はじめに
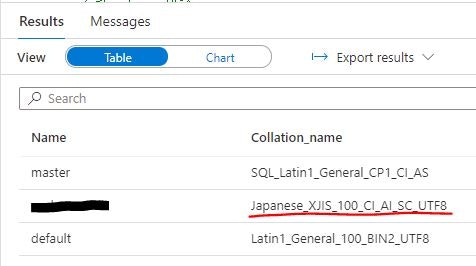
Azure Synapse Analytics の serverless SQL pool のデフォルトの照合順序は 「SQL_Latin1_General_CP1_CI_AS」 です。これは、以下の T-SQL を実行することにより確認できます。
SELECT name, collation_name FROM sys.databases

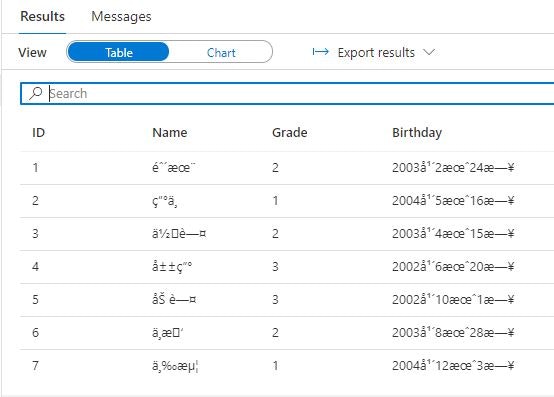
この照合順序のままですと、日本語が含まれたファイルを取り扱う場合に不便が生じます。具体的には、以下のようにUTF-8 でエンコードされた CSV ファイルを serverless SQL pool でクエリ実行すると、日本語の部分が文字化けします。
ID,Name,Grade,Birthday
1,鈴木,2,2003年2月24日
2,田中,1,2004年5月16日
3,佐藤,2,2003年4月15日
4,山田,3,2002年6月20日
5,加藤,3,2002年10月1日
6,中村,2,2003年8月28日
7,三浦,1,2004年12月3日
照合順序の変更
これを防ぐには、serverless SQL pool の照合順序を変更する必要があります。日本語対応しているものであれば何でもよいですが、例えば「Japanese_XJIS_100_CI_AI_SC_UTF8」に変更するには以下の T-SQL を実行します。
ALTER DATABASE <dbname> COLLATE Japanese_XJIS_100_CI_AI_SC_UTF8
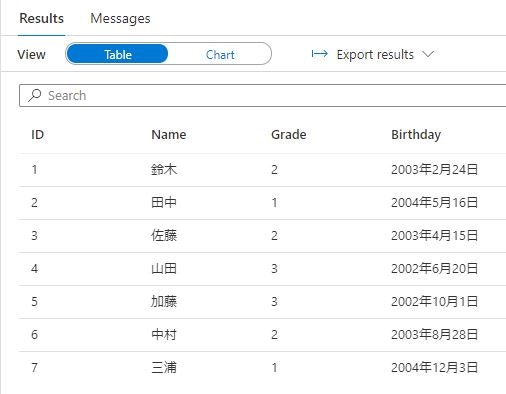
変更後にクエリを実行すると、文字化けせずに結果が返されることが確認できます。
所感
今回の件はオンプレの SQL Server などではよくある話題であり知っていればどうということはないのですが、サーバーレスであると内部の仕組みに対する意識が薄れがちになるのでよい教訓となりました。