はじめに
LLMの学習において,一般的にモデルがXXB, XXXB級となり非常に巨大なために,分散学習の選択肢をとるパターンは少なくないと思います。
大規模な分散学習を行う場合には,MosaicMLを使うと,低コストかつ効率的,柔軟なモデル学習ができて便利です。
この記事ではMosaicMLでStreamingDatasetを使って,データをストリーミングしながらシャッフルする時のシャッフルの品質や速度について調べたので共有します。
背景
現在業務でLMの事前学習などを行っていまして,ModenBERTを触る機会がありました。みなさんご存知のBERTの最新版になります。ModernBERTの解説記事は世の中にたくさんありますので,この記事では割愛します。
ところで,ModernBERTの論文中に,データのサンプリングに関して,学習において一度失敗したとの記述があります。
Our first pretraining run of ModernBERT-base ended in disaster as the loss exhibited a slow seesaw pattern before slowly diverging. Despite using PyTorch’s distributed random sampler, training metrics suggested that the model was training on the dataset in a non-random order. Like the Olmo authors, we determined that the PyTorch random sampler returns sequentially biased samples when the number of samples is somewhere between 500 million and 1 billion samples. We resolved this issue by replacing the PyTorch sampler with NumPy’s PCG64DXSM random sampler.
つまり非常に大きなデータセットを学習に用いる場合,PytorchのDistributedSamplerを用いると,学習データが0.5B-1B周辺に偏り,損失関数の収束が悪くなるとのことです。
自身がModernBERTの学習を行う上で,割と重要そうなので理解を深めるために少し調べてみました。
Pytorchのtorch.randperm vs numpy.random.PCG64DXSM
はじめに,今回は以下のpythonバージョンと
Python 3.12.8
以下のpythonライブラリの環境で実験を行いました。
composer==0.32.1
mosaicml-streaming==0.13.0
numpy==2.1.3
torch==2.7.0+cu126
まず,ModernBERTの公式の学習コードの実装を確認します。
src/text_data.pyのこの部分がDistributedSamplerPCG64DXSMのコードです。確認すると,以下のようになっています。
if self.shuffle:
# deterministically shuffle based on epoch and seed
# use numpy's RNG PCG64DXSM instead of torch.randperm
rng = np.random.Generator(np.random.PCG64DXSM(self.seed + self.epoch))
indices = rng.permutation(len(self.dataset)).tolist() # type: ignore[arg-type]
else:
indices = list(range(len(self.dataset))) # type: ignore[arg-type]
numpy.random.PCG64DXSMを使ってランダムインデックスの生成をしています。
一方,論文中で言及されている"PyTorch’s distributed random sampler"は継承元のDistributedSampler,torch.utils.data.distributed.DistributedSamplerの可能性が高いです。
DistributedSamplerではどのようにランダムインデックスを生成しているかというと,以下の実装でした。
def __iter__(self) -> Iterator[T_co]:
if self.shuffle:
# deterministically shuffle based on epoch and seed
g = torch.Generator()
g.manual_seed(self.seed + self.epoch)
indices = torch.randperm(len(self.dataset), generator=g).tolist() # type: ignore
else:
indices = list(range(len(self.dataset))) # type: ignore
torch.randpermを使っています。
おそらくModernBERTではtorch.randpermを最初使っていたらサンプルが偏って,学習がうまく進まなかったものと想像します。
またこんな記事もありました。Torch vs Numpy Shuffling
ここではtorch.randpermとnumpyの乱数ジェネレータの比較実験をしていて,データ量がXB級になるとやはりtorch.randpermだと若いIDのサンプルに偏ってしまうと結論づけています。
本当にそうなのかね?ということで自分の環境で実験してみました。
まず,Torch vs Numpy Shufflingのコードをお借りして,以下のコードで実験してみます。
torch.randpermのコードは以下です。
torch.randpermで1-3*10^9までの整数のpermutationを生成し,そこから最初の10000件をサンプルして,1-10のデサイルに分けます。このデサイルは10分位数であり,1-3*10^9の整数が10個の等しい区切りのどこかに所属することになります。つまりビン数が10個のヒストグラムですね。
import torch
import matplotlib.pyplot as plt
exponent = 9
shuffled = torch.randperm(3 * 10**exponent)
shuffled_interval = shuffled[:10_000]
def decile(index, collection_size):
"Returns 1 to 10, for the decile of `index` within `collection_size`"
return 1 + int(index // (collection_size / 10))
deciles = [decile(x.item(),shuffled.shape[0]) for x in shuffled_interval]
plt.figure(figsize=(10, 6))
plt.hist(deciles, bins=range(1, 12), align='left', rwidth=0.8)
plt.xlabel('Decile')
plt.ylabel('Frequency')
plt.title(f'Histogram of Deciles with torch.randperm when permutation of 3^{expornent}')
plt.xticks(range(1, 11))
plt.show()
同様に,numpy.random.PCG64DXSMのコードも上記同様の操作と描画をします。
import numpy as np
import torch
import matplotlib.pyplot as plt
expornent = 9
rng = np.random.Generator(np.random.PCG64DXSM())
shuffled = rng.permutation(3 * 10**expornent)
shuffled = torch.from_numpy(shuffled)
shuffled_interval = shuffled[:10_000]
def decile(index, collection_size):
"Returns 1 to 10, for the decile of `index` within `collection_size`"
return 1 + int(index // (collection_size / 10))
deciles = [decile(x.item(),shuffled.shape[0]) for x in shuffled_interval]
plt.figure(figsize=(10, 6))
plt.hist(deciles, bins=range(1, 12), align='left', rwidth=0.8)
plt.xlabel('Decile')
plt.ylabel('Frequency')
plt.title(f'Histogram of Deciles with PCG64DXSM randomization when permutation of 3^{expornent}')
plt.xticks(range(1, 11))
plt.show()
decile_torch.pyの結果は以下。一様分布ぽい...?

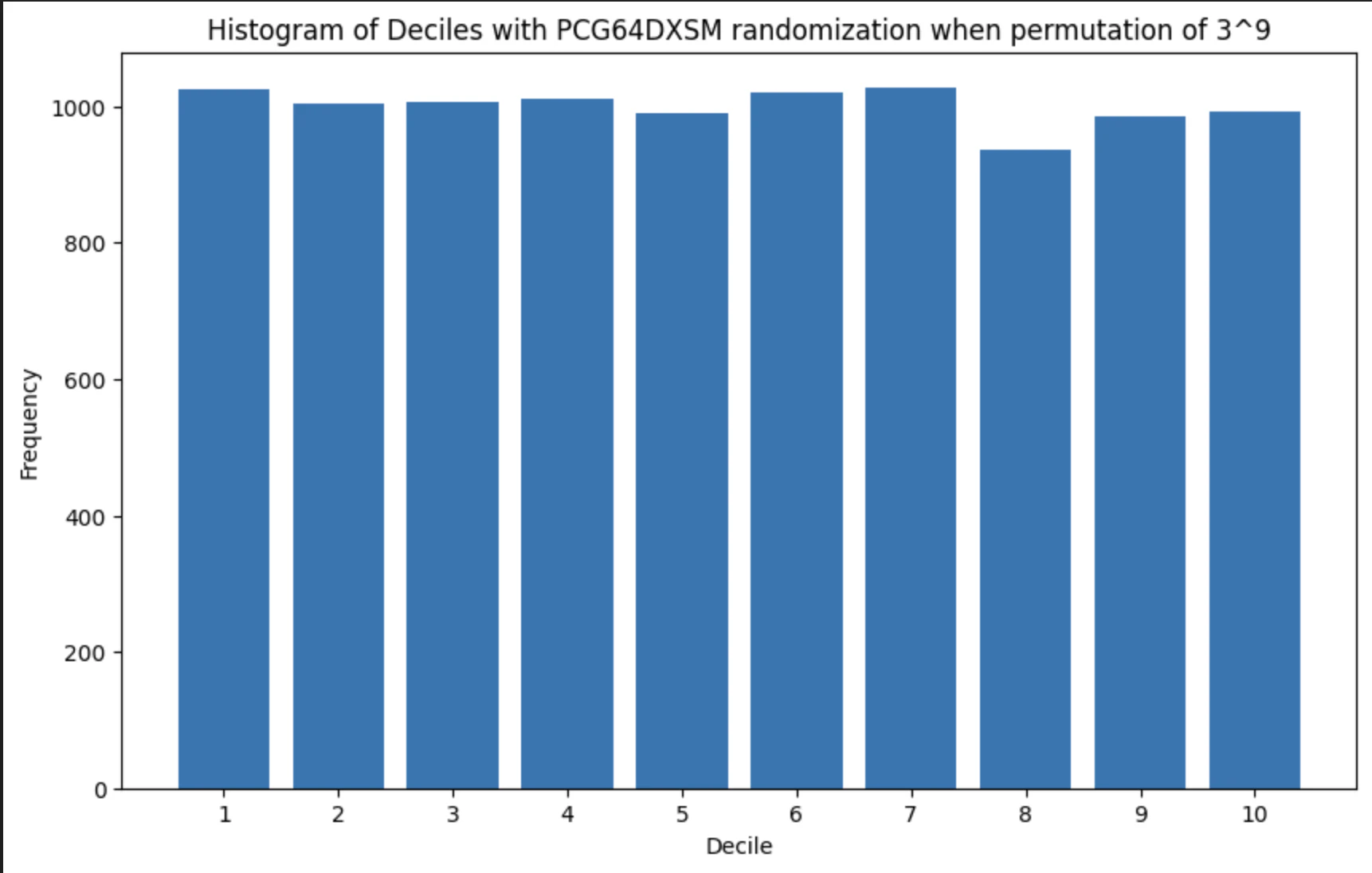
decile_numpy.pyの結果は以下。torch.randpermとほぼ変わらないですね。
どうやらTorch vs Numpy Shufflingとpytorchとnumpyのバージョンが異なっていたみたいなので,デグレさせてもう一回同じコードを回しました。
torch==2.7.0+cu126 -> torch==2.4.0+cu126
numpy==2.1.3 -> numpy==2.0.1
バージョンを下げてやってみたところ,以下の結果になりました。
decile_torch.py
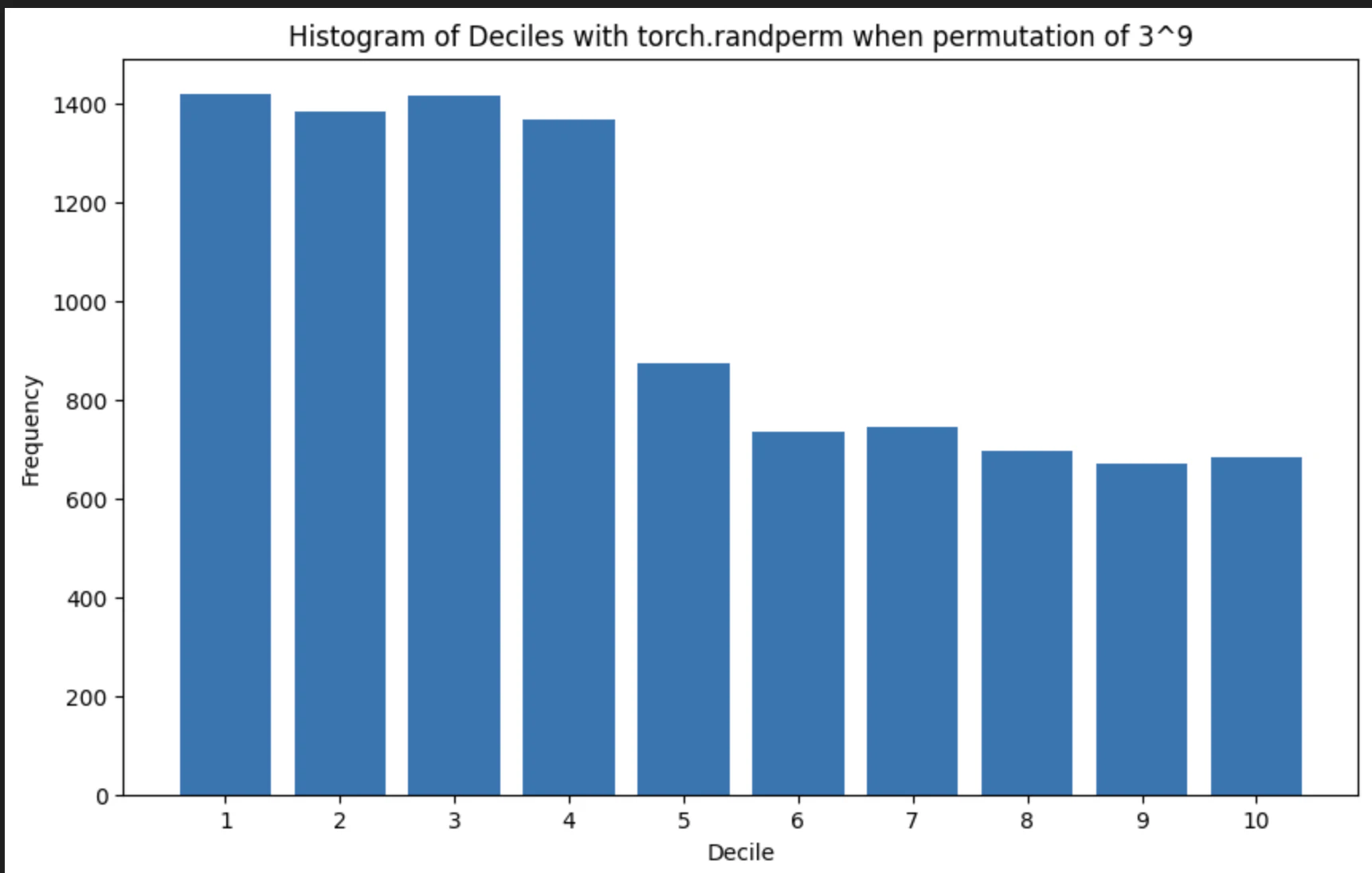
decile_numpy.py

明らかにtorch.randpermの方が若いインデックスの方にサンプルが偏っていることがわかります。この検証の結論としては,少なくともtorch==2.7.0以上であればtorch.randpermを使っても大丈夫そう,ということがわかりました。詳細は分かりませんが,疑似乱数生成のアルゴリズムのアップデートがあったのではないでしょうか。
ModernBERTの学習でどのバージョンのpytorchが使われていたか正確にはわかりませんが,torchのバージョン履歴を見ると,ModernBERT論文の出たタイミングが2024年12月であることを加味すると,おそらく2.4系~2.5系で学習させていたのではないかと考えられます。
StreamingDatasetのシャッフル方法
先ほどの検証は,ModernBERTの学習において,ローカルに解凍されたMDS(Mosaic Data Shard)データが存在し,そのローカルデータをサンプルする際はDistributedSamplerPCG64DXSMが使われるため,実施してみました。私もストレージに余裕はあったので,500GB~1Tサイズの.mds形式のデータをローカルストレージに構えて,そこを見に行く形でモデル学習を進めていました。ModernBERT論文で言及していたSamplerの問題も,こちらのケースかと思われます。
しかしながら,ストレージに余裕がない場合はStreamingDatasetを使ってリモートのS3バケットなど,任意のクラウドストレージからデータをストリーミングして学習に使わざるを得ません。特にLLMなどの事前学習などは数Tトークン規模で行われるため,リモートのデータをストリーミングする選択肢が現実的な場合もあります。(NW I/O速度は学習速度に影響します)
そこで気をつけたいのが,StreamingDatasetを用いたデータのシャッフルです。このシャッフル方法を調べていくとデータの偏りが発生しやすい方法だったので共有します。
MosaicMLのStreamingDatasetでは,MDS形式のデータを複数のノードに分散して学習を行うために,シンプルなコードで実装が可能です。
SteramingDatasetの使い方はこんな感じです。
from streaming import StreamingDataset
SEED = 42
ds = StreamingDataset(
remote='s3://...',
keep_zip=True,
shuffle=True,
shuffle_algo="py1e",
shuffle_seed=SEED,
batch_size=1,
)
MosaicMLにおいて,データはmdsのshardという単位で処理されるため,StreamingDatasetは独自のシャッフルアルゴリズムを実装しています。(shuffle=Trueでデータのシャッフルを有効化できます)
シャッフルアルゴリズムの指定はshuffle_algoで可能です。デフォルトは'py1e'です。
shuffle_algo引数で以下のようにシャッフルアルゴリズムが変化します。
| shuffle_algo | algorithm type | description |
|---|---|---|
| 'py1e' | Shuffle-block-based | 各canonical node内で、shuffle_block_size 個ずつブロック単位でサンプルをspread+シャッフル。 各shardのサンプルが,ブロックをまたいで散らされる (spread out) |
| 'py1br' | Shuffle-block-based | py1e の簡易/派生版。canonical node内で,block_size ごとにブロック内シャッフルを行う。ブロック境界はランダム化される |
| 'py1s' | Intra-shard shuffle | canonical node割り当て後に各shard (あるいはその一部) 内だけをシャッフルする。 |
| 'py2s' | Intra-shard shuffle | shard内シャッフルを、canonical nodeへの割り当ての前後で実施。(2回シャッフルする) |
| 'naive' | Naive | shard単位を無視してデータを全部混ぜる |
公式のdocumentより,Streamingの場合のシャッフルの手順について整理しました。
まず,基本的にシャッフルは以下の手順で行われます。
- Step1
- rawデータを.mds形式に変換し,以下のような順でshardが並んでいるとする。番号はshardの番号

- rawデータを.mds形式に変換し,以下のような順でshardが並んでいるとする。番号はshardの番号
- Step2
- shard単位で順番がシャッフルされる

- shard単位で順番がシャッフルされる
- Step3
- 全てのcanonical nodeにシャッフルされたshardが分割される。この時,分割境界でshardが2つのnodeにまたがる場合もある

- 全てのcanonical nodeにシャッフルされたshardが分割される。この時,分割境界でshardが2つのnodeにまたがる場合もある
- Step4
- canonical node単位で,データのシャッフルを行う。この時のシャッフルアルゴリズムを
shuffle_algoで決める
- canonical node単位で,データのシャッフルを行う。この時のシャッフルアルゴリズムを
そして,Step4での各アルゴリズムの概要を以下のように理解しました。
py1e
- 以下の図のように,決められたブロック単位で,shard内サンプルを散らしてシャッフルする方式です。py1eでは短いブロックでデータのシャッフルを他のブロックと混ぜながら行う方式で,複数shardからなるランダムな順番のデータをブロックに割り当てられるので,node内のデータ全体を混ぜるよりも高効率にシャッフルできます

- まず,shard内でサンプルをシャッフル(1回目)して,それをshard間をまたがるblockに分散(2回目)させるので,Step4でのシャッフル回数は2回行うことになります
- ちなみにブロックの大きさは一定の区間でランダムに変動します
py1br
- 以下の図のように,点線の部分でブロック単位に区切り,区切られたブロック内でシャッフルします

- ブロックサイズはpy1eと同じように,動的に一定の区間で変動します
- 点線のブロック境界を跨いでシャッフルされることはありません
- Step4でのシャッフル回数は1回です
py1s,py2sはshard内シャッフルのため,偏りが発生することが自明のため,今回は取り上げません。
混合データをStreamingDatasetで学習に使う際の注意点
事前学習のケースによっては,学習データをマージしてmdsにする場合もあるかと思います。例えば多言語モデルの事前学習を行う場合に,huggingfaceから言語別にダウンロードして,shardの塊を言語1, 言語2, ...言語nのように順番に並べている場合ですね。
もしくは時系列データだと,初めから特徴が系列の部分部分で異なるデータがシャッフルされず,順番にshardになっている可能性もあります。
この時,データ規模が大きいと,大抵はロードしてシャッフルしてまた書き込む,といった事前シャッフルが困難になるかと思われます。この時,StreamingDatasetsを使ってデータをストリーミングして学習を始める際にシャッフルするとどうなるか,実験します。
前提
多言語モデルを作るために複数のオープンデータのデータセットから,日本語と英語のデータセットをダウンロードして,mds形式でリモートのクラウドストレージに保存したとします。合計0.1Bサンプルのデータが日本語→英語の順で並んでおり,1shardあたり10000サンプルが入っていて,それが10000shardあると想定します。前半5000shardは日本語データ,後半5000shardは英語データとなります。
このデータをStreamingDatasetで,シャッフルしながら取得して,モデル学習に使うことを想定します。
実験
実験は以下のコードで行いました。
from streaming.base.shuffle.py1e import get_shuffle_py1e
from streaming.base.shuffle.py1br import get_shuffle_py1br
from streaming.base.shuffle.naive import get_shuffle_naive
import numpy as np
def simulate_lang_ratio_with_shuffle(
get_shuffle_fn,
algo_name: str,
shard_sizes,
num_canonical_nodes: int = 1,
block_size: int = 1 << 18,
num_batches: int = 10,
batch_size: int = 2000,
):
shard_sizes = np.array(shard_sizes, dtype=np.int64)
num_shards = len(shard_sizes)
num_samples = int(shard_sizes.sum())
# make language label by shard: the first half is ja, the second half is en
shard_langs = np.array(
["ja"] * (num_shards // 2) + ["en"] * (num_shards - num_shards // 2)
)
# make shard index
sample_to_shard = np.empty(num_samples, dtype=np.int64)
offset = 0
for shard_idx, sz in enumerate(shard_sizes):
sample_to_shard[offset : offset + sz] = shard_idx
offset += sz
# get order
ids = get_shuffle_fn(
shard_sizes=shard_sizes,
num_canonical_nodes=num_canonical_nodes,
seed=1,
epoch=1,
block_size=block_size,
)
# ids[pos] = original sample id
# get shard's lang that the sample belongs to
shuffled_langs = shard_langs[sample_to_shard[ids]]
deviations = []
print(f"\n=== {algo_name} ===")
for b in range(num_batches):
start = b * batch_size
end = min((b + 1) * batch_size, num_samples)
if start >= num_samples:
break
batch_langs = shuffled_langs[start:end]
ja_cnt = int((batch_langs == "ja").sum())
en_cnt = int((batch_langs == "en").sum())
total = len(batch_langs)
major = max(ja_cnt, en_cnt)
deviation = (major / total - 0.5) * 100
deviations.append(deviation)
print(f"batch {b}: range [{start}, {end-1}]")
print(
f" ja: {ja_cnt}, en: {en_cnt}, "
f"ratio: {ja_cnt/total:.4f} : {en_cnt/total:.4f}, "
f"deviation_from_50%: {deviation:.4f}%"
)
# mean deviation
mean_dev = float(np.mean(deviations)) if deviations else 0.0
print(f"\n{algo_name}: mean deviation_from_50% over {len(deviations)} batches = {mean_dev:.4f}%")
# 10_000 samples * 10_000 shards
shard_sizes = np.array([10_000] * 10_000, dtype=np.int64)
simulate_lang_ratio_with_shuffle(
get_shuffle_fn=get_shuffle_py1e,
algo_name="py1e",
shard_sizes=shard_sizes,
num_canonical_nodes=1,
# block_size=1_000_000,
num_batches=100, # the number of iteration
batch_size=2000, # batch size
)
simulate_lang_ratio_with_shuffleのalgo_nameをpy1e, py1br, naiveと変化させて,サンプルした言語の比率が50%から平均でどれだけ逸脱しているか,学習時のバッチサイズは2000として,100試行して確認します。したがって試行数は学習のステップ数と同等です。
また,block_sizeパラメータもpy1e, py1brの時のみ変化させます。block_sizeを大きくすればサンプルもshard間を跨いでシャッフルでき,シャッフルの質が上がる想定です。
結果は以下となりました。
| Algorithm | block_size | Mean deviation from 50% | Computation time |
|---|---|---|---|
| py1e | default | 9.4005% | 17.2s |
| 5_000_000 | 2.9550% | 25.2s | |
| py1br | default | 4.9005% | 5.5s |
| 5_000_000 | 1.1225% | 8.1s | |
| naive | default | 0.9970% | 10.3s |
最も比率が均等になるようにシャッフルできているのはnaiveでした。canonical node内での全サンプルのシャッフルを行うので当然と言えば当然ですね。
py1eとpy1brを比較すると,両方ともblock_sizeを上げればシャッフル性能は上昇していました。block_sizeを上げれば理論上naiveに近づいてゆくことにはなり,性能は上がります。しかし,py1eの方がpy1brよりも総じてシャッフルの質は悪かったです。これはpy1brの方がblock内でシャッフルを行うので,遠くに配置された異なるshardのデータともよく混ぜることができたためでしょうか。今回は時間がかかるため最初の100ステップしか見ていないので,block境界のところはもしかするとpy1eの方がよく混ざっているかもしれません。またStreamingDatasetのshuffle_algoのデフォルトのpy1eは計算時間がネックになります。実質シャッフルを2回実施するので,その分計算コストがかかってしまいます。(naiveよりも大きい)今回の検証はこのような結果でしたが,これらのアルゴリズムのシャッフルの質,計算コストはshard数,shard内サンプル数によって変わると思われます。
このシナリオにおいて,データの一部(指定した学習トークン量を終わるまで)しか使わずに学習を行うとなると,日本語:英語=50:50でデータを作成したにも関わらず,実際学習したデータは日本語:英語=60:40になっていて,一方の言語で期待した性能が出なかったなどとなりかねません。StreamingDatasetを使う際には,shuffle_algoは計算コストがそこまで大きくなく,一貫してシャッフルの質を担保できるnaiveにしておくと安心でしょう。