目的
ジョンズ・ホプキンズ大の集計データはGithubに公開されています。本家のダッシュボードよりはショボいですが、自分で好きなように可視化できるものをPower BI(無料版)を使って作ります。
[追記] 完成したpbixファイルのリンク張っときます: https://github.com/yoshiwatanabe/powerbi/blob/master/JHU-COVID19-Analysis.pbix
構成
長くなるので複数のステップに分けることにします。
- Githubからデータを取得してPower BIクエリを作成する
- 作成したクエリをさらに処理してデータモデルを作る
- 集計データのためのメジャーを作る
- データモデルとメジャーを使ってデータの可視化をする
対象
- Power BI初心者および全く扱ったことがない人
- Power BIとかTableauに興味がある人
- 普段はプログラマ・開発者でデータサイエンスにちょっと興味がある人
参考資料
Dannelly Ramos - AnalyzeWithPower
https://www.youtube.com/channel/UCbywJPHKxhqdHp8azdiEwCg
ジョンズ・ホプキンズ大の集計データをPower BIで可視化してる人を探したら一発で出てきました。大変参考になりました。このシリーズで作成するモデルやメジャーはDannellyさんが解説したものをベースにしています。
背景
私はメインでC#を使う開発者です。データサイエンティストではありません。Power BIの経験値は1年に1回使わないぐらいです(Power BIではDAXと呼ばれる式で記述しますが、先週まで全く知らなかったので2日ぐらい集中して勉強したところです)。開発に携わっているサービスはめちゃめちゃPower BI使ってるんですが、今までそっち方面は無視してたんですが、もうちょっと理解したいなと思うのと、ジョンズ・ホプキンズ大のデータをいじってみたいなと思ったのがきっかけです。
おことわり
ジョンズ・ホプキンズ大の集計データに限らず、新型コロナウイルス関連のデータは、特に全世界の範囲を一様に網羅しているデータは、比べることそのものが無意味だという見解もあります。私個人としては感染者数ではなく死亡数(これはいくらなんでも水増しやその逆をし難い、がそれでも国によっては死因を特定できずカウント漏れがあるかもしれませんが)のトレンドはある程度のインサイトを含んでいると考えています。
あくまでもPower BIの練習用データとして多くの人の興味を引く(つまり学習のモチベーションが期待できる)新型コロナウイルスのデータを利用しているのであって、データソースの質に関しては暗示的にも明示的にもなんら価値判断を下していません。
あともう一つ、スクショなどは英語です。すみません。日本語版を使ったことが無いので。
準備
Power BI初心者を対象にしてるので、アカウント解説からスタートしますが、この辺りの整備が終わってる人はスキップしてください。
まずはローカルのPCで実行しているPower BIデスクトップにログインしている状態まで行きましょう。何もない状態からのスタートなら、まずはPower BIでフリーのアカウントを開設するところから始めます。
Power BI 無料アカウントを開設する
注意: セキュリティの都合上、GmailやOutlookなどのアドレスは使えません。組織(学校や会社)のメールアドレスを使いましょう。
https://powerbi.microsoft.com/en-us/power-bi-pro/

Power BI デスクトップをダウンロードする
この記事シリーズではPower BIデスクトップを使うので、ダウンロードしましょう。
使用するマシンは特に早いものじゃなくても大丈夫です。メモリーは1GBすら使わないのでノートパソコンで十分です(私もSurface Book 2ですべてやりました)

Power BI デスクトップにログインする
新規で作成したPower BIのアカウント(もしくは既存のもの)でPower BIデスクトップにログインします。

これで準備は完了です。
ジョンズ・ホプキンズ大学のデータをGithubから取得する
Johns Hopkins University (今後は「JHU」と表します)のGithubレポジトリで、下のディレクトリからCSV形式のデータファイルを3つ、データソースとしてダウンロードする手順を解説します。
以下の3種類のデータファイルをダウンロードします
-
confirmedglobal= 感染確認数 -
deathsglobal= 死亡数 -
recoveredglobal= 回復数
ちなみにアメリカ(US)のデータもありますが、今回はglobalを使います。

データファイルが3つあるので3回繰り返すことになりますが、そのうちのひとつを例にとって手順を解説します。
まずは、ひとつのデータファイル(この場合、confirmed のデータ)のRaw ボタンをクリックします。

このようにカンマで区切られたテキストデータの状態で、URLをコピーします

面倒くさがり屋さんのために、3つのデータファイルのURLを下に貼っておきます。
- https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv
- https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv
- https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv
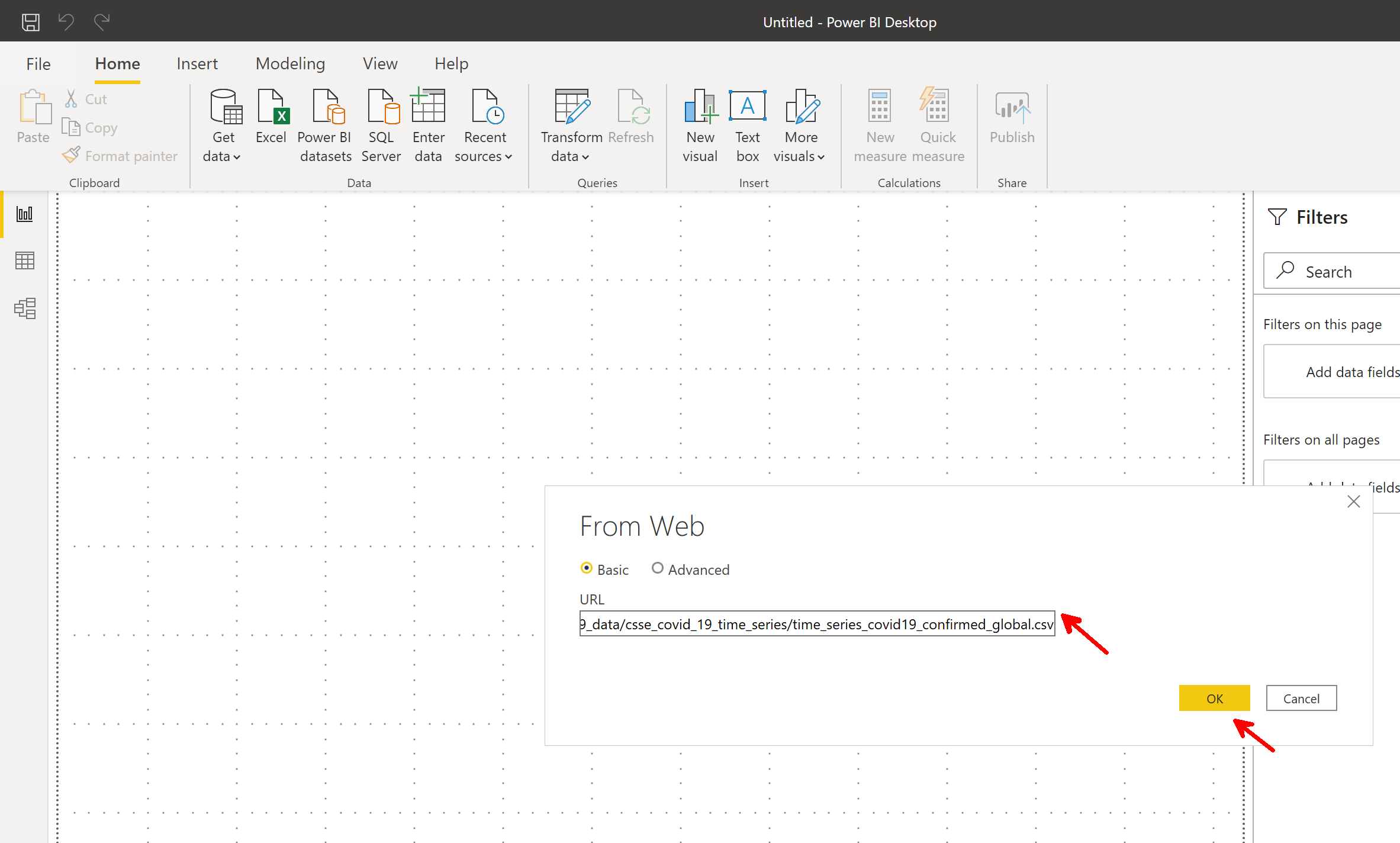
URLがコピーできたら、そのままの状態でPower BIPower BIデスクトップに移動して、以下の手順でURLをペーストする画面まで行きましょう。

URLをペーストしから、OKボタン。
データのプレビューが表示されますが、迷わずLoadボタンをクリック。
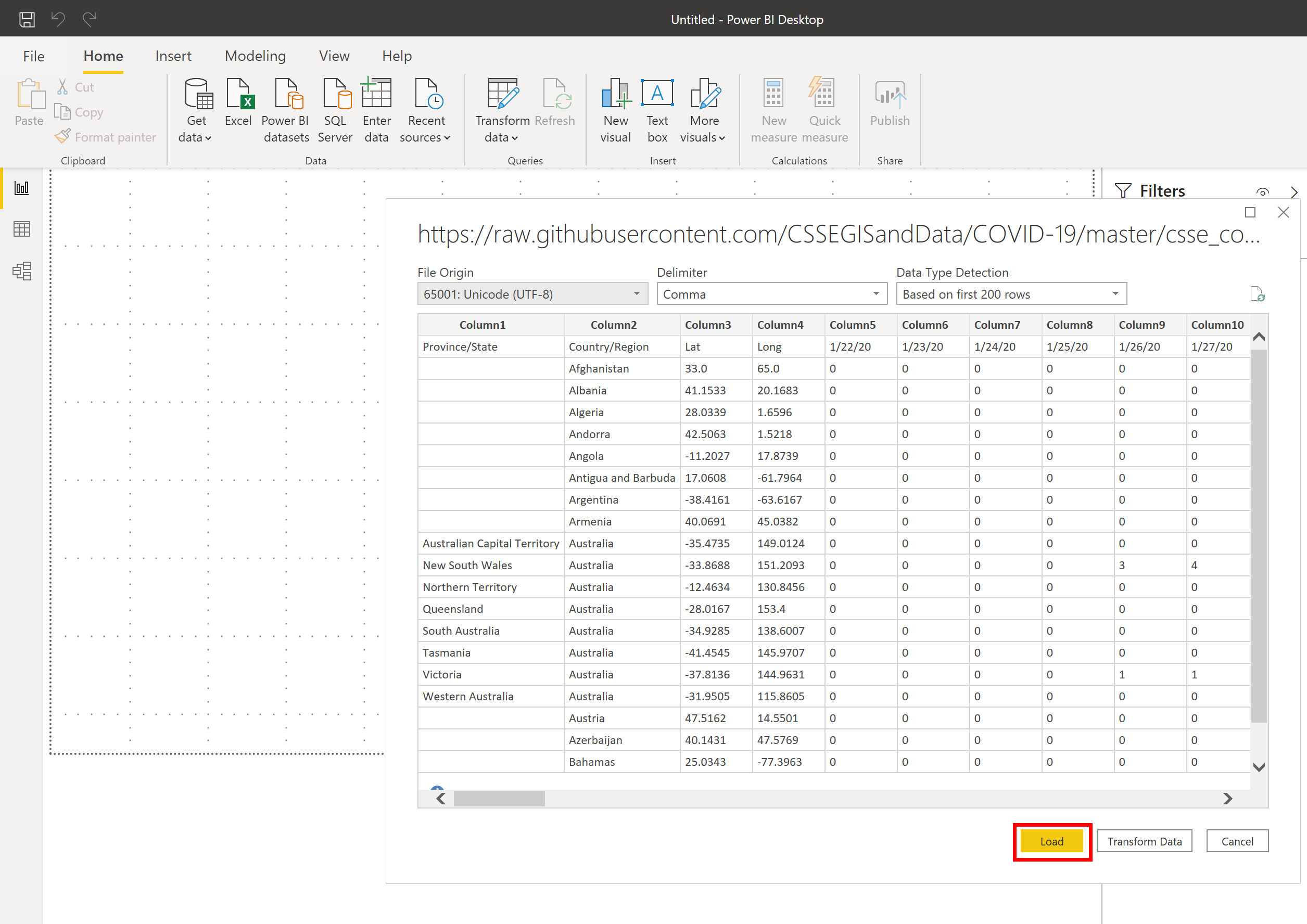
データが「適用(Apply)」されます。
これをあと2回、別の2つのデータファイルのURLを使って繰り返しましょう。
3つのデータファイルのダウンロードが完了したら、下図のように3つのPower BIクエリがワークスペースに加えられます。

これで必要なデータソースをPower BIデスクトップにクエリとして加え終えました。
ところでこのあたりのタイミングで、Power BIファイル(.pbix)として名前を付けて保存しておきましょう。(私はJHU-COVID19Analysis.pbix と名付けました)
2/5に続く
次の記事ではPower BI クエリからデータモデルを作るところを解説します。