はじめに
自分が実施したことの備忘録のメモとなります。
やること
機械学習の勉強を実施しようとすると大量の画像が必要になるときがあります。画像収集には、Bingが一番適しているようだというのと、Microsoft Azureはやってことがなかったので、これも勉強ということで実施してみました。画像収集でつまずくと地味にツライと参考URL先の投稿でもありますが、激しく同感です。
【参考URL】Yahoo、Bing、Googleでの画像収集事情まとめ
https://qiita.com/ysdyt/items/565a0bf3228e12a2c503
前提
Microsoft:Bing Search APIのキーの取得(参考URLにて取得方法を確認)
https://azure.microsoft.com/ja-jp/
有効期限:無料で使えるのは30日間
参考URL
・Bing Web Search APIで画像自動収集プログラムを作る
https://blog.wackwack.net/entry/2017/12/27/223755
・Bingの画像検索APIを使って画像を大量に収集する
https://qiita.com/ysdyt/items/49e99416079546b65dfc
・公式:クイック スタート:Bing Image Search REST API と Python を使用してイメージを検索する
https://docs.microsoft.com/ja-jp/azure/cognitive-services/bing-image-search/quickstarts/python
コード
-
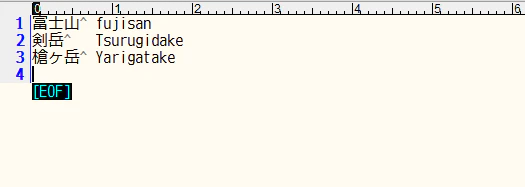
検索ワードは複数にしたかったので、ローカルからアップロードする(検索ワードともに、格納するフォルダ名もアップロード)
-
Endpoint URL
https://bingsearchv7forimages.cognitiveservices.azure.com/bing/v7.0 -
参考URLのコードに、アップロードの部分を追加しただけのみとなります。
import math
import requests
import time
import OpenSSL
import urllib
import hashlib
import sha3
import os
import csv
# 引数fをファイル名と拡張子(.は含まない)に分割する
def split_filename(f):
split_name = os.path.splitext(f)
file_name =split_name[0]
extension = split_name[-1].replace(".","")
return file_name,extension
def download_img(path,url):
_,extension = split_filename(url)
if extension.lower() in ('jpg','jpeg','gif','png','bmp'):
encode_url = urllib.parse.unquote(url).encode('utf-8')
hashed_name = hashlib.sha3_256(encode_url).hexdigest()
full_path = os.path.join(path,hashed_name + '.' + extension.lower())
r = requests.get(url)
if r.status_code == requests.codes.ok:
with open(full_path,'wb') as f:
f.write(r.content)
print('saved image...{}'.format(url))
else:
print("HttpError:{0} at{1}".format(r.status_code,image_url))
# Endpoint URL
url = "https://api.cognitive.microsoft.com/bing/v7.0/images/search"
# Bing Search API Key
APIKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Parameter
headers = {'Ocp-Apim-Subscription-Key':APIKey}
count = 10 # 1リクエストあたりの最大取得件数 default:30 max:150
mkt = "ja-JP" # 取得元の国コード
num_per = 2 # リクエスト回数(count * num_per=取得画像数)
offset = math.floor(count / num_per) # ループ回数
with open("./list.txt", "r", encoding="utf-8_sig") as f:
reader = csv.reader(f, delimiter='\t')
for row in reader:
keyword = row[0]
pathname = row[1]
# 保存先の指定
path = "./" + pathname
# 保存先が存在しない場合
if not os.path.exists(path):
os.makedirs(path)
for offset_num in range(offset):
params = {'q':keyword, 'count':count, 'offset':offset_num*offset, 'mkt':mkt}
r = requests.get(url, headers=headers, params=params)
data = r.json()
for values in data['value']:
image_url = values['contentUrl']
try:
download_img(path, image_url)
except Exception as e:
print("failed to download image at {}".format(image_url))
print(e)
time.sleep(0.5)
-
アップロードファイル:検索ワードと格納フォルダ名称(list.txt)
-
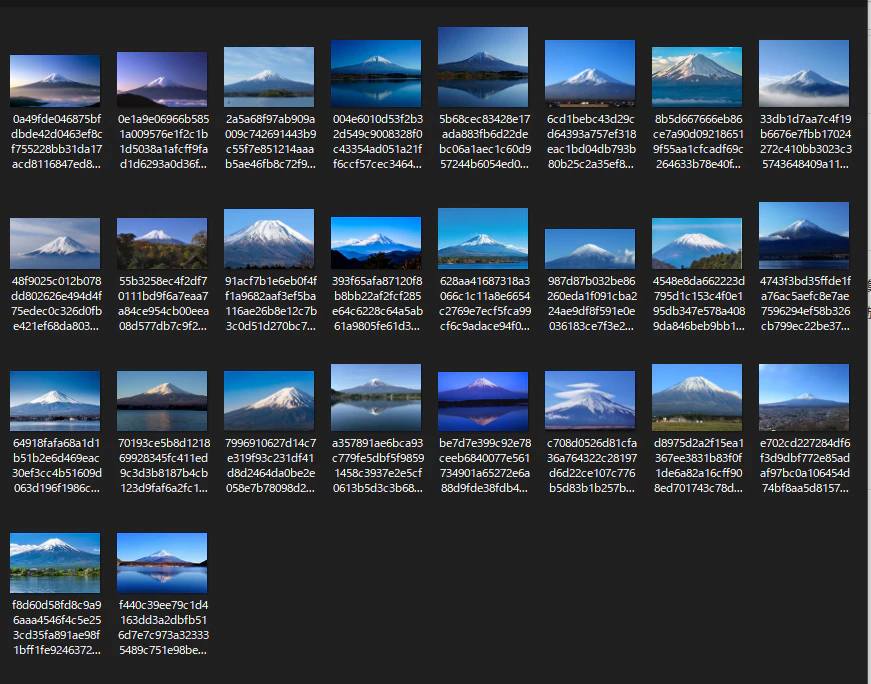
ダウンロード画像(fujisan)
その他
- インストール:
pip install pysha3は、python version 3.7 ではエラーになった。version 3.6ではエラーなくインストールができたので、当プログラムは、python3.6で実行。
まとめ
-
画像系の機械学習を勉強するときに最初でつまずく、ということは回避できました。(感謝)
-
MS Azureの有料料金も高くないので、無料枠終了後、状況によって使用してもよいのかもと思いました。
料金:https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/search-api/