はじめに
Rustコミュニティにおいて、AI・機械学習(ML)分野への関心が急速に高まっています。その中心的な役割を担うプロジェクトの一つが、Rust製のディープラーニングフレームワーク「Burn」です。安全性、パフォーマンス、そして移植性を妥協しないという野心的な目標を掲げるBurnは、多くの開発者から注目を集めています。
そして先日、その進化を加速させる重要なリリースv0.18.0が公開されました。このバージョンは、特にパフォーマンス面で大きなマイルストーンを達成しており、RustによるAI開発の新たな可能性を示すものとなっています。
本記事では、Burn v0.18.0で何が変わったのか、そしてなぜそれが重要なのかを、技術的な背景と共に詳しく解説していきます。
Burnとは? RustでAIをやるということ
Burnは、柔軟性、計算効率、移植性を最重要目標としてRustで構築された、次世代の総合的な動的ディープラーニングフレームワークです。
多くの既存フレームワークがPython(フロントエンド)とC++/CUDA(バックエンド)を組み合わせる「2言語問題」を抱えているのに対し、BurnはGPUカーネルの記述からモデル定義、トレーニング、推論まで、すべてをRustで完結できる点が最大の特徴です。これにより、シームレスな開発体験とエコシステム全体の健全性が実現されます。
主な特徴は以下の通りです。
- 複数バックエンド対応: WGPU(WebGPU)、CUDA、ROCmといったGPUバックエンドや、CPUバックエンド(tch - LibTorch、ndarray)を切り替えられます。これにより、NVIDIA、AMD、Apple Silicon、さらにはWebブラウザまで、真のクロスプラットフォーム展開が実現します。
- 柔軟性とパフォーマンスの両立: 動的グラフの書きやすさを維持しつつ、JIT(Just-In-Time)コンパイラによる最適化で静的グラフに迫るパフォーマンスを達成します。
- 豊富な機能: データセットAPI、変換(Augmentation)、トレーニング機能、ロギングなど、実用的なMLプロジェクトに必要な機能が標準で提供されています。
v0.18.0のハイライト:パフォーマンスの劇的な向上
v0.18.0の核心は、一言で言えばパフォーマンスの劇的な向上です。特に、フレームワークの心臓部である行列乗算(Matrix Multiplication, Matmul)と、演算を融合して最適化するFusion機能が大幅に強化されました。
マイルストーン1: 最先端のマルチプラットフォーム行列乗算カーネル
ディープラーニング、特にTransformerアーキテクチャでは、計算時間の大半が行列乗算に費やされます。つまり、行列乗算を高速化できれば、モデル全体のパフォーマンスが直接的に向上します。
従来、この領域はNVIDIAのcuBLASやCUTLASSといった高度に最適化されたライブラリの独壇場でした。しかし、これらは特定のハードウェア(NVIDIA GPU)にしか対応しておらず、柔軟性に欠けるという課題がありました。
Burnの開発チームは、この課題を解決するために、あえて行列乗算カーネルをゼロから独自実装するという困難な道を選びました。その成果が、v0.18.0で導入された新しい行列乗算エンジンです。
公式の技術ブログ「State-of-the-Art Multiplatform Matrix Multiplication Kernels」で公開されたベンチマークは衝撃的です。
![NVIDIA RTX 4080 (CUDA)でのベンチマーク]
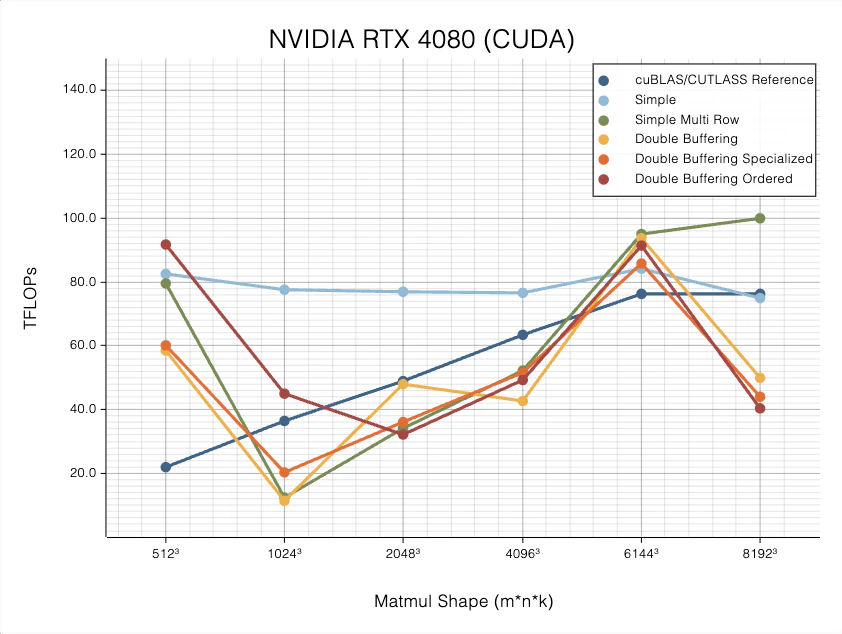
(出典: burn.dev)
上のグラフはNVIDIA RTX 4080 (CUDA)での性能を示していますが、Burnの独自実装(Simple, Simple Multi Rowなど)が、特定の条件下でcuBLAS/CUTLASSに匹敵、あるいはそれを上回る性能を達成していることがわかります。
さらに驚くべきは、この高性能なカーネルがCUDAだけでなく、Vulkan、ROCm、Metalといった複数のバックエンドに対応している点です。これにより、NVIDIA製GPUだけでなく、AMD製GPUやApple Silicon上でも、ハードウェアの性能を最大限に引き出すことが可能になりました。
なぜ独自実装が重要なのでしょうか?
その理由は、現代のAIワークロードにおけるボトルネックが、計算そのものからメモリへのデータ移動に移り変わっているからです。独自実装により、複数の計算処理を一つにまとめる「Kernel Fusion」を柔軟に行えるようになります。例えば、行列乗算の結果を一度グローバルメモリに書き出すことなく、そのまま次の活性化関数の計算に使うことで、無駄なメモリアクセスを徹底的に削減できるのです。
マイルストーン2: 動的グラフと静的グラフの融合
v0.18.0では、テンソルコンパイラエンジンも改良され、動的グラフを最適化する新しい検索メカニズムが導入されました。これにより、実行時に計算グラフの操作(演算の並べ替えや不要な計算の削除など)を自動で行い、最適化を最大化します。
これは、PyTorchのような動的グラフの書きやすさ・柔軟性と、TensorFlow(v1)のような静的グラフのパフォーマンスという、「いいとこ取り」を目指すBurnの設計思想を体現する重要なアップデートと言えるでしょう。
その他の主な改善点
- マルチスレッドとメモリ管理の安定性向上: CI(継続的インテグレーション)が拡張され、マルチスレッド環境での信頼性が向上しました。
-
CubeCLの設定機能: バックエンドエンジンであるCubeCLを、
cubecl.tomlファイルで細かく設定できるようなりました。 -
safetensorsフォーマットのサポート: Hugging Faceなどで広く使われている、安全で高速なモデル保存形式
safetensorsのインポートに対応しました。
なぜ今、Burnが重要なのでしょうか?
v0.18.0のリリースは、単なる機能追加以上の意味を持ちます。
-
「Rustでも戦える」から「Rustだからこそ勝てる」へ: これまで、RustでAIをやるメリットは主に安全性やメモリ効率の観点から語られることが多かったです。しかし、Burnの今回の成果は、パフォーマンスにおいても既存のC++/CUDAエコシステムに挑戦し、特定の領域では凌駕できることを示しました。これは、「Rustだからこそ実現できる、真にクロスプラットフォームで高性能なAI」という新たな地平を切り拓くものです。
-
エッジAIとWeb展開の加速: WGPUバックエンドの性能向上は、デスクトップGPUだけでなく、Webブラウザやエッジデバイス上でのAI推論の可能性を大きく広げます。プラットフォームごとにモデルやコードを書き換える必要なく、単一のRustコードベースから高性能なアプリケーションを展開できる未来が現実味を帯びてきました。
-
オープンなエコシステムへの貢献: 特定のハードウェアベンダーにロックインされることなく、オープンな標準(WGPU, Vulkan)の上で最先端のパフォーマンスを追求するBurnのアプローチは、AIインフラの未来にとって非常に重要です。
まとめ
Burn v0.18.0は、特にパフォーマンス面で目覚ましい進歩を遂げた画期的なリリースです。行列乗算カーネルの独自実装という大胆な挑戦により、クロスプラットフォームでありながら業界標準に匹敵する性能を達成したことは、RustのAI/ML分野における大きなブレークスルーと言えるでしょう。
もちろん、PyTorchやTensorFlowといった巨大なエコシステムに比べれば、Burnはまだ発展途上です。しかし、その根底にある思想、Rustという言語の持つポテンシャル、そして活発なコミュニティの存在は、BurnがAI開発の未来において重要な選択肢の一つとなることを強く予感させます。
RustでのAI開発に興味がある方は、ぜひこの機会にBurnのGitHubリポジトリを覗いてみてはいかがでしょうか。
参考リンク
- 公式リリースノート: Release v0.18.0 · tracel-ai/burn
- Redditでのアナウンス: Burn 0.18.0: Important performance milestones
- 技術ブログ(行列乗算について): State-of-the-Art Multiplatform Matrix Multiplication Kernels
- Burn公式サイト: https://burn.dev/