この記事は Qiita Advent Calendar 2025 - 時系列データ の10日目の記事です。
Day 4の記事では、統計的手法(Z-score、IQR、EWMA)を使って時系列データの異常検知を行いました。今回は ディープラーニング(LSTM) で同じデータを分析し、統計的手法と比較してみます。
なぜ Deep Learning?
時系列異常検知の研究分野では統計的手法から Deep Learning への移行が進んでいます。特に以下のようなケースで DL が優位とされています:
| データの特性 | 推奨手法 | 理由 |
|---|---|---|
| 多変量・高次元 | Deep Learning | センサー間の相関(空間的依存関係)を捉えられる |
| 単変量・周期的 | 統計的手法も有効 | DL の複雑さに見合わないケースも |
使用するデータ
今回もDay 4と同じく、GitHubのコントリビューション数を使います。
{
"daily_contributions": [
{"date": "2023-01-01", "count": 0},
{"date": "2023-01-02", "count": 3},
...
]
}
- 期間: 2023-01-01 〜 2025-12-08(約3年間)
- データ数: 1,073日分
- 特徴: 日によって0〜101の範囲で変動する時系列データ
今回のデータ(GitHubコントリビューション数)は 単変量 です。統計的手法に比べてDLが有利なデータではないですが、デモとしてご笑覧ください。
なぜ3年分?
Day 4では直近1年(約370日)のデータを使いましたが、今回は 3年分 に拡大しています。
ディープラーニングは統計的手法と比べてより多くのデータを必要とします。特にLSTMは時系列のパターンを学習するため、十分なサンプル数がないと汎化性能が低下します。
今回のデータ量:
- 1,073日 → シーケンス数 1,043(30日窓でスライド)
- Train: 834シーケンス、Test: 209シーケンス
これでも小規模ですが、デモとしては十分な結果が得られました。
データの取得
GitHubのGraphQL APIで取得できます。
gh api graphql -f query='
query {
user(login: "USERNAME") {
contributionsCollection(from: "2023-01-01T00:00:00Z", to: "2023-12-31T23:59:59Z") {
contributionCalendar {
weeks {
contributionDays {
date
contributionCount
}
}
}
}
}
}
'
なぜRustでディープラーニング?
Pythonが主流のディープラーニングですが、Rustでも Burn というフレームワークが登場しています。
BurnはPyTorchライクなAPIで、PyTorchに触れたことがあれば馴染みやすい構文です。PyTorchについて書かれた入門書などを読めば、Burnも理解できると思います。
さらに、Rustで書かれているため
- 型安全: コンパイル時にテンソルの次元エラーを検出
- 高速: ネイティブコードにコンパイル
また、
- バックエンド切替: CPU/GPU/WebGPUを同じコードで使える
という利点もあります
今回はBurn v0.18.0を使います。
LSTMとは
LSTM(Long Short-Term Memory)は、時系列データを扱うためのニューラルネットワークです。
Longなの?Shortなの?と混乱させるような名前ですが
- Short-Term Memory(短期記憶): 従来のRNNが持つ「隠れ状態」のこと
- Long: その短期記憶を「長く」保持できるようにした
つまり「長期的に保持できる 短期記憶」という意味です(Hochreiter & Schmidhuber, 1997)。
RNNの問題点
通常のRNN(再帰型ニューラルネットワーク)は、過去の情報を「隠れ状態」として次のステップに渡します。しかし、長い系列になると古い情報が薄れていく 勾配消失問題 が発生します。
シーケンス: [x_1] → [x_2] → [x_3] → ... → [x_T]
↓ ↓ ↓ ↓
h_1 → h_2 → h_3 → ... → h_T → 予測
問題: x_1 の情報が x_T まで届かない(勾配消失)
LSTMの解決策
LSTMは ゲート機構 を導入して、情報の流れを制御します。
┌─────────────────────────────────┐
│ Cell State │ ← 長期記憶(情報を保持)
└─────────────────────────────────┘
↑ ↑ ↓
[Forget Gate] [Input Gate] [Output Gate]
↑ ↑ ↓
─────────────────────────────────────
Hidden State → 出力
| ゲート | 役割 |
|---|---|
| Forget Gate | 古い情報を「忘れる」割合を決定 |
| Input Gate | 新しい情報を「記憶する」割合を決定 |
| Output Gate | 記憶から「出力する」情報を決定 |
Burn の LSTM 実装(burn::nn::lstm)では、このゲート機構が以下のように実装されています:
// 各ゲートの計算(sigmoid で 0〜1 に正規化)
let forget_values = activation::sigmoid(biased_fg_input_sum);
let add_values = activation::sigmoid(biased_ig_input_sum);
let output_values = activation::sigmoid(biased_og_input_sum);
let candidate_cell_values = biased_cg_input_sum.tanh();
// Cell State と Hidden State の更新(これがLSTMの本質)
cell_state = forget_values * cell_state.clone() + add_values * candidate_cell_values;
hidden_state = output_values * cell_state.clone().tanh();
最後の2行が LSTM の数式そのものです:
| 数式 | 意味 |
|---|---|
| $C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t$ | Cell State 更新:古い記憶を忘れ($f_t$)、新しい情報を追加($i_t$) |
| $h_t = o_t \odot \tanh(C_t)$ | Hidden State 更新:Cell State から出力を生成($o_t$) |
ここで $\odot$ は要素ごとの積(Hadamard積)を表します。各ゲートの値が 0〜1 の範囲なので、情報の流れを「どれだけ通すか」を制御できます。
長期記憶が可能な理由
通常のRNNとLSTMの違いを比較してみます:
通常のRNN:
h_1 → h_2 → h_3 → ... → h_T
毎ステップで h が変換され、x_1 の情報が徐々に消失(勾配消失)
LSTM:
C_1 → C_2 → C_3 → ... → C_T (Cell State: 長期記憶の「高速道路」)
h_1 → h_2 → h_3 → ... → h_T (Hidden State: 短期的な出力)
ポイントは Cell State の更新式です:
C_t = \underbrace{f_t \odot C_{t-1}}_{\text{古い記憶を保持}} + \underbrace{i_t \odot \tilde{C}_t}_{\text{新しい情報を追加}}
- $f_t$(Forget Gate)$\approx 1$ の場合:$C_{t-1}$ がほぼそのまま $C_t$ に引き継がれる
- $f_t \approx 0$ の場合:古い記憶を忘れ、新しい情報で置き換える
つまり、重要な情報に対して Forget Gate が高い値を維持すれば、Tステップ経っても情報が保持されます。これが「長期依存性を学習できる」というLSTMの強みです。
LSTMによる異常検知の原理
LSTMを使った異常検知のアプローチは主に2つあります:
| アプローチ | 原理 | 異常の判定 |
|---|---|---|
| 予測型(今回採用) | 過去のデータから次の値を予測 | 予測と実際の差が大きい |
| 再構成型 | 入力シーケンスを再構成 | 再構成誤差が大きい |
今回は、Malhotra et al. (2015) のアプローチを参考に、予測型 を採用しました。
論文との違い
元論文では複数ステップ先を予測し、誤差の多変量ガウス分布から最適な閾値を学習してます。本記事ではシンプルに「翌日1ステップ」の予測と、統計的な閾値(2σルール)を使用しています。
この簡略化は多くのチュートリアルや実装例で目にするアプローチです。本番運用では、複数ステップ予測や動的閾値の採用を検討するとよいでしょう。
スライディングウィンドウ
30日間のデータから翌日の値を予測します。
シーケンス0: [day1, day2, ..., day30] → 予測: day31
シーケンス1: [day2, day3, ..., day31] → 予測: day32
シーケンス2: [day3, day4, ..., day32] → 予測: day33
...
1,073日のデータから1,043個のシーケンスを作成し、80%を学習、20%をテストに使います。
異常検知の流れ
- 学習済みモデルで翌日の値を予測
- 予測値と実際の値の差(予測誤差)を計算
- 予測誤差が閾値(平均 + 2σ)を超えたら異常と判定
実装
モデル定義(model.rs)
use burn::prelude::*;
use burn::nn::lstm::{Lstm, LstmConfig};
use burn::nn::{Linear, LinearConfig};
#[derive(Module, Debug)]
pub struct LstmPredictor<B: Backend> {
lstm: Lstm<B>,
linear: Linear<B>,
d_hidden: usize,
}
impl<B: Backend> LstmPredictor<B> {
pub fn forward(&self, input: Tensor<B, 3>) -> Tensor<B, 2> {
let [batch_size, seq_len, _] = input.dims();
// LSTM層で時系列を処理
let (lstm_output, _) = self.lstm.forward(input, None);
// 最後のタイムステップの出力を取得
let last_output = lstm_output
.slice([0..batch_size, (seq_len - 1)..seq_len, 0..self.d_hidden])
.reshape([batch_size, self.d_hidden]);
// Linear層で予測値を出力
self.linear.forward(last_output)
}
}
Burn の LSTM インターフェース
burn::nn::lstm::Lstm の入出力を整理します。
入力:
input: Tensor<B, 3> // [batch_size, seq_len, d_input]
state: Option<LstmState<B, 2>> // 初期状態(None で零初期化)
| 次元 | 意味 | 今回の値 |
|---|---|---|
| batch_size | 同時処理するサンプル数 | 32 |
| seq_len | シーケンス長(過去何日分か) | 30 |
| d_input | 入力特徴量の数 | 1(単変量) |
出力:
(output, final_state) = lstm.forward(input, state)
| 出力 | 形状 | 説明 |
|---|---|---|
| output | [batch, seq_len, d_hidden] |
各タイムステップの隠れ状態 |
| final_state | LstmState { hidden, cell } |
最終タイムステップの状態 |
データの流れ:
LSTMへの入力: [32, 30, 1] ← 32サンプル × 30日 × 1特徴量
↓
LSTM (d_hidden=64)
↓
LSTMの出力: [32, 30, 64] ← 各日の隠れ状態(64次元)
↓
最後のステップを取得
↓
[32, 64] ← 30日目の隠れ状態のみ
↓
Linear (64 → 1)
↓
[32, 1] ← 翌日の予測値
- LSTM: hidden_size=64
-
出力:
[batch_size, 1](翌日の予測値)
学習ループ(train.rs)
use burn::optim::{AdamConfig, GradientsParams};
let learning_rate = 0.001;
let mut optim = AdamConfig::new().init();
for epoch in 1..=num_epochs {
for batch in train_batches {
// 順伝播
let output = model.forward(batch.sequences);
// MSE (Mean Squared Error): 予測値と実際の値の二乗誤差の平均
let loss = MseLoss::new().forward(output, batch.targets, Reduction::Mean);
// 逆伝播
let grads = loss.backward();
let grads = GradientsParams::from_grads(grads, &model);
model = optim.step(learning_rate, model, grads);
}
}
SGD と Adam
適応的手法として1950年代に提案されたSGD(Stochastic Gradient Descent)は現在も使われますが、Adam(Adaptive Moment Estimation, 2014年)などが主流になっています。
異常検知
const BATCH_SIZE: usize = 64;
// バッチ処理でGPU効率を最大化
for chunk in dataset.items.chunks(BATCH_SIZE) {
let batch = batcher.batch::<B>(chunk.to_vec(), device);
let output = model.forward(batch.sequences);
// 予測誤差を計算
let error = (actual - predicted).abs();
}
// 閾値: 平均 + 2σ(2σルール)
let threshold = mean_error + 2.0 * std_error;
閾値の決め方
Malhotra et al. (2015) では検証用データセットを用いて最適な閾値を探索しますが、今回は簡易的に 2σ (シグマ) ルール(平均 + 2標準偏差)を閾値として採用しています。正規分布を仮定すると、約95%のデータがこの範囲に収まります。
結果
学習まとめ
| 項目 | 値 |
|---|---|
| データ期間 | 2023-01-01 〜 2025-12-08(1,073日) |
| シーケンス数 | 1,043(Train: 834, Test: 209) |
| エポック数 | 50 |
| 最終Train Loss | 0.0026 |
| 最終Test Loss | 0.017 |
検出結果
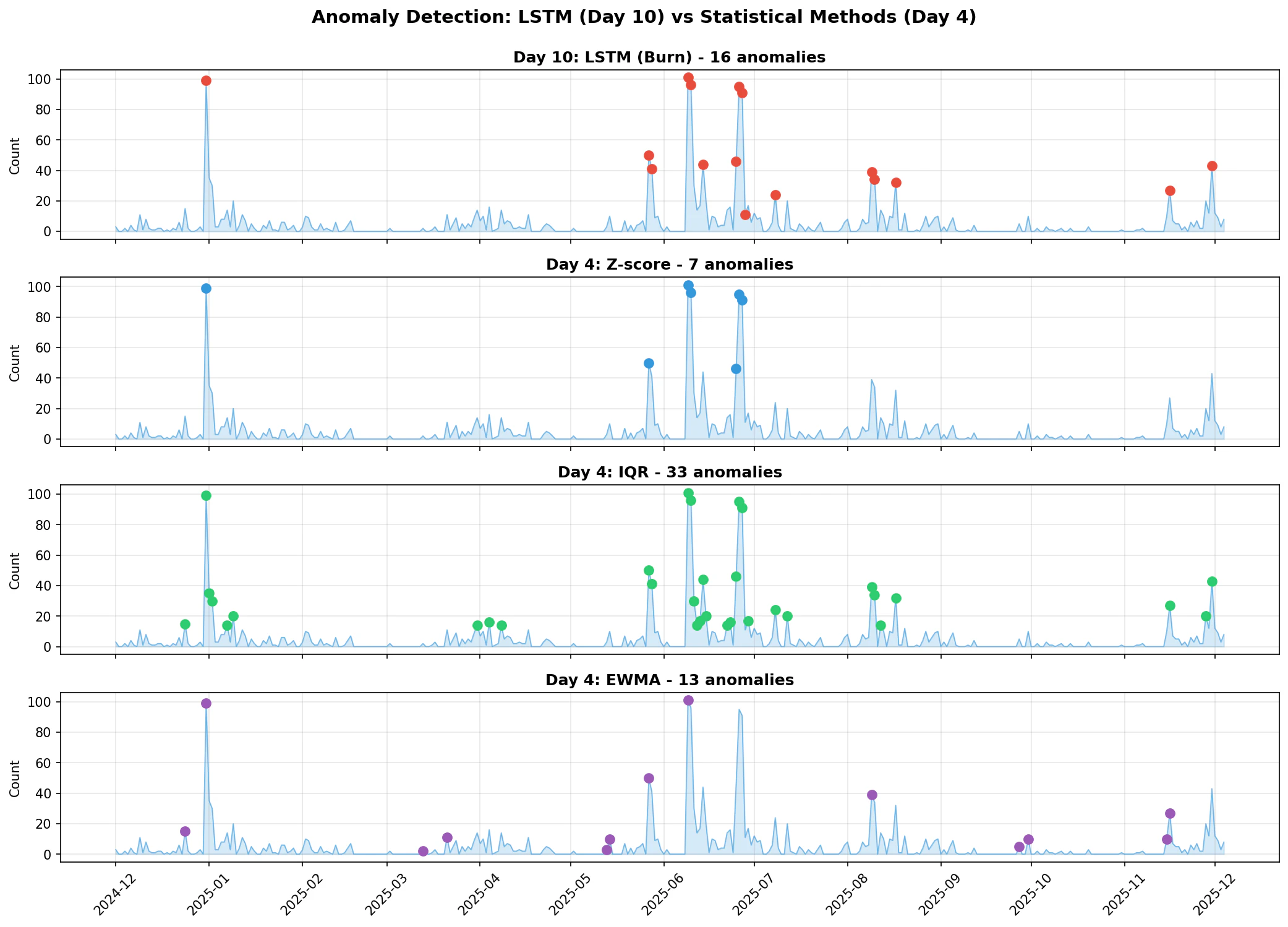
LSTM vs 統計的手法(同一期間での比較):
| 手法 | 検出数 | 特徴 |
|---|---|---|
| LSTM | 16 | スパイクを検出 |
| Z-score | 7 | 極端な値のみ |
| IQR | 33 | 幅広く検出 |
| EWMA | 13 | 急激な変化を検出 |
LSTMはZ-scoreとIQRの中間くらいの検出数で、バランスの取れた結果に見えます。しかし、Day 4で述べた通り異常値検出はヒューリスティックで、目的の異常を検出するためにはパラメータの調整が必要です。IQRは原理が理解しやすく調整しやすいのに対し、LSTMは解釈困難で、パラメータを変えても検出結果がどう変わるか予測しにくいという課題があります。
今回は 単変量 であり、Deep Learningに向いていないデータでした。
Deep Learningが真価を発揮するのは:
- 多変量: 複数センサー間の相関を捉える必要がある場合
- 高次元: 特徴量が多く、人手で閾値設定が困難な場合
- 非線形: 統計的仮定(正規分布など)が成り立たない場合
単変量・周期的なデータであれば、統計的手法で十分なケースが多い でしょう。
まとめ
RustのBurnフレームワークでLSTM異常検知を実装してみました。厳密に型づけられたRustで書かれているため、ソースコードまで辿るのが容易で、ニューラルネットワークの学習にも適していると思います。
今回はLSTMに向いていない単変量のデータを使ったためその真価を十分には感じられませんでしたが、逆に統計的手法の明快さなど良さを改めて感じました。次の機会には多変量のデータでLSTMを試してみたいです。
参考
- Burn - Rust Deep Learning Framework
- Day 4: 統計的手法による異常検知
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation
- Malhotra, P., et al. (2015). Long Short Term Memory Networks for Anomaly Detection in Time Series. ESANN 2015
明日の時系列データ Advent Calendarは @gorn708 さんです!