はじめに
この記事ではデータをAWS上で分析・可視化するための1つの方法を紹介いたします。
実際に手順の通りに手を動かしていただき、各サービスの理解を深めていただければ幸いです。
作業で発生する料金は1$かかるかかからないかくらいになりますのでご安心ください。(無料枠を使用した場合)
以下は作業の流れです。
- 可視化する対象のデータを入手する
- 対象のデータをAWSへアップロードする
- 対象のデータのカラム情報を登録する
- 対象のデータを可視化サービスに取り込む
- 対象のデータを可視化する
各AWSサービスの紹介
今回使用するAWSサービスについて簡単に説明いたします。
Amazon S3(Simple Storage Service)について
S3はAWSが提供するオブジェクトストレージサービスになります。
特徴
-
高い可用性
S3は内部で自動的にストレージリソースをスケールアップ・スケールダウンするので我々はストレージのリソースを気にする必要がありません。 -
高い耐久性
S3は99.99999999999%(9 x 11)の耐久性を実現しております。デフォルトで最低3つのAZのデバイスにデータを保存しているためデータの損失に強い。 -
優れたセキュリティ
データの暗号化はもちろん、ACL・バケットポリシーを用いることで許可されたユーザーにのみデータを提供することができる。 -
高いコストパフォーマンス
大きなファイルを保存してもそれほど料金がかからない ex. 500GBのデータを標準ストレージに保存してもストレージの保存料金は1297円/月 ほど(2021年1月24日時点) -
無制限の容量
S3バケットに容量制限はないのでいくらでもデータを保存することができます。 -
様々なAWSサービスとの連携
AWSの中でも1,2番目に古いサービスであり、様々なAWSサービスと連携することが容易です。
料金
すべてではありませんが、料金の大半を占める項目をピックアップいたします。
※東京リージョン 2021年 1月 24日時点
ストレージ料金
標準S3
| 区分 | 料金 |
|---|---|
| 最初の 50 TB/月 | 0.025USD/GB |
| 次の 450 TB/月 | 0.024USD/GB |
| 500 TB/月以上 | 0.023USD/GB |
リクエスト料金
-
PUT、COPY、POST、LIST リクエスト (1,000 リクエストあたり):0.0047USD
-
GET、SELECT、他のすべてのリクエスト (1,000 リクエストあたり):0.00037USD
-
DELETEは無料
データ転送
以下のデータは料金の対象になりません(以下、料金サイトから抜粋)
- インターネットから転送されたデータ
- インスタンスが S3 バケットと同じ AWS リージョンにある(同じ AWS リージョン内の別のアカウントを含む)場合、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスに転送されたデータ
- Amazon CloudFront (CloudFront) に転送されたデータ
つまり、課金されるのはS3からの送信のみでS3へのアップロードの際には料金が発生しません。また、同一リージョン内のAWSサービスとのデータ転送の際にも料金は発生致しません。S3からインターネットへデータを送信する際には気をつけた方が良さそうです。
| 区分 | 料金 |
|---|---|
| 1 GB/月まで | 0.00USD/GB |
| 次の 9.999 TB/月 | 0.114USD/GB |
| 次の 40 TB/月 | 0.089USD/GB |
| 次の 100 TB/月 | 0.086USD/GB |
| 150 TB/月以上 | 0.084USD/GB |
Amazon Athenaについて
AWSが提供するフルマネージドサービスで、S3にあるデータファイルに対してクエリを実行することの出来るクエリサービスになります。クエリはPrestoSQLベースとなっております。
つまり、S3を配置してしまえば、それだけでそのデータの分析を始められることができます。フルマネージドサービスなのでサーバーの管理は不要ですし、データをRDBにインポートさせる手間も必要ありません。
特徴
-
クエリを発行するごとに料金が発生する
アドホックなケースでクエリを発行する場合はDBを用意するよりも安くなるケースが多いです。 -
高速なクエリ
マネージドサービスであるためクエリを実行するクラスターの管理が自動化されており、パフォーマンスが最適化されております。そのため大規模なデータセットに対しても高いパフォーマンスを発揮いたします。 -
サーバーの管理が不要
データを入手してからすぐに分析のフェーズに入れるのでとても楽です。余計なことを考えなくて済むのは大きく感じます。
料金
スキャンされたデータ 1 TB あたり 5USD (2021年1月24日 東京リージョン)
これのみです。クエリを実行した分だけ料金が発生します。
1ドル=107円換算で1GBあたり約0.522円ほどになります。
QuickSightについて
AWSが提供するBI(Business Inteligence)サービスです。
特徴
-
サーバーレス
BIツールとなるとサーバーを自前で用意して運用するケースが多いのですが、QuickSightではサーバーの管理が不要ですぐに始められます。 -
SPICE
SPICEはQuickSightが持つインメモリ計算エンジンです。取り込んだデータのキャッシュとしても捉えることができます。 -
ML Insights
機械学習と自然言語処理を利用してインサイトを提供することができます。 -
従量課金制
QuickSightでは主に利用するユーザー数によって料金が発生するため安価に可視化を始めることができます。
料金
※Enterprise Editionの場合
-
作成者のユーザーあたり 18USD
-
閲覧者のユーザーあたり 最大5USD
-
SPICEの容量追加 1GBあたり $0.38 /月
1.データの入手
今回は日本の人口推移のデータを使用し、データの可視化を行います。
こちらからcsvファイルをダウンロードしてください。
このcsvファイルは文字コードがSJISかつダブルクォーテーションの引用符つきのcsvファイルになります。また、最後の2行のデータの備考コメントとなります。
後の作業に影響があるためデータを整形していきます。
文字コードをutf8へ変更
% nkf -w --overwrite c01.csv
ダブルクォーテーションの削除 最後の行を削除×2 data.csvとして書き出し
cat c01.csv | sed "s/\"//g" | sed -e "$d" | sed -e "$d" > data.csv
2.S3へデータをアップロード
AWSアカウントにログインしていただき、サービス一覧からS3へ遷移してください。
任意のバケット、プレフィックスを作成し先ほどダウンロードして加工したファイルdata.csvをアップロードしてください。
本記事では s3://inu-is-dog/japan-population/data.csv へアップロードしております。
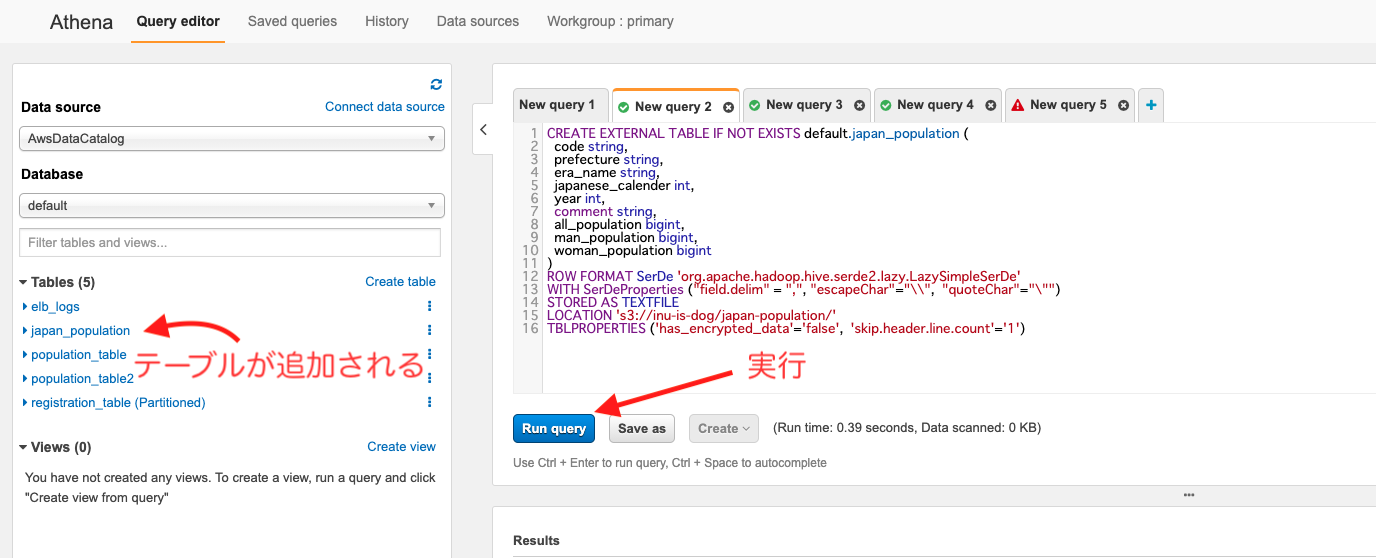
3. Athena でテーブル情報を登録する
サービス一覧からAthenaへ遷移してください。初めてAthenaを開かれる方はAthenaのクエリ結果をどこに保存するのか問われるかと思いますが適宜設定してください。
次にAthenaで以下のクエリを実行してください。S3の配置場所(LOCATIONの部分)は3の手順でファイルを配置したS3パスへ変更してください。
CREATE EXTERNAL TABLE IF NOT EXISTS default.japan_population (
code string,
prefecture string,
era_name string,
japanese_calender int,
year int,
comment string,
all_population bigint,
man_population bigint,
woman_population bigint
)
ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SerDeProperties ("field.delim" = ",", "escapeChar"="\\", "quoteChar"="\"")
STORED AS TEXTFILE
LOCATION 's3://inu-is-dog/japan-population/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1')
このクエリはS3に配置されたcsvのカラム情報をテーブル情報として登録するためのクエリになります。
クエリを実行するとdefaltのデータベースにjapan_populationのテーブルが追加されるはずです。
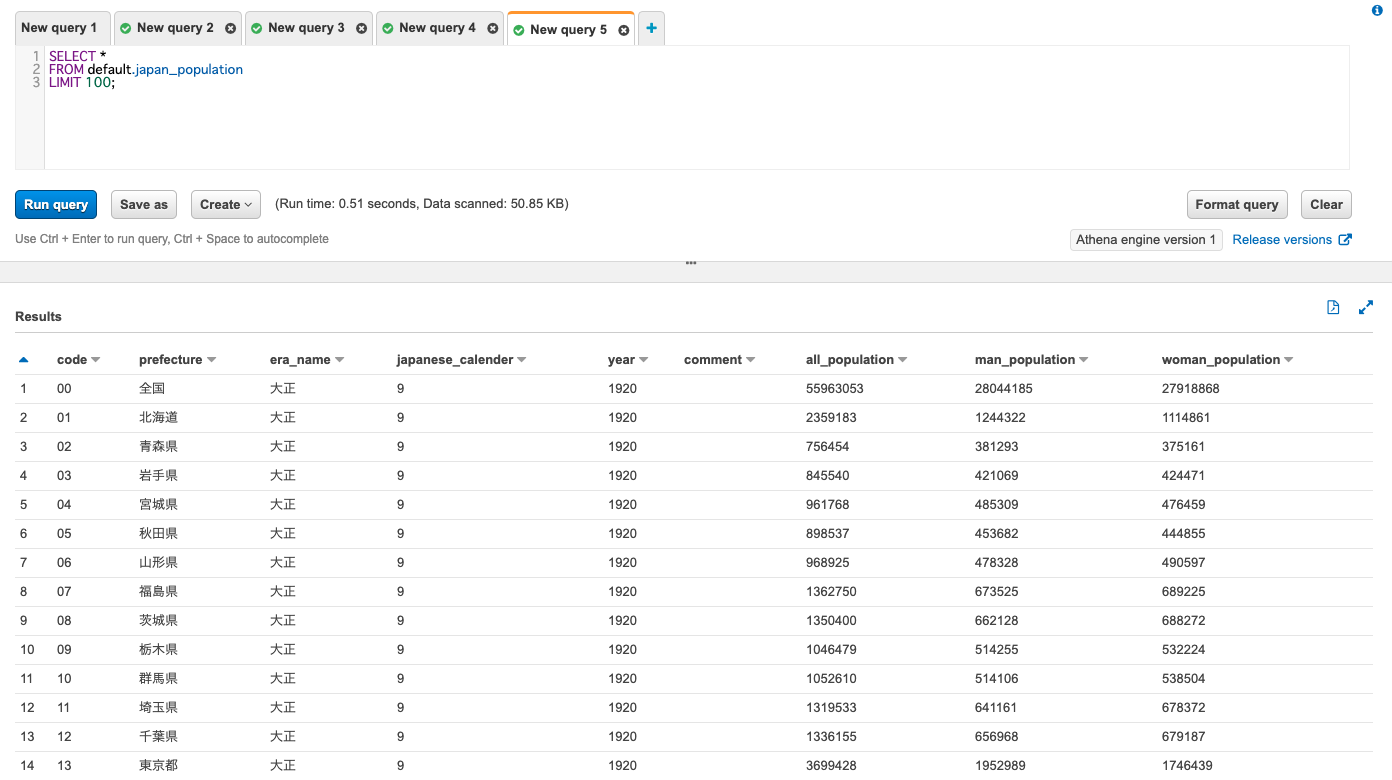
テーブルが追加されたことを確認しましたら、テーブルの中身を正しく読み込めているのかを確認します。
以下のクエリを実行してデータを読み取れれば成功です。
SELECT *
FROM default.japan_population
LIMIT 100;
4. QuickSightでデータセットを作成する
AWSのサービス一覧からQuickSightへ遷移してください。
初めてQuickSightを使用する場合はアカウントの設定が必要かと思います。適宜設定してください。
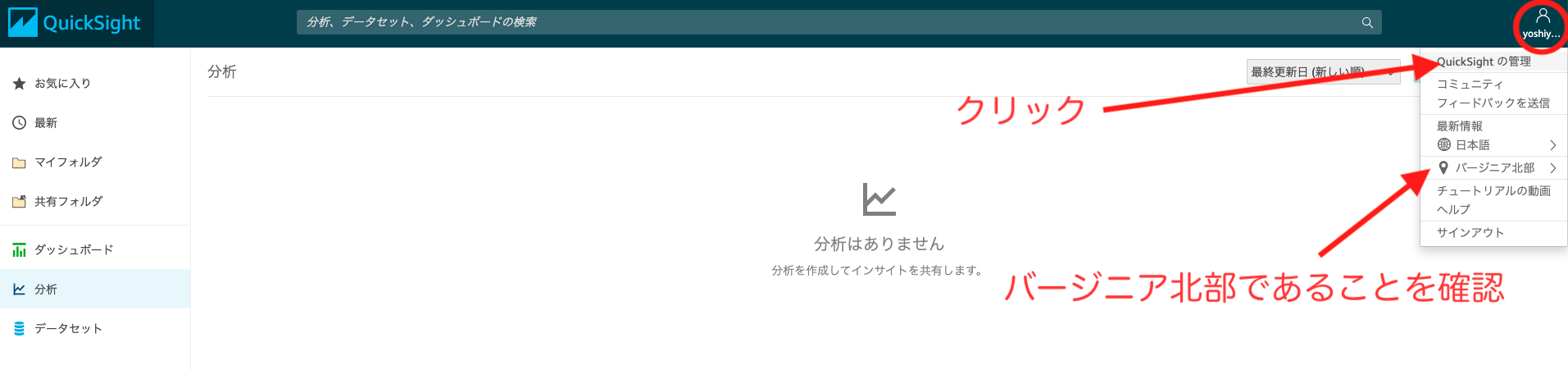
まず、QuickSightがS3、Athenaと連携できるように設定します。
右上の人型のマークをクリック > QuickSightの管理をクリック
※リージョンはバージニア北部へ変更すること
QuickSightのAWSサービスへのアクセスの追加または削除をクリック
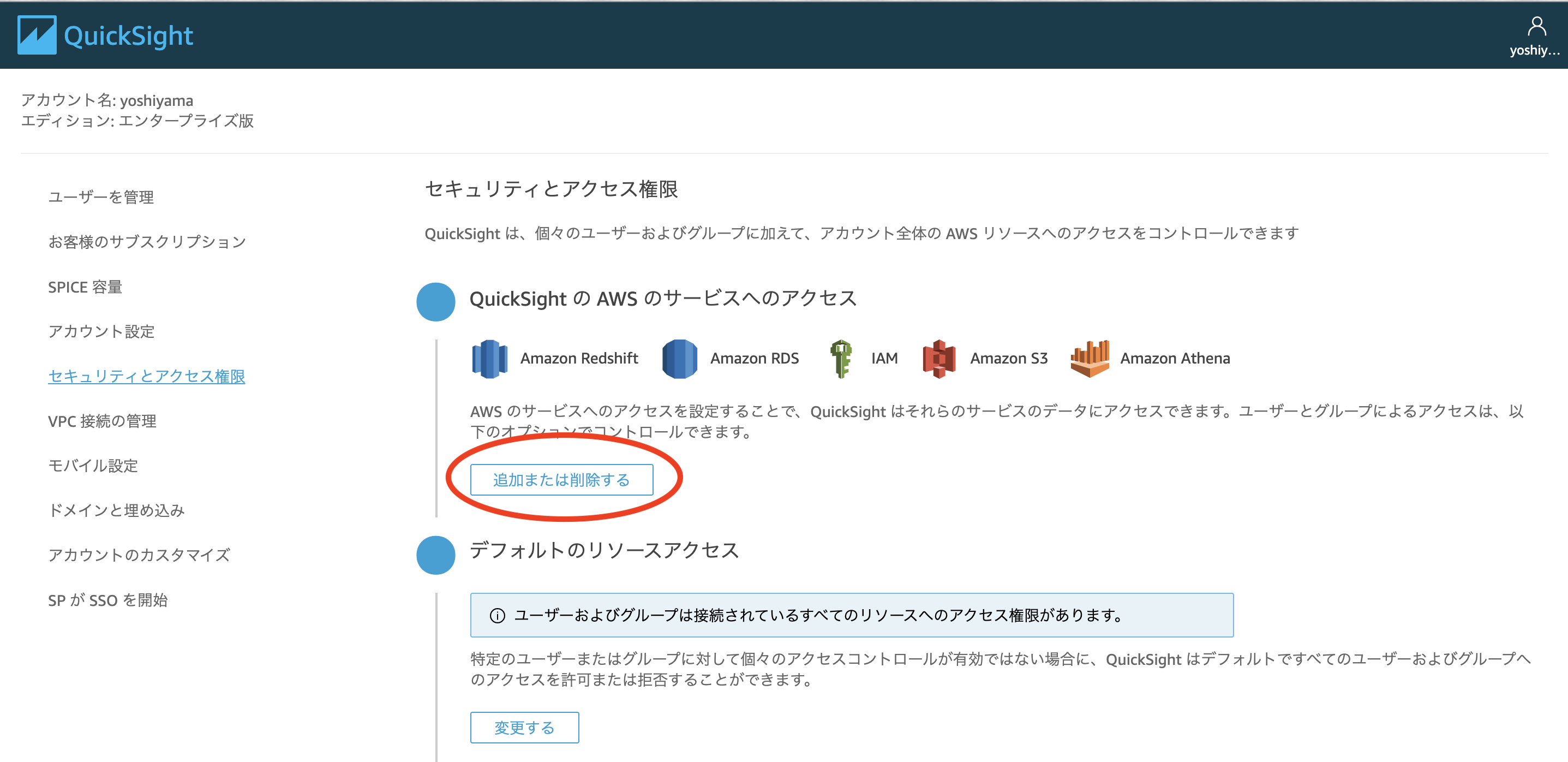
S3とAthenaにチェックが入っていることとファイルを格納しているS3バケットが対象となっているのかを確認する
チェックが入っていなければチェックをいれて更新する
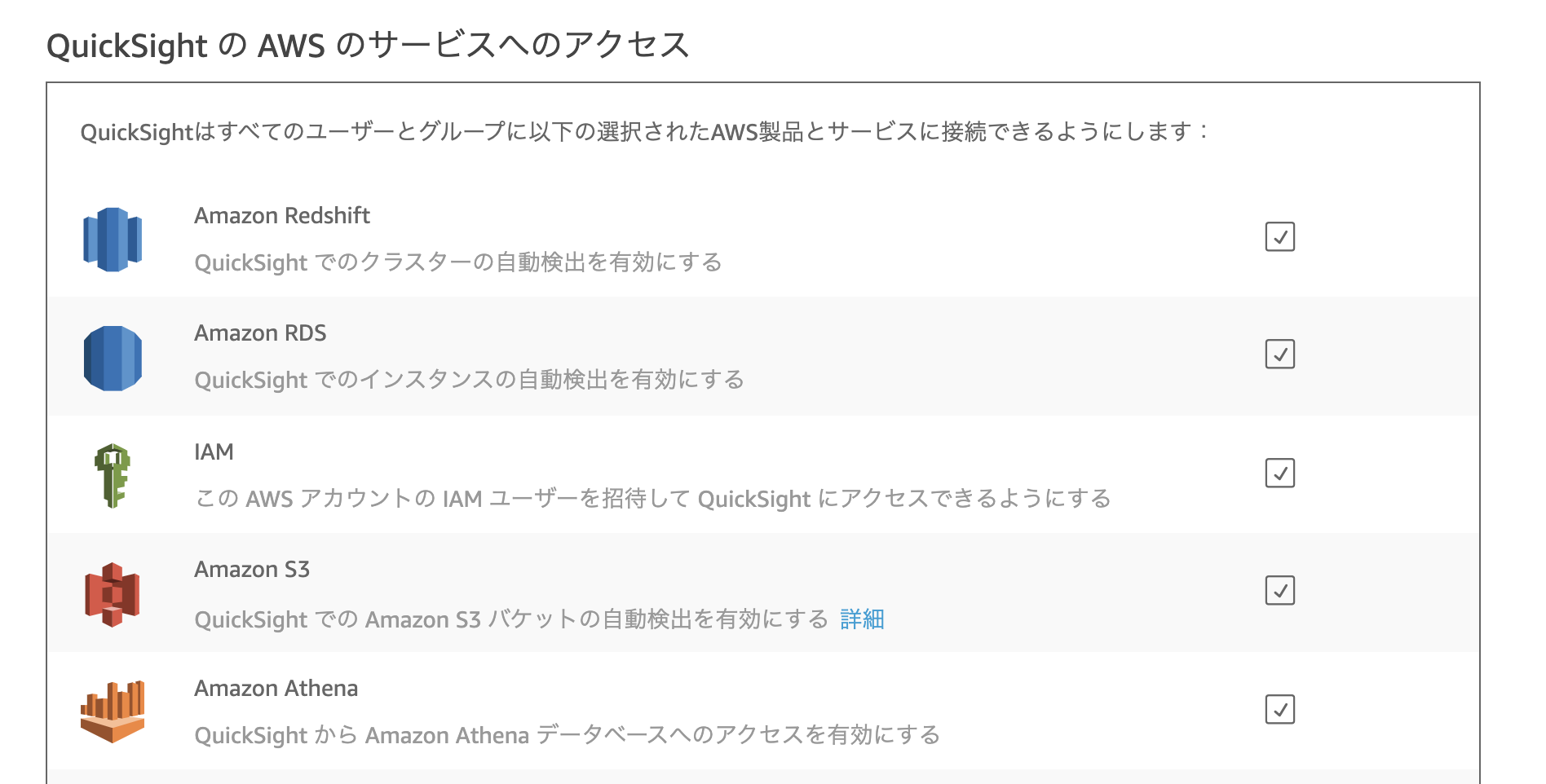
リージョンを東京へ戻し
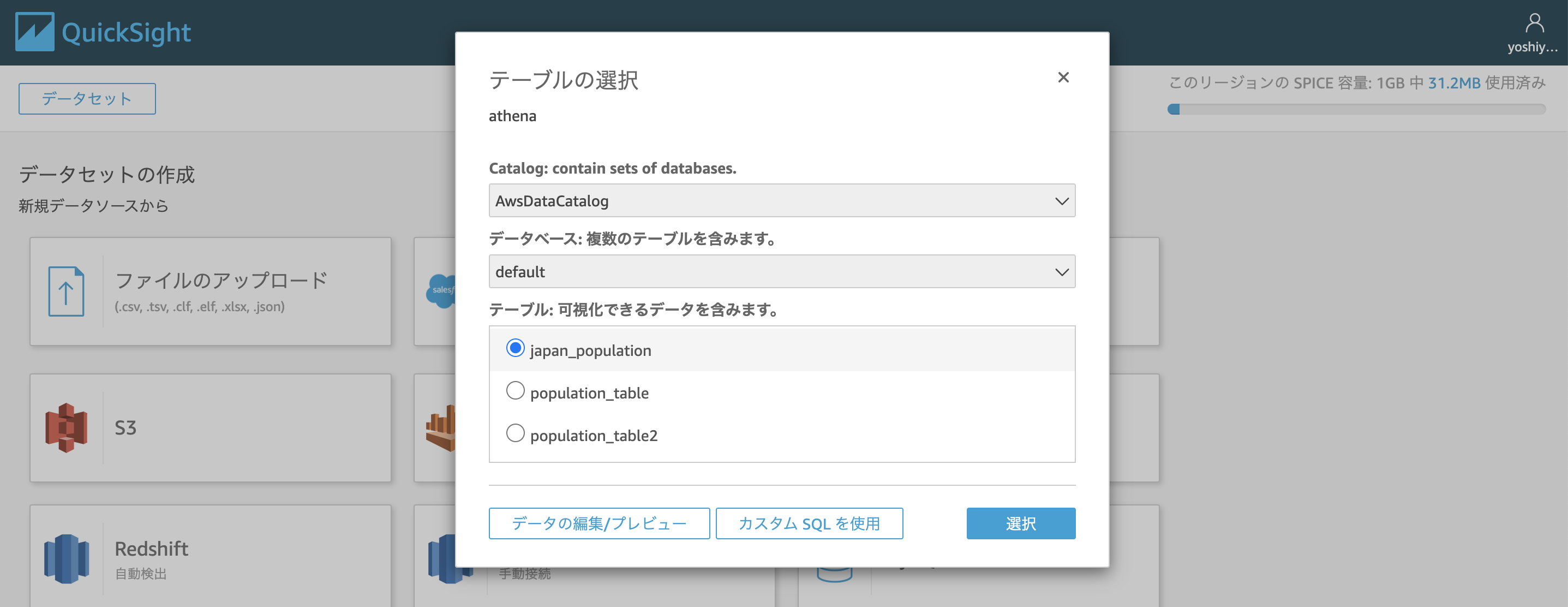
データセット > 新しいデータセット > Athena をクリックする
画像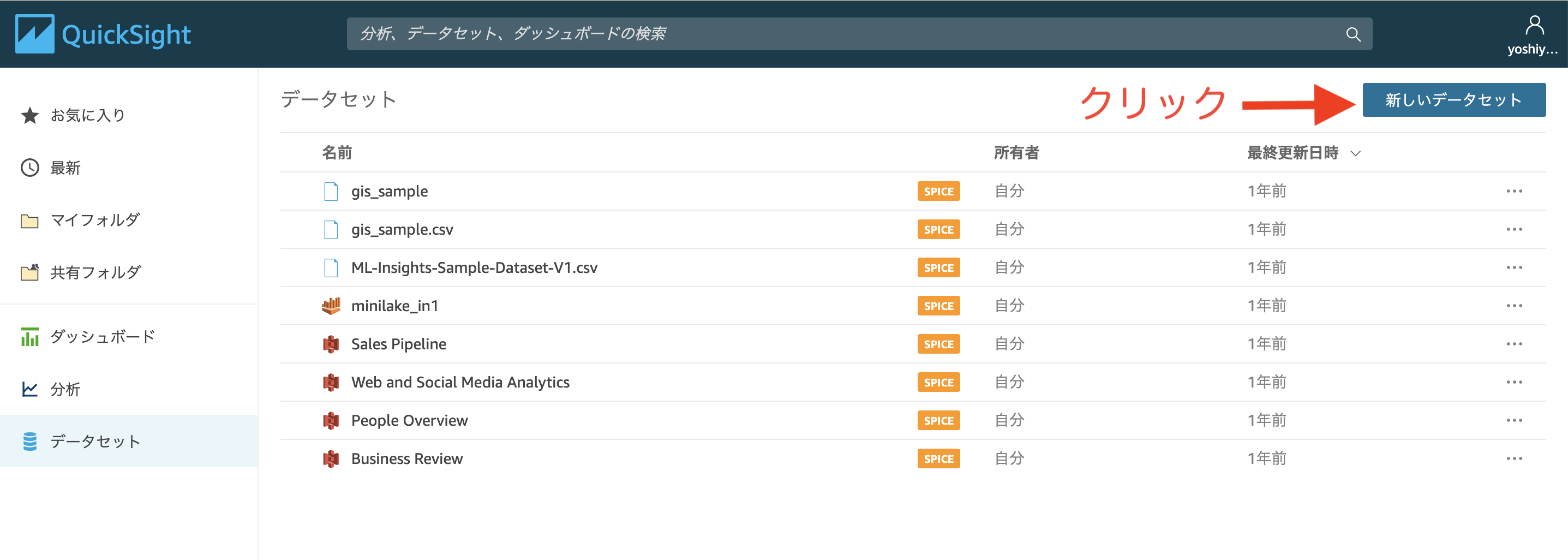
任意のデータソース名をつけデータソースを作成
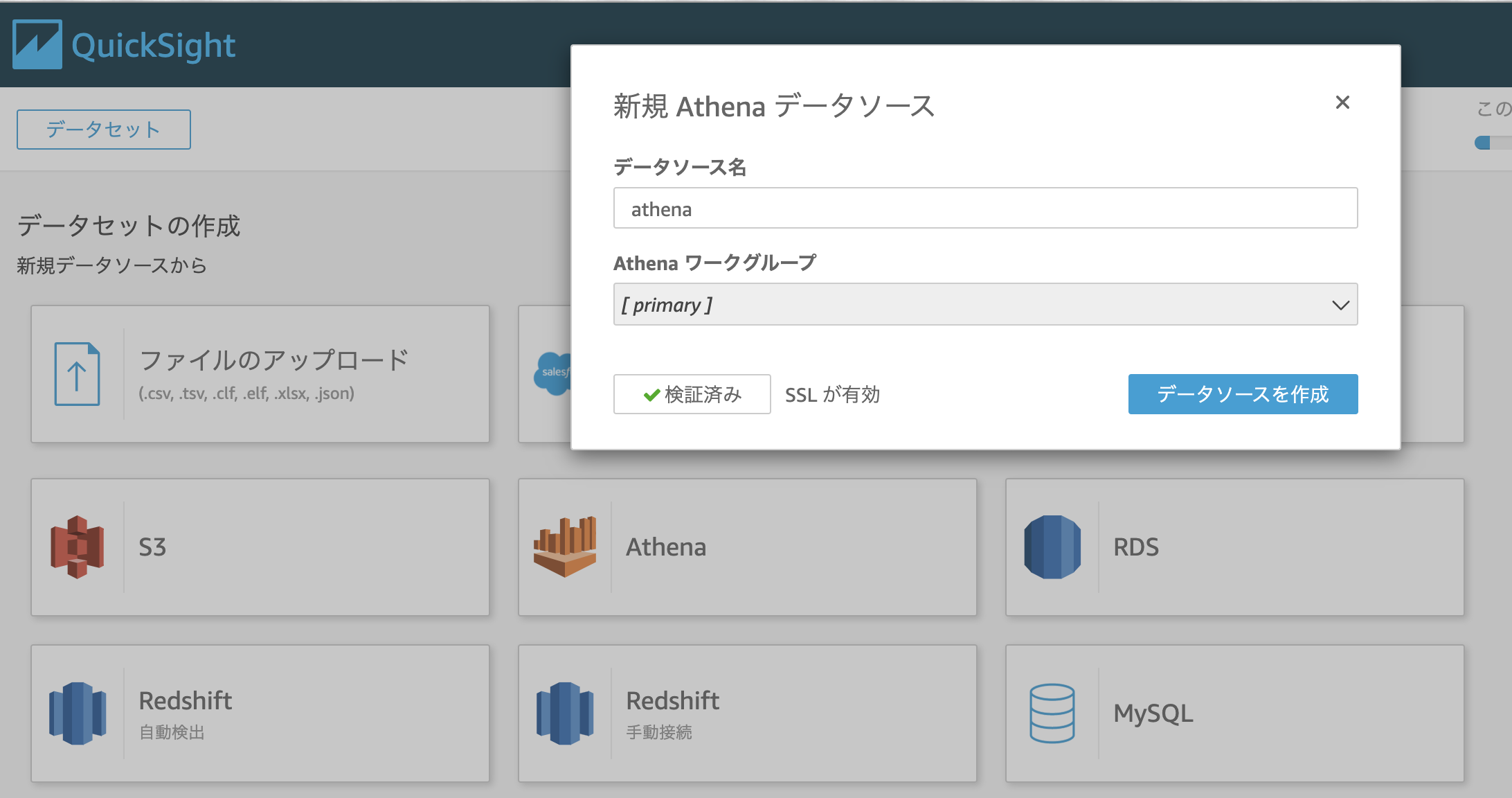
データベース:default
テーブル:japan_population
で選択する
今回はSPICEにデータを保存したいので"迅速な分析のために SPICE へインポート"を選択し、Visualizeを選択するとするとデータのインポートが始まりますので完了まで待ちます。
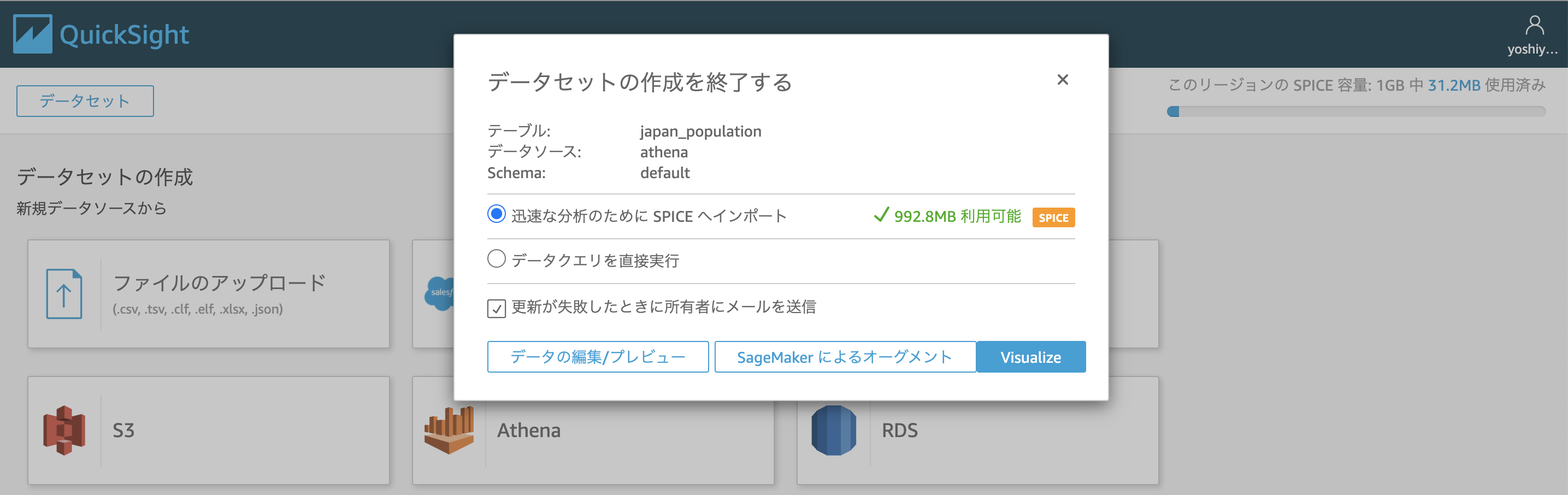
これで可視化の準備は完了です。
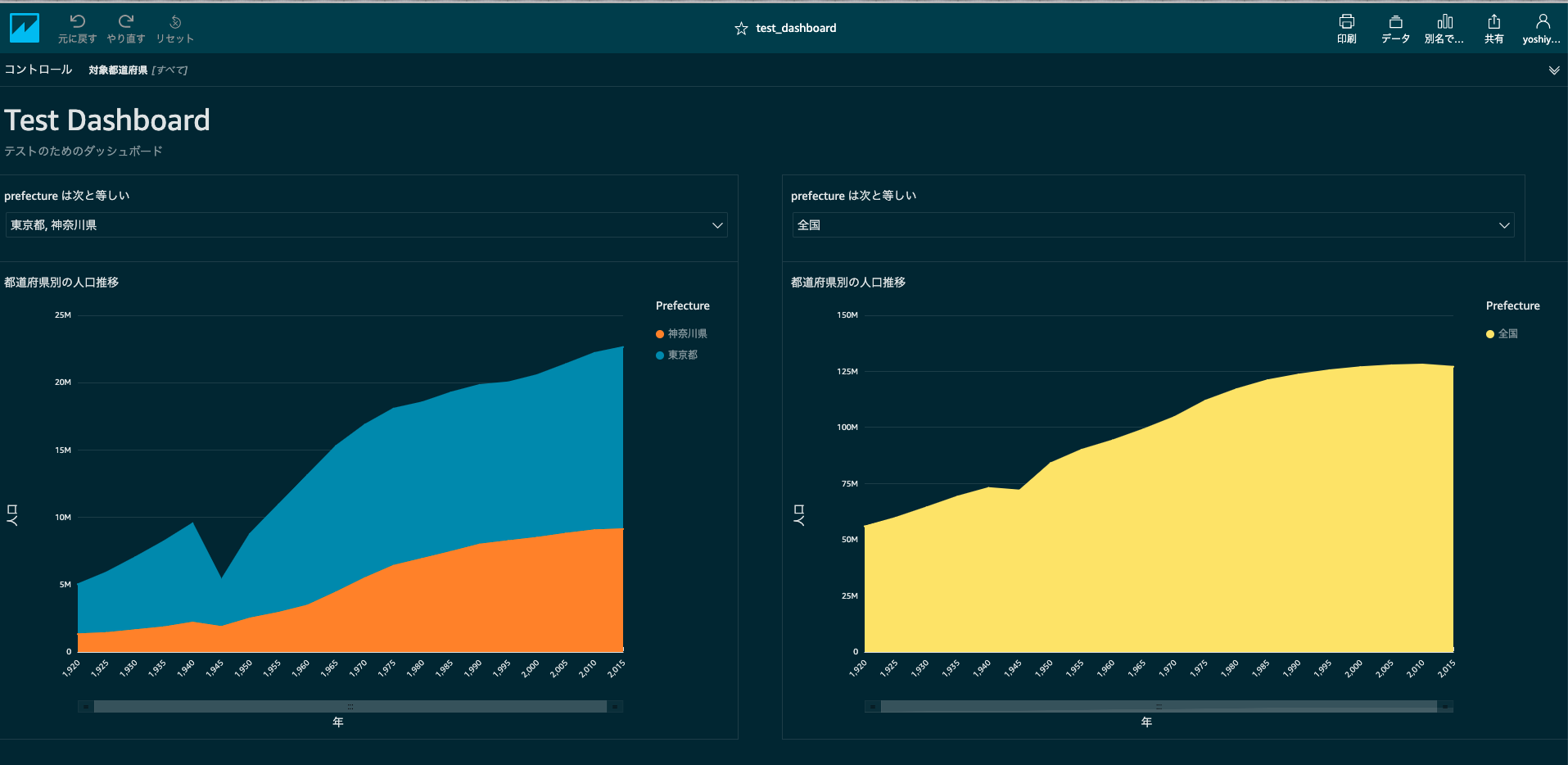
5. QuickSightでデータを可視化する
インポートが完了したら分析の画面に移ります。
最初にグラフが1つ用意されておりますので、フィールドリストから必要なものをドラッグ&ドロップで追加します。
今回は
- ビジュアルタイプ:積み上げ面折れ線グラフ
- Xのフィールド:year
- 値:all_population
- 色:prefecture
として都道府県ごとの人口の推移を観察できるようにしましょう。
このような図となるはずです。
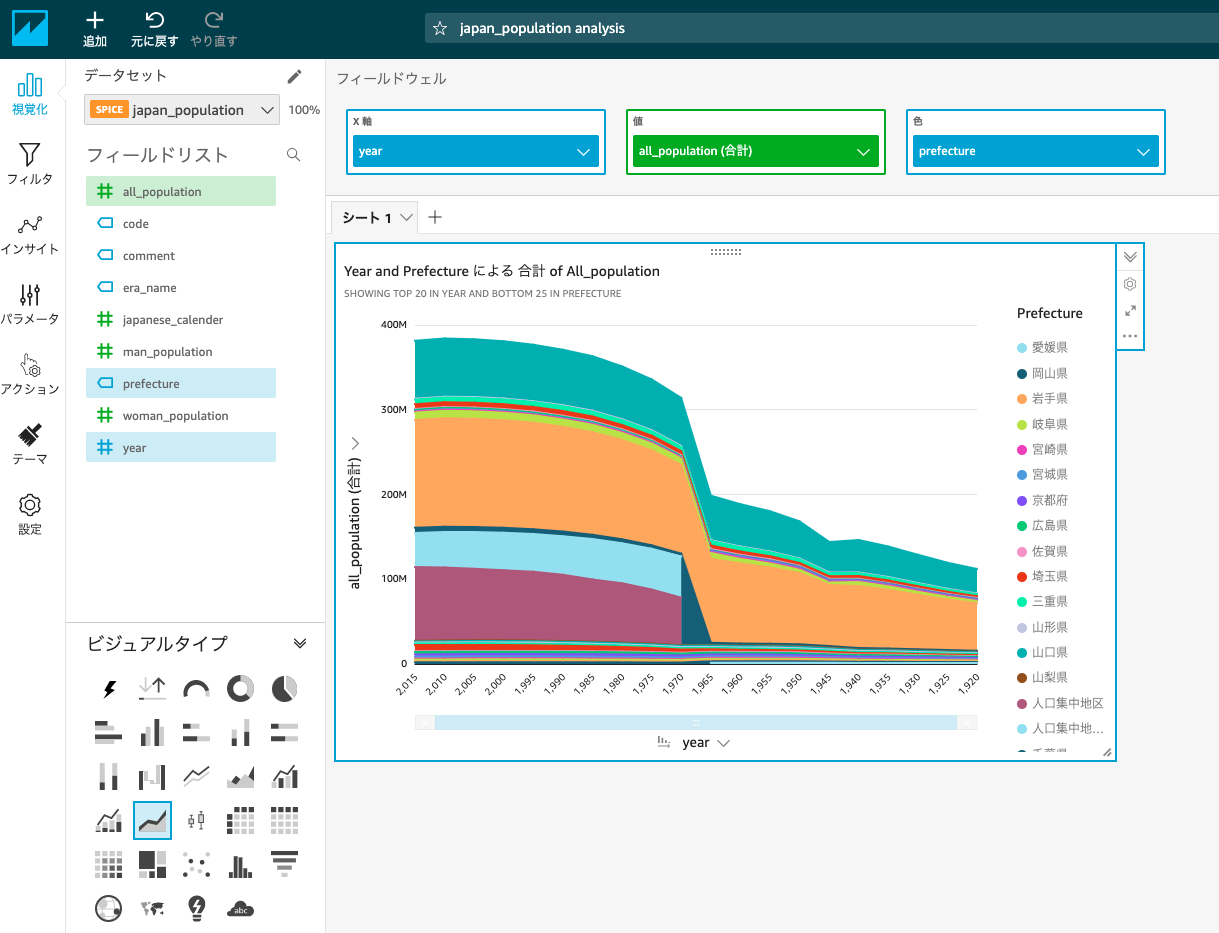
Prefectureの中に都道府県以外に全国、人口集中地区、人口集中地区以外の地区も混ざっていることがわかります。
これらの値は都道府県の値の中でも特別な値なので排除しましょう。
Prefectureの判例の中で右クリックしてこれらの値をグラフから取り除きます。また、判例で表示しきれないものはotherとしてまとめられてしまいますのでこれも非表示にしてみます。
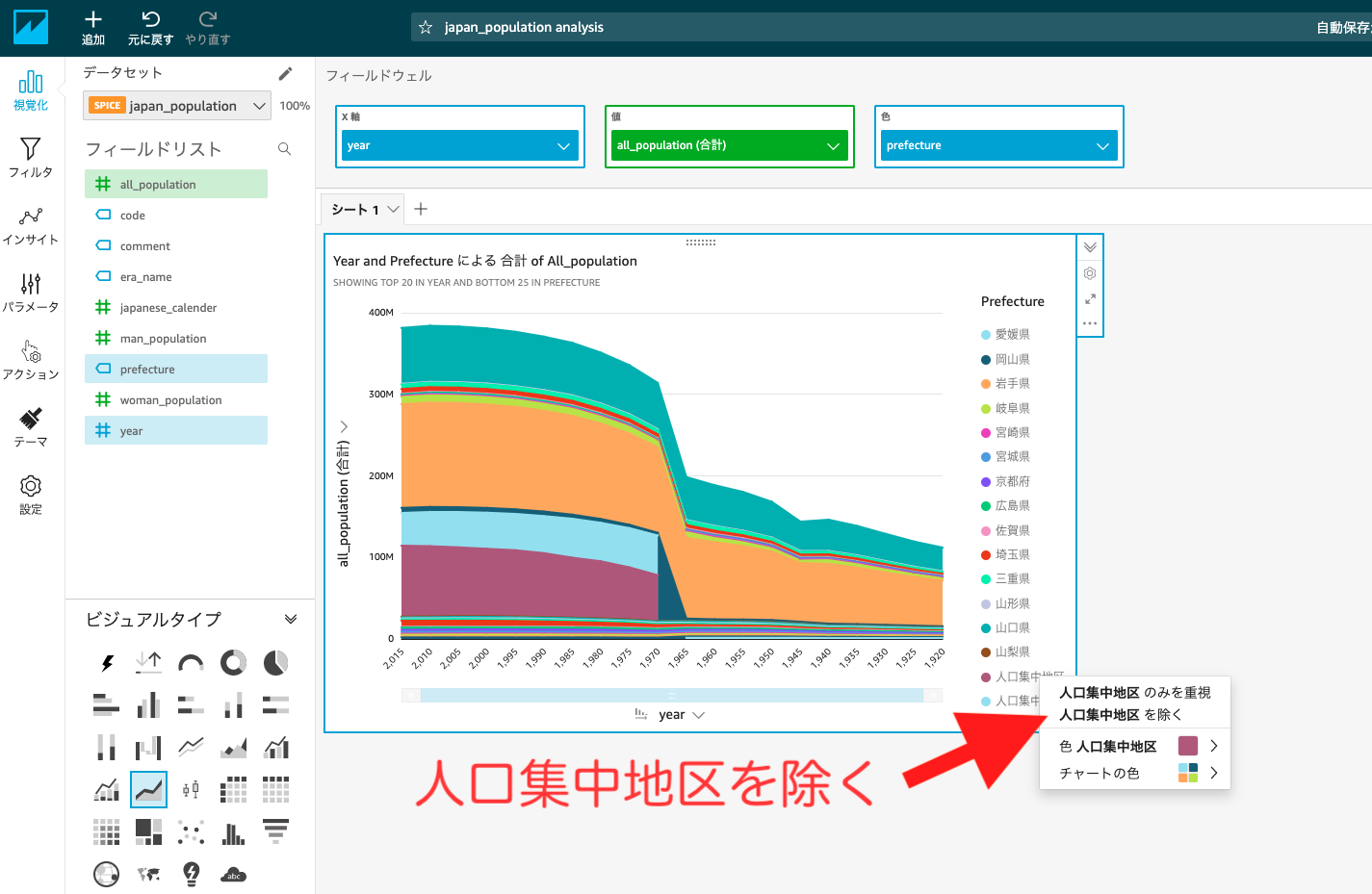
それらしいグラフになってきました。
あとは左上の"追加"から新たなグラフやタイトルを追加したり、テーマから色味を変えてみてダッシュボードらしく整備していきます。
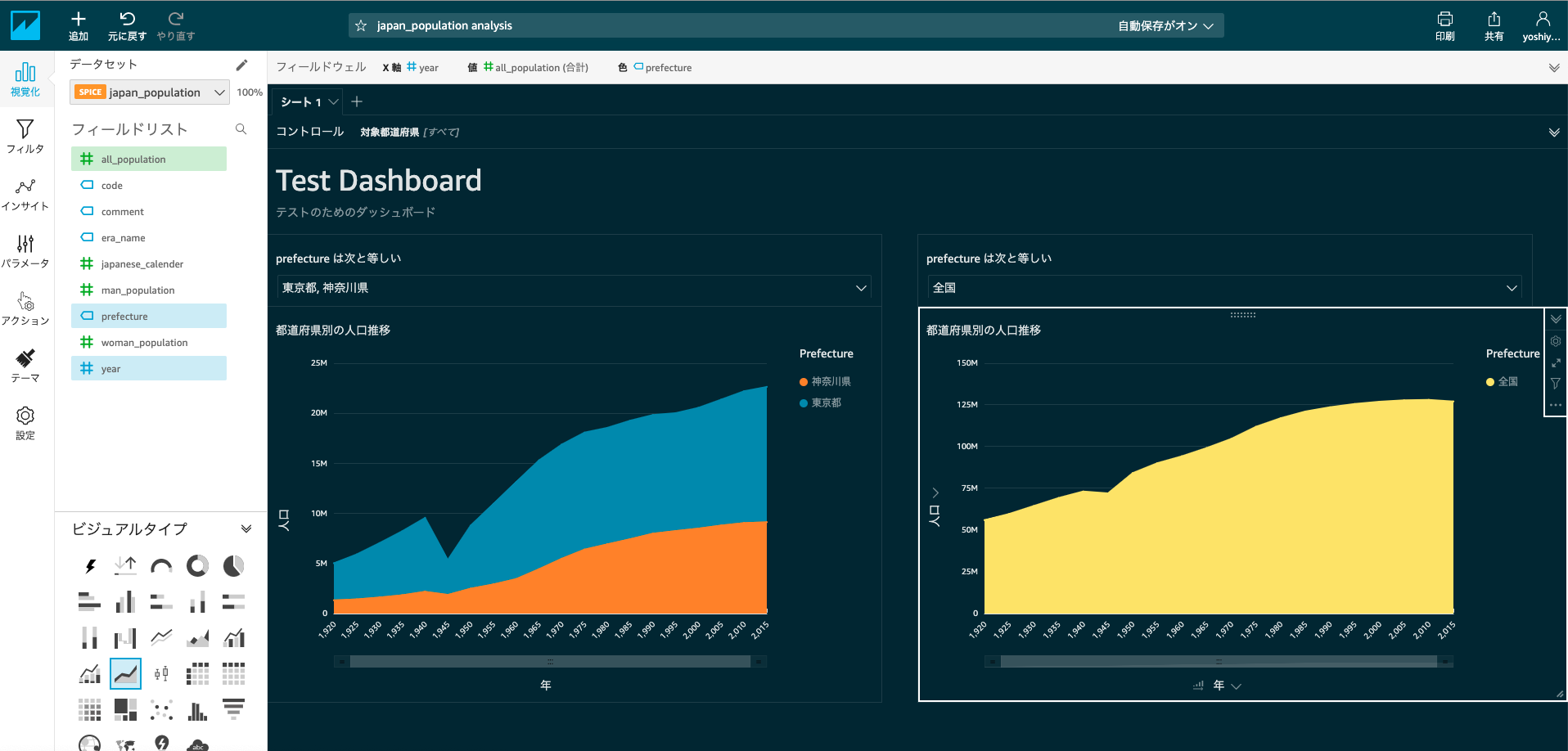
最後にこの可視化した内容を第三者と共有するためにダッシュボードの共有をおこないます。
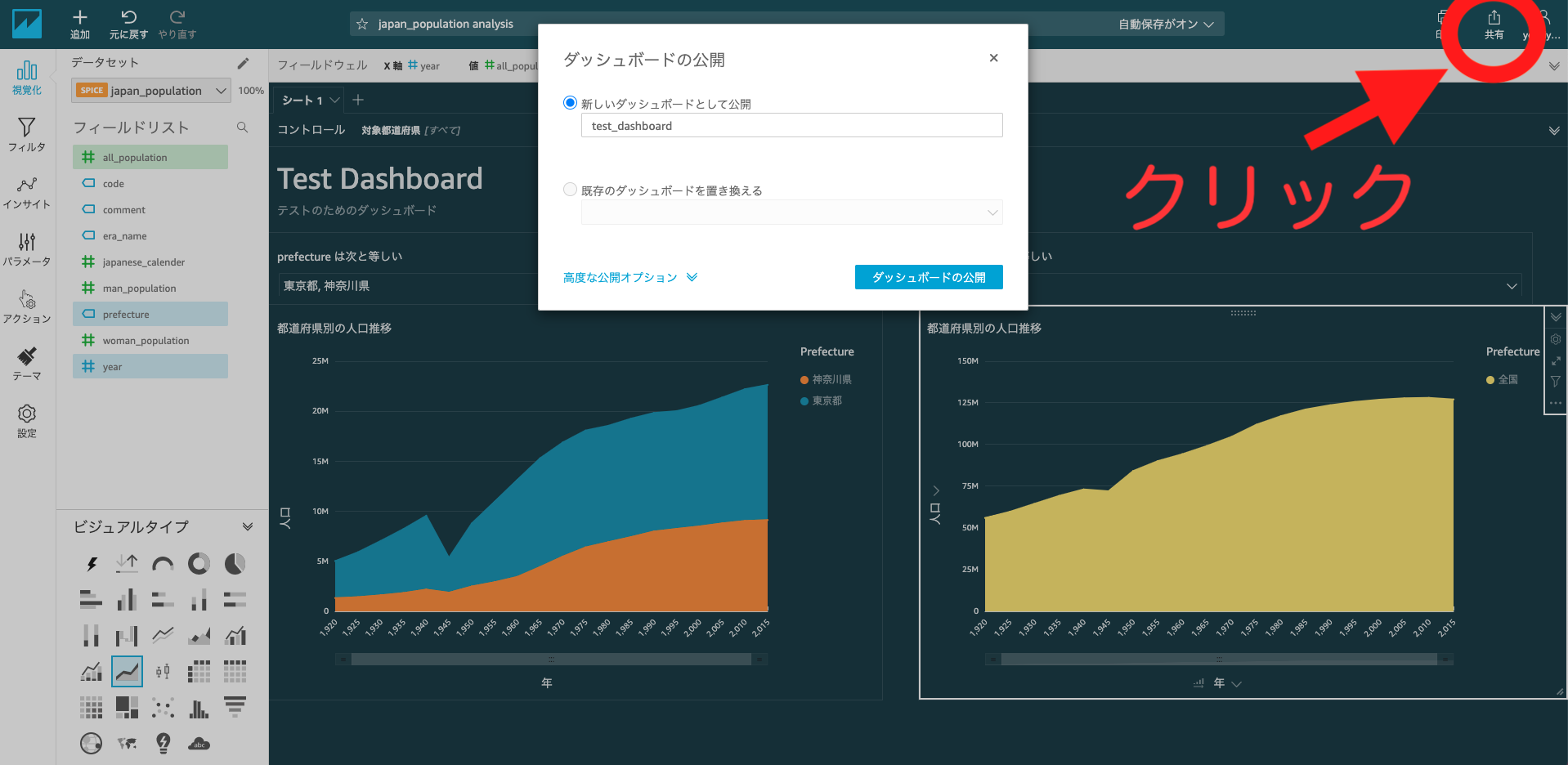
右上の共有から"ダッシュボードの公開"を選択します。
任意のダッシュボード名を入力し公開します。
ダッシュボードを誰に公開するのかはダッシュボードのアクセス管理から行います。
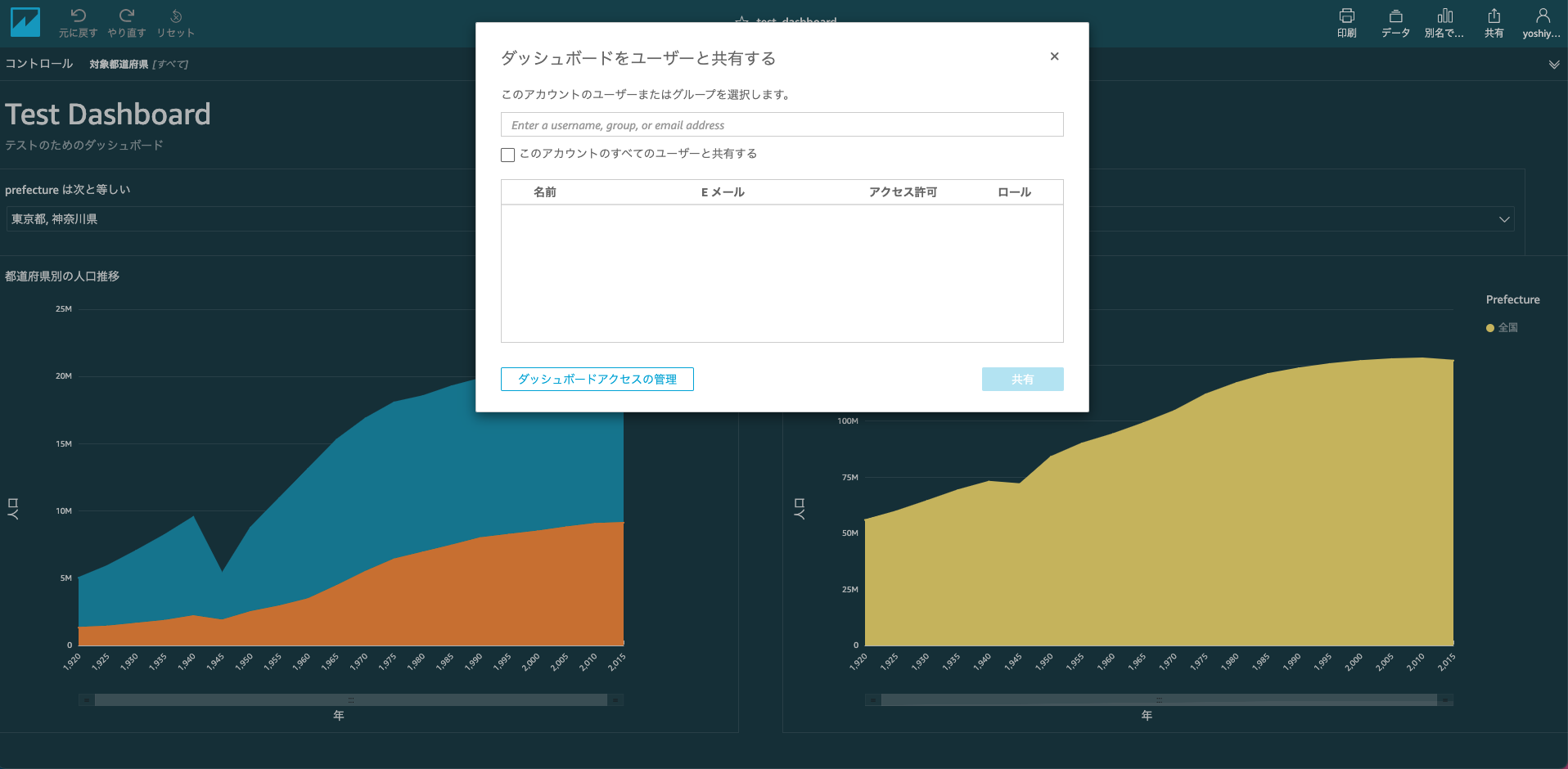
これでデータを可視化した結果のダッシュボードを公開することができました。
最後に
これで一通りの作業は完了となります。
今回は、サーバーレスの環境でデータを分析・可視化を行うことができました。
AthenaもQuickSightもマネージドサービスなので初心者にとっては始めやすいものなんだということが伝われば幸いです。
しかし、マネージドサービスが万能かというとそういうわけではありません。AWSが大半を管理しているからこそカスタマイズしにくかったりする部分があるのでその辺りはケースバイケースなので注意が必要です。