概要
- 2023年7月18日に LLM アプリケーションのデバッグ、テスト、評価、監視するプラットフォーム LangSmith が公開されました。
- 今回は公開された LangSmith について調べ、検証してみた記事となります。
LangSmith
LangChain は、今まで LLM を利用したアプリケーションを作成する際により開発者に楽に実装ができるよう構築されたフレームワークです。
ただ、課題として今まではこれをプロトタイプで作成するのは良いが、実際の本番環境で運用する際に歯痒かったものを提供するプラットフォームとして公開された形となります。
例えばどんなところが歯痒かったの?
下記のようなことで困った開発者はいるのではないでしょうか。
- LLM 呼び出しの最終的なプロンプトが何であったのか(プロンプトテンプレートのフォーマットが終わった後にできた最終のプロンプトのことですね。)
- 各ステップで LLM 呼び出しから何が返されるのか知りたい。
- LLM または他のリソースへの呼び出しの正確なシーケンスと、それらがどのように連鎖しているかを知りたい
- トークンの使用状況
- コストの管理
- 遅延している箇所のデバッグ
LangSmith が解決すること
- アプリケーション開発者が上記のようなことに時間を使うのではなく、デバッグ、テスト、ロギング、監視などのための一連のツールとして、LangSmith が公開されました。
検証してみた
主な機能
- ロギングとトレース
- テストと評価
ロギングとトレース
LangSmith を使用すると、LLM を使ったアプリケーションの実行のログを簡単に記録することができます。
具体的には、LangChain 内の提供されているコンポーネントの入力と出力を検査することができます。
これによって、アプリのデバックや特定のコンポーネントの動作を確認することができるようになるイメージです。
使用方法
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=<your-api-key>
LANGCHAIN_PROJECT=<your-project>
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
llm.predict("Hello, world!")
- 実行されたものは LangSmith 上のプロジェクトに保存されるようです。
- トレースを有効にした状態で、LangChain コンポーネントを実行するか、LangSmith SDK を使用して実行ツリーを直接保存するたびに、実行の呼び出しが順が階層で保存され可視化されます。
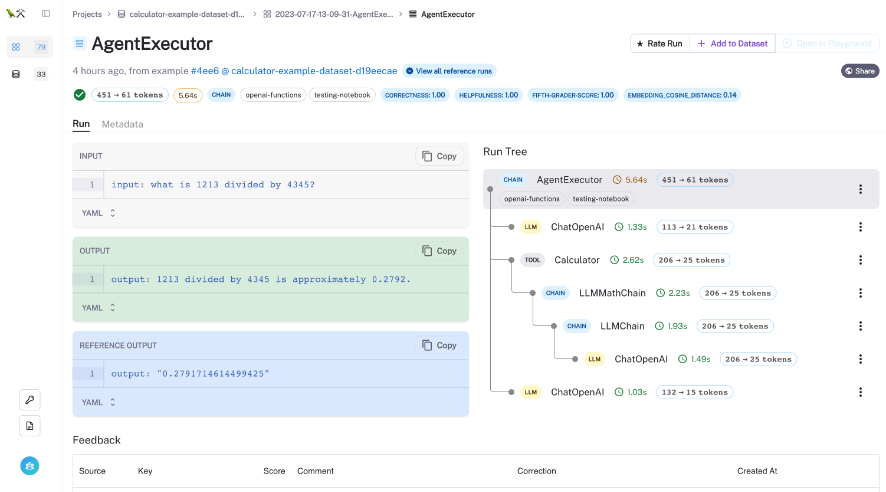
ここがすごいよ LangSmith
どうやら、実行トレースが取得できると、サポートされているチェーン、LLM、チャットモデルのプロンプトとパラメーターを直接変更して出力がどのようになるのか確認できる機能があるよう。
モデルの変更や、Temperatureの調整などやった時の変化が見れるの嬉しいですね!
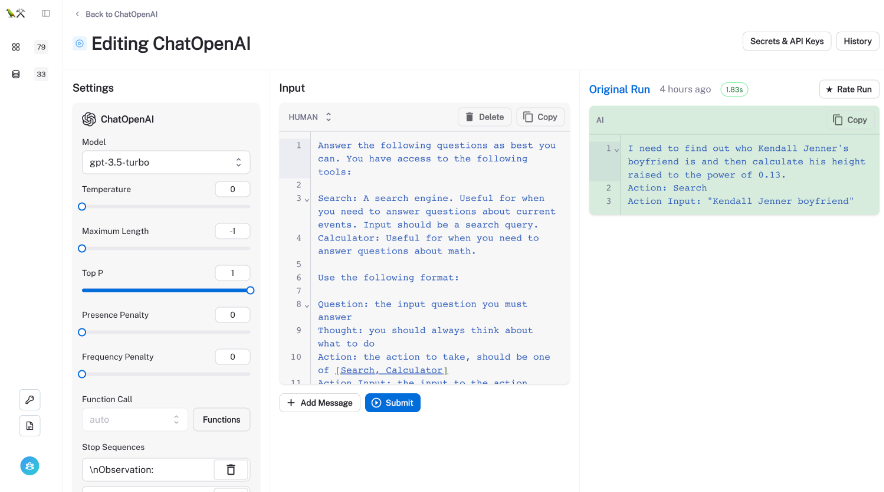
テストと評価
LLM アプリケーションを作成しようとした時に多くの課題が LLM アプリの品質を下げる要因になります。
例えば
- 出力結果が揺らぐ: 同じプロンプトに対して異なる出力が生成される(例え、temperatureが0で設定されていたとしても)
- APIの背後にあるモデルは時間の経過とともに変化する
- LLM はプロンプトインジェクションに対して脆弱
- 最先端のモデルは高価になる場合がある
- レイテンシー
LangSmith を使うと??
LangSmith の機能を使うと、より良いモデルの選択やプロンプト、コードのチェックなど上記の問題に対処する方法を見つけることができます。
必ずしも答えが出るわけではないが、問題を検出する助けになる自動評価ツールを提供しているようです。
評価
使い方としては、以下の順番で設定するようです。
1: 入力例のデータセットを作成する
2: 評価する LLM、チェーン、またはエージェントを定義する
3: 評価を構成して実行する
4: LangSmith で結果のトレースと評価フィードバックを確認する
準備
pip install -U "langchain[openai]"
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=<your api key>
1: 入力例のデータセットを作成する
from langsmith import Client
example_inputs = [
"a rap battle between Atticus Finch and Cicero",
"a rap battle between Barbie and Oppenheimer",
"a Pythonic rap battle between two swallows: one European and one African",
"a rap battle between Aubrey Plaza and Stephen Colbert",
]
client = Client()
dataset_name = "Rap Battle Dataset"
dataset = client.create_dataset(
dataset_name=dataset_name, description="Rap battle prompts.",
)
for input_prompt in example_inputs:
client.create_example(
inputs={"question": input_prompt},
outputs=None,
dataset_id=dataset.id,
)
2: 評価する LLM、チェーン、またはエージェントを定義する
下記のサンプルコードのように、データセットには単純な入力のスキーマを用意し、このデータセット上の任意の LLM またはチェーンを評価します。
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
def create_chain():
llm = ChatOpenAI(temperature=0)
return LLMChain.from_string(llm, "Spit some bars about {input}.")
3: 評価を構成して実行する
LangSmith は、LangChainで提供されている、データセットに対するトレースを生成するためのメソッドとして、run_on_dataset および、arun_on_dataset がある。
下記はあくまで例だが、下記のようなコードを書くことにより、評価が実行されフィードバックは LangSmith 内に自動的に記録されます
LangChain は、データセットに対する予測 (およびトレース) を生成するための便利なrun_on_datasetおよび非同期arun_on_datasetメソッドを提供します。RunEvalConfigが提供されると、構成されたエバリュターが予測にも適用され、自動フィードバックが生成されます。
from langchain.smith import RunEvalConfig, run_on_dataset
eval_config = RunEvalConfig(
evaluators=[
"criteria",
RunEvalConfig.Criteria("harmfulness"),
RunEvalConfig.Criteria(
{"cliche": "Are the lyrics cliche?"
" Respond Y if they are, N if they're entirely unique."}
)
]
)
run_on_dataset(
client=client,
dataset_name=dataset_name,
llm_or_chain_factory=create_chain,
evaluation=eval_config,
verbose=True,
)
4: LangSmith で結果のトレースと評価フィードバックを確認する
評価結果は、「Rap Battle Dataset」にリンクされた新しいテストプロジェクトにストリーミングされます。
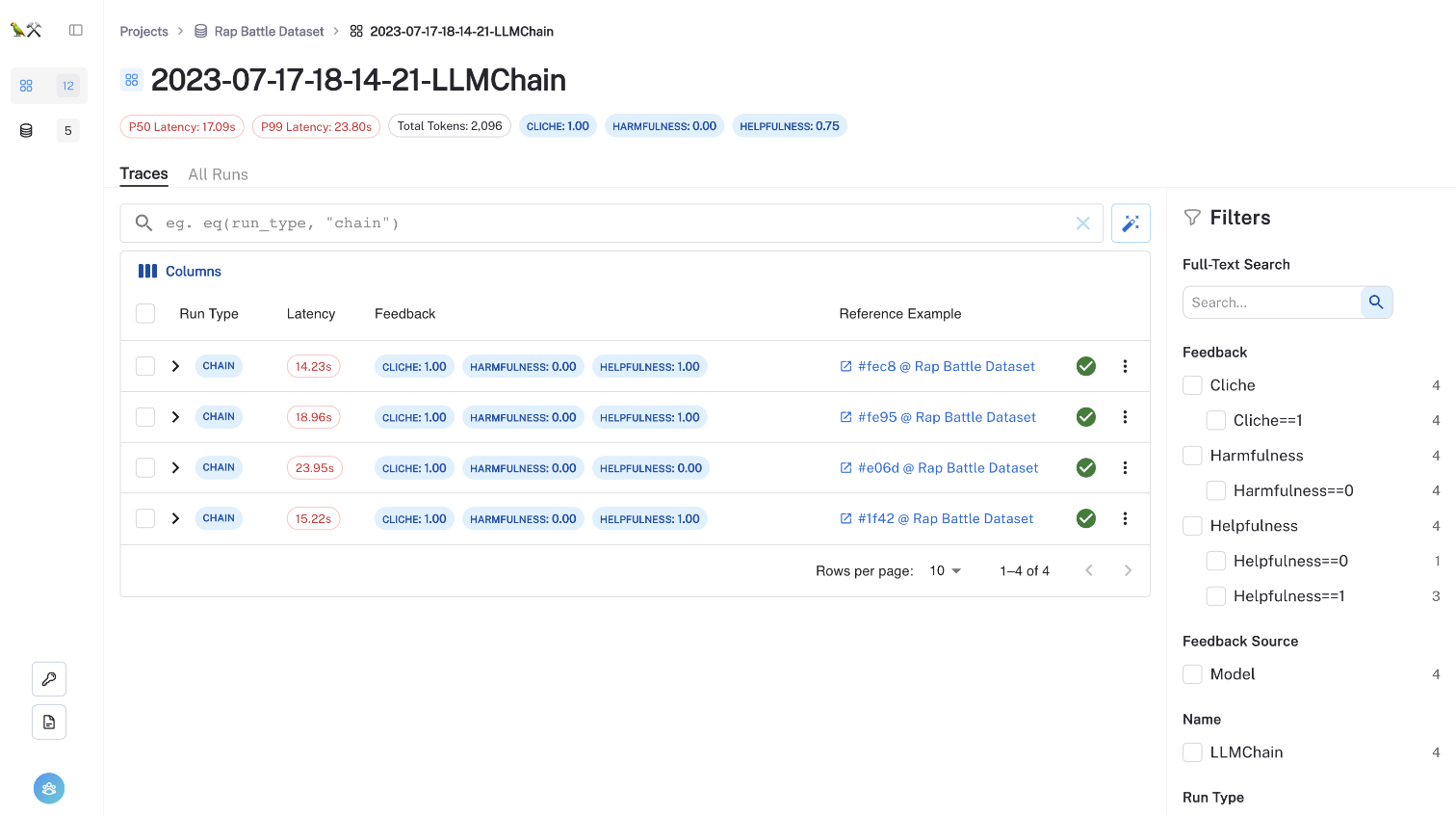
やってみた
1: サポートされているログイン方法のどれかを使用して、LangSmith アカウントを作成します。
ログインするとこんな画面になります。
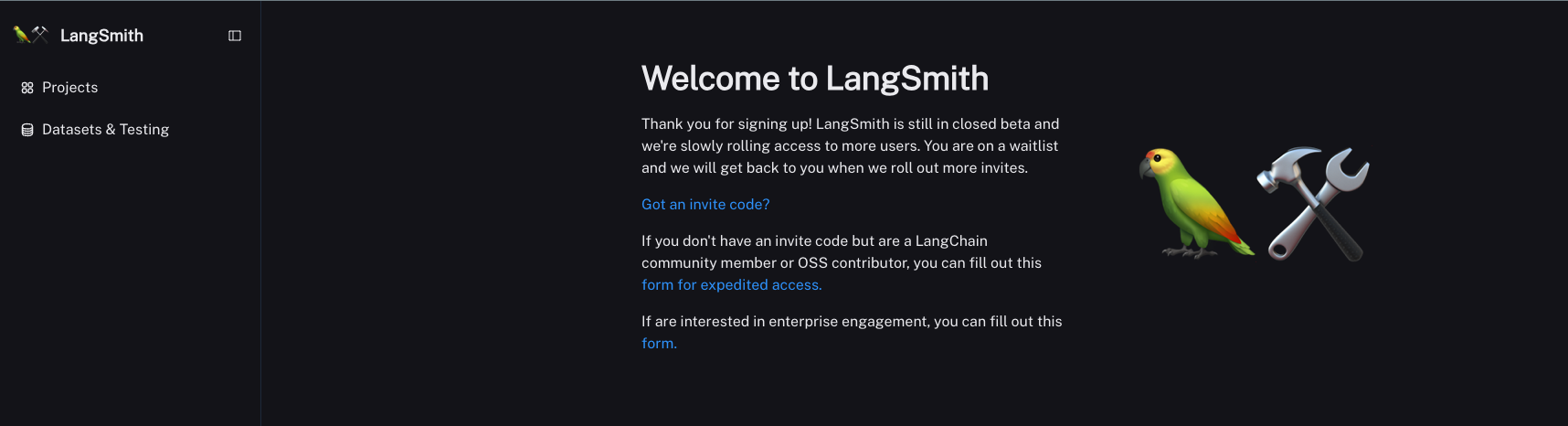
2: 設定ページに移動して API キーを作成します。
と思ったら・・・
どうやら LangSmith まだプライベートベータ版なようで early access をする場合、OSSのコントリビュータか、Waiting listへの登録が必要なよう。
一旦、申し込みだけ完了して次報を待ちます。
連絡書き次第、改めて検証していこうと思います。

LangSmith Waitlist
下記が、LangSmith Waitlistのページです。
これを見た人は全員登録しましょう。
参考文献