最近、黙々と抽象的な概念なり新言語の考え方だのをインプットしています。
個人的な事情で、設計的なところを既存システムの在り方に頼り、客観的に評価できなかった反省を踏まえ、今回はクリーンアーキテクチャの理解をまとめます。
クリーンアーキテクチャの文脈では「設計 = アーキテクチャ」と言い切ってしまっているので、まさに設計のお話です。
クリーンアーキテクチャが言いたいことをパパッと理解したいとか大切さが知りたいとかいった人向けです。
実用的な面に関しては、有識の方が記載されている【参考】をご参照頂ければ幸いです。
クリーンアーキテクチャとは
「大切なルールほど、他のルールと独立した設計にしようや」という概念です。
ここでいうルールとは、決まりごと。そして決まりごとに即したプログラムのコードの両方です。
あらゆるソフトウェアは、アナログなビジネスをシステムによってデジタル化して定型化なり効率化なり自動化なりしているわけですが、ソフトウェアが構成している決まりやルールの大切さの度合いは、それぞれ違います。
大切なルールほど上位。大切じゃないほど下位のルールとなります。
どういった組み分けをするのかは、目的の後に記します。
クリーンアーキテクチャの目的
一番の目的は、「下位のルールが変わっても、上位のルールは変更しなくてもよいようにする」ということです。
下位のルールが変わったくらいで、上位のルールを変えない。上位のルールが変更された場合のみ、上から変更していこう。
上位を変える必要がなければ楽できる。そういった狙いのアーキテクチャです。
この目的にそえば、以下のメリットが得られる。
- コードの変更の必要にせまられたとき、その範囲が最小限になるようにする
- もっと言えば、「最上位であるビジネスルールが変更されたら変更箇所が多くなるのはまぁ仕方ないけど、コントローラーの内容が変わったくらいで何でそんなに苦労してるの?」といったツッコミができるようになる
- コンポーネント(※1)分割することで、人員が開発領域の分担化できるようになる
- 開発者は、自分の開発領域だけに集中しデプロイできるようになる。
- チームが並行して進められるようになる。
- プログラムをテストしやすい領域とテストしにくい領域に分けられる。
- 基本的にテストしやすい領域には、データ構造が決定された入出力データがないといけない。
- 単体テストでテストしたいものをテストしやすい領域に集めていく。
- 「ビジネス上の決まり」と「どのフレームワークを使うか、UIを使うか、DBを使うか」といった話を分けられる。
- CUIからGUIに変わろうと、GUIからATMに変わろうと、ATMからWebに変わろうと、上位のルール用に作ったプログラムを無駄にしなくてすむ。
※1:ここでいうコンポーネントとは、デプロイが必要な最小単位です。
このプログラムの範囲だけデプロイしとけば仕事が終わり、ユーザが喜ぶということです。
大切さの話はここまでです。
どんな感じで?と気になったら続きをどうぞ。
例に即したルールの組み分け
では、ルールの各レベルが何なのかというお話を銀行のビジネスに例えて記述します。
下記の1にいくほど上位、4にいくほど下位です。
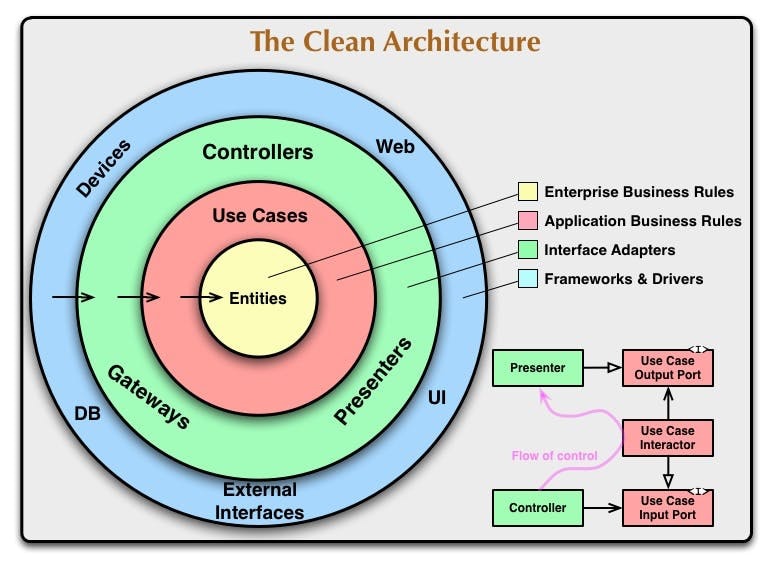
-
ビジネスルール
特定の会社が行う銀行のビジネスであれば、絶対不変のルール。
ある銀行が「お金を貸すとき、貸したお金の●%の利子をつけて貸します。」と決めたルールは、WebシステムだろうがATMだろうが受付だろうが同じ企業の銀行なら変わりません。 -
ユースケース
銀行員(ユーザ)のためにWebシステムによって自動化したいルール。
銀行員が顧客対応をするとき、「信用の数値が500以上ある顧客には、貸付の見積もりを出す。その数値を超えなければ見積もり自体出さない」という判断をしているとします。これをWebシステムで行いたい。となったらこれはユースケース上のルールです。
受付でもするが銀行員の判断が含まれていて、それを定型化し自動化したルール。 -
インターフェースアダプター
データフォーマットの変換ルール。
Web画面から顧客が貸付希望の依頼をしてきたら、信用の数値を引っ張り出してユースケースのルールに渡す。
このルールに即して、ユーザから受け付けたデータをユースケースに便利なデータフォーマットに変換、ユースケースから受け付けたデータを画面に表示させるためのデータフォーマットに変換する。逆に言えばデータ変換の橋渡しのみに徹するということです。 -
フレームワークやドライバー
ドライバー固有の書き方に即したルール。
銀行システムが受け付けた顧客データや貸付データをPostgreSQLのDBに格納する。
選定したDBに即したSQLだったり、外部サービスのアクセスのために用いたライブラリに即したコードを記述する部分。
1のビジネスルールが2のユースケースのルールを用いることはないし、2のユースケースが3のインターフェースアダプターのルールを用いることはないです。
逆に、4→3→2→1といった流れのルールの使用が自然なわけです。
クリーンアーキテクチャのミソな話(依存性の逆転)
基本的にプログラムはどの言語を使おうと以下の流れをしようと思えば、上位のルールを参照することになります。
- ユーザが、フォーム入力、送信
- アプリケーションが、フォームデータをユースケースのルールで扱えるようにデータ加工
- ユースケースのルールによる加工(★ここで参照!)
- (DB格納とかいったデータの保存)
- 結果を画面で表示できるようにデータ加工
- 画面に結果表示
ここで、インターフェースアダプターのプログラムがユースケースルールの実装プログラムのimportとかしてしまうと、ユースケースの実装ルールを引き継いでしまうことになります。ファイル単位でコードを切り分けたとしても、結局上位のルールは読み込んでしまう。
つまり、機能の実装だけしてればいいや、って考えているとクリーンアーキテクチャは実現不可能です。
銀行に例えるなら
『お金を貸してください、あとは頼みました』と依頼するまでをインターフェースアダプターの役割としたいのに、『お金を貸す方法を教えてもらって、貸す処理までウチで引き取るよ』となると、荷が重いわけです。
その場合に、インターフェースを挟みます。
インターフェースは、『ウチでは「お金を貸す」「お金を預かる」といったことをしているよー』と伝えるのがインターフェースです。まさに銀行窓口です。
そして窓口が裏で行なっている処理は、ユースケースのルールに即してユースケースのコンポーネントプログラムが行うようにする。
インターフェースを挟むことによって、アーキテクチャのレベルの切り分けからコンポーネントの切り分けといったことまでできるようになります。
依存性の逆転
プログラムが4→3→2→1と使用する流れがありつつ、ルールの独立性としては1 > 2 > 3 > 4と依存する関係を保つことができる。これを依存性の逆転といい、クリーンアーキテクチャのミソの部分になります。
ここまでがクリーンアーキテクチャがいいたいことの大枠です。
クリーンアーキテクチャの概念の凝縮性
補足の部分ですが、クリーンアーキテクチャは、以下の知見を組み合わせてベストプラクティスを目指そうという指向のもと生まれました。
実際にどう扱うかの細かい部分まで知りたければいかがキーワードになると思います。
- SOLIDの原則(クラス単位のデータの分け方)
- コンポーネントの原則(コンポーネント単位のデータの分け方)
- デザインパターン
- Humble Objectパターン(テストがしやすい領域としにくい領域に分ける)
- アーキテクチャ
- レイヤードアーキテクチャ(MVCやサービス、リポジトリといった技術的な役割による分け方)
- ヘキサゴナルアーキテクチャ(UI、DB、外部サービスといったインフラストラクチャとビジネスロジックを司るドメインの分け方)