プログラミング初心者がChatGPTを使って競馬予想AIを作ることで、生成AIとプログラミングについて学んでいく企画の第13回です。
↓前回の記事はこちら
前回の記事では、オッズを特徴量として含めた馬の過去成績テーブルを修正、さらにレース結果テーブルとのマージを行いました。
今回は馬の過去成績やレース情報を含んだ新たなテーブルで学習・予測を行い、予測精度がどれくらい変わるか見てみます。
マージしたテーブルを用いたモデルの学習
それでは前回作成したNewテーブルを用いて、学習と予測を行っていきます。
まずはテーブルの中から今回使用する特徴量を指定します。
feature = [
'weight_carried',
'popularity',
'odds',
'last3f',
'body_weight',
'sex',
'age',
'time_sec',
'body_diff',
'weather',
'course_condition',
'course_state',
'distance_length',
'log_odds',
'log_odds_avg_3',
'log_odds_avg_5',
'log_odds_avg_10',
'odds_zscore_in_race',
]
X = model[feature]
y = model['is_win']
これで特徴量は少し盛って20個!だいぶ増えましたね。
こうしてできたデータセットを学習データと評価データに分割します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
LightGBMのパラメータをセットして、モデルの性能を評価します。
params = {
'objective': 'binary', # 2クラス分類
'metric': 'binary_logloss', # ロス関数
'boosting_type': 'gbdt', # 勾配ブースティング
'learning_rate': 0.1, # 学習率(小さいほど慎重に学習、ただし学習時間は長くなる)
'num_leaves': 31, # 木の葉の数(複雑なモデルほど大きく)
'verbose': -1, # 全てのログの出力を非表示
'early_stopping_round': 30, # 30回連続で改善しなければ終了
'num_boost_round': 300 # 最大100本の木を作成
}
ml_model = lgb.train(params, lgb_train, valid_sets=[lgb_train, lgb_eval], valid_names=['train', 'eval'])
y_pred_prob = ml_model.predict(X_test, num_iteration=ml_model.best_iteration)
y_pred = (y_pred_prob >= 0.5).astype(int) # 確率を0.5で閾値判定
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
results = X_test.copy() # 学習データ
results["actual"] = y_test # 実際の予測対象
results["predicted"] = y_pred # 予測結果
results["predicted_prob"] = y_pred_prob # 予測確率
# results.head(10)
Accuracy: 92.90%
実行結果を見ると90%以上の正答率を出していますが、これはもともと目的変数の90%以上が0に偏っているため発生する現象です。
実際に1着の馬が何頭いて、そのうち何頭を当てられているかを確認すると
print(f"Actual values:\n{results['actual'].value_counts()}")
print(f"Predicted values:\n{results['predicted'].value_counts()}")
Actual values:
actual
0 5283
1 419
Name: count, dtype: int64
Predicted values:
predicted
0 5634
1 68
Name: count, dtype: int64
419頭中68頭の馬を当てていることがわかります。
的中率に換算すると16%!
特徴量の追加前は5.5% だったので、3倍の精度向上です。
(的中率16%も聞いたことないくらい低いですが…)
とりあえず特徴量を増やすことで精度が確認できました。
ここで使われているオッズは投票を締め切った後の確定オッズになります。
実際に使う際には、JRAのサイトなどからリアルタイムでオッズを取得することになります。
その場合、確定オッズとは大幅に異なり今回の評価のような精度は出ないこと考えられます。
(機械投票勢が締め切り直前に買い占めを行うため)
SHAPによる特徴量の影響度合いの確認
特徴量が増えたため、それぞれがどのくらい予測に影響したかを確認するためのSHAP(SHapley Additive exPlanations) という指標を用いて評価します。
この指標は特徴量の影響度合いを可視化 するために使われ、SHAP値が正なら予測に対してプラスに影響し、反対に負なら予測に対してマイナスの影響を与えたことを示します。
SHAP summary plotを表示して各特徴量のSHAP値を確認してみましょう。
import shap
import matplotlib.pyplot as plt
explainer = shap.TreeExplainer(ml_model)
shap_values = explainer.shap_values(X_test)
shap.summary_plot(shap_values, X_test)
得られた画像を確認すると横軸にSHAP値、縦軸にモデルに使用した特徴量が並んでいることがわかります。
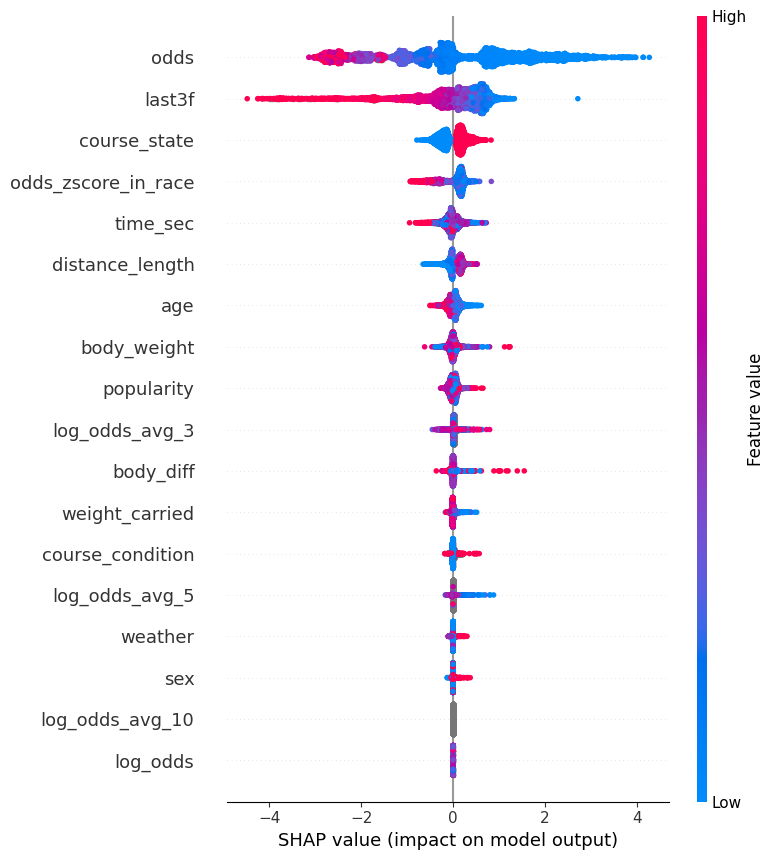
色は特徴量の具体的な値を表しており、"odds"や"time_sec"はグラデーションが見えることがわかりますが、"course_state"や"weather", "sex"は0,1,2, ...などの限られた整数値しかとらないためグラデーションはなくはっきりしていますね。
また縦軸はSHAP値のばらつきが大きい順に並べてくれています。
最上段の"odds"は値が低い(青)ほど予測精度を上げていて、値が高い(赤)だと予測の精度を悪くしています。
人気馬(オッズが1~10)を予測するモデルなので、オッズが高い馬(10~100)が入ってくるとノイズになりうるわけですね。
LightGBMはラベルが大きいほど良いと解釈するため、モデルの解釈性と入力している特徴量の愛称量がよくないような気がします。
一方でオッズを対数化した"log_odds_avg_3"は特徴量の値が高くても低くても予測にプラスに影響していることがわかります。
これは特徴量を加工したおかげといえるでしょう。
他に平均を取るときの母数を10まで増やした"log_odds_avg_10"はほとんどSHAP値が0、予測に影響しないことがわかりますね。
おそらくデータを抽出する期間が短すぎて、10試合平均など取れない(半年で10試合も出ている馬などいない)のでしょう。
このように特徴量がうまく使えていないこともわかります。
この画像一枚でわかることは無限にありそうですが、まだまだデータも特徴量も足りないため、それらを増やしてから再度SHAPを使って考察しましょう。
今後のロードマップ
最後に今一度、この先の開発ロードマップをまとめます。
- 特徴量の追加
- 馬の過去成績テーブルから抽出しきれていない特徴量を追加(タイムなど)
- 血統・騎手テーブルの作成
- 馬の血統データや騎手データをスクレイピング
- 加工して一つのテーブルにマージする
- 調教師や厩舎の情報も余力があれば…
- 予測モデルの最適化
- パラメータの最適化
- そもそもLightGBMの2値分類で良いのか?
- ランキング学習や複勝予測も試す
- 回収率計算
- レース結果と同じページにある配当結果テーブルを元に回収率を計算
- 回収率の最適化
- ケリー基準の適用
- レース直前オッズの取得
- JRAの公式サイトから投票締め切り直前のオッズを取得
- この値を使って予測を実行
- 予測と投票の自動化
- レース前日までに学習を済ませる
- 投票締め切りまでに予測、投票まで終わらせる
ここまで行けば、一通り競馬予想AIができたといえるでしょう。
それにしても先が長いですが、引き続きコツコツ進めていきます。
それでは次回は、さらに特徴量を追加して的中率を上げていきます🎯。