プログラミング初心者がChatGPTを使って競馬予想AIを作ることで、生成AIとプログラミングについて学んでいく企画の第15回です。
これまでレース結果テーブルと馬の過去成績テーブルを用いて特徴量を作成し、予測を行ってきましたが、的中率がほぼ0% と思うようなモデルを作れませんでした。
課題はいくつも思い浮かぶのですが、とりあえず元データが半年ほどのデータでは話にならないだろうということでデータの拡充を行います。
データを取り直すにあたりコードも書き直した箇所があるため、今回はそれらについて言及していきます。
1. Classの導入
Pythonなどのオブジェクト指向の言語ではClassという概念があります。
自分のコードを可読性・保守性の高いものにするだけではなく、moduleを扱う上でも必須の概念になります。
プログラミング初心者である自分はこのClassを知らなかったのですが、さすがにプログラミングをやる上では避けられません。
そこで今回以下の3つのクラスを導入するとともに、クラスについて簡単に学びました。
PathReaderクラス
一つ目はJSONファイルからファイルパスを読み込むクラスです。
# ---------------------
# Path Reader Module
# This module reads file paths from a JSON configuration file.
# ---------------------
import json
from pathlib import Path
class PathReader:
def __init__(self, config_file: str):
self.config_file = Path(config_file)
with open(self.config_file, "r", encoding="utf-8") as f:
self.paths = json.load(f)
def get_path(self, key: str) -> str:
return self.paths.get(key, None)
- __init__メソッド
- JSONファイルを開いて辞書形式でself.pathsに格納
- get_pathメソッド
- キーを指定してパスを取得
フォルダ構造を変えると各所に散らばったパスを変える必要があり、それが面倒であったのと、自分はDesktopとNotePCの環境で作業をしているのですが、環境が変わるたびにフォルダパスの変更が発生したためこのクラスを導入しました。
GetHTMLクラス
二つ目はnetkeiba.comからHTMLを取得して保存するクラスです。
# ---------------------
# Get HTML Module
# This module gets html code from netkeiba.com.
# ---------------------
import os
import time
import random
import requests
from module.random_agent import RandomUserAgent
class GetHTML:
def __init__(self, timeout: int = 10, min_sleep: float = 0.8, max_sleep: float = 2.0, ua: RandomUserAgent = RandomUserAgent()):
self.timeout = timeout
self.min_sleep = min_sleep
self.max_sleep = max_sleep
self.ua = RandomUserAgent()
def get_and_save(self, url: str, save_path: str):
"""
指定URLからHTMLを取得し、指定パスに保存する
url: 取得先URL
save_path: 保存先ファイルパス(.bin形式)
"""
if os.path.exists(save_path):
print(f"[Skip] Existing bin file: {save_path}")
return # 既にそのURLが取得済みならスキップ
else:
try:
res = requests.get(url, headers={"User-Agent": self.ua.get_user_agent()}, timeout=self.timeout)
res.raise_for_status() # エラーがあれば例外を発生
# HTMLをバイナリで保存
with open(save_path, "wb") as f:
f.write(res.content)
# アクセス間隔を少し空ける(サーバー負荷対策)
time.sleep(random.uniform(self.min_sleep, self.max_sleep))
except Exception as e:
print(f"[ERROR] Failed to fetch {url}: {e}")
- __init__メソッド
- 各変数設定
- get_and_saveメソッド
- HTMLの取得と保存
- 既にファイルが存在すればスキップ
- バイナリ形式(.bin)で保存
- エラー時は例外をキャッチして表示
レース結果や馬の過去成績、加えて今後血統テーブルなど様々なWebページをスクレイピングするときに必要なクラスです。
実はこの中にUserAgentをランダムで使用するためのクラスも含まれています。
User-Agent
こちらがUserAgentをランダムに出力するクラスです。
スクレイピングを行う際、同じUserAgentを使い続けBotと判断されないように使用します。
# ---------------------
# User Agent Module
# This module generates user agent randomly.
# ---------------------
import random
class RandomUserAgent:
def __init__(self):
# 利用可能なUserAgent一覧
self.user_agents = [
# Windows Chrome 系
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:122.0) Gecko/20100101 Firefox/122.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/121.0.2277.83 Safari/537.36",
# macOS Chrome 系
"Mozilla/5.0 (Macintosh; Intel Mac OS X 13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
]
# インスタンス化時点でランダムに選択
self.user_agent = random.choice(self.user_agents)
def get_user_agent(self) -> str:
"""選ばれたUserAgentを返す"""
return self.user_agent
実は同じ役割のモジュールが存在するのですが、何かがうまくいかず(記憶喪失)5つに厳選したこちらのクラスを用意しました。
2. データの拡充
テーブルの型やその他細かいところを修正し、データを一年分くらい増やしてみました。(合計データ数は64,000件!)
その結果1000レース近い評価データの中で、なんと当てられたのはたったの2件…
Actual values:
actual
0.0 11944
1.0 922
Name: count, dtype: int64
Predicted values:
predicted
0 12864
1 2
Name: count, dtype: int64
どうしようもないくらいまだ少ないですが、ここで落ち着いて現在の予測条件を確認してみましょう。
こちらが学習時の流れです。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {
'objective': 'binary', # 2クラス分類
'metric': 'binary_logloss', # ロス関数
'boosting_type': 'gbdt', # 勾配ブースティング
'learning_rate': 0.1, # 学習率(小さいほど慎重に学習、ただし学習時間は長くなる)
'num_leaves': 31, # 木の葉の数(複雑なモデルほど大きく)
'verbose': -1, # 全てのログの出力を非表示
'early_stopping_round': 30, # 30回連続で改善しなければ終了
'num_boost_round': 300 # 最大100本の木を作成
}
ml_model = lgb.train(params, lgb_train, valid_sets=[lgb_train, lgb_eval], valid_names=['train', 'eval'])
y_pred_prob = ml_model.predict(X_test, num_iteration=ml_model.best_iteration)
y_pred = (y_pred_prob >= 0.5).astype(int) # 確率を0.5で閾値判定
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
results = X_test.copy() # 学習データ
results["actual"] = y_test # 実際の予測対象
results["predicted"] = y_pred # 予測結果
results["predicted_prob"] = y_pred_prob # 予測確率
色々気になるところはあるかと思いますが、自分が手をつけたのは予測結果を決めるしきい値です。
確率の半分0.5をしきい値としていますが、これを超える確率がほぼ得られていないのが現状です。
3. しきい値の検討
ではどのくらいの確率なら良いのでしょうか?
予測確率の分布をみてみましょう。
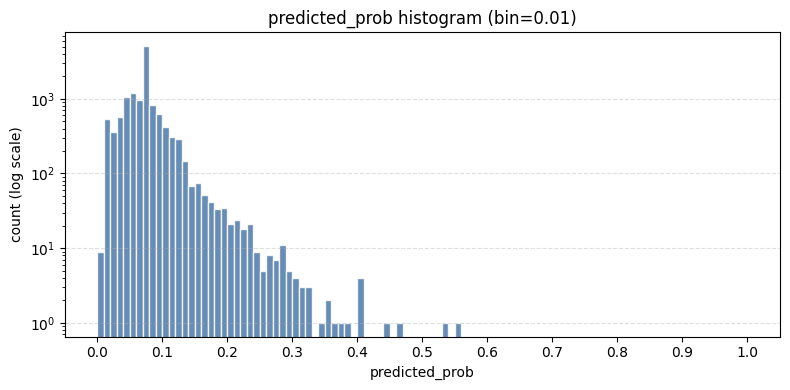
0.5以上ではほぼ確率が分布していないことがわかります。
LightGBMにとっても0.5以上はかなり確度の高い予想なのでしょう。
したがってある程度リスクを受け入れ、0.05~0.30の範囲で検討していきましょう。
ここからは力技です。
目星を使た範囲で結果をゴリゴリ確認していきます。
こちらが各しきい値での1着予想と、その予想があっている確率(Hitting rate)です。
| Threshold | 0.01 | 0.05 | 0.10 | 0.20 | 0.30 |
|---|---|---|---|---|---|
| count_is_1 | 12857 | 2541 | 1626 | 153 | 24 |
| Hitting rate | 1.00 | 0.91 | 0.25 | 0.03 | 0.01 |
しきい値が低いほど、当然1着予想が多くなり、購入数も多いためHitting rateも高くなります。
数打てば当たるの究極系です。
この結果は「しきい値を下げて購入数を増やせば当たりやすくなる」という当然の結果を示しており、闇雲に的中率を高めていっても外している馬券も多すぎて損をする結末になりかねません。
的中率だけのモデルでは痛い目を見るということがよくわかったため、次回はオッズを用いた回収率ベースのシミュレーションを行っていきましょう。