概要
- AWS で人気のサービス DynamoDB についての論文が公表され巷で噂になっていたと思う。
- 今回は、その論文を読み込んでいき、ざっくりまとめていくという記事になります。
- 完全趣味な記事なので、興味ある人がいれば幸いです笑
Abstract
- まず論文のタイトルですが、「Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service」と題したものとなっています。
- Amazon DynamoDB は、NoSQL とよばれる部類のデータベースサービスです。
- 一貫した耐久性、可用性、パフォーマンスを提供してくれるマネージドなサービスなのが特徴ですね。
- 冒頭、2021年に66時間にわたる「Amazon Prime Day」中にピーク時8920万リクエスト/秒をさばいていたようです。すごいですね。
Introduction
- DynamoDB の進化は凄まじく、特にこの10年で起こったこと、何を改善してきたのかが語られている貴重な論文だと思う。
(画像引用基: https://www.usenix.org/conference/atc22/presentation/elhemali)
ということで、論文内にある重要な箇所を引っこ抜きながらまとめていく。
DynamoDBとはどういうものか
-
マネージドなクラウドサービス: VM などの計算資源を自分でプロビジョニングしなくてよく、障害対応なんかもやってくれる。
-
マルチテナントアーキテクチャ: ユーザからは見えないようになっているが、DynamoDB は異なるお客さんの資源(データ)を同じ物理マシンに格納しているが、公平にリソースの利用効率を保てるような仕組みを持っている。
-
boundless scale for tables: テーブルのスケールを無限に増やせる。裏にあるストレージのノードがどんどんシャードされて増えていく。
-
性能が予測が可能: DynamoDB は早いし、遅くならない。put とか get とかの KVS (キーバリューストア)の基本的な操作のレイテンシーが50%タイルと99%タイルで倍しか違わない。1KB の get でサーバサイドレイテンシが数ミリ秒。ただし、高いスループットになった状態でレイテンシを維持しようとすると金を払わないといけない。金を払わないとスロットルされる。
-
highly available: 落ちないということ。DynamoDB はデータをレプリケートする。複数のデータセンター(AWSではいうところのAZ)にまたがり、自動的に再レプリケーションを行う。また、ディスクやノードに障害が発生した場合、自動的に再レプリケーションする。
- また、リージョンテーブルとグローバルテーブルという概念がある。
- リージョンテーブルは、同一リージョンの中の複数のAZにストレージが散らかっている。SLAは、99.99%
- グローバルテーブルは、複数リージョン間でレプリケートしてくれる。SLAは、99.999%
- なので、単一のazに紐づいていない。(デフォルトでやってくれる)
- また、リージョンテーブルとグローバルテーブルという概念がある。
-
supports flexible use cases: スキーマとかないドキュメントベースのデータベース。
Architecture
主要な登場人物
-
ストレージノード: データをファイルに持っているやつ。
- DynamoDB の個々のテーブルはパーティションされていて、そのパーティションを持っているのがストレージノード。
- ストレージノードは、1個のパーティションをもっているだけではなく、いろんなテーブルの複数のパーティションを持っている。
-
メタデータサービス: いろんなメタデータを持っている。どのテーブルのどのキーの範囲がどのパーティションに対応していて、そのパーティションがどのストレージノードにあるかという情報を持っている。
-
リクエストルータ: ユーザからのリクエストを受け取って、まずメタデータサービスにそのリクエストに対応するストレージノードをくれと問い合わせて、返却されたストレージノードに問い合わせデータをフェッチして返すような動き。
-
オートアドミンサービス: システム全体をヘルスチェックとかして見張っている。ノードを増やす減らすといった作業や、障害を見つけたときに復旧するとかをしている。コントロールプレーンのAPIを判定するのもこやつ。
[下記が、DynamoDBのarchitectureを図にしたもの]
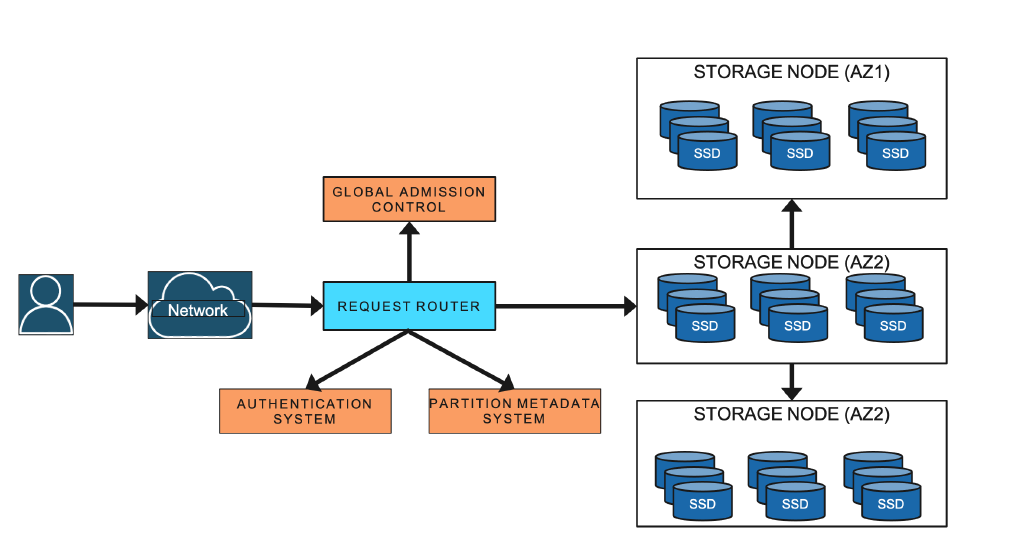
(画像引用基: https://www.usenix.org/conference/atc22/presentation/elhemali)
- あるインデックスは、どのプライマリキーという情報を持っているノードがいる気がしており、クエリルータがよしなにしてくれる。
- セカンダリインデックスがどのカラムにあるかというのは、メタデータの一部な気がする。
ストレージノードの詳しい話
-
DynamoDBのテーブルは複数のパーティションに分割されている。
-
各パーティションはどこかのストレージに格納されている。
-
パーティションをどのタイミングで分割するかという基準は2つある。
- ①: データがでかくなりすぎたらパーティションする
- ②: リクエストのスループットが増えてきたらパーティションする(つまりデータが少なくてもリクエストの負荷分散のためにパーティションする)かつ、レプリケーションもする(アベイラビリティを上げるため)。パーティションはAZを跨いでレプリケートする。
-
気を付けるポイント
- レプリケートするが、これは負荷分散のためではない。
- データベースによってはリードオンリーのものを作ってそっちにリクエストを流すものがあったりする。
- ただ、これをしたくてレプリケーションする訳ではない。
- レプリケーションはあくまでアベイラビリティを上げるため。
- スループットが欲しい時にレプリケーションの数を増やしたりはしない。
-
1つのパーティションをレプリケートした複数のストレージノードをまとめて、レプリケーショングループと呼ぶ。
-
ライトのリクエストに対応できるのは、リーダだけ。(他にも色々仕事がある)
-
リーダはライトのリクエストを受け取ると、write-ahead logs を書いて書いた分のログをレプリカに送りつけることで複製する。
-
そして送りつけた先から、ACK が返ってきますがそれがクォーラム(多数決)の判定をすることで、書き込めたよをユーザに返す。
-
あとはログだけではなくて、Bツリーなんかも持っている。
-
ストレージノードがパーティションのために持っているものは、データベースのための Bツリーと write-ahead logs を持っている。
[ストレージノードにおけるストレージレプリカの中身]
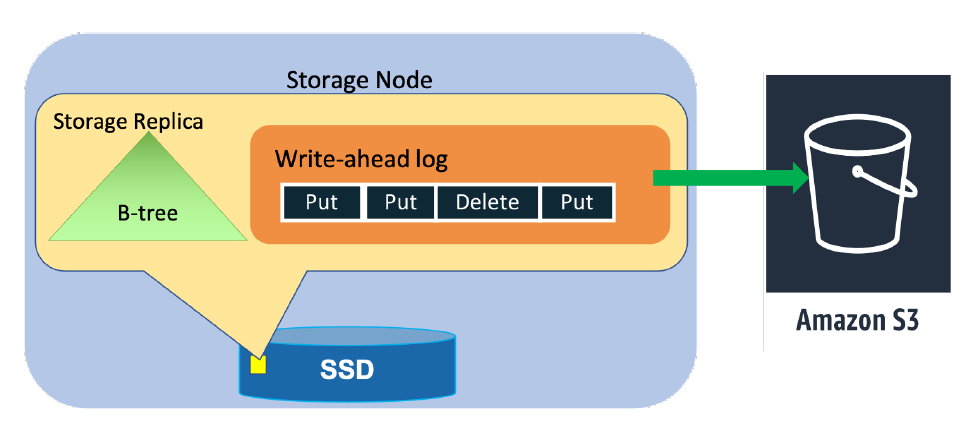
(画像引用基: https://www.usenix.org/conference/atc22/presentation/elhemali)
ログは、定期的にS3にバックアップされ復旧とかに使われる。
ストレージノードの特別な実装がある
- ログレプリカ
- これは、レプリケーションの対象。最近のログだけを持っている。Bツリーは持っていない。
- そのノードはリードとかライトみたいなリクエストは受け取れない。
- ただ、リーダが複製するためにログを送りつけてきたら、受け取ったよーと返す。
ログだけを持っているレプリカがなぜ必要なのか?
- いつもいる訳ではない。
- 実は復旧のため。
- 普通のレプリカが何かしらの理由で故障した時に、代理で登場する。
- 普通のレプリカを作って復旧するでもいいのだが、Bツリーなんかを作り直すのは時間がかかる。それがない。
なのですぐに復旧できる。
[ログノードにおけるログレプリカの中身]
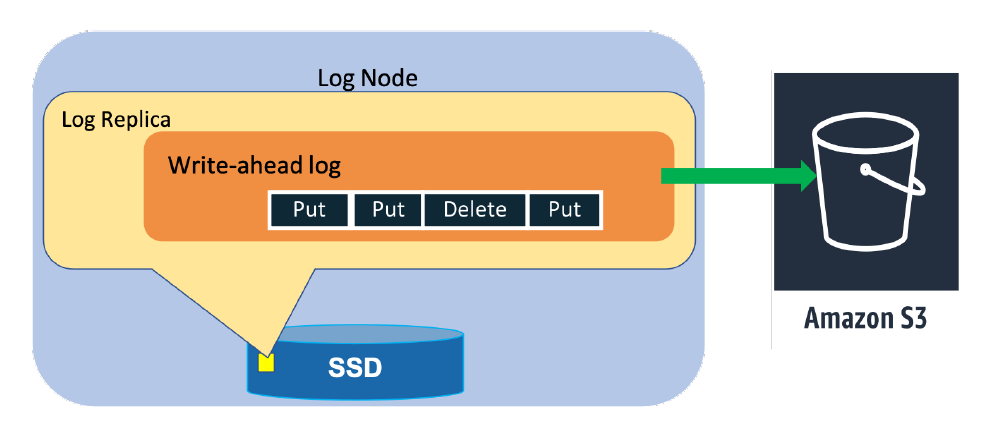
(画像引用基: https://www.usenix.org/conference/atc22/presentation/elhemali)
Initial improvements to admission control
-
どうやってスループットを担保するのか。Predictably レイテンシーを実現するのかについてを語っていく。
-
まず前提として DynamoDB では、テーブルごとにリードキャパシティユニットとかライトキャパシティユニットとか、毎秒これくらいのリクエストを捌けるようにしてほしいというのをユーザが設定している。
-
この設定によって時間単位で課金もされている。
-
なので、スループットだけはプロビジョンしていた感じになる。
-
最近は自動になっている。つまりはスループットはトラックされていてそれによって課金するというモデル。
-
なので各テーブルには期待されるスループットがあるので、DynamoDB はこのスループットを実現するようにテーブルを分割する。
-
最初の頃はこれが素朴だった
- まず、ストレージノートというのはいっぱいパーティションを持っている。
- 個々のパーティションは最大で 1000RCU (毎秒1000 リードまで処理できるとする)とする。
- ユーザがあるテーブルのRCUを3200にした。
- でも個々のパーティションは1000しか持てない。
- さてどうやって分割しよう・・
- この場合は4つに分割し、各 800RCU ごとになる。
-
例えば、そのあとユーザがRCUを3600にしたとしても、900RCUで4つに分割しても大丈夫。
-
それ以上になってくると分割数を増やしていく感じになる。
-
逆に減った時は、多分だがマージとかはしないっぽい。分からない。テーブルを分割した時の挙動も特になし。
-
とにかくパーティション単位でスループットを知ってて、責任を持つというのが重要なポイント
-
なのでストレージノードは個々のパーティションへのリクエストをトラックしていて、クオータみたいなものを計算している。
-
実際に責任を持つスループットを超えたら、スロットルする。
-
3200RCUの例でいうと、個々のパーティションに800RCUのスループットまできてそれを越えようとしたら、800RCUになるようにスロットルする。
-
ただ、これだとアクセスが偏るホットパーティションが生まれる問題を秘めている。
-
パーティションをオーバプロビジョニングしてユーティリゼーションが下がってしまうという問題が発生。
-> これを10年かけて DynamoDB の中の人は改善していく。
Bursting
-
最初に登場した仕組みが Bursting
-
小手先の変更ではあるが、少しの間設定されたWCUよりおっきくなってもいいよということにする。
-
300秒まではスパイクしてもいいことにした。
-
この間は、各パーティションに割り当てられたWCUではなく、パーティションの限界(1000WCU)までは使えるようにした。
-
ただし、ストレージノードの中にあるパーティションが運悪く同じタイミングでバーストするのは困るので、ストレージノード全体の WCU の合計をトラックしていてそっちに余裕がある時のみバーストするそう。
-
なので他のテナントがバーストしているからといって、影響を受けるとかはない。
Adaptive capacity
- 次に導入されたのが Adaptive capacity という仕組み。
- パーティション単位だけではなく、テーブル全体のスループットも見張るようにする。
- 例えば、どこかのパーティションでスロットリングが起きた時に、もしテーブル全体のスループットが余っていたらスロットリングが起きたパーティションのWCUを引き上げるとする。(はみ出すにを許すというより、引き上げるイメージ)
- テーブル全体のスループットが上限に達したら、増やした分は無くしてまた下げられる。
- パーティション単位のスループットを調整する。
- バーストよりもいいところがある。
- プロビジョンで増えたパーティションはオートアドミンの力によってキャパシティに余裕のある別のストレージノードに移動させられることがあるらしい。=> 再配置が起きるらしい。
Global admission control
-
この2つの仕組みよってアクセスパターンによるスロットリングは改善されたそう。
-
ただ、Adaptive capacity も良くないところもある。
-
1つにスロットリングが起きると、調整を入れ始めるので、少しだけスロットリングが起きる。ここが残念。
-
そもそもパーティション単位でスロットルしているのが問題なのでは??となったらしい。
-
スロットリングの操作のことを本論文では、admission controlと言っているが、このadmission controlがパーティション単位なのが悪いという議論がされた。
-
なので、パーティションレベルではなくテーブル全体のスループットを見張ってadmission controlすることになる。=> これが Global admission control
-
これがAdaptive capacityを置き換える。
-
Adaptive capacityはどうするかというと、スロットリングは今までストレージノードがやっていた。
-
それだけではなく、この仕組みをリクエストルータの方に持ってくる。
-
リクエストルータはテーブルへのアクセスをスロットルしたい。
-
テーブルにアクセスするためのトークンをGlobal admission controlサーバに対してトークンくれ!をいう。
-
あのパーティションにアクセスしたいんだというのを聞くらしい。
-
そうするとGlobal admission controlサーバは、テーブル単位のプロビジョンキャパシティをトラックしているので、キャパシティに到達していなければ、はいどうぞという感じでトークンをあげる。
-
トークンを払い出してもらったら、リクエストルータはストレージノードにアクセスする。
-
なので、テーブル単位のスループットをトラックするGlobal admission controlサーバが登場した。
-
ストレージノードも引き続き他人に迷惑をかけないようにスロットリングはしている。
ここまでは、スロットルの上限を上げることで、不当にスロットルさせないような仕組みについて説明してきた。
- ただ、スロットルがストレージノードのキャパシティの上限に達してしまうとスケールしない。
- 全体のパーティションの数を増やすといいが、ただパーティションの数を増やすだけだとホットパーティションのようにアクセスが集中する問題への解決はできていない。
Balancing consumed capacity / Splitting for consumption
-
つまり4個だったパーティションを8個に増やしてもアクセス数が偏っていたらパーティションが無駄に増える可能性も秘めている。
-
なので、ホットなパーティションだけを増やすようにする仕組みとなっている。
-
パーティションの数をただ増やすだけではなく、ホットなパーティションがあればそいつをスプリット(分割)する。
-
どうやって分割するかというとアクセスパターンから推測する。
-
ただ、アクセス数によって分割することへの問題もある。
- 単一のキーにアクセスが集中していると、そいつは分割できないのでどうしようもできない。
- 逆にフルスキャンの時もできない。全部触るので。
-
こういう時は検出して分割しないようにしているらしい。
-
なので、まとめるとデータサイズだけではなくスループットでも分割するのが特徴。
-
どのパーティションをどのストレージノードに置く(コロケーション)のもちょっと工夫がいるらしい。
-
パーティション単位の実際のスループットをモニターし、そうすると自分の持っているパーティションの合計が分かるのでそれが自分のキャパシティの限界に近づいてきたら、オートアドミンサービスに助けを求める。
-
具体的には、このパーティションを他にやってと頼むような動作になるらしい。そうすると、オートアドミンサービスが持っていってくれる。
-
これによってパーティションの空きを動的に作っていくらしい。
On-demand provisioning
- On-demand provisioning: DynamoDBの最初の頃は、WCUとかRCUなどのスループットをユーザが指定していた。でも値決めるの大変。
- 2018年からは自動でいい感じにしてくれるらしい。
(機能的な改善の話はここまで。エモい話がこの後続くが、そちらは後日別の記事で公開します。)
参考文献