フロンティアモデル包囲網 — 崩れ始める価値独占
本記事は、筆者が所属するクイックイタレート株式会社で社内エージェント環境を構築した際の整理メモをもとにしています。
関連する公開事例は 事例紹介 をご覧ください。
LLM(Local/フロンティアモデル) × エージェントツール × 社内システム連携の
設計・構築・運用のご相談も承っております。
はじめに
筆者は最近、Hermes Agent と Obsidian に向き合うなかで、久しぶりに「熱中」を感じた。ChatGPT を初めて見て興奮したとき以来の感覚だった。
あれからフロンティアモデルは驚くような精度向上を見せ、あっという間に我々の生活圏にまで入り込んだ。とりわけコードを書くソフトウェア産業にとって影響は大きく、業界の激変を肌で感じている。
その一方で、ふと立ち止まる瞬間も増えた。「今日の天気を教えて」のような、決定論的な手段でも十分に答えられる問いに、膨大な電力を使う最先端AIを呼び出すことの是非。Local LLM でフロンティアモデルより2〜3桁小さいモデルを動かしてみると、小さなモデルで足りるタスクがかなりあること、そしてモデルは切り替え可能だということを、実感として理解する。すると「何でもフロンティアモデルに聞く」ことが本当に最適なのか、という疑問が頭をもたげる。Hermes Agent と向き合う時間が長くなるほど、その疑問は確信に近づいていった。
その違和感を、できるだけ冷静に言葉にしてみたい。
フロンティアモデルは、いまもAIの中心にいる。
GPT、Claude、Gemini、Grok、Qwen、Llama 系の大型モデルは、文章生成、推論、コード、マルチモーダル、エージェント実行のどの領域でも、依然として最先端を押し広げている。
だから、この記事は「フロンティアモデルはもう不要になる」という話ではない。むしろ逆だ。強いモデルはこれからも使われるし、利用総量はむしろ増えていくだろう。
ただ、ひとつだけ静かに変わりつつあることがある。すべての用途で「このフロンティアモデルでなければならない」と指名される場面が、少しずつ減っている。
- 下からは、スモールサイズモデルが軽作業を奪う
- 横からは、十分な品質のモデルが横一列に並ぶ
- 後ろからは、次世代モデルが「最強」の有効期間を短くする
- 土台では、高品質データの制約が重くなる
- そして上からは、エージェントがコンテキストを保持したまま裏側のモデルを切り替え、ユーザーからモデル名を見えなくしていく
この複数方向からの圧力を、本記事では フロンティアモデル包囲網 と呼ぶ。
では、包囲しているのは何で、包囲されているのは何なのか。ひとつずつ見ていく。
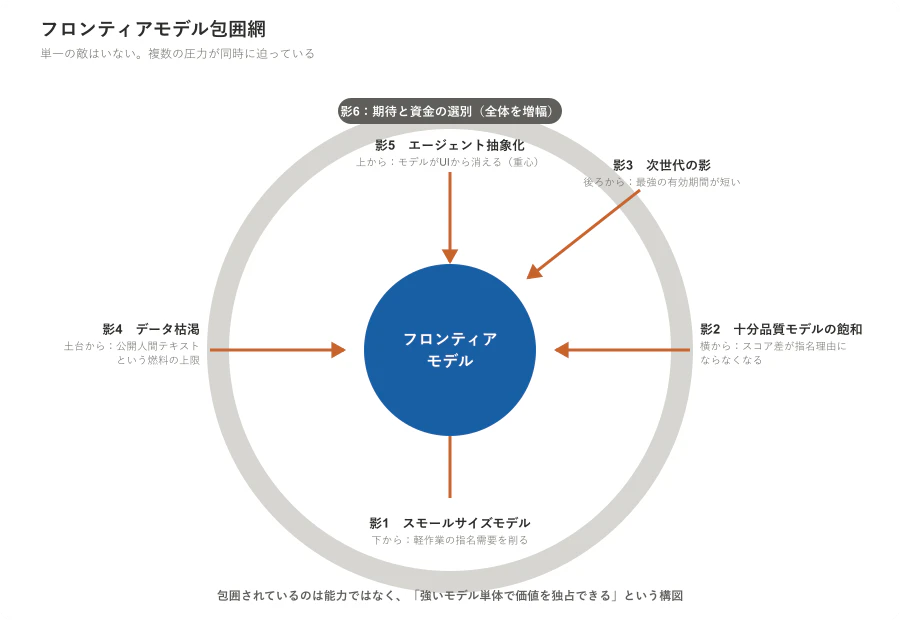
影1:スモールサイズモデル — 下から
最初の影は、下から来る。
軽い作業 — 分類、抽出、短い下書き、定型変換 — のために、わざわざフロンティアモデルを指名する理由が、急速に薄くなっている。
スモールモデルの脅威は、「小さいモデルも意外と使える」という話ではない。同じ水準の能力を出すために必要なモデルサイズと推論コストが、急速に小さくなっている ことにある。
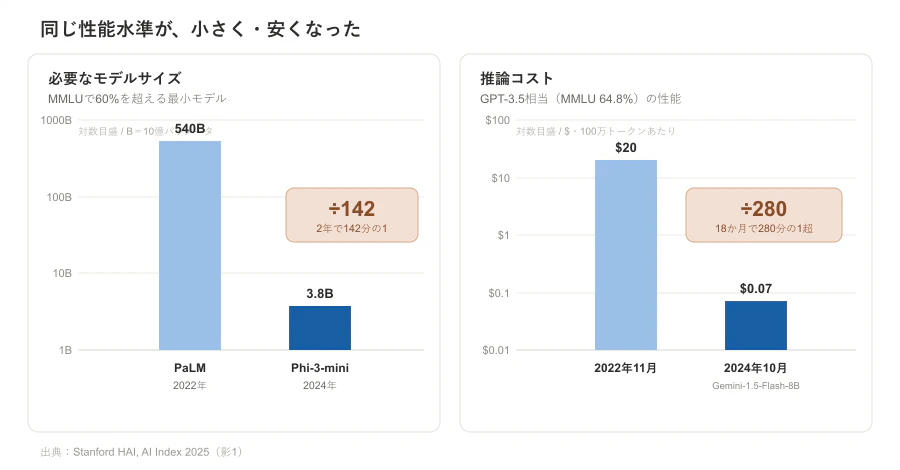
Stanford AI Index 2025 の数字が、それを端的に示す。MMLU で 60% を超える最小のモデルは、2022年には PaLM の 5,400億パラメータ 級だった。それが2024年には、Microsoft の Phi-3-mini、わずか 38億パラメータ 級まで小さくなった。約2年で 142分の1 だ。
推論コストも同じ方向に動いている。GPT-3.5 相当(MMLU 64.8%)の性能を出すモデルのコストは、2022年11月の100万トークンあたり 20ドル から、2024年10月には 0.07ドル(Gemini-1.5-Flash-8B)まで落ちた。約18か月で 280分の1以上 だ。
これは、軽作業をフロンティアモデルに投げる経済合理性が、下から削られているということだ。フロンティアモデルが弱くなったのではない。フロンティアモデルを使う「べき」タスクの範囲が、下から狭まっている。
反証・限界:MMLU 60%、GPT-3.5相当(64.8%)は、最前線の総合性能ではなく、あくまで「十分品質」の下限を示す指標だ。ここから言えるのは「フロンティアモデル不要」ではなく、「軽作業での指名需要が下から削られる」までである。推論コストもAPI提供条件やプロンプト設計で変動する。
影2:十分品質モデルの飽和 — 横から
二つ目の影は、横から来る。同世代のモデルどうしの話だ。
飽和とは、進歩が止まることではない。むしろ、上位モデルがどれも高い水準に到達した結果、「この1社でなければならない」という根拠が弱くなる ことだ。
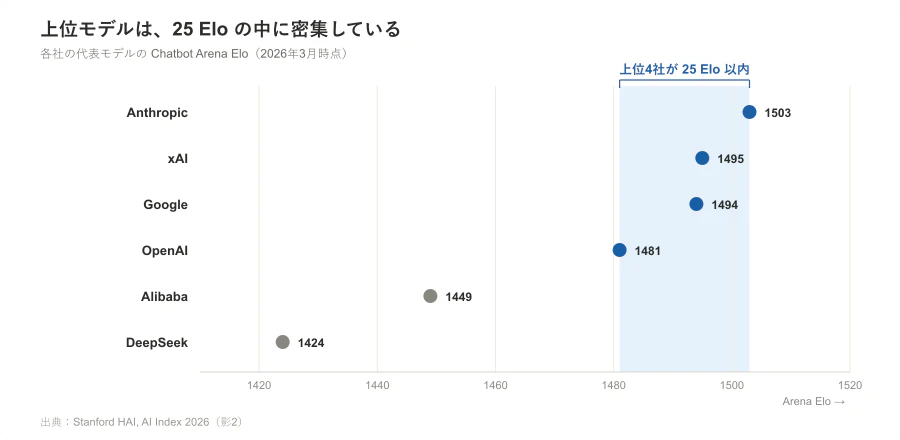
Stanford AI Index 2026 によれば、Chatbot Arena の Elo は、2026年3月時点で Anthropic 1503、xAI 1495、Google 1494、OpenAI 1481 — 上位4社が25点以内に密集 している。少し下に Alibaba 1449、DeepSeek 1424 が続く。
この収斂は、数年かけて進んだ。AI Index 2025 によれば、Arena でのトップモデルと10位の差は11.9%から5.4%へ、トップ2モデル間の差は4.9%から0.7%へ縮んでいる。そして AI Index 2026 は、税務・住宅ローン処理・コーポレートファイナンス・法務推論といった専門業務系の評価でも、上位15モデルの差が各ベンチマークでわずか3ポイント程度まで詰まっていると報告している。「チャットの好み」の話ではない、ということだ。
こうなると、実務で重要になるのは、純粋なスコア差だけではない。価格、速度、安定性、長文、コード、日本語、社内データとの接続性。選定理由は、モデル単体の強さから、利用文脈へ移っていく。
反証・限界:AI Index 2026 自身が、ベンチマークの無効問題率(GSM8Kで最大42%)や、Arena順位が「プラットフォームへの適応」を部分的に反映しうることを指摘している。だからこの章の結論は「どれも同じ」ではなく、「スコア差だけでは指名理由になりにくい」である。
影3:次世代の影 — 後ろから
三つ目の影は、後ろから来る。飽和(横)とは別物の、縦方向の陳腐化 だ。
今日の最強モデルは、長く最強でいられない。これは単に「新モデルが出る」という話ではない。評価指標そのものが短期間で陳腐化し、リーダーボードも高頻度で更新されるようになっている。
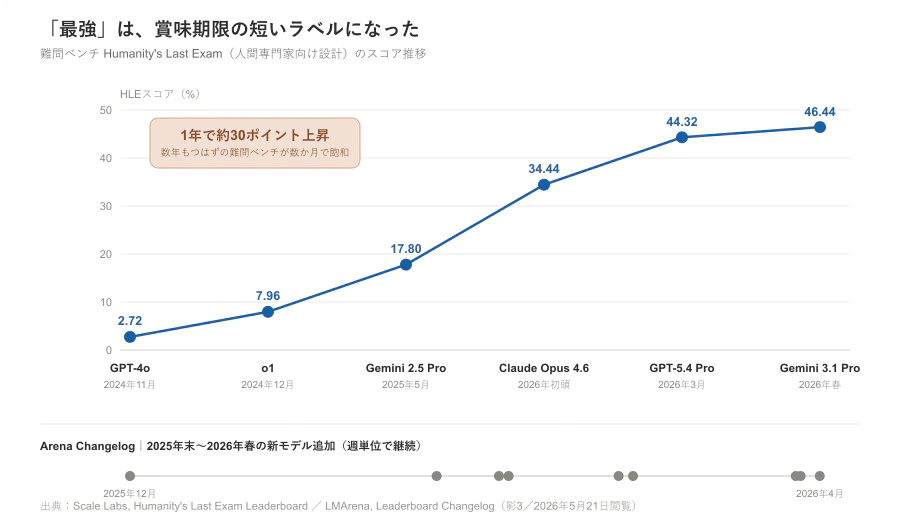
象徴的なのが、人間の専門家に有利になるよう設計された難問ベンチマーク Humanity's Last Exam(HLE)だ。Scale Labs の公式リーダーボードでスコアの推移をたどると、その急伸がよくわかる。
| モデル | Leaderboard上の表記・時点 | HLEスコア |
|---|---|---|
| GPT-4o | November 2024 | 2.72 |
| o1 | December 2024 | 7.96 |
| Gemini 2.5 Pro Preview | May 2025 | 17.80 |
| Claude Opus 4.6 (Thinking Max) | Scale Labs掲載時点 | 34.44 |
| GPT-5.4 Pro | 2026-03-05 | 44.32 |
| Gemini 3.1 Pro Preview (Thinking High) | Scale Labs掲載時点 | 46.44 |
※HLEスコアは Scale Labs Leaderboard の2026年5月21日閲覧時点の値。Leaderboard は更新されるため、記事公開時に再確認すること。
「数年は使える」はずだった難問ベンチマークですら、フロンティアモデルは1年で一桁台から四割台後半へ駆け上がった。AI Index 2026 も、HLE でフロンティアモデルが1年で約30ポイント上昇したと整理している。
新しい有力候補が増えるペースも速い。Arena のリーダーボード更新履歴(Changelog)を見ると、2025年末から2026年春までの追加だけでも —
2025-12-04 Grok 4 Fast Reasoning
2026-02-06 Claude Opus 4.6
2026-02-19 Gemini 3.1 Pro Preview
2026-02-21 GPT-5.2 Chat
2026-03-16 Grok 4.20 Beta Reasoning
2026-03-19 Qwen 3.5 Max Preview
2026-04-22 Kimi K2.6
2026-04-23 DeepSeek V4 Pro
2026-04-27 GPT-5.5 High
主要モデルの追加は、月単位どころか週単位で続いている。
そして、この次世代の登場速度には物理的な天井も見えはじめている。次世代モデルは来る。ただしその速度は、電力・冷却インフラの建設速度に律速されはじめている。
「最強」は、固定された称号ではなく、賞味期限の短いラベル になっている。特定のフロンティアモデルに長期ロックインする合理性は、後ろから崩されていく。
反証・限界:HLE のスコアは thinking モードや評価設定に影響され、ユーザー体験をそのまま表すものではない。また、リーダーボード更新の頻度は、そのまま市場シェアや社内標準の切り替え頻度を意味しない。だからこの章の結論は「最強が毎月交代する」ではなく、「最強の有効期間が短くなっている」である。
影4:データ枯渇 — 土台から
四つ目の影は、土台から来る。
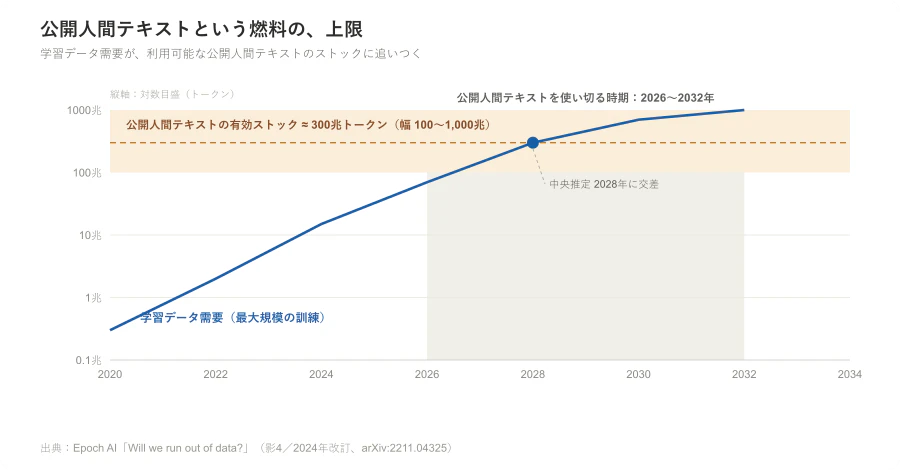
データ枯渇とは、「もうAIは学習できない」という意味ではない。問題は、これまでスケーリングを支えてきた公開人間テキストという燃料に、上限が見えはじめている ことだ。
Epoch AI は、品質と重複を補正した公開人間テキストの有効ストックを 約300兆トークン(90%信頼区間で100兆〜1,000兆)と推定している。そして、現在のLLM開発トレンドが続けば、このストックは 2026年から2032年 のあいだに十分に使い切られる、と見積もる(中央予測は2028年)。学習効率のために多めのデータで学習させる「過剰学習」を強めれば、枯渇はさらに早まる。
したがって、成長の主戦場は、単純なWebテキストの大量投入から、専門データ、合成データ、ツール利用ログ、推論時計算、ワークフロー統合へ移っていく。スケーリングを牽引してきた最大の燃料が細るという事実は、土台からの圧力として効いてくる。
反証・限界:Epoch AI の推計は、高品質・公開・人間生成テキストに限定されている。私有データ、マルチモーダルデータ、合成データ、ポストトレーニング、運用ログは、この数字の外側にある。だからこの章は「枯渇」ではなく「伸びの燃料が変わる」と読むのが、強くて安全だ。
影5:エージェント抽象化 — 上から
五つ目の影は、上から来る。そして、この記事でいちばん重要なのはここだ。
これまでの四つの影は、すべて「モデル同士の競争」だった。下から、横から、後ろから、土台から — どれもモデル市場の内側の話だ。だが、この五つ目だけは違う。エージェント抽象化が重要なのは、モデル同士の競争ではなく、モデルがUIから消える話だからだ。
証拠は2段で見たい。
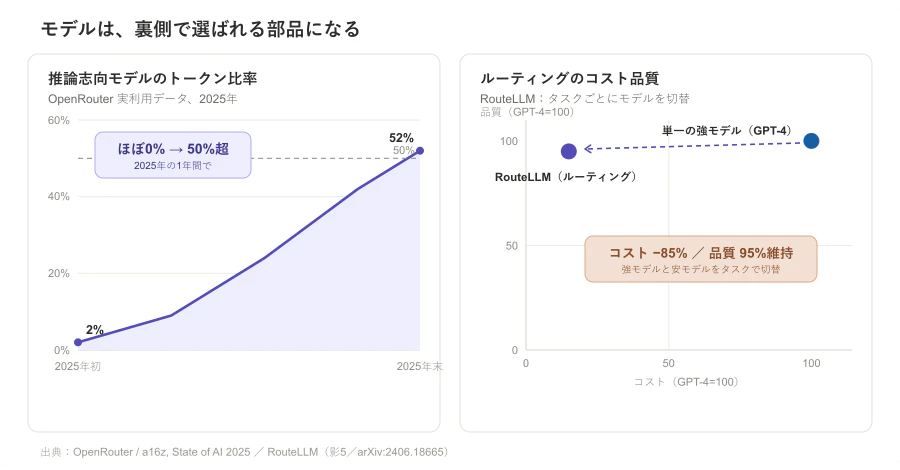
第一段。OpenRouter と a16z の State of AI 2025 は、100兆トークン規模の実利用メタデータ(300超のアクティブモデル、60超のプロバイダ)を分析し、推論志向(reasoning-optimized)モデルに流れるトークン比率が、2025年初頭のほぼゼロから50%超へ上昇 したとしている。平均シーケンス長も、2023年末の2,000トークン未満から2025年末には5,400トークン超へ伸びた。LLMの利用は、単発のチャットから、長い文脈・ツール呼び出し・状態管理を含む agentic inference へ移っている。
第二段。RouteLLM のようなルーティング手法は、タスクごとに強いモデルと安いモデルを切り替えることで、GPT-4 の95%相当の品質を保ったまま、最大85%のコストを削減 できることを示している。
この二つが合わさると、何が起きるか。実利用の中心が agentic inference へ移り、しかもモデル選択を裏側のルータ論理に吸収する経済合理性がある。ここから、かなり強い推論が立つ — ユーザーは「どのモデルを使うか」ではなく「どのエージェントに任せるか」を考えるようになる。 その裏側で、
- この要約はローカルLLM
- この設計判断はClaude
- このコード修正はCodex
- この下読みはGemma
- この公開文書整形はGPT
と切り替わっていても、ユーザーはそれを意識しない。
ここで起きるのは、モデルの敗北ではない。モデルの部品化 である。ユーザーに見える主役は、GPTでもClaudeでもGeminiでもなく、「自分のエージェント」になる。これが モデルの没個性化 だ。
反証・限界:OpenRouter のデータは observational であり、プラットフォーム上の価格・供給・ユーザー層に影響される。RouteLLM が示すのは「ルーティングの経済合理性」であって、ユーザー意識の変化を直接測ったものではない。だから「ユーザーがモデル名を見なくなる」は、一次資料が直接観測した事実ではなく、そこから導いた——強いが——推論である、と明記しておきたい。
影6:期待と資金の選別 — すべてを増幅する
ここまでの五つの影は、技術と市場の側から見た圧力だった。だが、もうひとつ、上記すべての影を増幅する第六の影 がある。資本市場からの期待だ。
ここで起きているのは、資金の消滅ではない。資金の選別 である。
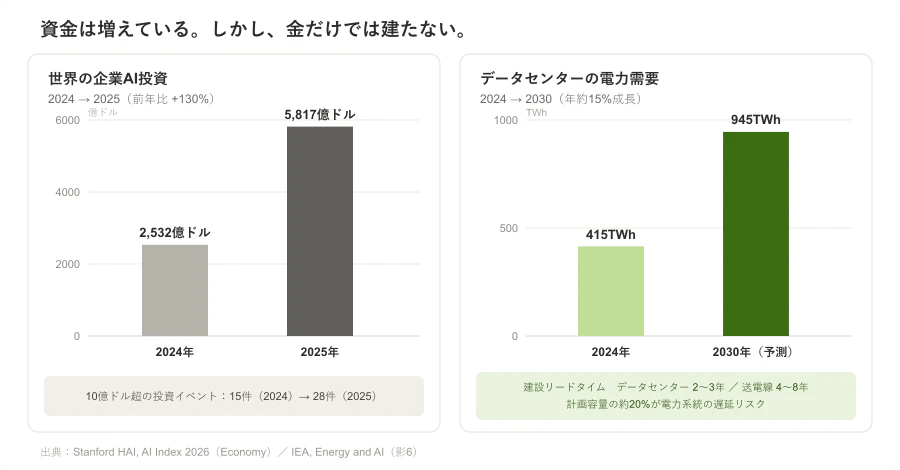
AIインフラへの投資額は、むしろ巨大化している。Stanford AI Index 2026 によれば、世界の企業AI投資は2024年の2,532億ドルから2025年には 5,817億ドル(前年比130%増)へ。生成AI関連の投資だけで1,709億ドル、前年比200%超だ。10億ドルを超える投資イベントは、2024年の15件から2025年には28件へとほぼ倍増した。主要クラウド事業者の設備投資も、AIインフラ需要を背景に記録的な水準へ膨らんでいる。
将来予想も巨大だ。2026年のAIインフラ投資について、主要な金融機関の見立てはこうなっている。
| 試算元 | 2026年の投資額 | 対象・性格 |
|---|---|---|
| Goldman Sachs | 約5,270億ドル | ハイパースケーラ設備投資のアナリスト・コンセンサス(上方修正が続く) |
| Morgan Stanley | 約7,400億ドル | 主要テック企業の設備投資(前年比69%増、直近はさらに上振れ) |
| Reuters / S&P Global | 約6,350億ドル | Microsoft・Amazon・Alphabet・Meta の4社合算試算(Visible Alpha) |
対象企業も費目も観測時点も異なる別々の試算だが、どの見立てでも2026年だけで5,000億〜7,000億ドル超 という桁になる。資金は、細るどころか膨らんでいる。
だが、投資家はすべてのAI投資を同じようには評価しなくなっている。Goldman Sachs は、利益成長が圧迫され借入で設備投資をまかなうインフラ企業からは資金が回避され、一方で「設備投資と売上の結びつき」を示せる企業が報われている、と明言する。問われるのは、「そのcapexはどの売上に変わるのか」「そのクラスタは本当に建つのか」「その電力はどこから来るのか」だ。指名需要が落ち、最強の賞味期限が縮み、モデルがエージェントに吸収されていく — 影1〜5の一つひとつが、この問いを重くする。
さらに、資金だけではデータセンターは建たない。IEA は、世界のデータセンターの電力消費が2024年の約 415TWh から2030年には約 945TWh へ増え、2024〜2030年に年約15%で伸びる(他部門の電力需要の4倍以上の速さ)と見ている。データセンター本体は2〜3年で建てられても、送電線の整備には先進国で4〜8年かかる。その結果、計画中のデータセンターの約20%が、電力系統の制約で遅延リスクにさらされうるという。
つまり、制約は「金があるか」から、「金を電力・用地・冷却・系統接続に変換できるか」 へ移っていく。
これは「AIバブルが崩壊する」という話ではない。AI領域への資金総量は増え続けるだろう。しかし、それがフロンティアモデル単体に無条件で集中する構図は崩れつつある。資金は消えるのではなく、選別され、宛先を変える。
反証・限界:上表の3つの試算は、対象企業も費目も観測時点も異なる別指標であり、ひとつの折れ線に混ぜてはいけない(だから本記事も表で並置するに留めている)。IEA の945TWhや20%遅延リスクも、ベースケースの前提つきの数字で、政策・効率改善・立地分散で変わりうる。だからこの章は「収縮」ではなく「選別」で止めるのが正確だ。
包囲網の本質
六つの影を、ひとつの動詞で言い換えてみる。
- 小さくなる — MMLU 60%超の最小モデルは 540B から 3.8B へ(影1)
- 安くなる — GPT-3.5相当の推論コストは $20 から $0.07 へ(影1)
- 詰まる — Arena 上位4社が 25 Elo 以内に密集(影2)
- 古くなる — 難問ベンチマークが数か月〜1年で飽和(影3)
- 足りなくなる — 公開人間テキストは 2026〜2032 年に制約化(影4)
- 見えなくなる — reasoning / agentic 利用が 50% 超へ(影5)
- 建てにくくなる — データセンター電力需要は 415TWh から 945TWh へ(影6)
フロンティアモデルを倒す「単一の敵」はいない。下から、横から、後ろから、土台から、上から、そして資本の側から — 複数の圧力が同時に迫っている。 だから「包囲網」なのだ。
そして、包囲されているのはフロンティアモデルの 能力そのものではない。包囲されているのは、「強いモデルだけで価値を独占できる」という構図 のほうだ。
正確に言えばこうなる。
- フロンティアモデルの利用総量は、増えるかもしれない
- しかし、すべての用途で特定のフロンティアモデルを指名買いする必要性は下がる
- 指名需要は、ルーティング対象へと変わる
- そしてフロンティアモデルは、本当に難しい高付加価値な用途へと押し上げられていく
「需要が減る」のではない。「指名需要が減る」のだ。
これからの勝ち筋
では、これからのAI競争は何の競争になるのか。
モデル単体の性能競争では終わらない。どのモデルを、どの文脈で、どのエージェントが、どのワークフローに接続するか の競争になる。
これは、ローカルLLM、エージェント運用、Obsidian、Kanban といった「運用設計」に注目してきた人間にとっては、むしろ追い風だ。価値の重心が、モデルという一点から、モデル × エージェント × 文脈 × ワークフロー という構成へと移っていくからだ。
フロンティアモデル包囲網とは、強いモデルが不要になる話ではない。強いモデルはこれからも必要だ。むしろ、重要な場面ではますます必要になるだろう。
ただし、その価値はモデル単体で閉じなくなる。Local LLM、Hermes Agent、Obsidian、Kanban のような文脈保持と運用設計の層が前段に立ったとき、勝ち筋は「最強モデルを持つこと」ではなく、「強いモデルを、適切な文脈とエージェントとワークフローに接続できること」 へ移る。
これからのAI競争は、モデル競争でありながら、同時にエージェント競争、文脈競争、ワークフロー競争になっていく。
フロンティアモデル包囲網とは、強いモデルが不要になる話ではなく、強いモデルだけでは価値を独占できなくなる、という構造変化 のことである。
余談 — 筆者がこの「運用設計」に賭ける理由
個人的な話を最後に少しだけ。
筆者はインターネットのブームが始まろうとする頃、ネットワークスペシャリストでありながら「衛星通信」という傍流に身を投じた。それはそれで面白い人生だったと思う。ただ、自分の能力をインターネットの本流に注いでいたら、また違う景色を見ていたのかもしれない——そう思うことが、たまにある。
エージェントの潮流は、LLM と同等か、それ以上のムーブメントになりうる。皮肉なことに、筆者は Starlink の台頭で従来型衛星通信の事業環境が変わったことにより、長く身を置いた「衛星通信」からむしろ少し距離を取る形になった。だからこそ今度は、インターネットの再来とすら言われるこの大潮流の、ど真ん中の本流を乗りこなしてみたい。
フロンティアモデルそのものを作る側にはなれなくても、強いモデルを文脈とエージェントとワークフローに接続する層なら、まだ本流に間に合う。この記事は、その確信の輪郭を自分なりに描いてみたものだ。
出典・参考
- Stanford HAI, AI Index 2025(2025年4月) — 小型モデルの性能向上(MMLU 60%超の最小モデルが PaLM 540B から Phi-3-mini 3.8B へ、142分の1)、GPT-3.5相当の推論コストが $20/M tokens から $0.07/M tokens へ(280分の1以上)、Arena 上位モデル間の差の縮小(11.9%→5.4%、4.9%→0.7%)
- Stanford HAI, AI Index 2026(2026年4月) — Arena Elo 上位モデルの密集(2026年3月時点)、Humanity's Last Exam で1年30ポイント上昇、専門業務ベンチマーク上位15モデルの差が3ポイント、ベンチマーク無効問題率・Arena適応に関する留保、企業AI投資・生成AI投資・投資イベント件数(Economy)
- Scale Labs, Humanity's Last Exam Leaderboard — フロンティアモデルのHLEスコア推移
- LMArena, Leaderboard Changelog — 主要モデル追加の高頻度化(2025年末〜2026年春)
- Epoch AI, Will we run out of data?(2024年6月改訂、arXiv:2211.04325) — 公開人間テキストの有効ストック約300兆トークン(90% CI 100兆〜1,000兆)、2026〜2032年に十分利用される可能性(中央予測2028年)
- OpenRouter / a16z, State of AI 2025(2025年12月) — 100兆トークン超の実利用分析、reasoning モデルのトークンシェアが50%超へ、平均シーケンス長5,400超へ、agentic inference への移行
- RouteLLM(GitHub: lm-sys/routellm、arXiv:2406.18665) — タスクに応じたLLMルーティング、最大85%のコスト削減と95% GPT-4性能の維持
- IEA, Energy and AI(2025年4月) — データセンター電力消費 415TWh → 945TWh(年約15%成長)、計画中案件の約20%が遅延リスク、データセンター建設2〜3年 vs 送電線整備4〜8年
- Goldman Sachs("Why AI Companies May Invest More than $500 Billion in 2026") — 2026年ハイパースケーラ設備投資コンセンサス約5,270億ドル、投資家による選別(設備投資と売上の結びつき)
- Morgan Stanley("AI Capex 2026") — 主要テック企業の2026年設備投資7,400億ドル、前年比69%増
- Reuters / S&P Global(Visible Alpha 試算) — Microsoft・Amazon・Alphabet・Meta の2026年AIインフラ計画額 約6,350億ドル(4社合算試算)、電力・インフラ容量の制約
※数値はいずれも公表時点のものであり、対象企業セット・費目・観測時点が異なる指標を含む。予測には幅があり、引用時は最新の一次情報を確認のこと。各capex数値(5,270億/7,400億/6,350億ドル)は出所・対象・時点が異なるため、混同しないこと。
本記事は、筆者が所属するクイックイタレート株式会社で社内エージェント環境を構築した際の整理メモをもとにしています。
関連する公開事例は 事例紹介 をご覧ください。
LLM(Local/フロンティアモデル) × エージェントツール × 社内システム連携の
設計・構築・運用のご相談も承っております。