ややこしかったので「OpenAI API」と「MCP Server」について調べた — ローカルLLMとコーディングツールが繋がる仕組みを整理する
はじめに
最近、ローカル LLM やコーディングエージェント周辺の文章を読んでいると、「OpenAI API」と「MCP」が同じ文脈で並んで出てくることが多い。
- 「ollama は OpenAI 互換 API を提供している」
- 「Claude Code は MCP を使ってツールに接続する」
- 「OpenAI も MCP に対応した」
- 「Codex CLI は MCP サーバーを stdio で起動する」
これらの文をいくら並べても、それぞれが何の層の話をしているのかがわからないと、頭が混ざる。実際、自分も最初は「OpenAI API の中に MCP が含まれているのか?」「MCP は OpenAI API の代替なのか?」と取り違えかけた。
結論から言うと、OpenAI API と MCP は別物で、しかも役割が違う層に属している。同じ「LLM 関連の API」と呼ばれていても、片方は「モデルとの会話」を運ぶ仕様で、もう片方は「モデルにツールやコンテキストを渡す」仕様だ。
この記事は、ローカル LLM 環境 (ollama / llama.cpp / LM Studio / Unsloth) を立てて、そこに Claude Code・OpenCode・Codex CLI・Cline などのコーディングツールを繋ぎ込もうとしている人が、どの層にどの仕様が効いているかを一枚絵で持てるように整理したものだ。
本記事は、筆者が所属するクイックイタレート株式会社で、社内のオンプレ LLM 環境とコーディングエージェントを連携させる検証を進める中で、社内向けに整理したメモを Qiita 用に書き直したものです。オンプレ LLM × エージェントツール環境の設計・構築・運用のご相談も承っております。
結論を先に:二つの仕様は別物、別レイヤー
| OpenAI API(Chat Completions / Responses) | MCP(Model Context Protocol) | |
|---|---|---|
| 何の仕様か | LLM への入力(メッセージ列・パラメータ)と出力(生成テキスト・トークン使用量)を JSON で運ぶ HTTP API | LLM の外側にいる「ツール提供サーバー」と「ツール利用クライアント」のあいだで、ツール一覧・呼び出し・結果を運ぶプロトコル |
| 誰が定めたか | OpenAI(ただし業界デファクト化) | Anthropic(2024年11月オープンソース化)、現在は OpenAI / Google も採択 |
| トランスポート | HTTP / HTTPS(SSE での streaming あり) | stdio(ローカル)/ HTTP+SSE / Streamable HTTP(リモート) |
| 誰が「サーバー側」になるか | 推論を担う側(OpenAI、ollama、llama.cpp server、LM Studio、vLLM 等) | ツール・データを抱えている側(GitHub MCP サーバー、Filesystem MCP サーバー、社内ツール用のカスタム MCP サーバー等) |
| 誰が「クライアント側」になるか | 推論を呼びたい側(あらゆるアプリ/エージェント/コーディングツール) | LLM を動かしているホスト側のエージェント(Claude Code、Codex、Cursor、Cline、ChatGPT 等) |
| 解決する問題 | 「LLM にプロンプトを送って応答を貰う」を、ベンダー横断で同じ JSON で書けるようにする | 「LLM が外部の道具や知識に手を伸ばす」を、ツール側とクライアント側で N×M の個別実装をしないで済むようにする |
両者は競合関係ではなく、直交する。エージェントを 1 つ動かすと、両方が同時に走っているのが普通だ。
OpenAI API とは何か(Chat Completions / Responses)
OpenAI が https://api.openai.com/v1/chat/completions で提供している、いわゆる Chat Completions API の仕様。リクエストの形は概ねこうなる。
POST /v1/chat/completions
Content-Type: application/json
Authorization: Bearer <API_KEY>
{
"model": "gpt-5",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Tokyo の今日の天気は?" }
],
"temperature": 0.2,
"stream": false
}
レスポンスとして choices[0].message.content に生成テキストが入って返ってくる。stream: true を指定すると Server-Sent Events でトークンが順次流れる。tools を指定すれば関数呼び出し(function calling)が出る。
仕様の正典:
ここで重要なのは、この JSON 形式そのものが業界デファクトになっていること。OpenAI 以外のベンダーや OSS 推論サーバーが、自前のモデルを動かしながら 「OpenAI 互換の /v1/chat/completions エンドポイント」 を提供することで、既存のクライアント実装を全部そのまま使える、という運用が定着している。
なお OpenAI 自身は 2025 年に Responses API という上位 API を出して、こちらをエージェント向けの主力に位置づけている。Chat Completions も継続するが、新機能(hosted tools、computer use、MCP の hosted tool 化など)は Responses 側に厚い。ローカル LLM ツール群が互換実装しているのは、現時点では主に Chat Completions の方。
MCP(Model Context Protocol)とは何か
Anthropic が 2024 年 11 月に公開したオープン仕様。役割は「LLM が外部のツール・データソースに繋がるときの、配線の標準化」。
LLM エージェントを真面目に組むと、以下のような問題に必ず突き当たる。
- GitHub と Slack と社内 DB と、それぞれ繋ぎたい
- 各ツールは API がバラバラ(REST、GraphQL、独自プロトコル)
- 各 LLM クライアント(Claude Desktop、Cursor、Cline、ChatGPT、自作エージェント)も、それぞれ違うやり方でツールを呼ぶ
- 結果として N 個のクライアント × M 個のツール = N×M の glue コードが量産される
MCP はこの N×M を N + M に潰す。ツール側は MCP サーバーを 1 個実装すれば、MCP クライアントを話す全部のホストから使える。クライアント側は MCP クライアントを 1 回実装すれば、世界中の MCP サーバーに繋げる。
仕様の正典:
MCP サーバーが提供できるのは大きく 3 種類。
-
Tools:LLM が呼び出して副作用を起こせる関数(
create_issue、read_file、run_queryなど) - Resources:LLM に読ませたいコンテキスト(ファイル内容、DB レコード、ドキュメント断片)
- Prompts:定型のプロンプトテンプレート
トランスポートは 3 系統あって、ここが OpenAI API との見た目の違いを生んでいる。
-
stdio:MCP サーバーをローカルプロセスとして起動し、標準入出力で JSON-RPC を流す。
npx -y @modelcontextprotocol/server-filesystem /pathのように、クライアントが子プロセスとして立ち上げて喋る形式。ローカル開発で最もよく使われる。 - HTTP + SSE:旧来のリモート用トランスポート。
- Streamable HTTP:現在推奨されているリモート用トランスポート。
stdio という単語が MCP の文脈でだけ頻出するのは、ローカル MCP サーバーが標準入出力で JSON-RPC を受け渡しするから。OpenAI API には stdio 版は存在しない(HTTP 一択)。ここを取り違えると「ollama は stdio で MCP を提供しているのか?」みたいな問いが生まれてしまうが、答えは No だ。
責務の違いを 1 枚で
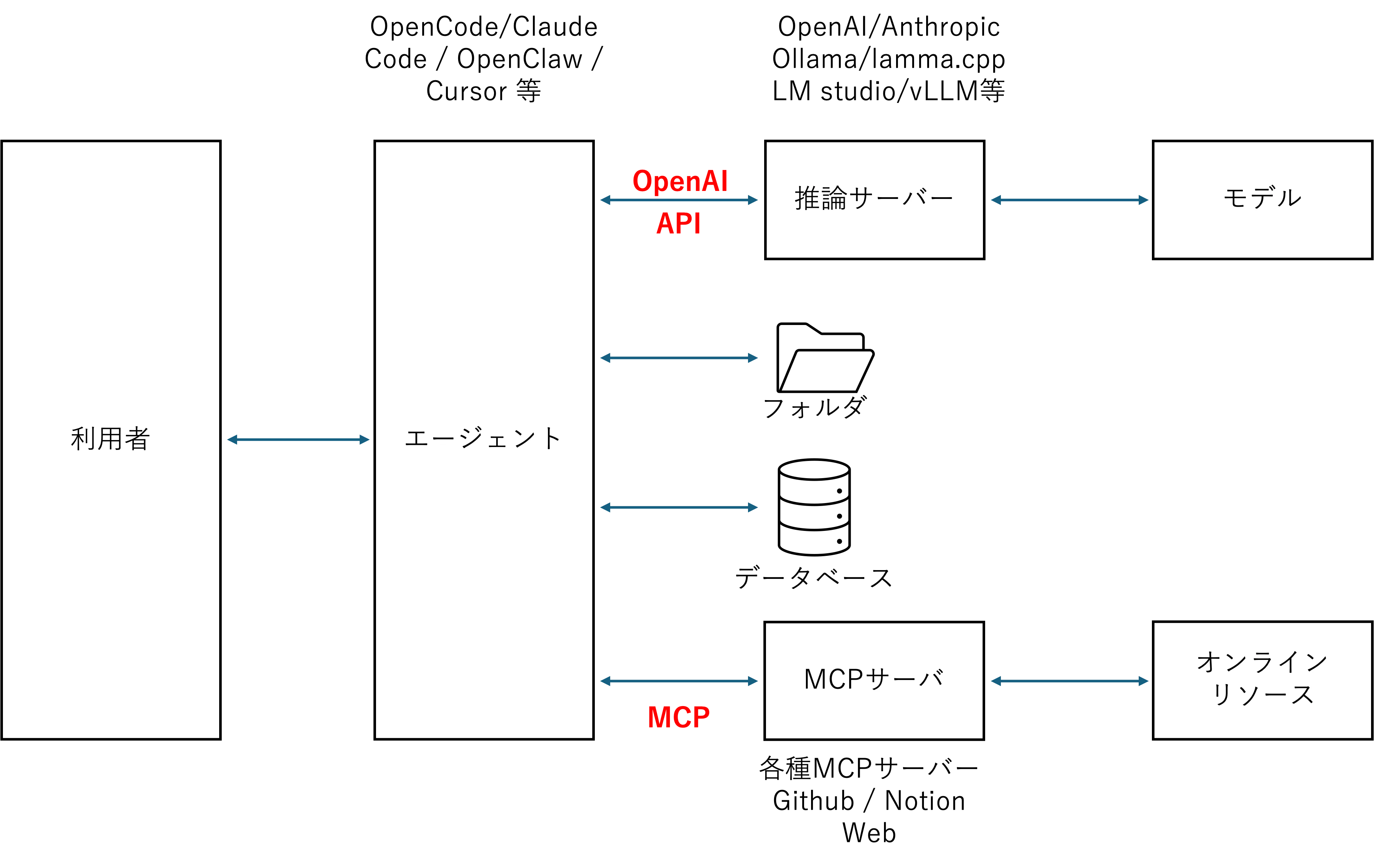
エージェントは中央のオーケストレーターで、上側では OpenAI API で「モデルに考えさせる」、下側では MCP で「世界に手を伸ばす」。両方を同時に喋っていて、両者は別物、というのがこの図の含意だ。
ローカル推論サーバーが提供しているもの
ここが本記事の核心の一つ。ローカル LLM ツールは、ほぼ例外なく「OpenAI 互換 HTTP API」を提供する。MCP は提供しない(しても意味がない、後述)。
| ツール | 提供 API | 起動方法の例 | 既定ポート |
|---|---|---|---|
| ollama | OpenAI 互換(/v1/chat/completions、/v1/embeddings)+ ネイティブ /api/chat
|
ollama serve |
11434 |
| llama.cpp(server モード) | OpenAI 互換(/v1/chat/completions、/v1/completions、/v1/embeddings) |
./llama-server -m model.gguf -c 8192 --host 0.0.0.0 |
8080 |
| LM Studio | OpenAI 互換(/v1/chat/completions ほか) |
GUI から「Local Server」を起動 | 1234 |
| Unsloth | (単体では推論サーバーを持たない。学習・量子化が主目的) 推論時は llama.cpp / vLLM 経由で OpenAI 互換 API として提供する |
vllm serve <model> 等 |
任意 |
ここで誤解しやすい点を 3 つだけ。
- これらは MCP サーバーではない。 ollama も llama.cpp も「LLM の本体(モデル)」を抱えていて、外から「文章を生成して」と頼まれて応答する側。MCP はそれより外側、エージェントが「ツールが欲しい」と頼む先の話。
-
これらは stdio で喋らない。 全部 HTTP。
curl http://localhost:11434/v1/chat/completions ...で叩ける。MCP の stdio とは別世界。 -
OPENAI_API_BASEを書き換えるだけで差し替え可能。 環境変数OPENAI_API_BASE(またはツールごとの設定キー)にhttp://localhost:11434/v1を入れて、API キーは何でもいい文字列を入れれば、OpenAI SDK ベースのクライアントはそのまま喋る。これが「OpenAI 互換」の運用上の威力。
llama-server を --host 0.0.0.0 で社内 LAN にバインドする場合、外部からの接続が遮断されているか必ず確認すること。OpenAI 互換 API は API キー検証を強制しない(受け取った文字列を素通りさせる実装が多い)ので、開いていればモデルが第三者から叩き放題になる。オンプレ LLM の設計思想(社内データを社外に出さない)が、ここを開けた瞬間に根本から崩れる。
クライアントツールが使っているもの
コーディング系のエージェント(Claude Code、OpenCode、Codex CLI、Cline、Cursor、Aider、Continue ...)は、OpenAI API(または Anthropic API)でモデルと喋りつつ、MCP でツールに繋ぐ、という二刀流が標準になっている。
| ツール | モデルと喋る経路 | ツールに繋ぐ経路 |
|---|---|---|
| Claude Code | Anthropic API(OpenAI 互換 gateway 経由でローカル LLM にも繋がる) | MCP(stdio / HTTP) |
| OpenCode | OpenAI 互換 API(プロバイダ多数、ローカル LLM 可) | MCP |
| Codex CLI / IDE 拡張 | OpenAI Responses API | MCP(stdio / Streamable HTTP) |
| Cline / Roo Code | OpenAI 互換 API(ベンダー多数) | MCP |
| Cursor | 内部で複数モデル + ベンダー API | MCP(stdio / HTTP) |
| Aider | OpenAI 互換 API | (MCP ではなく独自のツール統合が中心) |
この表で大事なのは、「モデルと喋る経路」の列にはほぼ OpenAI 系の名前が並び、「ツールに繋ぐ経路」の列には MCP がほぼ並ぶということ。両方の役割は分業されていて、それぞれの仕様で別々の配線が走る。
「ローカル LLM で Claude Code っぽい体験をしたい」という需要に対しては、
- ローカルに
ollamaかllama.cpp serverを立てる(OpenAI 互換 API を吐く) - クライアント側で
OPENAI_API_BASEをローカルに向ける - ツールが必要ならクライアントの設定に MCP サーバーを足す(filesystem、github、社内ツール ...)
の 3 ステップで構築できる。1 と 2 が OpenAI API の話、3 が MCP の話。混ぜると説明ができなくなる。
「OpenAI も MCP に乗ってきた」最近の動き
ややこしさをさらに深める要因として、2025 年 3 月以降、OpenAI 自身が MCP を全面採用してきている。
- OpenAI が Responses API(エージェント向けの主力 API)を出し、Chat Completions の後継的な位置づけにした
- Responses API は MCP サーバーを built-in tool タイプとしてサポートし、関数スキーマを手で書かずにリモート MCP サーバーを直接指す形になった
- Codex CLI / IDE 拡張は MCP サーバー(stdio / Streamable HTTP)を
~/.codex/config.tomlに書いて使う - ChatGPT 自体も Apps SDK 経由で MCP サーバーを繋げるようになった
ここで重要なのは、この動きが「OpenAI API と MCP が同じものになった」ことを意味しないこと。むしろ逆で、
- OpenAI は Responses API(モデルとの会話の API) の 中で、ツール記述の標準として MCP(ツール接続のプロトコル) を採択した
ということ。API はモデルと話すための器、MCP はその器の中で「外の道具を呼ぶときの配線規格」として使われている。両者の責務分担はむしろ明確になった。
ChatForest の整理がわかりやすい:Responses API と hosted MCP tools はサーバーサイドで動く(OpenAI のインフラがリモート MCP サーバーに接続する)、Agents SDK の stdio はクライアントサイドで動く(自分のコードがローカルで MCP サーバーを起動する)。同じ MCP でも、誰がプロセスを抱えるかでアーキテクチャが分かれている。
ハマりどころ
実装中に取り違えやすい質問を、対応する答えとセットで並べておく。
| 取り違え | 何が起きているか | 正しい言い換え |
|---|---|---|
| 「ollama は MCP に対応していますか?」 | 層を取り違えている。ollama は「モデルを動かすサーバー」で、MCP の対象は「ツール・データを抱えるサーバー」 | 「ollama を MCP クライアントに繋ぎたい」なら、間にエージェント(Claude Code 等)を挟む。「ollama を MCP サーバーにしたい」は意味をなさない |
| 「MCP サーバーを書きたいので OpenAI SDK を入れる」 | 不要。MCP サーバーは LLM を呼ばない(呼んでもいいが、それは MCP サーバーの中の実装の話) |
@modelcontextprotocol/sdk(TS)か mcp(Python)を入れる |
| 「Claude Code をローカル LLM で使いたい」 | これは OpenAI API 互換側の話 |
OPENAI_API_BASE(または相当の設定)をローカル推論サーバーに向ける |
| 「Codex CLI で社内ツールを使わせたい」 | これは MCP 側の話 | 社内ツール用の MCP サーバーを書き、~/.codex/config.toml に登録する |
| 「OpenAI API のバージョンと MCP のバージョンの整合性は?」 | 別仕様なので独立に進化する | OpenAI API の SemVer と MCP の仕様バージョンは独立に追う |
「stdio というのは OpenAI API の話?」 |
違う。stdio は MCP のローカルトランスポート | OpenAI API は HTTP のみ |
まとめ — 二軸で覚える
最後に、混同を避けるための一行整理。
- OpenAI API は「モデルと話す」プロトコル。HTTP で、JSON で、Chat Completions / Responses。
- MCP は「モデルに道具と知識を渡す」プロトコル。stdio か HTTP+SSE か Streamable HTTP で、JSON-RPC。
ollama/llama.cpp/LM Studio/Unsloth (vLLM 経由)が提供するのは前者。MCP ではない。Claude Code/OpenCode/Codex CLI/Cline等のエージェントは、両方を同時に喋る。前者でモデルと会話し、後者で外部ツールに繋ぐ。- OpenAI が MCP に対応した、というのは「モデルと話す API の中で、ツール接続の規格として MCP を採用した」という話で、両者が一つになった話ではない。
二つのプロトコルは、エージェント時代の「縦の配線」と「横の配線」だ。縦(モデルとの会話)は OpenAI API、横(ツールとの会話)は MCP。それぞれの仕様書を別々に開いて読めば、混乱は解ける。
| 担う層 | 仕様 | 主なトランスポート | 何に専念しているか |
|---|---|---|---|
| モデルとの会話 | OpenAI API(Chat Completions / Responses)、Anthropic Messages 等 | HTTP / SSE | 推論(プロンプト→生成)の入出力規格を統一する |
| モデルと外界の会話 | MCP | stdio / HTTP+SSE / Streamable HTTP | ツール・データソースの接続を N+M 化する |
両者を別々に見られるようになると、「ローカル LLM × エージェントツール × 社内システム」の構成図が、急にスッキリ書けるようになる。社内向けの設計書を書くときも、この二軸を最初の図に描いてから始めると、議論の前提が揃う。
参考リンク
- OpenAI Platform — API Reference: Chat Completions
- OpenAI Platform — API Reference: Responses
- Model Context Protocol — Specification
- Model Context Protocol — Introduction
- ollama / ollama OpenAI compatibility docs
- llama.cpp server README
- LM Studio — Local Server docs
- Unsloth
- Claude Code / OpenCode / Codex CLI
本記事は、筆者が所属するクイックイタレート株式会社で社内エージェント環境を構築した際の整理メモをもとにしています。関連する公開事例は 事例一覧 をご覧ください。オンプレ LLM × エージェントツール × 社内システム連携の設計・構築・運用のご相談も承っております。