まとめ
LLaVAのデフォルトの損失は下図のように計算されている。
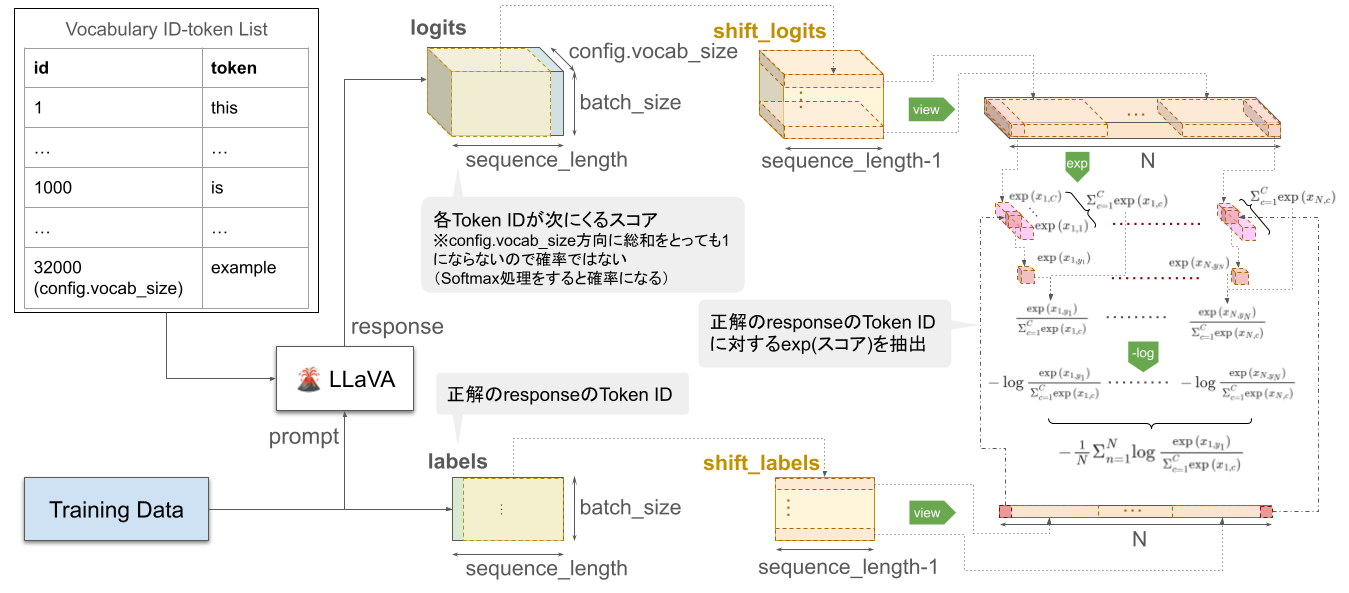
全体の流れ
経緯
- 分類タスクや判定タスクの損失関数は理解していたが、言語生成AIの損失関数はどう定義されているのか知らなかったのでとりあえず1例一通り調査した
-
huggingface/transformersのGPT2を実装した中で、今回はLLaVAを題材にした
- 損失関数:今回題材にしたコード
- ざっと見たところ、同じような損失関数が実装されていたモデルは下記の通り
- ViP-LLaVA
- InstructBLIP
- GPT bigcode
- GPT neox japanese
理解に必要と思われる部分の抜粋
変数の説明
- input_ids(入力するトークンIDのテンソル)
-
引用
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`): Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it. Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for details. [What are input IDs?](../glossary#input-ids) ``` - 参考
-
引用
- vocab_size(LLaVAモデルのVocabulary size。一回のプロセスに取り扱えるトークン数)
-
引用
vocab_size (`int`, *optional*, defaults to 32000): Vocabulary size of the Llava model. Defines the number of different tokens that can be represented by the `inputs_ids` passed when calling [`~LlavaForConditionalGeneration`] - 参考:What is Vocabulary Size: LLMs Explained
-
引用
- logits(LLaVAが予測した各トークンに対するスコアのテンソル)
-
引用
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`): Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). - 参考:What is LM head mean?
-
引用
- labels(損失を計算するためのラベル(トークンID)のテンソル。
input_idsで-100が設定されているidは損失計算時に無視される)-
引用
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*): Labels for computing the masked language modeling loss. Indices should either be in `[0, ..., config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
-
引用
損失関数部分
損失計算のスクリプトを抜粋したもの
(デフォルトがattention_mask: Optional[torch.Tensor] = Noneのためattention_maskを利用しない場合を取り上げる)
# Shift so that tokens < n predict n
...
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
...
# Flatten the token
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1).to(shift_logits.device)
)
スクリプト詳細
Shift so that tokens < n predict n 部分
-
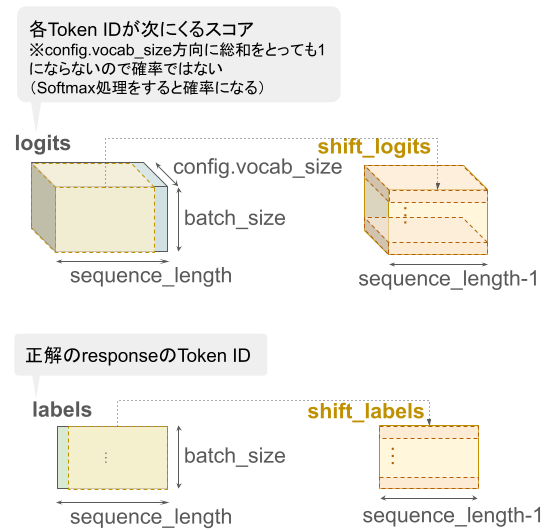
shift_logits = logits[..., :-1, :].contiguous()-
batch_size×sequence_length×config.vocab_sizeの3次元テンソルであるlogitsを取得- 第1次元の長さ:
batch_size - 第2次元の長さ:
sequence_length - 第3次元の長さ:
config.vocab_size
- 第1次元の長さ:
- 第1次元と第3次元をそのままに、第2次元の末尾の要素を削除
- メモリ内に再配置して
shift_logitsに代入
-
-
shift_labels = labels[..., 1:].contiguous()-
batch_size×sequence_lengthの2次元テンソルであるlabelsを取得- 第1次元の長さ:
batch_size - 第2次元の長さ:
sequence_length
- 第1次元の長さ:
- 第1次元をそのままに、第2次元の第1要素を削除
- メモリ内に再配置して
shift_labelsに代入
-
shift_logitsとshift_labelsのイメージ
Flatten the token 部分
-
loss_fct = nn.CrossEntropyLoss()- デフォルトの設定でCross Entropy関数を
loss_fctに代入
- デフォルトの設定でCross Entropy関数を
-
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1).to(shift_logits.device))- Cross Entropy関数の詳細は次節
- 第1引数:
shift_logits.view(-1, shift_logits.size(-1))-
shift_logitsを(batch_size * (sequence_length - 1))×config.vocab_sizeの2次元テンソルに変形-
shift_logits.size(-1)でshift_logitsの末尾の次元長config.vocab_sizeを得る
-
-
- 第2引数:
shift_labels.view(-1).to(shift_logits.device)-
shift_labelsを長さ(batch_size * (sequence_length - 1))の1次元テンソルに変形 -
shift_logitsと同じデバイスのメモリに格納
-
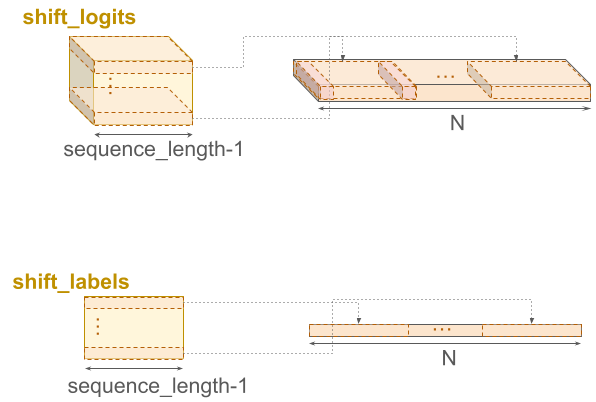
view関数のイメージ
CrossEntropyLoss関数の処理
題材にしたコードではCrossEntropyLoss関数に明示的な引数を与えていないため、下記では、デフォルト値を適用した際のアルゴリズムについて調べた。
公式ドキュメント(PyTorch ver. 2.2)の定数は下記のように設定される。
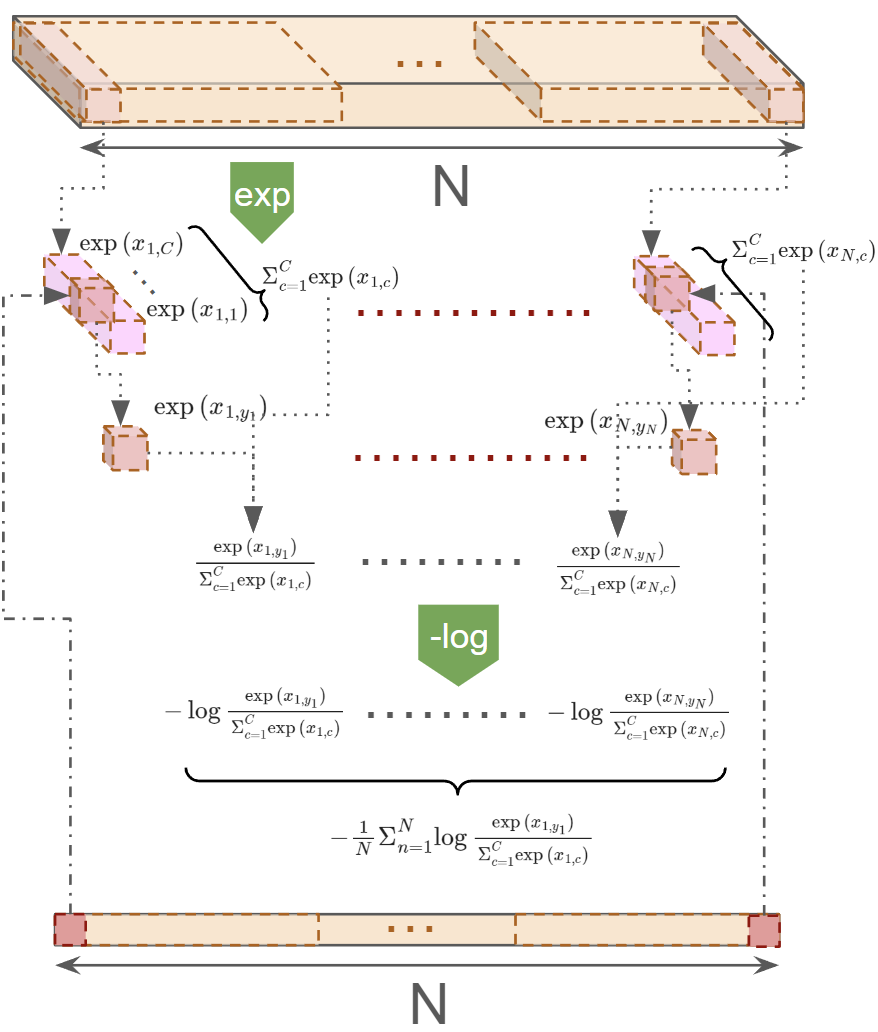
- バッチサイズ:$N =$
(batch_size * sequence_length) - クラス数:$C =$
config.vocab_size - 入力:$x =$
shift_logits.view(-1, shift_logits.size(-1))- $N$ × $C$の2次元テンソル
- ターゲット:$y =$
shift_labels.view(-1).to(shift_logits.device)- 長さ$N$の1次元テンソル
CrossEntropyLoss関数のデフォルト設定ではreductionがmean、weightがNoneに設定されるようなので、損失$ \ell(x,y) = L = [l_1, l_2, ..., l_N]^T$は、下記のようになる。
$$
\ell(x,y) = \Sigma_{n=1}^{N}{\frac{l_n}{N}}
$$
$$
l_n = -\log\frac{\exp(x_{n,y_n})}{\Sigma_{c=1}^{C}\exp(x_{n,c})}
$$
- $x_{n,y_n}$: $x$のうち第1次元$n$、第2次元が$y_n$に当てはまる要素
- $x_{n,c}$: $x$のうち第1次元$n$、第2次元$c$の要素
CrossEntropyLossの処理はLogSoftmaxとNLLLossと同じであることについて下記の記事で解説されている