プログラミング初心者がChatGPTを使って競馬予想AIを作ることで、生成AIとプログラミングについて学んでいく企画の第11回です。
↓前回の記事はこちら
前回の記事では、馬の過去成績のテーブルから作れる有効な特徴量について調査しました。
今回はこれらの特徴量を作っていき、レース結果テーブルとマージし1つの大きなテーブルにしていきましょう。
作成する特徴量
馬の過去成績テーブルに保存されている情報は以下の通りです。
Index(['horse_id', 'race_date', 'weather', 'race_no', 'race_id',
'num_of_horses', 'frame_no', 'horse_no', 'odds', 'popularity',
'finish_position', 'jockey_id', 'weight', 'course_condition', 'time',
'margin', 'final_3f', 'prize_money', 'course_state', 'distance_length',
'passing_1st', 'passing_2nd', 'passing_3rd', 'passing_4th', 'pace_1st',
'pace_2nd', 'body_weight', 'body_diff'],
dtype='object')
Number of items: 28
計28個のアイテムが格納されていますが、各種IDやレース情報を抜くと学習に使えるのは
- オッズ(odds)
- 人気(popularity)
- 最終順位(finish_position)
- 斤量(weight)
- タイム(time)
- 着差(margin)
- 上り(final_3f)
- 賞金(prize_money)
- 通過順位1(passing_1st)
- 通過順位2(passing_2st)
- 通過順位3(passing_3st)
- 通過順位4(passing_4st)
- ペース1(pace_1st)
- ペース2(pace_2nd)
- 馬体重(body_weight)
- 差分(body_diff)
の計16個の特徴量です。
想定よりも多いですが、前回の記事を元にそれぞれどういった集約の仕方にするか考えていきましょう。
枠番・馬番の情報はいったん特徴量から外しています。
しかしコース状態や馬の脚質と関連する特徴量ですので、いつかは入れましょう。
オッズ(odds)の特徴量化
今回1つの特徴量に対し、3つの集約方法をChatGPTに選出してもらい、それらを試しました。
集約方法ごとに3, 5, 10レースの平均をとっているため、1つの特徴量につき3×3で9個、入力データの列が増えることになります。
これだけ増やすのも初心者にとっては一苦労なので、今回はまずオッズの特徴量化について検討していきます。
log_odds(対数オッズ)
オッズは1~100倍以上になり、人気が極端に薄い場合はそのままだと100倍近く差がつくことになります。
したがって対数で丸め込んで使うと、LightGBMとの相性が良くなります。
今回はオッズを丸め込んだ後、nレース分の平均をとることにします。
# 元のDataFrameをいじらないようにコピーする
df_horse_cp = df_horse.copy()
# 直近nレースから集約できるように並び替えておく
df_horse_cp = df_horse_cp.sort_values(by=["horse_id", "race_date"], ascending=[True, False])
# オッズがstr型だったため数値に変更
df_horse_cp["odds"] = pd.to_numeric(df_horse_cp["odds"], errors="coerce")
# 対数化
df_horse_cp['log_odds'] = np.log(df_horse_cp['odds'])
# 各馬の3, 5, 10試合の平均をとる
df_horse_cp_log_3 = df_horse_cp.groupby("horse_id").head(3).groupby("horse_id")["log_odds"].mean().rename("log_odd_avg_3")
df_horse_cp_log_5 = df_horse_cp.groupby("horse_id").head(5).groupby("horse_id")["log_odds"].mean().rename("log_odd_avg_5")
df_horse_cp_log_10 = df_horse_cp.groupby("horse_id").head(10).groupby("horse_id")["log_odds"].mean().rename("log_odd_avg_10")
対数化したオッズの平均を、新たなFeatureテーブルに結合して後ほどrace_resultテーブルとマージすることにします。
# 新しいテーブルに結合(このテーブルを後ほどrace_resultテーブルに結合する)
df_horse_feature = pd.concat([df_horse_cp_log_3, df_horse_cp_log_5, df_horse_cp_log_10], axis=1)
df_horse_feature
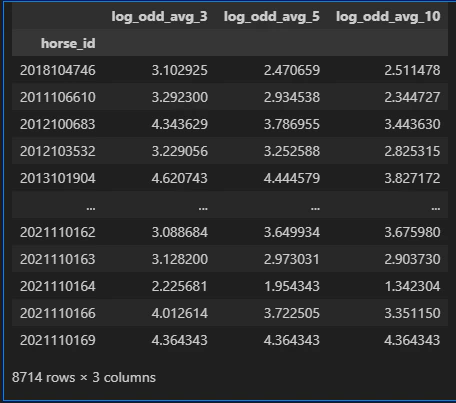
レース数が少ない馬のnレース平均がうまく取れていない気がしますが…
一旦このまま突っ走ります。
odds_zscore_in_race(レース内Zスコア)
このレースの中で相対的にどれくらい高いor低いかを示すことは、回収率を上げる上で重要です。
オッズの平均との差分をレース規模(頭数・人気分布)で正規化することで、相対スコア(z-score)がわかります。
z = \frac{odds - \mathrm{mean}(odds)}{\mathrm{std}(odds)}
# z-scoreの計算
df_horse_cp['odds_zscore_in_race'] = (
df_horse_cp.groupby('race_id')['odds']
.transform(lambda x: (x - x.mean()) / (x.std(ddof=0) + 1e-9))
)
# 追加された"odds_zscore_in_race"を元に平均値を計算
df_horse_cp_zscore_3 = df_horse_cp.groupby("horse_id").head(3).groupby("horse_id")["odds_zscore_in_race"].mean().rename("log_odd_avg_3")
df_horse_cp_zscore_5 = df_horse_cp.groupby("horse_id").head(5).groupby("horse_id")["odds_zscore_in_race"].mean().rename("log_odd_avg_5")
df_horse_cp_zscore_10 = df_horse_cp.groupby("horse_id").head(10).groupby("horse_id")["odds_zscore_in_race"].mean().rename("log_odd_avg_10")
# 馬の特徴量テーブルに追加
df_horse_feature = pd.concat([df_horse_feature, df_horse_cp_zscore_3, df_horse_cp_zscore_5, df_horse_cp_zscore_10], axis=1)
df_horse_feature
ここでddof=0は母分散、分母に1e-9を足しているのは全馬オッズが同一になり、ゼロ割になるのを回避するためです。
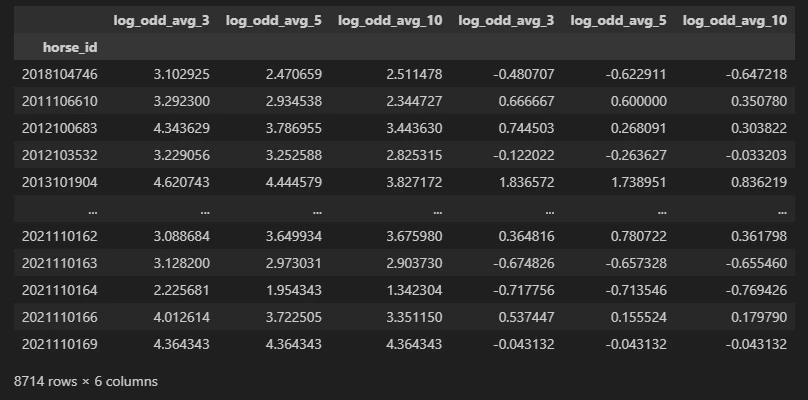
順調に特徴量が追加されていますね。
このオッズは対数化しなくてよいのか、そもそも平均しかとっていないが大丈夫なのかといった疑問も浮かびますが、一旦次に進めます。
odds_rank_gap(オッズ順位と人気順位の乖離)
オッズ順位と人気順位の乖離を見つけることで、市場の期待と実際の売れ方の不整合を見つけることができます。
各レース内のオッズ順位と人気順位の差分を計算し、人気とオッズが連動していない馬を見つけましょう。
# レース内オッズ順位(1が最も低オッズ=1番人気)
df['odds_rank'] = (
df.groupby('race_id')['odds']
.rank(method='min', ascending=True)
)
# "popularity"がstr型だったためint型に変更
df_horse_cp["popularity"] = pd.to_numeric(df_horse_cp["popularity"], errors="coerce")
# float型になっていることを確認
df_horse_cp["popularity"].apply(type).value_counts()
df['odds_rank_gap'] = df['odds_rank'] - df['popularity']
テーブルを確認すると最後列に"odds_rank_gap"が追加されており、一つだけ-2.0になっており差分が確認できますね。
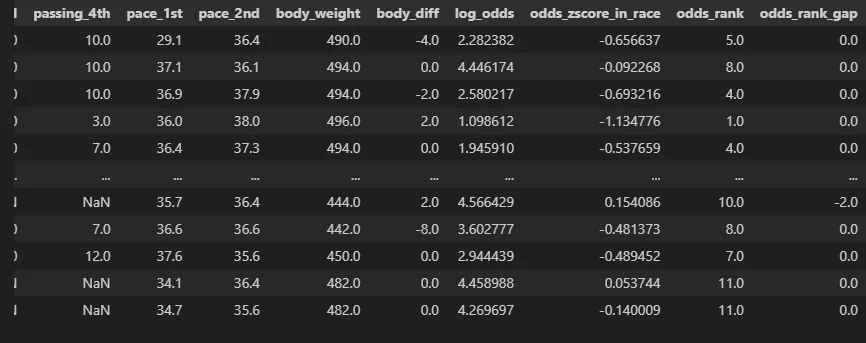
しかし一つだけではどうにもわからないため、どの値がどのくらい発生しているか数えてみましょう。
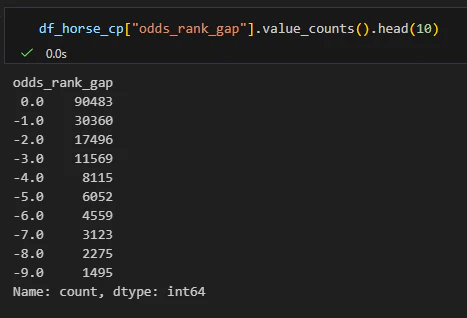
差分0が最も出現頻度が高く、その他は徐々に少なくなっていますね。
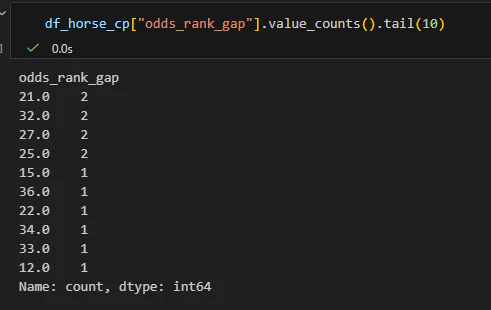
上位だけ見ていますが、念のため下位10個も見てみましょう。
出馬頭数はおよそ最大18頭なので、差も±18くらいになっているはず…
???
差分が36とか出ています。
絶対にこれはおかしいと思いデータを確認します。
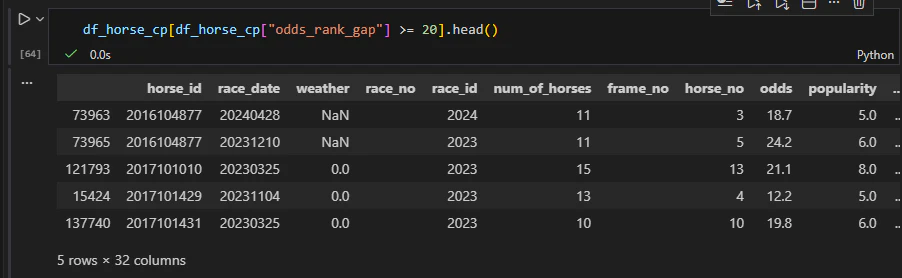
出力結果テーブル右側
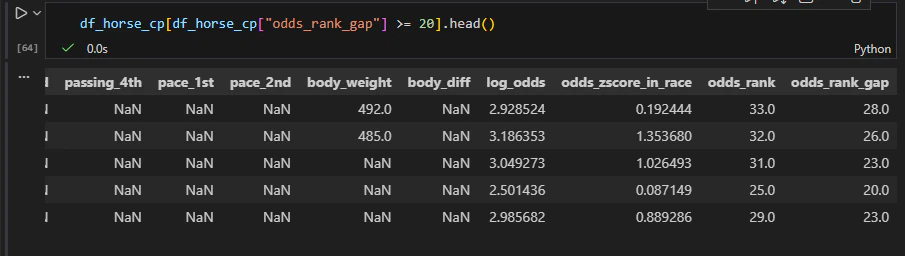
出力結果テーブル左側
1枚目最右列のpopularityは問題ないのですが、2枚目右から2列目のodds_rankがおかしなことになっています。
horse_idをURLに打ち込み、問題が起きている馬の過去成績ページを見に行くと、当該race_dateのレースでの問題がわかりました。
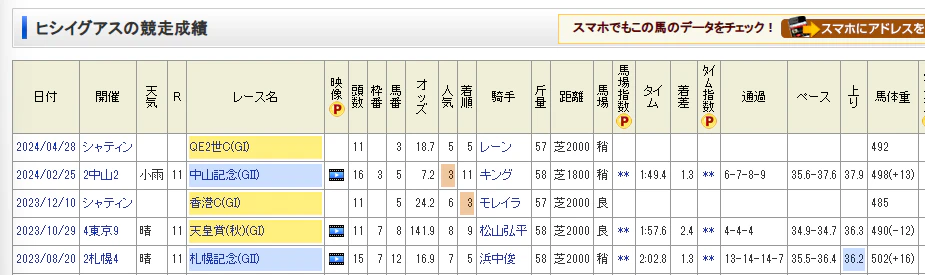
問題が起きているのは一番上のレースで、どうやら海外のレースのようです。
このレースをクリックするとrace_idに"H"という文字が入っていることに気づきます。
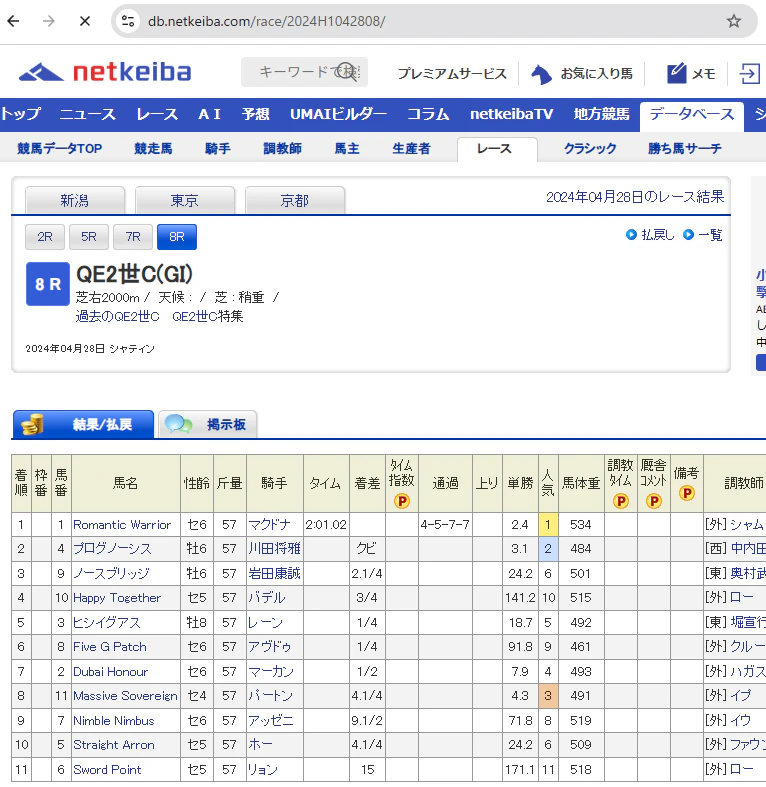
さらに先ほどの問題が起きているテーブルを確認するとrace_id列が"2024"で止まっていることがわかります…
horse_resultテーブルを作るときに、文字を正しくスクレイピングできていなかったようです。
したがって、こうした文字が入っているレース(海外のレース?)は年しか抽出できておらず、全ての結果がまとまってしまったようです。
ここで考えるのは
- スクレイピングのコードを修正
- 海外のレースはいっそデータから除外
のどちらにするかです。
データ量を減らすなどありえない、迷うことなくコード修正に取り掛かるべきなのでしょうが、これも一旦後回しにします。
100%の完璧を作るより、60%の動くものをさっさと作れとどこかで聞いたことがあります。
これを免罪符にして今回は先に進みましょう。
ちなみに正しくrace_idを抽出できていないデータは178,965データ中289でした(0.16%)。
逸脱データの除外は発想を転換して正しいデータ(race_idが12桁有る)のみ残すことにします。
df_horse_cp = df_horse_cp[df_horse_cp["race_id"].astype(str).str.fullmatch(r"\d{12}")]
df_horse_cp["race_id"].astype(str).str.len().value_counts()
race_id
12 178676
Name: count, dtype: int64
race_idごとの桁数をカウントした結果を確認すると、全て12桁になっていることがわかります。
改めて"odds_rank_gap"を確認すると…
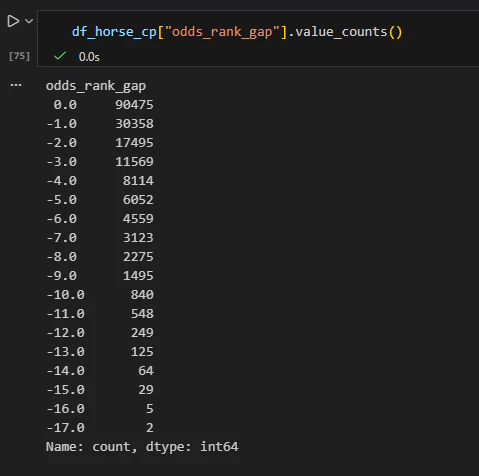
最大値が-17.0に収まっているのは良いのですが、値がすべて負なのがおかしいですし、また-17.0をたたき出している馬を確認するとそのレースで一頭しかデータがなかったりと色々問題がありました。
原因としては以下の4つです。
- スクレイピングしたレース範囲は2023年10月から2024年4月までだが、馬の過去成績をすべて含めた結果それ以外の範囲のレース結果が含まれている
- その結果まだ見ぬ馬とのレース結果が入り込んでおり、odd_rankを計算したときに正しい分母で計算できていない
- 例えば未来のデータを使っていることにもなるし、過去のデータでも出頭数が異常に少ない事象が発生
- 以下のURLで任意期間のrace_idをスクレイピングしたが、このカレンダーに適応されているのはJRA中央競馬のレースのみで、地方競馬は含まれていない
- 一方馬の過去成績には地方も中央も構わずレース結果がまとめられているので、データを集約する際おかしなことになる
上二つは特徴量エンジニアとしての経験の無さが、した二つは競馬に関するドメイン知識の無さが露呈しましたね…
現状の対策は以下とします。
- horse_resultテーブルの"race_date"列を参照し、スクレイピング期間以外のデータを除外する
- race_idで集約した結果、データ数が"num_of_horses"に届かない場合除外する
二つ目の馬の頭数比較は正しくodd_rank_gapを計算するための最終手段です。
本来は地方競馬のレース結果を除外する、もしくは完全に取得するのが自然ですが、確実にodd_rank_gapを計算するためこの方法をとります。
かなりの時間を要しましたが、正しい期間で等しい頭数のみ、"odds_rank_gap"を算出した結果がこちらです。
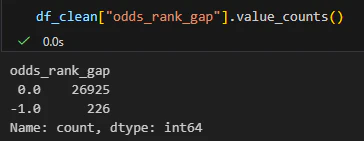
データが0or-1しかなくなってしまいました。
そんなわけない、ChatGPTも差が出て有効な特徴量になると言っていたのに…
そう思いながら-1のデータを確認していったところ、oddsが等しいと-1になるようです。
すなわちoddsは等しいためodd_rankは同じ、しかし人気は等しくはならないためそこで唯一差分が生まれているようです。
つまりオッズと人気は完全に一致していると考えて良さそうです。
集団知能がこんなにも優秀なのか、やはり確定後のオッズを使っているのが原因なのか、こうなる理由は不明ですがここまで差が出ない(出たとしてもオッズが等しいことで発生している優位ではない特徴量)のであれば、この特徴量は今のところボツにします。
今回は過去にスクレイピングした馬の過去成績テーブルで様々な問題が発覚し、修正をしていったため長めの記事になってしまいました。
しかしこれでテーブルは改善され、正しく特徴量を作れているはず…
次回は馬の過去成績から得た特徴量を一度race_resultテーブルにマージして予測精度がどう変わるか試してみます。