はじめに
対象読者
- GraphQLについてざっくり学びたい人
- 公式ドキュメント読むのがしんどい人
- Apollo/Relayどっちを使うか迷っている人
GraphQL概論編
RESTful API
代表的なWeb APIである、REST APIについて、簡単にまとめつつ、
GraphQLでできることについて、書いていこうと思います。
RESTful API(REST API)とは、Webシステムを外部から利用するためのプログラムの呼び出し規約(API)の種類の一つで、RESTと呼ばれる設計原則に従って策定されたものです。RESTそのものは適用範囲の広い抽象的なモデルだが、一般的にはRESTの考え方をWeb APIに適用したものをRESTful APIと呼んでいます。
RESTful APIでは、URL/URIですべてのリソースを一意に識別し、クライアントがHTTP(あるいはHTTPS)で要求(リクエスト)を送信すると、応答(レスポンス)がXMLやHTML、JSON、CSV、プレーンテキストなどで返されます。
引用元
とIT用語辞典に書いてあるのですが、かなりざっくりまとめると、
REST APIでは、あるURIにアクセスすると、そのURIに結びつく情報をレスポンスとして返します。
例えば、以下のエンドポイントにリクエストを送信すると、それぞれ固有のレスポンスを返すということです。
例:
/api/food/hot-dog
/api/sport/skiing
/api/city/Tokyo
RESTful APIの特徴
RESTful APIの特徴の一つとして、過剰な取得というものがあります。
説明のためにREST API版のSWAPIを利用し、https://swapi.dev/api/people/1/にGETリクエストを投げてみます。
下記にResponseを記載します。
ですが、もしクライアントが本当に必要だった情報が**"name"**, "height", **"mass"**だった場合、余分なデータが多いことが分かります。
これが、REST APIの過剰取得という特徴です。ただ、気をつけたいのは、この特徴はデメリットということではなく、あくまでのその使用用途に依存します。なので、通常REST APIを使用する場合は、不必要な情報は使い捨てるような使い方になると思います。
{
"name": "Luke Skywalker",
"height": "172",
"mass": "77",
"hair_color": "blond",
"skin_color": "fair",
"eye_color": "blue",
"birth_year": "19BBY",
"gender": "male",
"homeworld": "http://swapi.dev/api/planets/1/",
"films": [
"http://swapi.dev/api/films/1/",
"http://swapi.dev/api/films/2/",
"http://swapi.dev/api/films/3/",
"http://swapi.dev/api/films/6/"
],
"species": [],
"vehicles": [
"http://swapi.dev/api/vehicles/14/",
"http://swapi.dev/api/vehicles/30/"
],
"starships": [
"http://swapi.dev/api/starships/12/",
"http://swapi.dev/api/starships/22/"
],
"created": "2014-12-09T13:50:51.644000Z",
"edited": "2014-12-20T21:17:56.891000Z",
"url": "http://swapi.dev/api/people/1/"
}
GraphQLって何???
まず、GraphQLを学ぶにあたり、グラフ理論についてざっくり知っているといいので、説明します。
グラフ理論
グラフ理論とは、ノード(頂点)の集合とエッジ(辺)の集合で構成されるグラフに関する学問です。
例
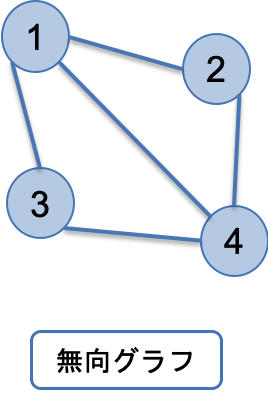
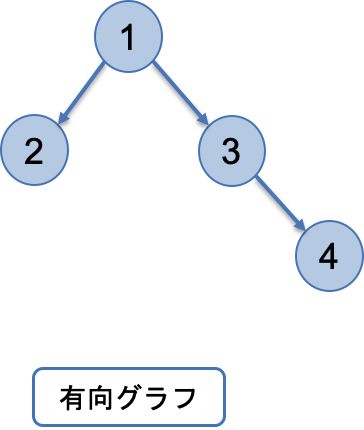
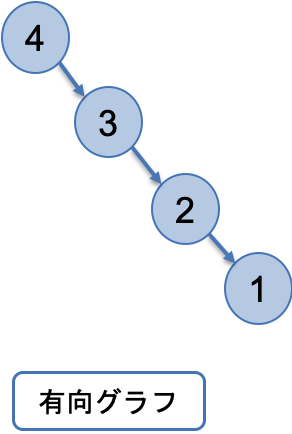
この学問の発祥になったとされるのが、ケーニヒスベルクの橋の問題です。こちらは有名なので、別途調べていただけると面白いと思います。※ここでは、割愛させていただきます。
グラフ理論とGraphQL
グラフ理論とGraphQLの繋がりを分かりやすくする為に、FacebookのようなSNSを考えてみます。
例
下記の図は、アイアンマンを基点に彼のfacebookで繋がっている友人関係をリクエストした時の繋がりを表しています。
そうするとこのリクエストは、下記の木のような構造になります。
指定したアイアンマンが根で、そのアイアンマンに紐づく友人関係が子になる形です。
このリクエストで、アイアンマンは彼の友人同士とエッジで接続されていることが分かります。
実は、この構造がGraphQLのクエリに似ているのです。

ツリー構造
・person
- name
- location
- birthday
- friends
* friend name
* friend location
* friend birthday
GraphQLのクエリ
{
me {
name
location
birthday
friends {
name
location
birthday
}
}
}
GraphQLとは
- GraphQLとは、 API用のクエリ言語であり、TypeSystemを使用してクエリを実行するためのサーバ側のランタイムです。
- また、クライアントがサーバからデータを取得、変更、講読ができるようにするためのデータ言語でもあります。

GraphQLの特徴
- 型指定されたスキーマ
・ フロントエンジニアだけで、開発や対応ができるようになります。
・ 型指定ができるので、型が堅牢になります。 - クライアントからのレスポンス形式の指定
・ クライアントからレスポンスの形式を指定できるようになります。
これによりオーバフェッチ、アンダーフェッチがなくなります。 - サブスクリプションを利用したリアルタイム処理
・ クライアントはデータをサブスクライブすることで、イベントドリブンに処理を実装することが可能になります。
クライアントからのレスポンス形式の指定
クリーンなインターフェースを実現できます。
どういうことかというと、例えば、下図のようにREST APIを利用し、ある1つの画面に表示すべきデータをフェッチするのに、複数のリソースに対しAPIを叩かなければならない場合、URIを複数アクセスする必要があります。
それに比べ、GraphQLの場合ですと、1つのリクエストで複数のリソースに対し問い合わせをする処理をGraphQL側がまとめ処理することができます。
これによりクリーンなインターフェースになるということです。

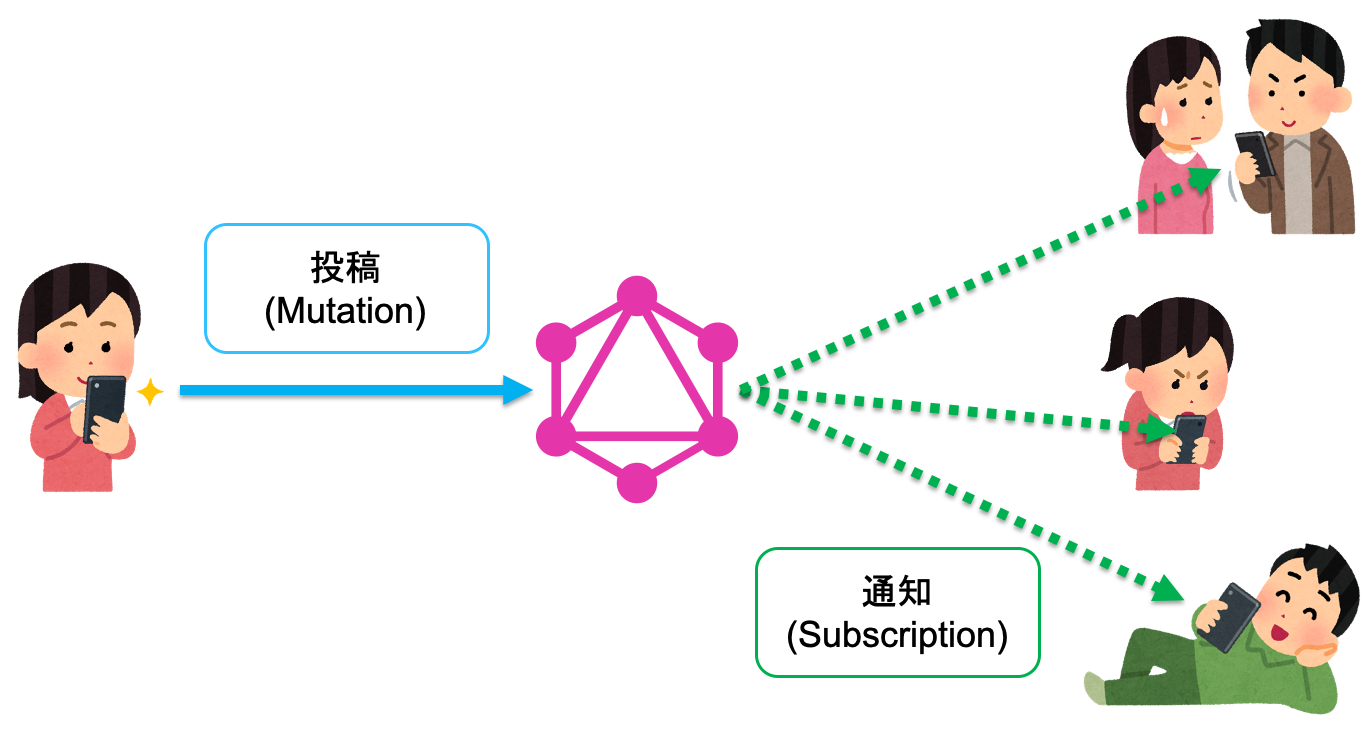
サブスクリプションを利用したリアルタイム処理 ①
Mutationをトリガーにしたイベントベースでの処理が行えます。
Mutationとは、GraphQLにおけるトランザクション処理(Put/Post/Delete)のことを指しています。
なので、クライアント側でPut/Post/DeleteをGraphQLサーバ側に行った場合、このPut/Post/Deleteの処理をサブスクリプションしているクライアントがいた場合、そのクライアントに対し、行われた処理内容のデータをpushすることができます。
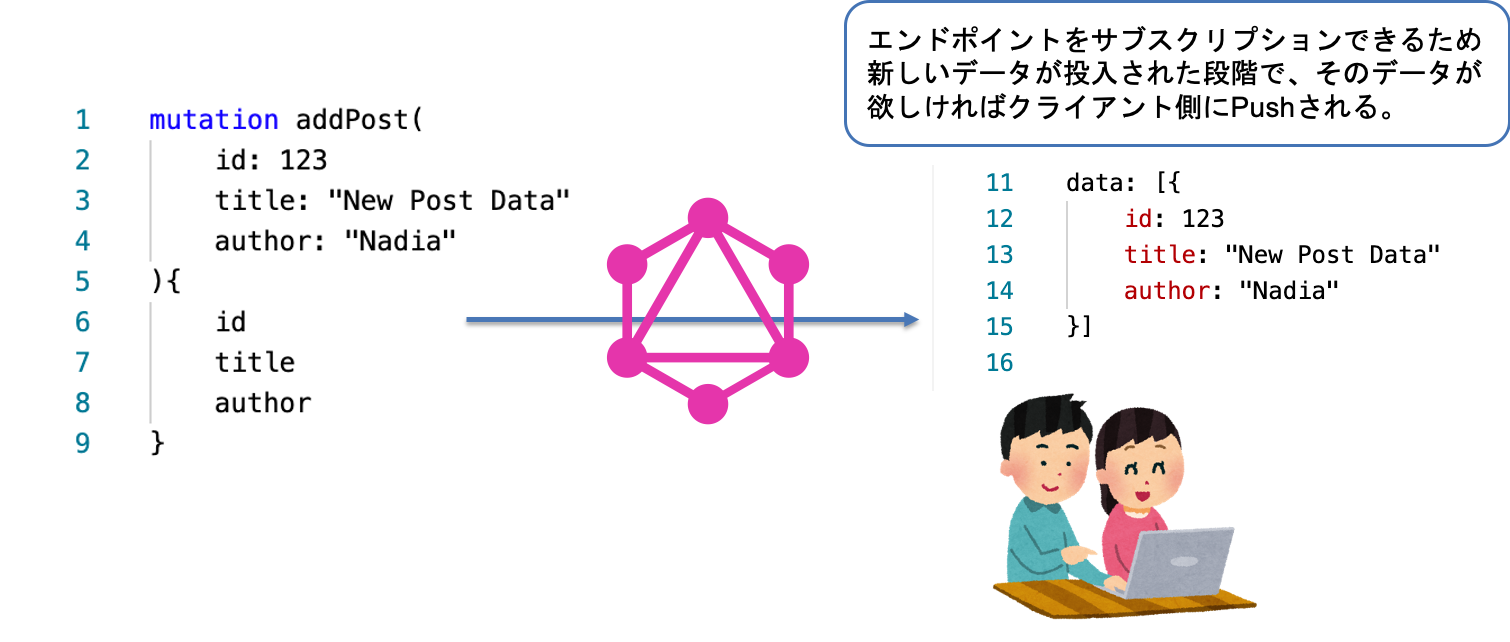
サブスクリプションを利用したリアルタイム処理 ②
実際のGraphQLサーバ側のスキーマとClient側の処理例

サブスクリプションを利用したユースケース
もし、サブスクリプションを使うとした場合、考えられるユースケース
- チャットアプリ
- SNS
- お知らせ等の通知機能
etc...
GraphQLに対する問題(デメリット)
- 変更管理
- ・ データを取得して操作するためにGlaphQL APIの仕様を理解する必要があります。
- ・ フロントエンドからのクエリを処理する方法を理解する必要があります。
- N + 1 問題
- 「1 つの SQL で N 件のレコードをフェッチしたあと、 それぞれ(フェッチした項目)に対して関連するレコードを個別にフェッチするのに N回 SQL を発行している」 状態です。
- これ何が問題かというと、この状態になると、RDB サーバと通信するための時間及びRDBMSがSQLを 解析する時間が増加する恐れが考えられます。
# N個のarticlesをフェッチする(SQLは1つ)
SELECT * FROM articles;
# articles ごとにuserをフェッチする(SQL1つがN回)
SELECT * FROM users WHERE id = 1;
SELECT * FROM users WHERE id = 2;
SELECT * FROM users WHERE id = 3;
SELECT * FROM users WHERE id = 4;
SELECT * FROM users WHERE id = 5;
SELECT * FROM users WHERE id = 6;
・
・
・
- Client側のキャッシュ戦略
- GraphQLは単一エンドポイントなので、HTTPのCache-ControllのようなURLベースのキャッシュ機構やCDNでのキャッシュ(reduxなど)はそのままでは使用ができません。
N + 1 問題
- 解決策
- N 回繰り返している SQL を 1 つにまとめる必要があります。
- → 遅延読み込み(Lazy Loading): 必要なデータが分かったあとで読み込み実施します。
- 遅延評価
- 必要なデータを一通り宣言したあとで、それらをまとめて一括で解決する。
- Resolver(スキーマによる名前解決)が promise を返した場合、その promise が fullfilled になるまで GraphQL は後続の評価を待つようにする。
Client側のキャッシュ戦略
- ネットワークキャッシング
- リクエストを傍受し、アプリケーションサーバーにアクセスする代わりに、メモリから直接応答を返します。
- → CDNでのキャッシュ(reduxなど)
- 解決策
- Client側における実装で、キャッシュを管理できるライブラリを使用します。
- 詳しくはGraphQL実装編で説明します。
GraphQL実装編
今回取り扱う実装パターン
- サーバサイド
- Express + Apollo server
- フロントエンド
- 1. React + Apollo client
- 2. React + Relay
Express, Apolloとは
- Express
- Node.js Web アプリケーションのフレームワークです。
- Apollo Pratform
- GraphQLのためのデータグラフの構築、クエリ、および管理を支援するライブラリです。
- データグラフとは、アプリケーションクライアントとバックエンドサービスの間に位置し、 それらの間のデータの流れを指します。

導入方法
- 前提条件
- Node.js v8.x 以上
- npm v6.x 以上
- git v2.14.1 以上
- Apollo Serverの複数の使用方法
- 1. サーバーレス環境を含むスタンドアロンのGraphQLサーバーです。
- 2. 既存のNode.jsミドルウェア(Expressなど)へのアドオンです。
- → Apolloプラットフォームは、段階的な採用を推奨している為です。
- 3. 複数のサービスにおける単一のデータグラフを利用するためのゲートウェイとしての使用です。
Apollo Serverによる実装例
- 依存関係のあるライブラリをinstall
- [apollo-server] : Apollo Server自体のコアライブラリです。
- [graphql] : GraphQLスキーマを構築し、それに対してクエリを実行するために使用されるライブラリです。

- GraphQLスキーマを定義
- クライアントがクエリできるデータの構造を定義します。
- クライアントは、 [books]というクエリを実行でき、サーバーは0個以上[Book]の配列を返します。
const { ApolloServer, gql } = require('apollo-server');
const typeDefs = gql`
type Book {
title: String
author: String
}
type Query {
books: [Book]
}
`;
- データセットの定義
- 上でデータ構造を定義したので、ここではデータ自体を定義します。
- 接続する任意のソース(データベース、REST API、または別のGraphQLサーバー等)からデータをフェッチできます。
- ここでは、サンプルデータをハードコードします。
const books = [
{
title: 'xxxxxxxxxxxxxxx',
author: 'yyyyyyyyyyyyyy',
},
{
title: 'xxxxxxxxxxx2',
author: 'yyyyyyyyyy2',
},
];
- Resolverの定義
- Apolloサーバーはクエリの実行時にそのデータセットを使用する必要があることを認識していない。そのために、Resolverを作成します。
- Resolverは、特定の[type]に関連付けられたデータをフェッチする方法をApolloサーバーに伝えます。
const resolvers = {
Query: {
books: () => books,
},
};
- Apollo-Severのインスタンスを作成
- 初期化時に、[スキーマ], [データセット], [Resolver]をApolloサーバーに提供します。
const server = new ApolloServer({ typeDefs, resolvers });
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});

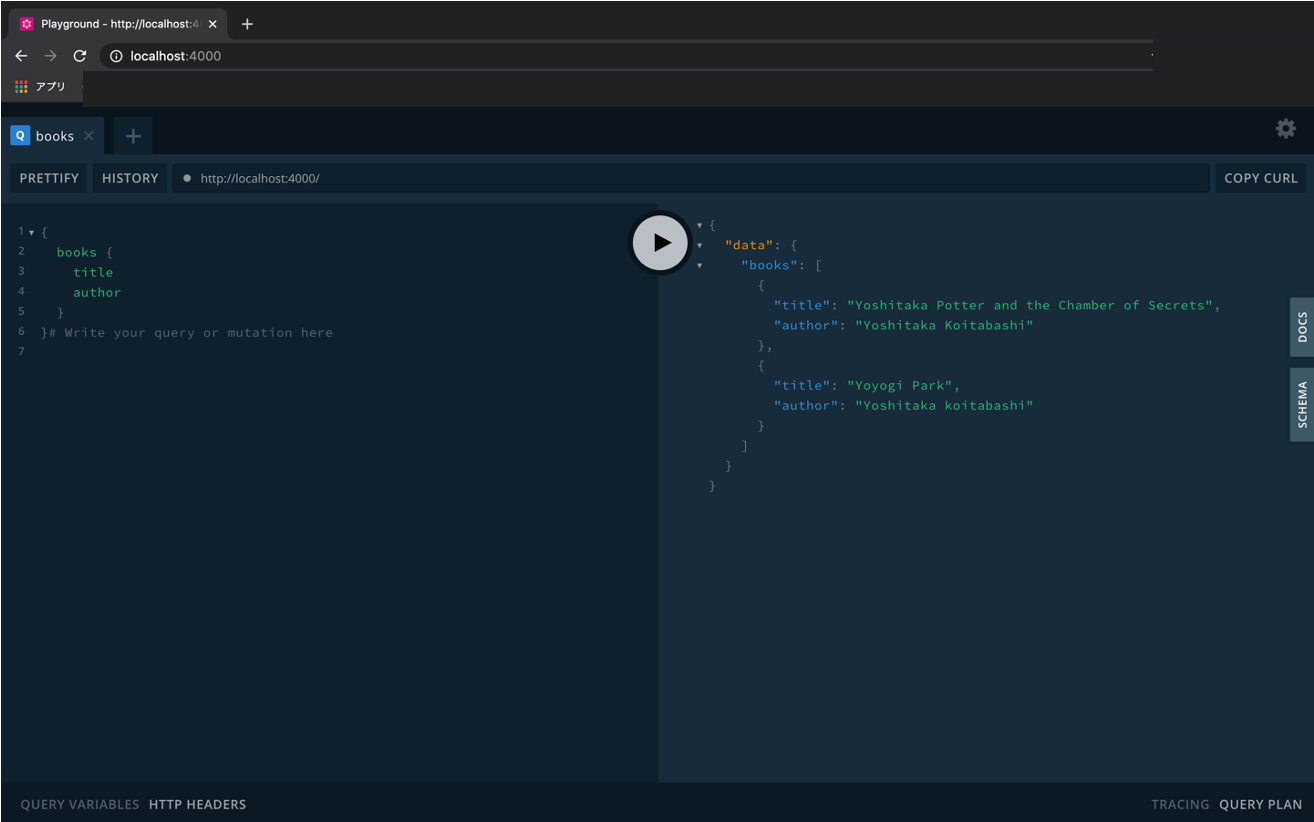
GraphQL Playgroundツールを利用してクエリを実行
Client側の実装例
- React + Apollo client
- React + Relay
Apollo Client / Relay
- Apollo clientは、キャッシュ機能と状態管理機能を備えたJavaScript GraphQLクライアントです。
- Relayは、GraphQLを利用したReactアプリケーションを構築するためのJavaScriptフレームワークです。
Apollo Client VS Relay
- [Client側のキャッシュ戦略]に依存すると思っています。

Apollo Clientにおけるキャッシュと状態管理
- Apollo Clientには、ローカルデータをリモートデータと一緒にApolloキャッシュ内に保存できるローカル状態処理機能が組み込まれています。

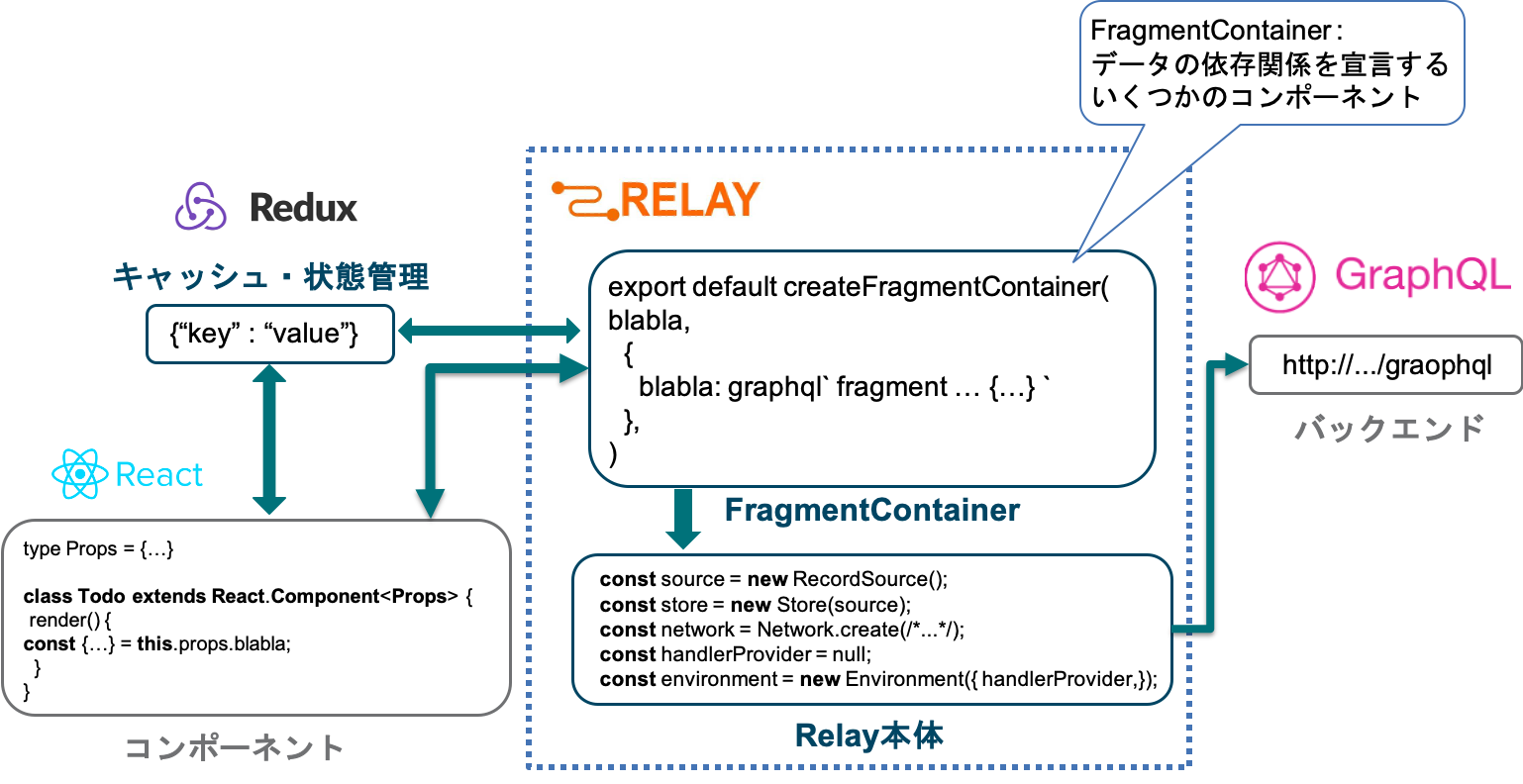
Relayにおけるキャッシュと状態管理
- Reduxを用いての状態管理となります。
まとめ
- 実はApollo以外の選択肢として、AWS Appsyncを利用する方法もある。こちらについては、別記事としていずれ書こうと思います。
- Apolloを利用する場合のメリットは、Expressを利用したWeb APIを既に作成しており、プロジェクトの都合等でGraphQLを利用する場合、Apolloをアドオンすることができ、そうした場合、徐々にGraphQLへ移行することができます。