やりたかったこと
個人でWEBサイトを作成して、HTML・CSS・JavaScriptを使ってきましたが、更新作業は面倒な部分もあります。自動で内容が更新されるWEBサイトを作成したいなと思いました。
サイト概要
「世界の絶景100選」などを紹介しているサイトにでてくる絶景について、頻出度、google検索結果、独自ポイントを付与して、世界の絶景ランキングを自動で生成する。(更新頻度:1日1回 or 2回)
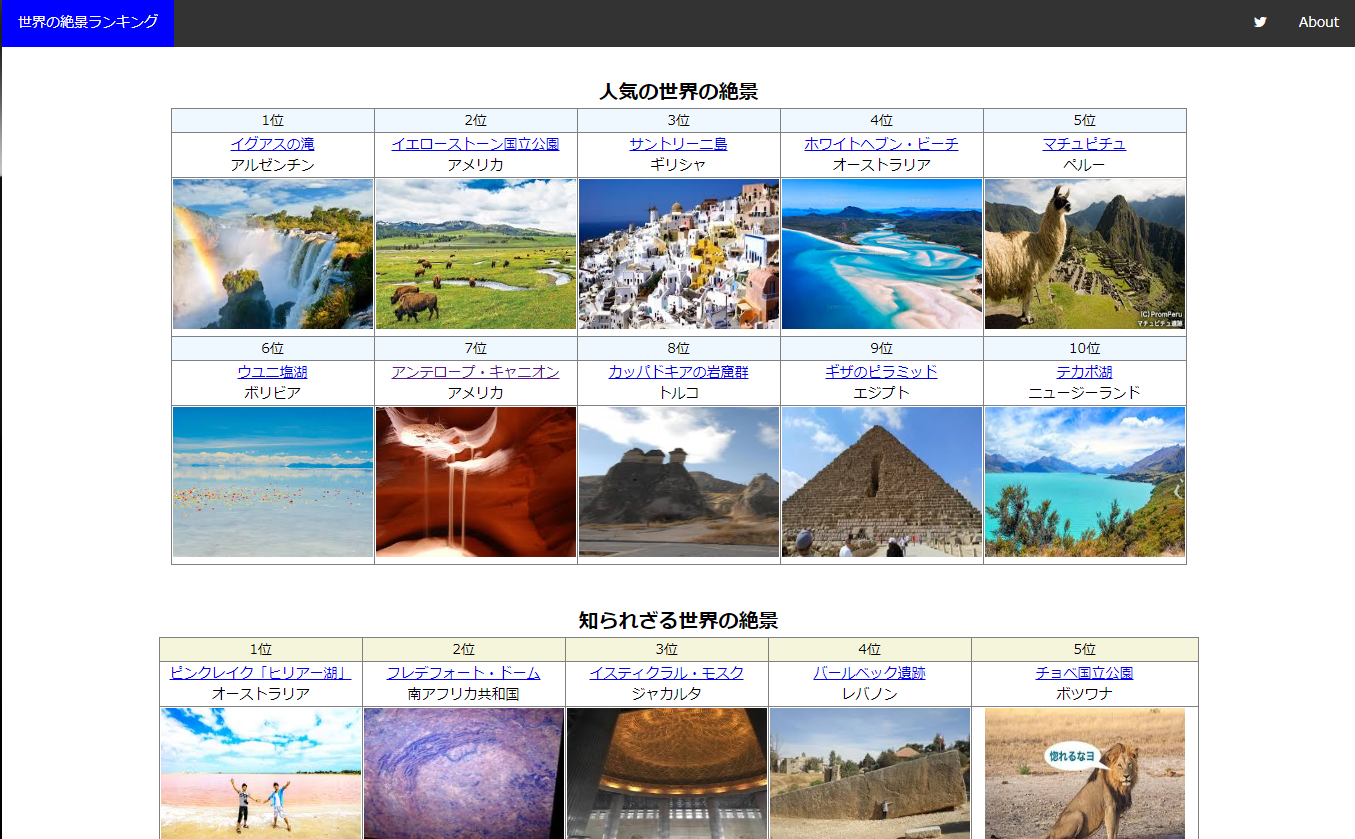
1. 人気の世界の絶景10
絶景まとめサイトでよくでてくる絶景 + 自分ポイントを付与 + googleの検索結果を加味する
2. 知られざる世界の絶景10
絶景まとめサイトで書いてはあるけど、そんなにでてこない絶景をランダム表示 + googleの検索結果の下位順を加味
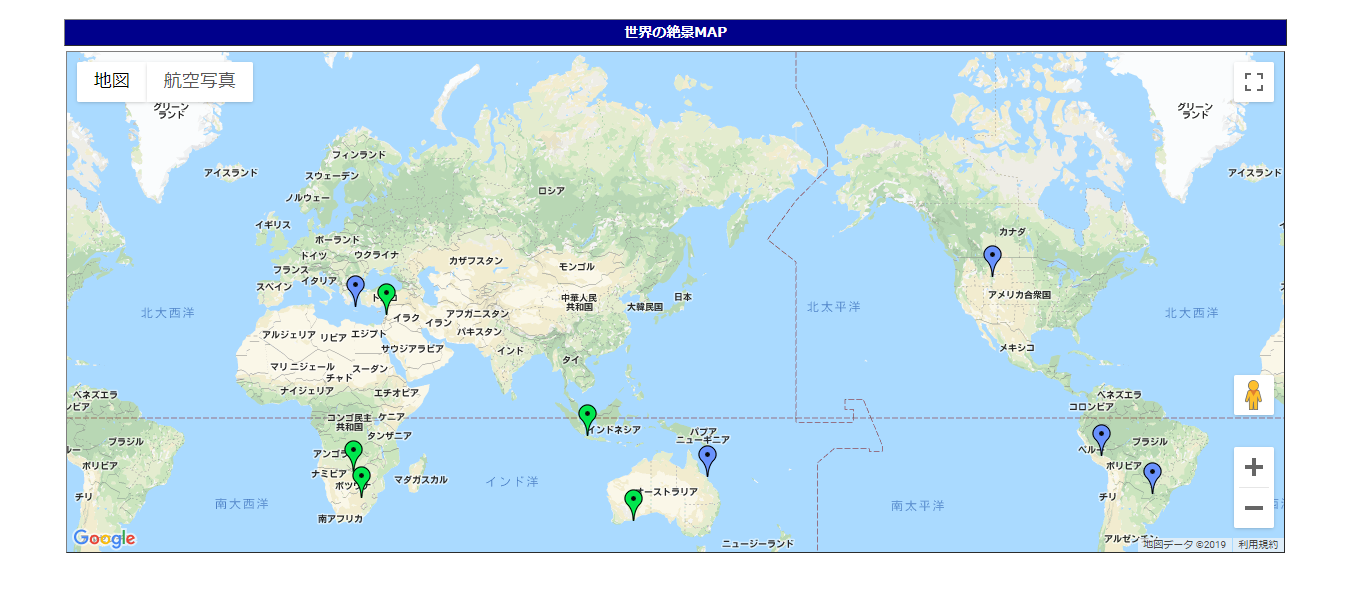
3. Google MAP API を利用して、それぞれのランキングの上位5つの絶景の場所にピンを立てる
公開サイト
使用技術
- Python3.6 にてスクレイピング(BeautifulSoup)
- Django2.0 + MySQL
- Google Map API v3
- Google Custom API
手順 と ポイント
1: ランキングの作成(Python)
①世界の絶景を紹介しているページを5~10サイトほど、pythonにてスクレイピングし、世界の絶景の名称を取得(更新頻度:1日1回)し、DB(MySQL)に格納する。
スクレイピングの例:
import urllib.request, urllib.error
from bs4 import BeautifulSoup
def getURL(urlInfo, tagInfo):
url = urlInfo
# ヘッダーセット
ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
req = urllib.request.Request(url, headers={'User-Agent': ua})
try:
# URLにアクセスする htmlが帰ってくる
html = urllib.request.urlopen(req)
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, 'html.parser')
# 要素全てを摘出する
return soup.find_all(tagInfo)
except:
pass
def makeList(tagInfo, findInfo, urlInfo):
# 取得結果をループし文字列を取得
for t1 in tagInfo:
text = t1.string
if text is None:
pass
else:
if findInfo is None:
list.append([text, urlInfo])
else:
index = text.find(findInfo)
if index != -1:
list.append([text, urlInfo])
list = []
#スクレイピングの実施
url1 = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxx' #URLをセットする
getInfo = getURL(url1, 'h2') #URLとタグ情報をセット
if getInfo is None:
print('データ取得失敗')
else:
# makeListにてlistを作成
makeList(getInfo, '位', url1) #検索ワードを渡す
②あらかじめ作成しておいたMy絶景リスト(一度スクレイピングした情報から独自に作成)をDBにアップロードしておく
DBへのアップロードの例:
import mysql.connector
import csv
#手持ちのデータリストmylistを読み込み、mysql table mylistにupdate/insertする
# MySQL接続
cnt = mysql.connector.connect(
host='xxxxxxxx',
db='xxxxxxx',
user='xxxxxxx',
password='xxxxxxx',
charset='utf8'
)
# カーソル取得
db = cnt.cursor(buffered=True)
# mylistを読み込み、dbをselect、データがなければinsert、あればupdate
with open("./mylist.txt", "r", encoding="utf-8_sig") as f:
reader = csv.reader(f, delimiter='\t')
for row in reader:
keyword = row[0]
name = row[1]
country = row[2]
point = row[3]
# dbデータをkeywordでselect
sqlselect = "select * from ranks_mylist where keyword='" + keyword + "';"
db.execute(sqlselect)
row1 = db.fetchall()
dbcnt = len(row1)
# dbにデータがあればupdate
if dbcnt > 0:
for rdata in row1:
id = rdata[0]
sqlupdate = 'UPDATE ranks_mylist SET name="' + name + '", country="' + country +'", point="' + point +'" where id="' + str(id) + '";'
db.execute(sqlupdate)
# dbにデータがなければinsert
else:
sqlinsert = 'INSERT INTO ranks_mylist(keyword, name, country, point) VALUES ("' + keyword + '", "' + name + '", "' + country + '",' + point + ')'
db.execute(sqlinsert)
# カーソル終了
db.close()
# コミット
cnt.commit()
# MySQL切断
cnt.close()
③
My絶景リストにある絶景とスクレイピングした情報をぶつけて、ランキングを作成し、DBに格納。
ぶつける際には、Google Custom Search APIを使用して、そのキーワードの検索結果数も加味する。
また、同時に、グーグルの画像検索結果を1件取得し、その画像URLも同時にDBに格納する。
2. ランキングサイトの表示(Django + GoogleMapAPI)
①作成されたランキングテーブルを使用して、サイトを表示する
テーブルへの書き出しは、javascriptでdocument.writeを使用してループする。リンクには、googleの通常検索と画像検索を埋め込む。
<caption>人気の世界の絶景</caption>
<thead class="tablehead1">
<tr>
<td>1位</td><td>2位</td><td>3位</td><td>4位</td><td>5位</td>
</tr>
</thead>
<tbody>
<tr>
<script type="text/javascript">
var flg = 1;
{% for rank in ranks.all %}
if(flg <= 5){
document.write("<td><a href='http://www.google.com/search?q={{ rank.name }}' target='_blank'>{{ rank.name }}</a><br>{{ rank.country }}</td>");
}
flg ++;
{% endfor %}
</script>
</tr>
<tr>
<script type="text/javascript">
flg = 1;
{% for rank in ranks.all %}
if(flg <= 5){
document.write("<td><a href='http://www.google.com/search?q={{ rank.name }}&tbm=isch' target='_blank'><img src = {{ rank.imageurl }} width='200' height='150'></td>");
}
flg ++;
{% endfor %}
</script>
</tr>
</tbody>
②Google MAP API v3 を利用して、それぞれのランキングの上位5つの絶景の場所にピンを立てる
→ 別記事参考(google map:名称にて場所を検索する)
まとめ
- スクレイピングの実施、ランキングを作成するPythonプログラムは、1日1回 or 2回 Cronにて実施している。
- スクレイピングを実施するサイトを増やしたり、自分ポイントの付与を変えたりするとランキングが動く。(特に、スクレイピングで1件しかとれなかった絶景はランダム表示なので、ランキングが頻繁に変わる)
→ スクレイピングによる情報や自分のロジック(ルール)などで、情報が自動更新されるサイトの作成ができました。