概要
モダンなウェブアプリケーションを開発していくにあたり、サービスのパフォーマンスを向上したいと思うケースってよくありますよね。
きっとその際に、インメモリデータストアとキャッシュ技術を利用し高速なパフォーマンスを実現することも解決策の1つになると思います。
Memcached や Redis、AWSを利用していればそれらソフトウェアの互換性のあるフルマネージドサービス Amazon ElastiCacheなどを利用しているんじゃないでしょうか。
今回は、そんなキャッシュ技術について、そもそもキャッシュってなんだっけを改めて振り返る記事となっております。
※本記事は Umer Mansoor さんが執筆されたBrief Overview of Caching and Cache Invalidationの内容を基に翻訳し、加筆、独自解釈したものです。
※ Umer Mansoor さんからは、快く本記事の翻訳、執筆については許可をいただいております。
キャッシュが適用される場所
キャッシュは、さまざまなレイヤーに存在します。あくまで例ではありますが、下記のようなさまざまな技術に採用されており、使用しております。
- プロセッサコア(L1、L2、L3)内にハードウェアキャッシュ
- OS のページ/ディスクキャッシュ
- よく知られる、MemCached、Redis、または DynamoDB の DAX などのデータベースのキャッシュ
- APIキャッシュ
- CDN のエッジレベルでのキャッシュなどのL7階層(アプリケーション層)の HTTP キャッシュ
- DNSキャッシュ
- ブラウザでのキャッシュ
さて、キャッシュとはなんなのでしょうか?
- 一言で言えば、キャッシュは、データのサブセットを一時的に保存するための高速なインメモリデータストレージ層です。
キャッシュの仕組み
-
キャッシュは元のデータソース(例えば、データベースなど)よりも読み取り時に高速であるため、データソースから直接データを取得するのではなく、キャッシュ内のデータにアクセスすることで、それ以降同じデータを読み取った際のデータの取得を高速化します。
-
また、キャッシュにより、データを計算するための複雑な操作やリソースを大量に消費する操作が回避され(例えば、ある読み取りに関してデータベースで複雑なSQLを発行しなければいけない場合など)、データの取得が効率化されます。
Read-Through
- Read-Throughとは、よくあるキャッシュのパターンです。
Read-Throughの動作
- これは、アプリケーションがデータを必要とするとき、まずそれがキャッシュに存在するかどうかを確認します。
- 存在する場合、データはキャッシュから直接読み取られます。
- データがキャッシュにない場合は、プライマリデータストアから読み取られるか、サービスによっては生成されます。
- データが読み取られるとキャッシュに保存されるため、それ以降のリクエストのためにキャッシュからデータを読み取れるようにできます。
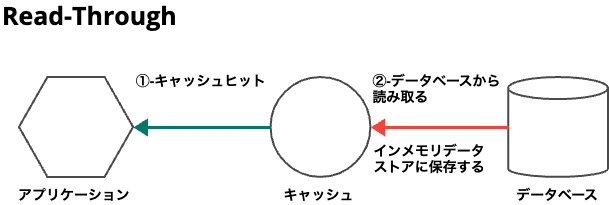
①: キャッシュヒット
キャッシュヒットとは、キャッシュがインメモリデータストア内にある場合、データストアから読み取る動作になります。
②-データベースから読み取る
データベースから読み取る動作とは、キャッシュ内に、データがなく読み取りに失敗した場合に、データベースから読み取り、インメモリデータストアに保存する動作になります。
なぜキャッシュが必要なのか
なぜ、キャッシュが必要なのかの理由は、2つあります。
理由①
- 読み取りたいデータを例えば、複雑なSQLクエリを利用しなければいけない場合に、データを読み取るだけで、多くのリソースを消費してしまいます。
- ただ、一度例えばクエリなどを発行し、そのデータを一定期間だけ保存することができれば、無駄なリソース消費がなくなるというわけです。
理由②
- データの取得を高速にすることです。
- キャッシュは元のデータソースからの読み込みよりも高速であり、キャッシュされた情報を迅速に取得できるため、ユーザーへのレスポンスも早くなるということですね。
キャッシュの例
- ある Webサービスがあり、表示するコンテンツは現在SNSでトレンドになっているものを表示する機能があったとします。
- このコンテンツは、webサービスを構成するプライマリのデータベース内にある大量のデータを処理し、あるアルゴリズムによって計算され、コンテンツが生成されます。
- もちろんこれは複雑な処理で、大量のコンピューターリソースが消費されます。
- なお、上記の処理についてはユーザごとに計算する必要があり、同じデータを何度も計算するのに、時間もコンピュータリソースも大量に消費します。
上記の事象による影響
- バックエンドとバックエンド用のデータベースに対して負荷がかかり、全体としてのインフラコストが増加しています。
- 関連するコンテンツの生成に時間がかかり、ユーザへのレスポンスに遅延が発生しています。
上記の問題に対する解決策はあるのか?
- これらの影響範囲が出たときにキャッシュが利用できます。
- キャッシュを利用することで、一度生成された関連コンテンツを最初に計算された後にキャッシュに保存しておけば、次回以降、データを要求されたときは、コストのかかる処理を毎度毎度行うのではなく、キャッシュからのレスポンスを返すようにすることができます。
ただ、これだけでは終わらない。キャッシュの難しいところ
キャッシュはいい面だけがあるように見えて、トレードオフもあることを忘れてはいけません。
実は、キャッシュで難しいことは、キャッシュを使用したくない時の処理とキャッシュの名前付けにあります。
キャッシュを使用したくない時
- キャッシュを使用したくない時というのは、キャッシュ内のデータを不要としてマークするか、削除する処理のことを指しています。
- リクエストを受け取ったタイミングで、対応するデータを無効としたい場合に、その処理をどうするのか。例えば、対応する無効なデータをキャッシュミスとして処理し、元のデータソース(データベースまたはサービス) から強制的に新たなデータを生成するなどの処理をするという感じです。
それってどんな時??
- 例えば、元のデータソース(信頼できる情報源)内のデータが変更され、無効なデータがキャッシュに残ったときに発生します。
- データのキャッシュが無効化されていない場合、一貫性のない情報、競合する情報、または不正確な情報をユーザに送ってしまう可能性があるということですね。
重要なのはキャッシュ戦略
- なので、こんな課題があった時にキャッシュを構成してアクセスするには、さまざまな方法があります。
- 次回の記事で、このキャッシュの戦略についてお話ししていこうと思います。
引用文献