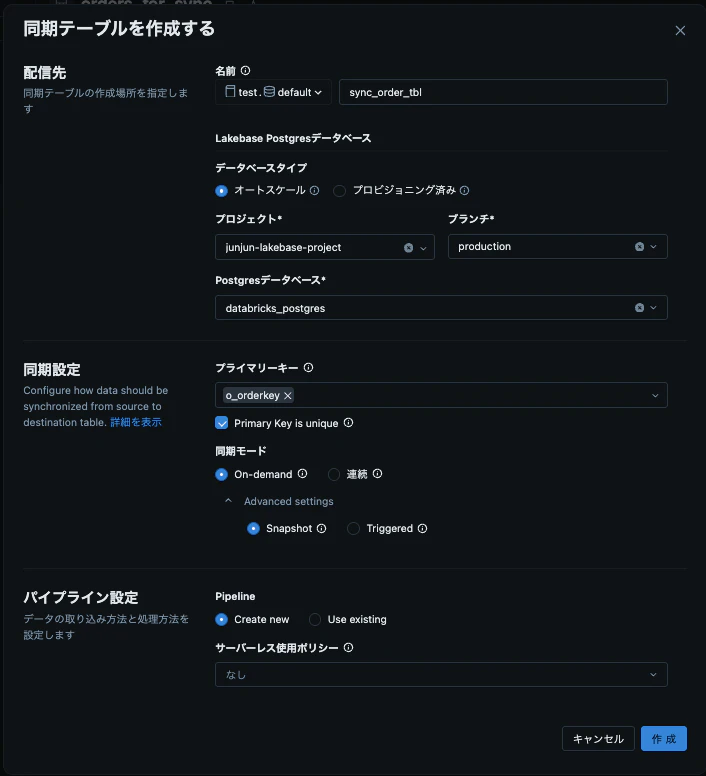
作成を押すとパイプラインが作成されdatabricksとLakebaseのデータが同期されます。
ちなみに同期する方法は以下があります。ユースケースによって選択するのがよいかと思います。
- Snapshot:一度だけ全件コピー
- Triggered:手動または定期的に差分を反映
- Continuous:継続的に差分を反映
今回は検証なので一度きりスナップショットで同期させました。
同期させた後は、LakebaseのSQL Editorの画面できちんとデータが取り込まれているのか確認します。
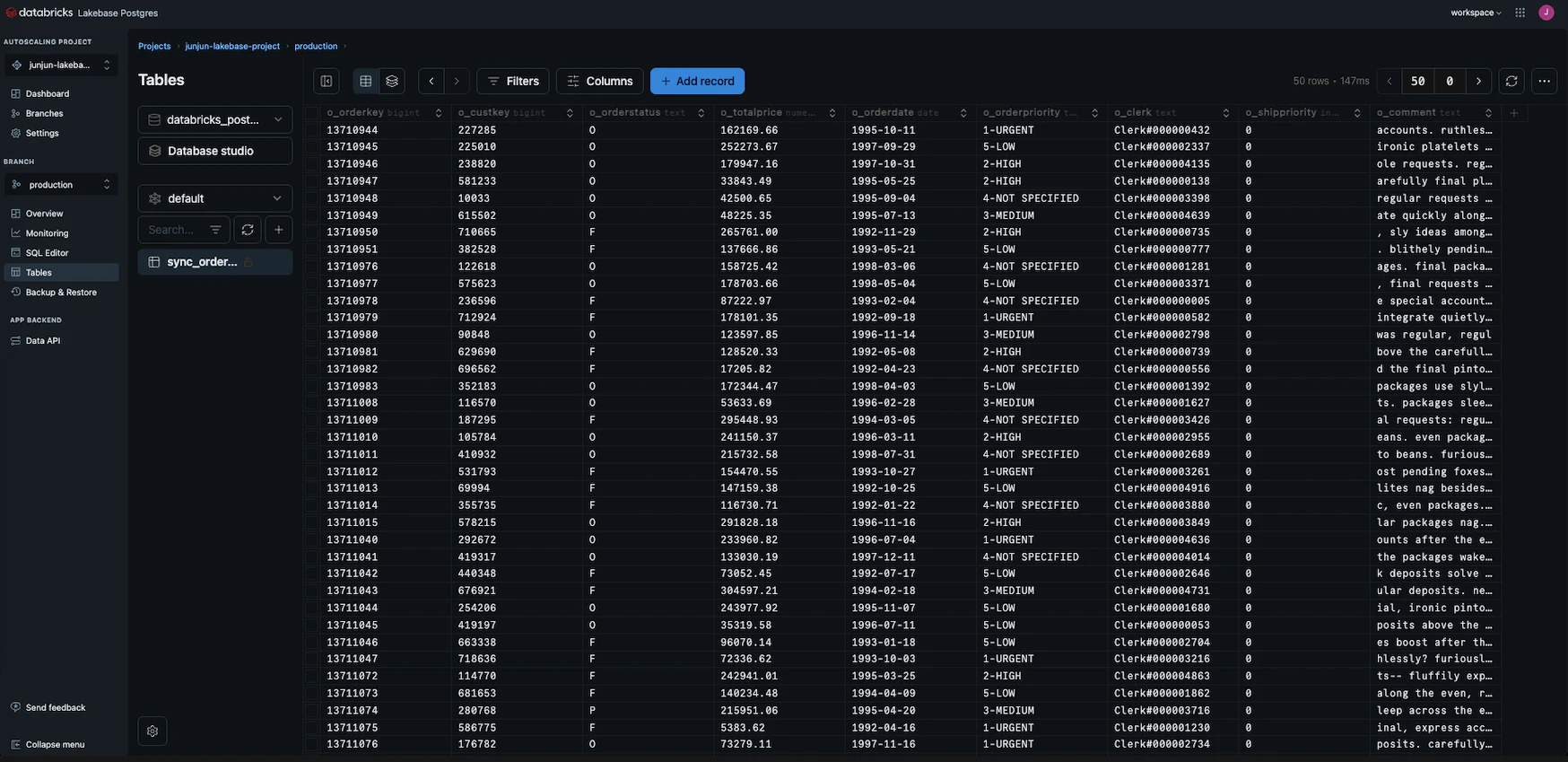
これでDB側の準備はOKですね。
databricks appsでDB用のAPIを作成する
① Databricks Appを作成する
databricksのTOP画面から新しいアプリを作成します。
テンプレートはFlask Hello Worldなどを選んで一旦作成します(後でコードを差し替えます)。
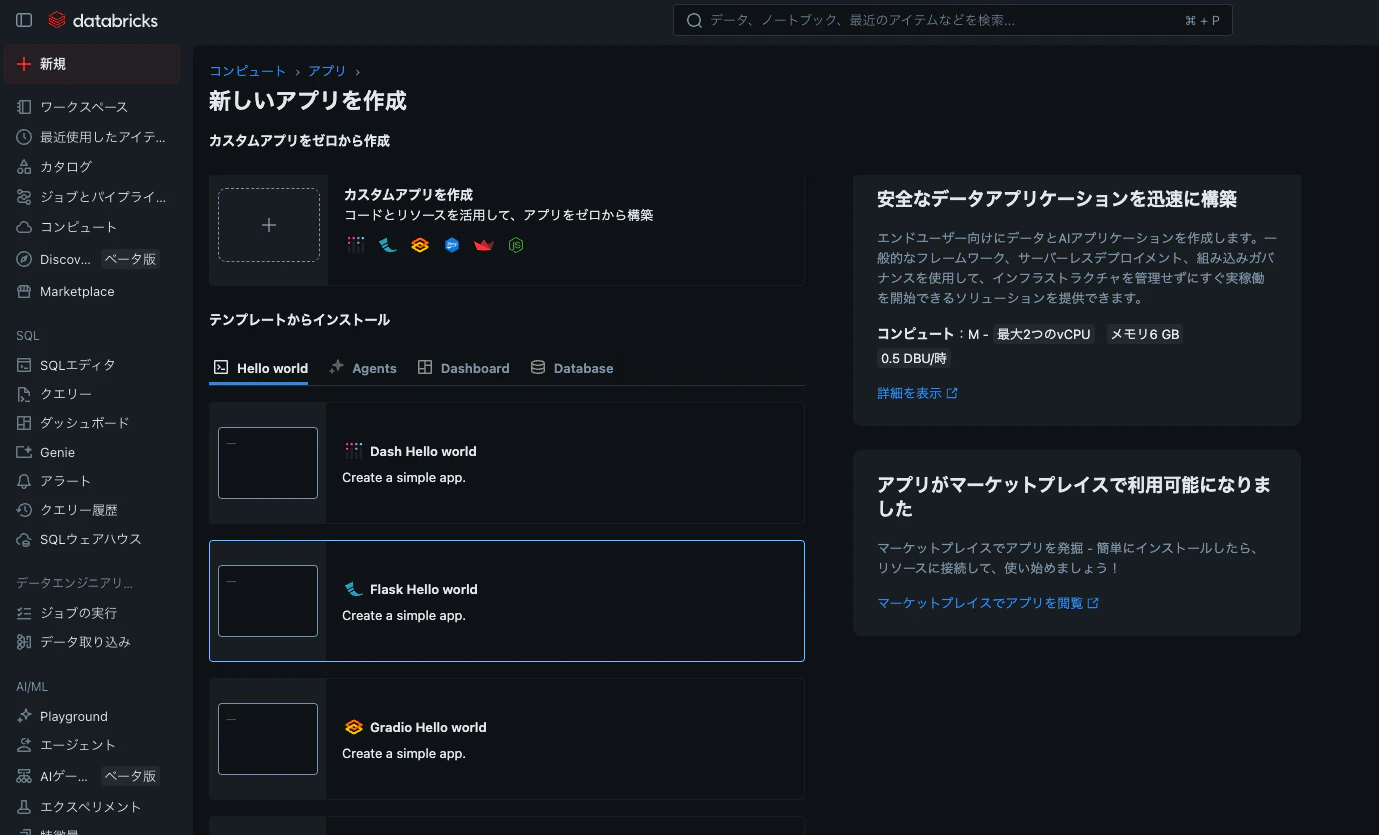
今回はdb-appという名前で作成します。
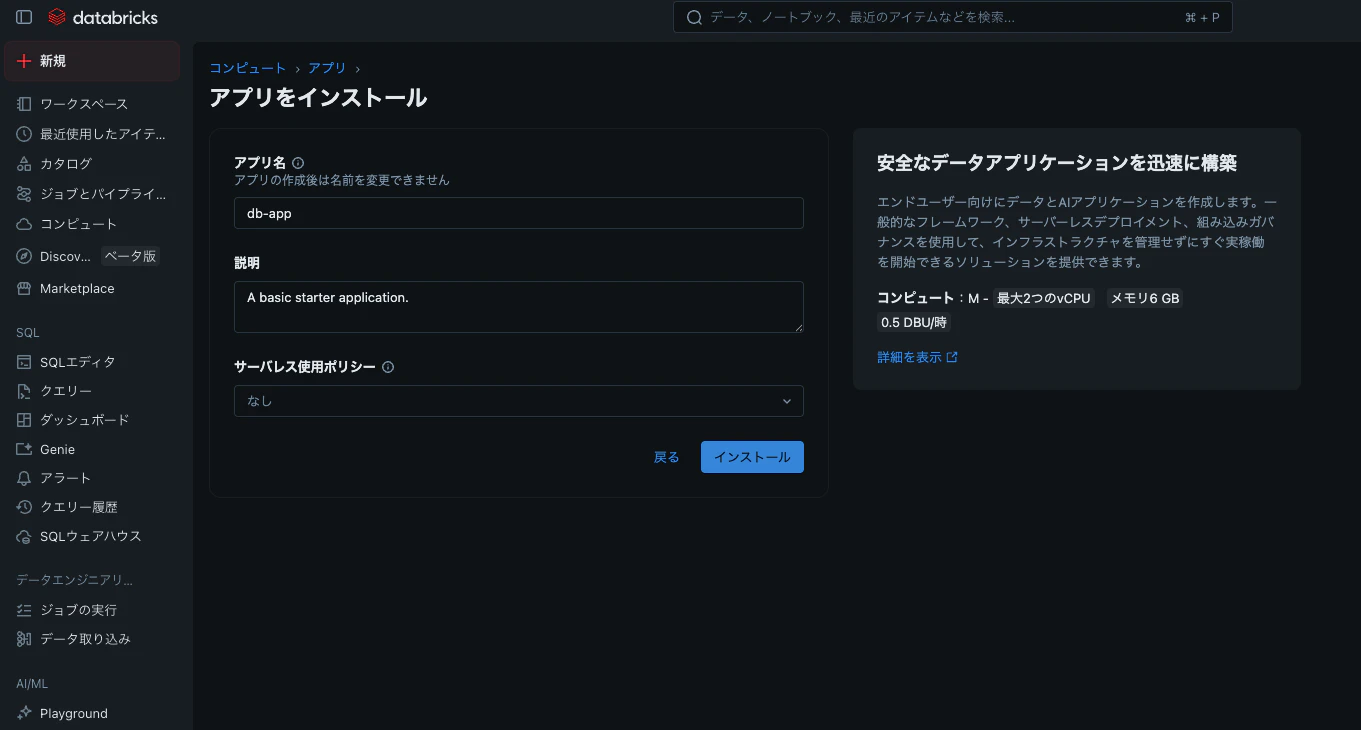
これでdatabricks appを作成できました。
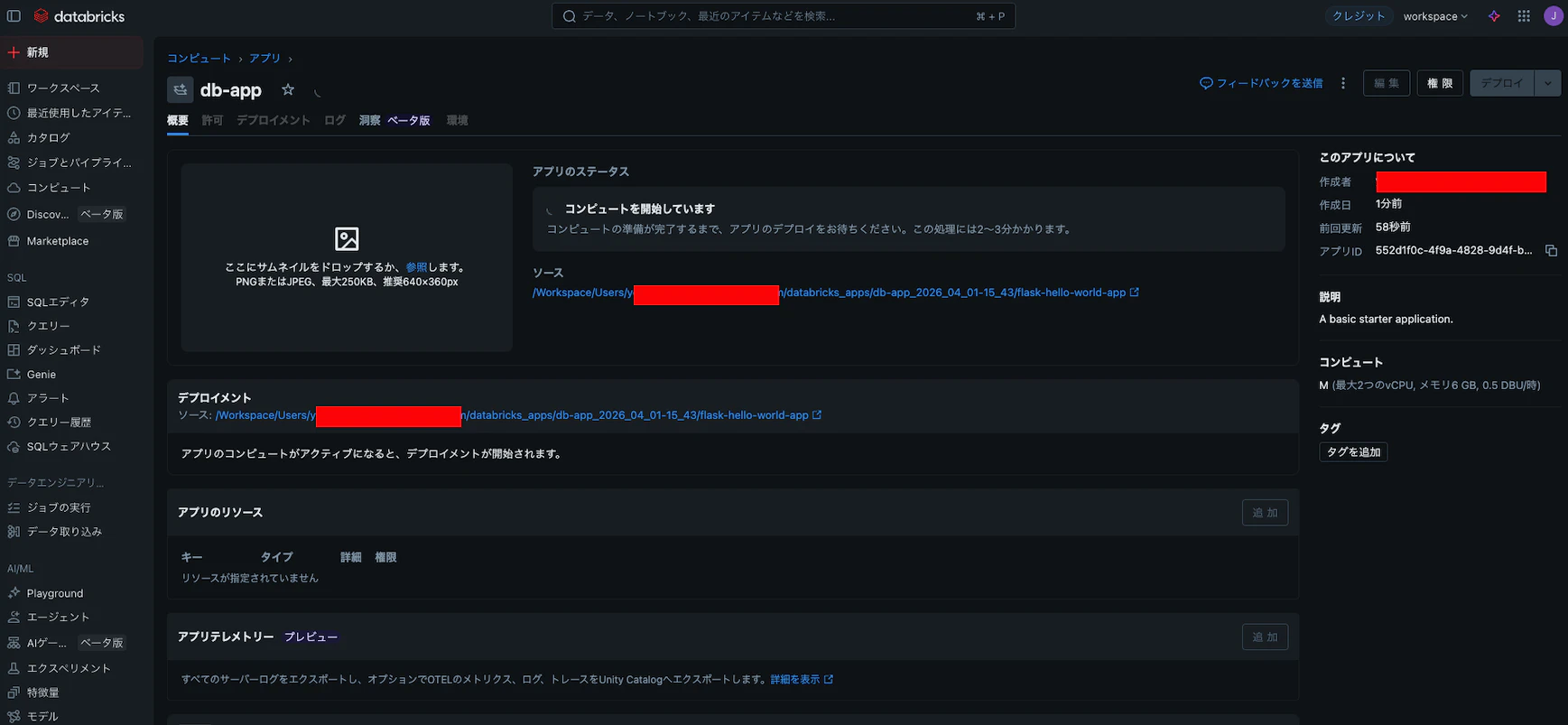
② DATABRICKS_CLIENT_IDを控える
作成したAppのEnvironment(もしくは環境)タブを開き、DATABRICKS_CLIENT_ID の値(UUIDの形式)を控えておきます。これがPostgresのユーザー名になります
③ LakebaseでAppのロールを作成する
-- OAuthトークン認証を有効化
CREATE EXTENSION IF NOT EXISTS databricks_auth;
-- Appのサービスプリンシパル用ロールを作成
SELECT databricks_create_role('<DATABRICKS_CLIENT_ID>', 'service_principal');
-- 接続・スキーマ・テーブルの権限を付与
GRANT CONNECT ON DATABASE databricks_postgres TO "<DATABRICKS_CLIENT_ID>";
GRANT USAGE ON SCHEMA "default" TO "<DATABRICKS_CLIENT_ID>";
GRANT SELECT ON TABLE "default".sync_order_tbl TO "<DATABRICKS_CLIENT_ID>";
※"default" をダブルクォートで囲むのはdefaultがPostgreSQLの予約語のため
④app用のコードを書き換える
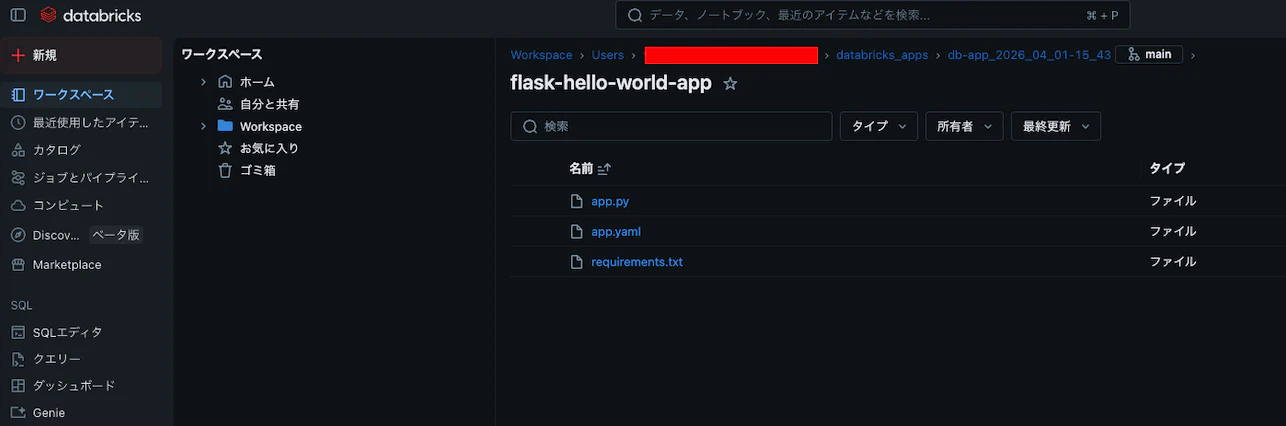
ファイル構成:
app/
├── app.yaml
├── app.py
└── requirements.txt
app.yaml:
command: ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
requirements.txt:
fastapi
uvicorn
sqlalchemy
asyncpg
databricks-sdk
app.py:
import os
from fastapi import FastAPI
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy import text
from databricks.sdk.core import Config
app = FastAPI()
def get_token() -> str:
config = Config()
return config.oauth_token().access_token
def make_engine():
token = get_token()
host = os.environ["PGHOST"]
db = os.environ["PGDATABASE"]
user = os.environ["PGUSER"]
port = os.environ.get("PGPORT", "5432")
url = f"postgresql+asyncpg://{user}:{token}@{host}:{port}/{db}?ssl=require"
return create_async_engine(url, pool_size=3)
@app.get("/orders")
async def get_orders(limit: int = 10):
engine = make_engine()
async with AsyncSession(engine) as session:
result = await session.execute(
text('SELECT o_orderkey, o_custkey, o_totalprice FROM "default".sync_order_tbl LIMIT :limit'),
{"limit": limit}
)
rows = result.mappings().all()
return [dict(r) for r in rows]
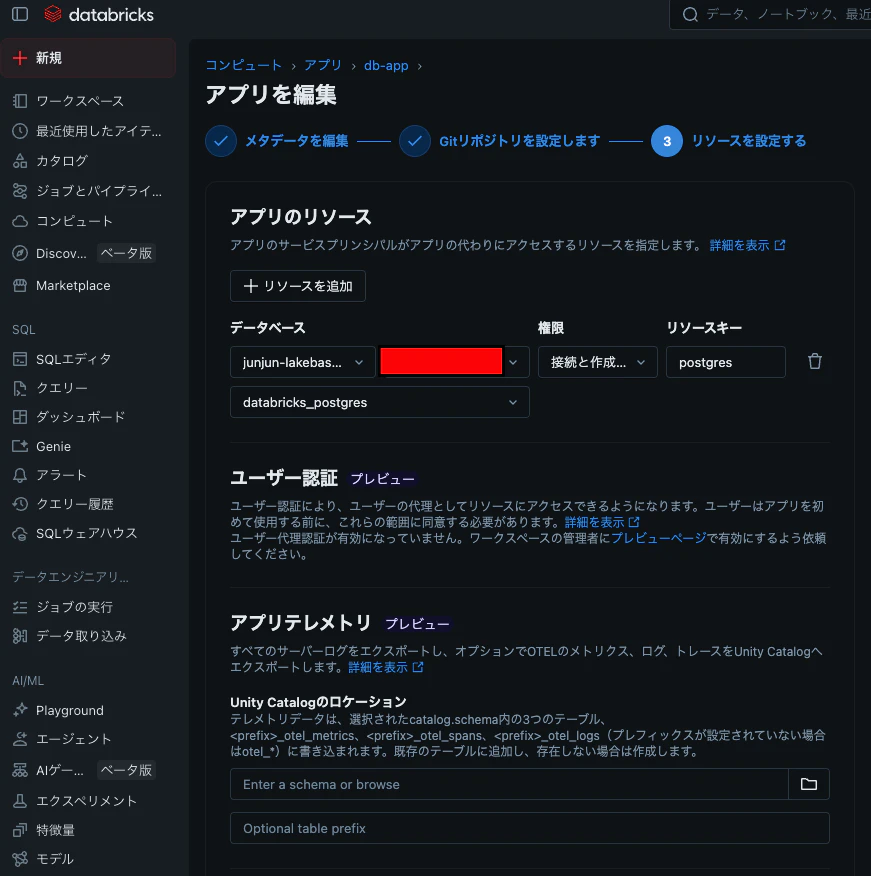
⑤ AppにLakebaseリソースを追加する
Appの設定画面でResourcesにLakebaseプロジェクトを追加します。これで④のコード内で使用する環境変数が自動で設定されます。
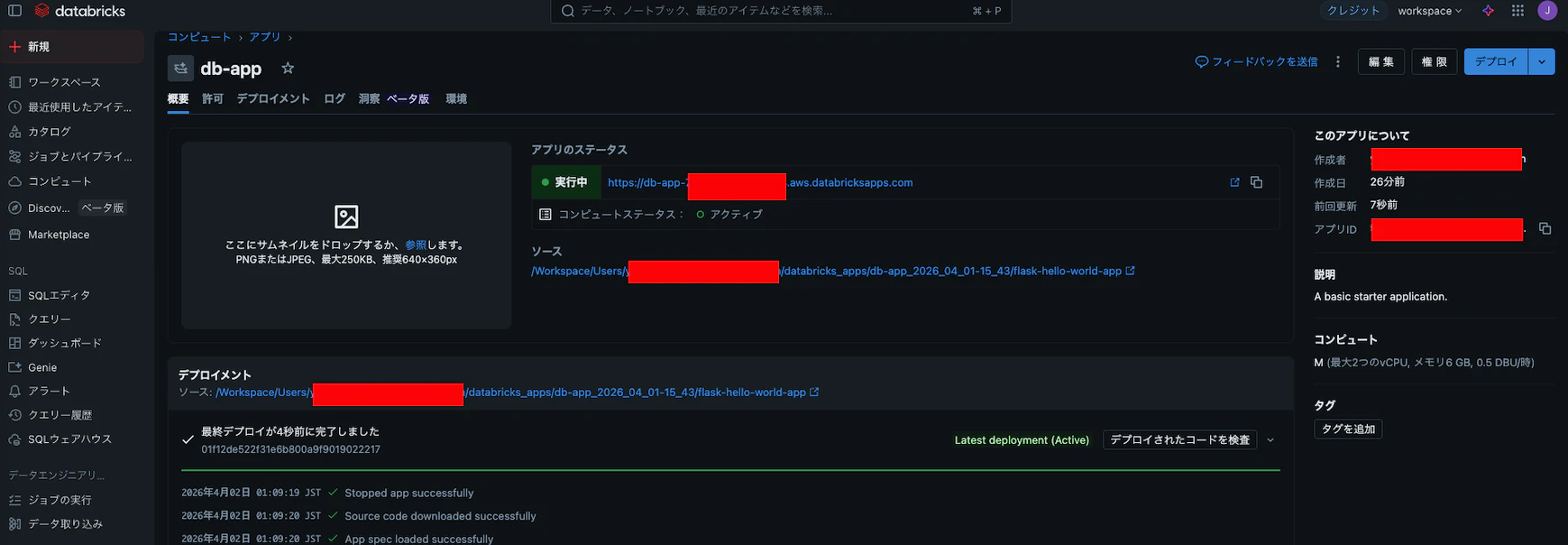
⑥デプロイして確認する
Databricks CLIでデプロイ、またはUIからソースをアップロードしてデプロイします。デプロイ後、AppのURLに対して以下で動作確認します。
取得検証コマンドと結果
% curl https://db-app-xxxx.aws.databricksapps.com/orders \
-H "Authorization: Bearer <OAuthトークン>"
[{"o_orderkey":13710944,"o_custkey":227285,"o_totalprice":162169.66},{"o_orderkey":13710945,"o_custkey":225010,"o_totalprice":252273.67},{"o_orderkey":13710946,"o_custkey":238820,"o_totalprice":179947.16},{"o_orderkey":13710947,"o_custkey":581233,"o_totalprice":33843.49},{"o_orderkey":13710948,"o_custkey":10033,"o_totalprice":42500.65},{"o_orderkey":13710949,"o_custkey":615502,"o_totalprice":48225.35},{"o_orderkey":13710950,"o_custkey":710665,"o_totalprice":265761.0},{"o_orderkey":13710951,"o_custkey":382528,"o_totalprice":137666.86},{"o_orderkey":13710976,"o_custkey":122618,"o_totalprice":158725.42},{"o_orderkey":13710977,"o_custkey":575623,"o_totalprice":178703.66}]
無事、データを取得できました。
これにて検証完了です。
今回の検証でハマったこと
samplesカタログから直接Sync Tablesを作成できない
最初、samples.tpch.orders に対してそのままSync Tablesを作成しようとしたところ、以下のエラーが出ました。
Synced database table cannot be created in catalog samples because the type is not supported.
samples カタログはDatabricksが提供する読み取り専用の特殊なカタログであり、Sync Tablesの同期元として直接指定することができません。
一旦別のカタログにCTASでコピーしてから同期する必要があります。
CREATE TABLE test.default.orders_for_sync
AS SELECT * FROM samples.tpch.orders LIMIT 5000;
スキーマ名 default はダブルクォートが必要
Sync Tablesで作成されたテーブルのスキーマ名が default でした。しかし default はPostgreSQLの予約語であるため、SQLで参照する際にダブルクォートで囲まないとエラーになります。
GRANTコマンド:
-- NG
GRANT USAGE ON SCHEMA default TO "xxxx";
-- OK
GRANT USAGE ON SCHEMA "default" TO "xxxx";
app.py内のSQL:
# NG
text('SELECT ... FROM default.sync_order_tbl LIMIT :limit')
# OK
text('SELECT ... FROM "default".sync_order_tbl LIMIT :limit')
環境変数名が DATABRICKS_LAKEBASE_HOST ではなく PGHOST
AppにLakebaseリソースを追加したときに自動注入される環境変数は PGHOST、PGDATABASE、PGUSER、PGPORT です。ドキュメントによっては DATABRICKS_LAKEBASE_HOST のような名前を想定した記述が見られますが、実際に注入される変数名は異なります。デプロイ後に環境変数が確認できるエンドポイントを用意しておくと原因の特定が早いです。
@app.get("/debug/env")
def debug_env():
return {k: v for k, v in os.environ.items() if "LAKE" in k or "PG" in k or "DATABRICKS" in k}
curlで叩く際はOAuthトークンが必要
Personal Access Token(PAT)をAuthorizationヘッダーに渡してもリダイレクトが返ってきます。Databricks AppsへのアクセスにはOAuthトークンが必要です。
# NG(PATを使うとリダイレクトが返ってくる)
curl https://db-app-xxxx.aws.databricksapps.com/orders \
-H "Authorization: Bearer dapi..."
# OK(OAuthトークンを使う)
curl https://db-app-xxxx.aws.databricksapps.com/orders \
-H "Authorization: Bearer <OAuthトークン>"
OAuthトークンはDatabricks SDKで取得できます。
from databricks.sdk.core import Config
config = Config(host="https://<your-workspace>.cloud.databricks.com")
print(config.oauth_token().access_token)
最後に
今回はdatabricksのLakebaseの動作検証をさせていただきました。
databricksに蓄積したデータを同期させてサービス用にDBを簡単に構築できるというのはとても魅力的だと感じます。