Cousera - Andrew Ng 先生の Machine Learning Week3 のロジスティック回帰を実装してみました。できるだけnumpyだけ使ってやってみました。
恒例のおまじない。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
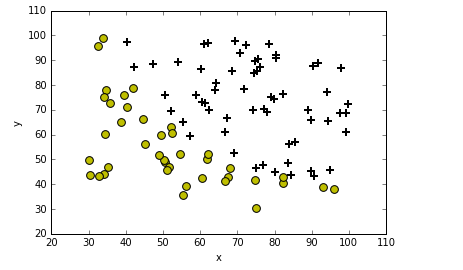
データ読み込んでプロットしてみる。
def plotData(data):
neg = data[:,2] == 0
pos = data[:,2] == 1
plt.scatter(data[pos][:,0], data[pos][:,1], marker='+', c='k', s=60, linewidth=2)
plt.scatter(data[neg][:,0], data[neg][:,1], c='y', s=60)
plt.xlabel('x')
plt.ylabel('y')
plt.legend(frameon= True, fancybox = True)
plt.show()
data = np.loadtxt('ex2data1.txt', delimiter=',')
plotData(data)
次にコスト関数とシグモイド関数の実装
$$h_θ(x)=g(θ^Tx)$$
$$g(z)= \frac{1}{1+e^{-z}}$$
シグモイド関数
$$j(θ)= \frac{1}{m}(log(g(Xθ))^Ty+(log(1-g(Xθ))^T(1-y)))$$
コスト関数
def sigmoid(z):
return(1 / (1 + np.exp(-z)))
def CostFunction(theta, X, y):
m = len(y)
h = sigmoid(X.dot(theta))
j = -1*(1/m)*(np.log(h).T.dot(y)+np.log(1-h).T.dot(1-y))
return j
では最初のコストをみてみましょう。
X = np.c_[np.ones((data.shape[0],1)), data[:,0:2]]
y = np.c_[data[:,2]]
initial_theta = np.zeros(X.shape[1])
cost = CostFunction(initial_theta, X, y)
print(cost)
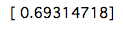
コストはこんな感じになりました。次に最急降下法の実装です。
def gradient_decent (theta, X, y, alpha = 0.001, num_iters = 100000):
m = len(y)
history = np.zeros(num_iters)
for inter in np.arange(num_iters):
h = sigmoid(X.dot(theta))
theta = theta - alpha *(1/m)*(X.T.dot(h-y))
history[inter] = CostFunction(theta,X,y)
return(theta, history)
initial_theta = np.zeros(X.shape[1])
theta = initial_theta.reshape(-1,1)
cost = CostFunction(initial_theta,X,y)
theta, Cost_h= gradient_decent(theta, X, y)
print(theta)
plt.plot(Cost_h)
plt.ylabel('Cost_h')
plt.xlabel('interation')
plt.show()
実行してみた結果が以下になります。
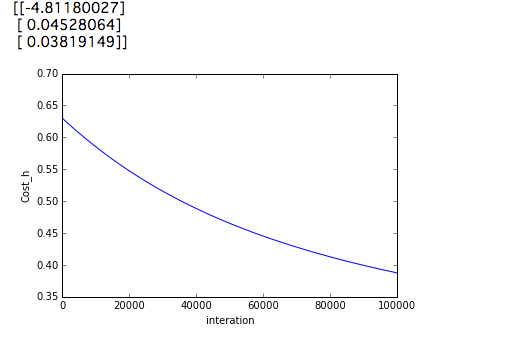
num_itersを10000000にするよりこうするほうがなぜかいい結果が得られます。では結果を見てみましょう。
def predict(theta, X, threshold = 0.5):
p = sigmoid(X.dot(theta)) >= threshold
return(p.astype('int'))
p = predict(theta,X)
y = y.astype('int')
accuracy_cnt = 0
for i in range(len(y)):
if p[i,0] == y[i,0]:
accuracy_cnt +=1
print(accuracy_cnt/len(y) * 100)
上記のコードを実行すると91.0%が得られます。ではnum_interを1000000で実行するといかのようになります。。
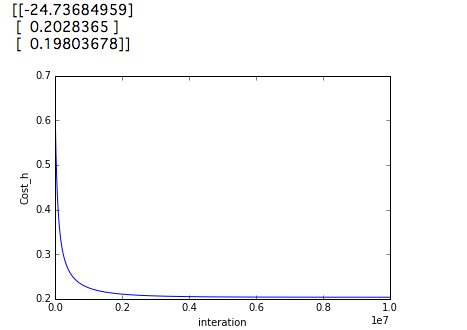
この精度を調べると89.0%になります。なぜコストが低いのにもかかわらず、上記の結果の方が悪くなるのかは不明です。
参考