プログラミング初心者がChatGPTを使って競馬予想AIを作ることで、生成AIとプログラミングについて学んでいく企画の第4回です。
前回の記事はこちらから
前回は1ヶ月のレース日程が表示されているページから、全てのrace_idを取得するコードを書きました。
今回は1ヶ月だけではなく、任意の期間でスクレイピングできるように拡張し、さらにrace_idからレース結果を取得しましょう。
今後はそのレース結果から特徴量を抽出し、AIモデルでの予測を行っていきます。
今回からプロンプトと生成AIの出力は載せないことにしました。
プロンプトに凝らないでもそこそこ良い回答を返すようになったので、プロンプトノウハウを残す必要性もないかなと。
任意の期間でのrace_idの取得と保存
まずは期間を定義するだけの関数を作りましょう。
開始年月と終了年月を入力したら、その間の期間をリストで返してくれるという機能を持っています。
# what: 任意の期間(20xx/xx~20yy/yy)を入力するとその期間の年月をリストで返してくれる関数
# for: スクレイピング期間を求めるため
def month_list(from_year: int, from_month: int, to_year: int, to_month: int):
result = []
year, month = from_year, from_month
while (year < to_year) or (year == to_year and month <= to_month):
result.append([year, month])
# 月を1つ進める
month += 1
if month > 12:
month = 1
year += 1
return result
開始日を2023/12、終了日を2024/2と入力すると想定通り以下の出力を返してくれます。
[[2023, 12], [2024, 1], [2024, 2]]
この関数と前回の記事で作成した「任意の期間全てのレースのレースIDを取得する関数」を使用して、レースIDの一括取得を行います。
さらに取得したレースIDはcsvに保存しておきましょう。
# 変数定義
from_year = 2023
from_month = 10
to_year = 2023
to_month = 10
race_id_list_path = r"C:\Users\yasak\Desktop\mykeibaAI_ver1p0\race_id_list.csv"
# スクレイピング期間
scraping_dates = month_list(from_year, from_month, to_year, to_month)
# 任意の期間の全てのレースのレースIDを取得
for scraping_date in scraping_dates:
scrape_race_id_list = get_monthly_race_ids(scraping_date[0], scraping_date[1], sleep=0.8)
print("取得件数:", len(scrape_race_id_list))
# print(df)
if os.path.exists(race_id_list_path):
race_id_list_old = pd.read_csv(race_id_list_path) # 既存データを読み込み
race_id_list = pd.concat([race_id_list_old, scrape_race_id_list]) # データの結合
race_id_list = race_id_list.drop_duplicates(subset=["race_id", "date"], keep="first")
else:
race_id_list = scrape_race_id_list
if "date" in race_id_list.columns:
race_id_list["date"] = race_id_list["date"].astype(int)
race_id_list = race_id_list.sort_values(by="date", ascending=True)
race_id_list["date"] = race_id_list["date"].astype(str)
race_id_list.to_csv(race_id_list_path, index=False, encoding="utf-8")
さらにどの期間をスクレイピングしたか一目でわかるように、csvのファイル名を変更します。
def csv_name_update():
# 探したい部分文字列(例: "keiba")
partial_name = "race_id_list"
# カレントディレクトリ(または任意のパス)
folder_path = r"C:\Users\yasak\Desktop\mykeibaAI_ver1p0"
# 部分一致するCSVファイルを探す
matched_files = [
f for f in os.listdir(folder_path)
if f.endswith(".csv") and partial_name in f
]
# 最初に見つかったファイルを original_filename に代入
if matched_files:
original_filename = matched_files[0]
print(f"見つかったファイル: {original_filename}")
else:
print("一致するCSVファイルが見つかりませんでした。")
# 新しいファイル名を構築するための値を抽出
with open(original_filename, newline='', encoding='utf-8') as f:
reader = list(csv.reader(f))
# 2行目1列目の値(インデックスは1, 0)
second_row_value = reader[1][0]
part1 = second_row_value[2:6] # 3文字目〜6文字目(0-indexed)
# 最終行1列目の値
last_row_value = reader[-1][0]
part2 = last_row_value[2:6]
# 新しいファイル名の構築
base_name, ext = os.path.splitext(original_filename)
new_filename = f"{base_name}_{part1}_{part2}{ext}"
# ファイル名の変更
os.rename(original_filename, new_filename)
print(f"ファイル名を変更しました: {new_filename}")
こちらがスクレイピングした結果です!
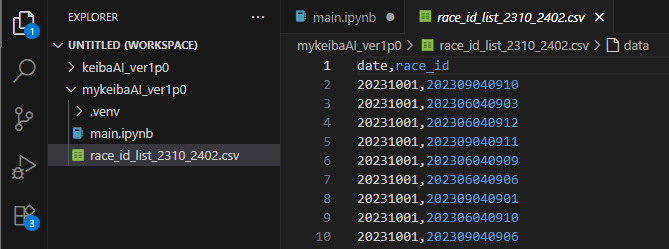
期間は半年にも満たないですが、いくらでも拡張可能なのは嬉しい。
長くなってしまったので今回はここまでにします。
次こそは取得したレースIDでレース結果をスクレイピングしていきます!