はじめに
Deep Learningの自己学習としてTensorFlowで画像分類をやってみました。
事前準備として前回の記事では、スクレイピングで学習データとなる画像をダウンロードしていますが、面倒な方は本記事の「フォルダ構成 」を参考に10~20枚ずつ、手動で画像データをダウンロードしておけば問題ないかと思います。
(学習データの数が少ないと良い学習結果が出ないかもしれません。)
興味のある方は是非、以下の記事で画像スクレイピングを実施してみてください。
※ 画像データを手動で保存する場合は対象のファイルがPNG形式(透過)でなくJPEG(拡張子は.jpg)であることに注意してください。PNG形式の画像を指定すると本記事のコードではエラーが発生します。
実行環境
本記事に掲載しているコードはJupyter Notebook(Python3)で実行しました。
- OS:Windows 11
- 言語:Python3
- 機械学習ライブラリ:TensorFlow
フォルダ構成
実行ユーザーのホームディレクトリに任意のフォルダを作成して以下のフォルダ/ファイルを配置しました。
├─download …①
├─image
│ ├─train …②
│ │ ├─0_スズメ
│ │ ├─1_カワセミ
│ │ └─2_ハクチョウ
│ └─test …③
│ ├─0_スズメ
│ ├─1_カワセミ
│ └─2_ハクチョウ
└─image_classification.ipynb …④
① 前回の記事でスクレイピングした画像データを格納したフォルダ。
② 学習データを格納するフォルダ、連番を付与した野鳥毎のサブフォルダを配置。
③ 学習結果を検証するデータを格納するフォルダ、連番を付与した野鳥毎のサブフォルダを配置。
④ 本記事のコードを実行したJupyter Notebookのファイル
準備
・画像データを配置
スクレイピングで「download」フォルダに格納された画像データをimage/trainとimage/testフォルダに移動します。
trainは学習データを格納するフォルダ、testは評価データを格納するフォルダにしています。
画像ファイルを配置する際、trainフォルダに9割程度、testフォルダに1割程度のデータが配置されるようにしました。
※手動で画像をダウンロードする場合はtrainに10枚程度ずつ、testに1枚ずつ画像を配置してください。
あと、明らかに関係なさそうな画像は削除しておいてください。
(「アニメキャラ」とか「ぬいぐるみ」とか、、、、4番目の画像、もしかして!? ヤメてくれ~~![]() )
)

・Anaconda Promptを起動してTensorFlowなど必要ライブラリをインストール
pip3 install numpy
pip3 install tensorflow
pip3 install matplotlib
学習
以下のコードをJupyter Notebookで実行します。
②~⑦は、⑧のコードを分解して説明しているもので、実際の学習には使用していません。
①ライブラリをインポート
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from PIL import Image
import glob
import os
import random
②Tensorflowのバージョンを確認
print(tf.__version__)
<出力>
2.11.0
③まずは適当にどれか一枚、画像を表示してみる
image = Image.open("image/train/1_カワセミ/カワセミ_191.jpg")
plt.imshow(image)
plt.show()
画像ファイルが表示されればOKです。

④リサイズする
Tensorflowには同じサイズで画像データを渡す必要があるためリサイズします。
# リサイズ設定
picture_size = (50, 50)
# 画像をリサイズ
image = image.resize(picture_size)
plt.imshow(image)
plt.show()
アスペクト比が変わると物体の形状が変わるので良くない気もしますが、対処が面倒なので今回はこのままいきます。
⑤学習データを水増しする
右向きの画像ばかり学習すると、左向きの画像に対応しづらいので反転させた画像を学習するようにします。
# 学習データを水増しするために反転画像も生成
image_rev = image.transpose(Image.FLIP_LEFT_RIGHT)
plt.imshow(image_rev)
plt.show()

⑥画像データを数値に変換する
Tensorflowに画像データを数値として渡す必要があるため変換しています。
エラーが出ずに数値の配列が出力されればOKです。
# 画像データを数値に変換
image_data = np.asarray(image)
print(image_data)
<出力>
tf.Tensor(
[[[255 204 210]
[242 189 195]
[234 183 188]
...
[179 197 209]
[184 202 214]
[187 205 217]]
:
上記の出力ではRGBの3要素が0~255の256段階で表現されていて、それがピクセル毎に並んでいるイメージです。
⑦ファイルのパスを取得する
「image」フォルダ配下の画像データのファイルパスを取得してみます。
以下のコードでは、ファイルパスからラベルを生成していますが、ラベルは数値で格納する必要があるためフォルダ名をアンダースコア(_)で文字列分割して前半の数値部分を抜き出しています。
for file in glob.glob("image/*/*/*.jpg"):
# Windows環境ではパス区切り文字の\で問題が出るためスラッシュに変換
file_path = file.replace("\\", "/")
print(file_name)
# サブフォルダの連番からラベルを取得
# 「0_スズメ」フォルダの0の部分をラベルにしています。
label = int(file_name.split("/")[2].split("_")[0])
print("label:" + str(label))
<出力>
image/test/0_スズメ/スズメ_101.jpg
label:0
image/test/0_スズメ/スズメ_134.jpg
label:0
image/test/0_スズメ/スズメ_211.jpg
label:0
image/test/1_カワセミ/カワセミ_51.jpg
label:1
image/test/1_カワセミ/カワセミ_73.jpg
label:1
image/test/1_カワセミ/カワセミ_85.jpg
:
⑧全ファイルを読み込んで変数に格納
上記の画像データの読み込み、加工、数値への変換、ファイルパスの取得が上手くいったら実際に全ファイルを読み込んで学習データを作成します。
以下のコードのx_trainは学習する画像データを格納する変数です。y_trainには画像データのラベルを格納します。
x_testとy_testは検証データを格納する変数です。
# 学習データを検証データを格納する配列
x_train = []
y_train = []
x_test = []
y_test = []
# リサイズ設定
picture_size = (100,100)
# ファイルを全て読み込み
for file in glob.glob("image/*/*/*.jpg"):
# 画像データを読み込み
image = Image.open(file)
# 画像をリサイズ
image = image.resize(picture_size)
# 学習データを水増しするために反転画像も生成
image_rev = image.transpose(Image.FLIP_LEFT_RIGHT)
# 画像データを数値に変換
image_data = np.asarray(image)
image_rev_data = np.asarray(image_rev)
# Windows環境ではパス区切り文字の\で問題が出るためスラッシュに変換
file_path = file.replace("\\", "/")
# trainフォルダの場合は学習データの配列に格納
if file_path.split("/")[1] == "train":
# 反転前のデータ
x_train.append(image_data)
y_train.append(int(file_path.split("/")[2].split("_")[0]))
# 反転後のデータ
x_train.append(image_rev_data)
y_train.append(int(file_path.split("/")[2].split("_")[0]))
# testフォルダの場合は検証データの配列に格納
elif file_path.split("/")[1] == "test":
x_test.append(image_data)
y_test.append(int(file_path.split("/")[2].split("_")[0]))
⑨数値をNumPy形式に変換
Tensorflowには最終的にNumPy形式のデータを渡すために変換が必要になります。
画像データの数値の配列をNumPyの配列に変換しますが、この際にRGBの0~255の数値を0~1の数値に変換します。
x_train = np.array(x_train) / 255.0
y_train = np.array(y_train)
x_test = np.array(x_test) / 255.0
y_test = np.array(y_test)
print(x_train)
print(y_train)
<x_train(画像データ)の出力>
[[[[0.0028143 0.00286044 0.00293733]
[0.00279892 0.00284506 0.00292195]
[0.00278354 0.00282968 0.00290657]
...
[0.00333718 0.00338331 0.00346021]
[0.00333718 0.00338331 0.00346021]
[0.00333718 0.00338331 0.00346021]]
:
<y_train(画像ラベル)の出力>
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2
:
⑩ラベル数をカウント
ニューラルネットの入力層に入った画像データが出力層で何個のラベルに分類されるか定義する必要があります。
以下の様にtrainフォルダ配下に画像が格納されたサブフォルダが配置されているので、サブフォルダの数がラベル数になります。
├─image
│ ├─train …②
│ │ ├─0_スズメ
│ │ ├─1_カワセミ
│ │ └─2_ハクチョウ
以下のコードで画像が格納されたサブディレクトリの数を計算します。
# 保存先のディレクトリ
dl_dir = "image/train/"
# フォルダ数のカウント
dir_count = 0
files = os.listdir(dl_dir)
for f in files:
path = os.path.join(dl_dir, f)
if os.path.isdir(path):
dir_count += 1
print(dir_count)
<出力>
3
⑪モデルを作成
KerasでSequentialモデルを作成します。
keras.models.Sequentialのパラメータで入力層、中間層(隠れ層)、出力層などを定義します。
学習したモデルで評価結果が良くない場合は各層の調整が必要になります。
各層の役割やパラメータについての詳細は以下の情報を参考にしてみてください。
# 画像サイズを高さと幅に分解
height, width = picture_size
# 空のモデルを生成
model = tf.keras.Sequential()
# 入力データのサイズを設定、3はRGBの3色(PNGなら透過情報が付与されるので4?)
model.add(tf.keras.Input(shape=(height, width, 3)))
# 平坦化層:入力データをチャンネルに関係なく全て1次元配列に変換
model.add(tf.keras.layers.Flatten())
# 全結合層:ユニット(パーセプトロン)数や活性化関数を設定
model.add(tf.keras.layers.Dense(256, input_dim=10, activation="relu"))
# ドロップアウト層: 過学習を防止する
model.add(tf.keras.layers.Dropout(rate=0.2))
# 出力のラベル数をセット(今回の構成では学習データを格納したフォルダ数になる)
model.add(tf.keras.layers.Dense(dir_count, activation="softmax"))
# モデルの情報を出力
model.summary()
<出力>
Model: "sequential_67"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_64 (Flatten) (None, 30000) 0
dense_124 (Dense) (None, 256) 7680256
dropout_63 (Dropout) (None, 256) 0
dense_125 (Dense) (None, 3) 771
=================================================================
Total params: 7,681,027
Trainable params: 7,681,027
Non-trainable params: 0
⑫学習してみる
学習する画像データ(x_train)と画像ラベル(y_train)を指定して学習します。
validation_splitで学習データと検証データの割合を設定します。
ややこしいですが、はじめにtrainとtestに分割した際のtestは学習後に推論(評価)するためのデータです。
TensorFlowの中で学習データ(train)が更にtrainとvalidationに分割されます。
# 学習回数
epochs = 100
# モデルを構築
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 学習開始
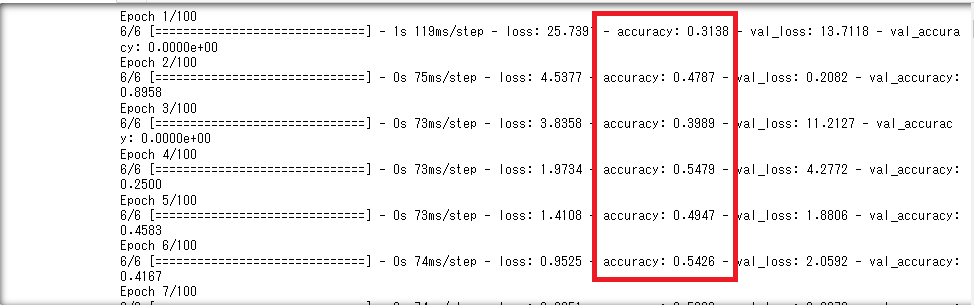
history = model.fit(x_train, y_train, epochs=epochs, validation_split=0.2)
accuracy(正解率)がちゃんと上がっていってる。
⑫試しに一部の学習結果をグラフ化
学習結果を格納した変数historyには、以下の情報が含まれています。
- accuracy ・・・ 学習データでの正解率(値が大きいほど良い)
- loss ・・・ 学習データでの損失値、誤差(値が小さいほど良い)
- val_accuracy ・・・ 検証データでの正解率(値が大きいほど良い)
- val_loss ・・・ 検証データでの損失値、誤差(値が小さいほど良い)
※valの方が重要。valはtestフォルダのデータでの検証ではなく、trainフォルダ内でTensorFlowがvalidation_splitの割合で分割した検証データ。
# 学習結果のaccuracy(正解率)をグラフ化
plt.plot(list(range(1, epochs + 1)), history.history['val_accuracy'])
<出力>
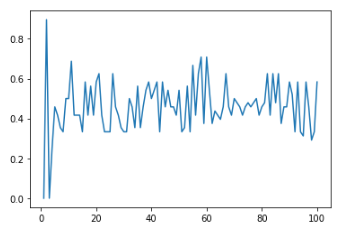
過学習になるとaccuracyが落ちていくので、一回 過学習になるくらいの学習回数を実施してみて、グラフを見ながら適切な学習回数で再実行したほうが良いかもです。
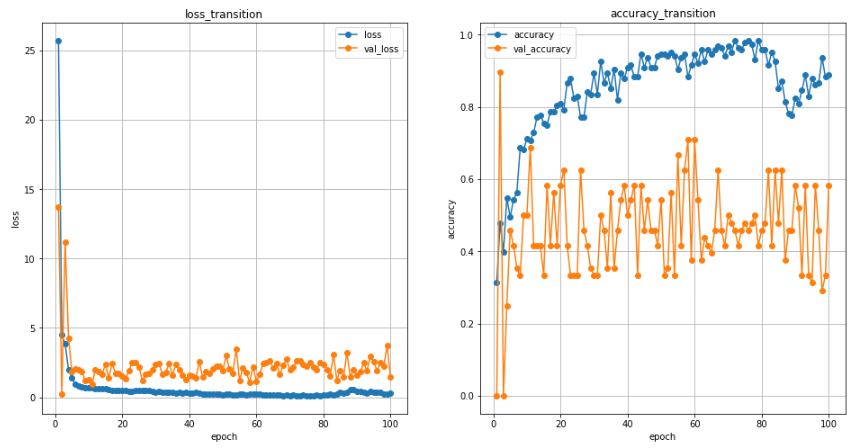
⑫全ての学習結果をグラフ化
# グラフ描画(2画面)
plt.figure(figsize=(16, 8))
# epochごとのlossを表示
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), history.history['loss'], '-o')
plt.plot(range(1, epochs + 1), history.history['val_loss'], '-o')
plt.title('loss_transition')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.grid()
plt.legend(['loss', 'val_loss'], loc='best')
# epochごとのaccuracyを表示
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs+1), history.history['accuracy'], '-o')
plt.plot(range(1, epochs+1), history.history['val_accuracy'], '-o')
plt.title('accuracy_transition')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.grid()
plt.legend(['accuracy', 'val_accuracy'], loc='best')
# グラフ表示
plt.show()
<出力>
推論
学習が完了したので、testフォルダのデータを使って推論(評価)してみます。
test(評価データ)に7枚ずつ画像データを格納していますので、スズメ/カワセミ/ハクチョウの3分類で計21枚の評価データがある状態です。
①損失値と正解率を表示
# loss(損失値)とaccuracy(正解率)を表示
model.evaluate(x_test, y_test)
<出力>
[0.5616952776908875, 0.761904776096344]
正解率が76%なので、分類には成功しているようです。
②評価データ毎の分類結果を確認
model.predict(x_test)
<出力>
array([[3.24959129e-01, 6.71169639e-01, 3.87130119e-03],
[6.37066603e-01, 2.93147445e-01, 6.97859675e-02],
[4.65011686e-01, 5.33596575e-01, 1.39170827e-03],
[7.06916928e-01, 2.80138791e-01, 1.29442709e-02],
[8.10759187e-01, 1.65052637e-01, 2.41881721e-02],
[4.69903022e-01, 1.49753660e-01, 3.80343378e-01],
[6.17901906e-02, 2.83589602e-01, 6.54620171e-01],
[1.61646336e-01, 8.37769628e-01, 5.84030000e-04],
[1.32313594e-01, 8.65706801e-01, 1.97956082e-03],
[1.03502214e-01, 4.71200645e-01, 4.25297171e-01],
[3.99172418e-02, 2.39561632e-01, 7.20521092e-01],
[1.97668061e-01, 7.44912982e-01, 5.74189276e-02],
[1.11428462e-02, 3.45105588e-01, 6.43751562e-01],
[3.16300124e-01, 5.83737612e-01, 9.99622941e-02],
[1.03746820e-02, 4.29824479e-02, 9.46642935e-01],
[9.09287557e-02, 2.29178995e-01, 6.79892182e-01],
[1.16567537e-02, 5.69392182e-02, 9.31403995e-01],
[1.22988282e-03, 3.41582671e-02, 9.64611828e-01],
[1.26148956e-02, 1.02560461e-01, 8.84824634e-01],
[5.78217804e-02, 1.46138296e-01, 7.96039879e-01],
[5.97072719e-03, 5.37272617e-02, 9.40302014e-01]], dtype=float32)
配列の配列で結果が表示されます。
外側の配列(行)が評価データで、画像ファイル21枚分の21行が表示されています。
内側の配列(列)が3種類あるラベルの3要素で、評価データ各ラベルである確率が表示されています。
e-0の様な形式で表示される場合もありますが、6.5e-01は6.5×10のマイナス3乗という意味です。
分かり辛いので以下のコードで推論にて最も可能性が高いと判断されたラベルを表示してみます。
predictions = model.predict(x_test)
for p in predictions:
print(np.argmax(p))
<出力>
1
0
1
0
0
0
2
1
1
1
2
1
2
1
2
2
2
2
2
2
2
正解ラベルは以下の様になっています。
for y in y_test:
print(y)
<出力>
0 # ← 推論では1になっている
0
0 # ← 推論では1になっている
0
0
0
0 # ← 推論では2になっている
1
1
1
1 # ← 推論では2になっている
1
1 # ← 推論では2になっている
1
2
2
2
2
2
2
2
評価結果の方と比較すると、、、
- スズメの画像7枚の内、2枚をカワセミ、1枚をハクチョウだと思っているようです。
- カワセミの画像7枚の内、1枚をハクチョウだと思っているようです。
- ハクチョウの画像は全て正解していました。
もう少し分かりやすく評価結果を表示してみます。
# ラベル(スズメ/カワセミ/ハクチョウ)を格納する配列
labels = []
# testフォルダ配下のサブフォルダを取得
for dir_path in glob.glob("image/test/*"):
# Windows環境ではパス区切り文字の\で問題が出るためスラッシュに変換
dir_path = dir_path.replace("\\", "/")
# ラベルの名前を取得(スズメ/カワセミ/ハクチョウ)
label = dir_path.split("/")[2].split("_")[1]
# 配列に追加
labels.append(label)
# 評価結果を取得
for i in range(len(predictions)):
# 予測したラベル(推論)
test = labels[np.argmax(predictions[i])]
# 正解のラベル
answer = labels[y_test[i]]
# 正解なら○、不正解は✕
if test == answer:
mark = "○"
else:
mark = "✕"
# 結果を表示
print(mark + " 予測:" + test + " / 正解:" + answer )
<出力>
✕ 予測:カワセミ / 正解:スズメ
○ 予測:スズメ / 正解:スズメ
✕ 予測:カワセミ / 正解:スズメ
○ 予測:スズメ / 正解:スズメ
○ 予測:スズメ / 正解:スズメ
○ 予測:スズメ / 正解:スズメ
✕ 予測:ハクチョウ / 正解:スズメ
○ 予測:カワセミ / 正解:カワセミ
○ 予測:カワセミ / 正解:カワセミ
○ 予測:カワセミ / 正解:カワセミ
✕ 予測:ハクチョウ / 正解:カワセミ
○ 予測:カワセミ / 正解:カワセミ
✕ 予測:ハクチョウ / 正解:カワセミ
○ 予測:カワセミ / 正解:カワセミ
○ 予測:ハクチョウ / 正解:ハクチョウ
○ 予測:ハクチョウ / 正解:ハクチョウ
○ 予測:ハクチョウ / 正解:ハクチョウ
○ 予測:ハクチョウ / 正解:ハクチョウ
○ 予測:ハクチョウ / 正解:ハクチョウ
○ 予測:ハクチョウ / 正解:ハクチョウ
○ 予測:ハクチョウ / 正解:ハクチョウ
以下は不正解になっているカワセミの画像です。

横長の画像なのでリサイズ時に形状が変わっていることが原因だと思います。
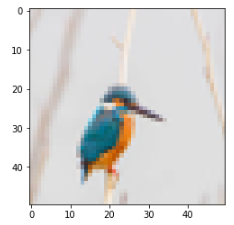
本当は余白を入れて正方形にしたり、正方形で必要な部分を切り抜いたほうが良いのかと思います。
それ以外にも、群れ(複数匹)になっている画像や背景が目立っている画像など除外するともっと良い結果になるかと思います。