GitHub で +5.7k スターを集めている Microsoft 製の変換ツール markitdown。これ、実際の現場でどこまで通用するのか気になったので、ブラウザだけで完結する Python 環境「fudebako」を使って、PDF や Office 文書、画像までガッツリ検証してみました。
LLM の前処理として導入を考えているなら、知っておくべき「変換の限界」があります。今回は、業務 PC に Python を入れられない環境でも再現可能な、リアルな検証結果をまとめます。
はじめに:この記事でわかること
- LLM に PDF や Office 文書を食わせる前の前処理として
markitdownは実用的なのか - 業務 PC で Python が動かせない環境での現実的な環境構築法
- 実際の提案書や報告書を変換した時のリアルな評価
検証はすべて fudebako(HTML 1 ファイルで動く Python 環境、機内モード OK)の上で行いました。手元で同じ手順をすぐ再現できるはずです。
1. markitdown とは
microsoft/markitdown は、様々なファイルを Markdown に統一変換する Microsoft 製のライブラリです。PDF や Office 文書、画像などを一括で Markdown 化できる手軽さから、RAG 構築界隈で急速に注目を集めています。
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("doc.pdf")
print(result.text_content)
公式の対応形式は以下のとおりです(公式 README より)。
- PDF, PowerPoint, Word, Excel
- 画像(EXIF メタデータ + OCR)
- 音声(EXIF メタデータ + 文字起こし)
- HTML, テキスト系(CSV, JSON, XML)
- ZIP, Outlook メッセージ, EPub
- YouTube URL
2. 検証環境 — fudebako で動かす
通常は pip install markitdown で環境を作りますが、業務 PC だとそうもいきません。そこで fudebako の出番です。リリースページから HTML を落として開くだけ(v0.3.3 で約 100 MB)。
v0.3.3 には pandas や pdfplumber、Pillow など主要なライブラリが同梱されているので、%pip install markitdown を叩くだけで PDF や DOCX 変換まで即座に動き出します(XLSX は markitdown[xlsx] で openpyxl を追加)。
ドライブタブにファイルをアップロードすれば、ブラウザ上でプレビューも可能です。
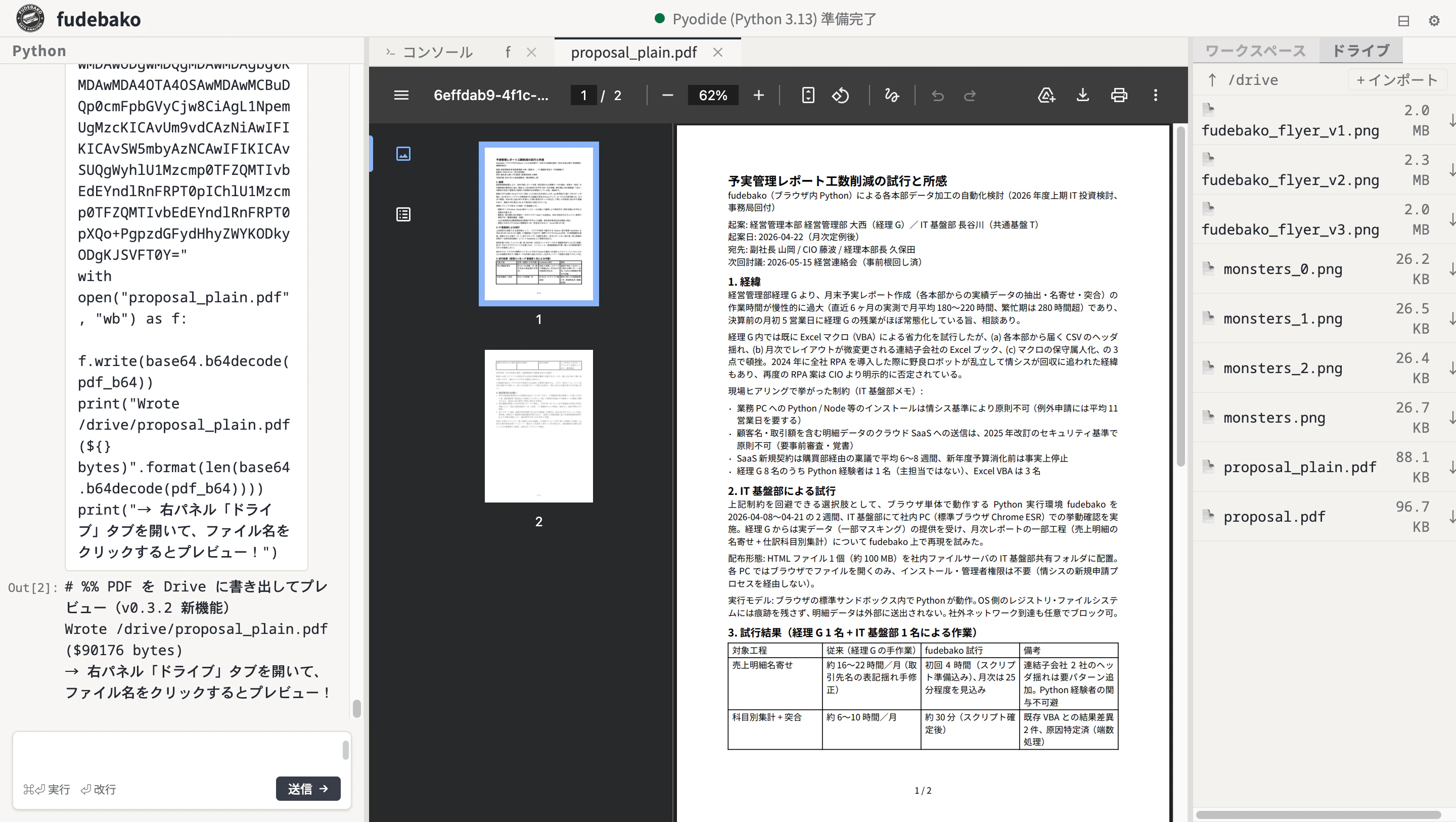
変換前に「元のレイアウトがどうなっているか」を視覚的に確認できるのはかなり便利。一連の流れはこんな感じです。
3. 動く形式 — HTML / CSV / XLSX
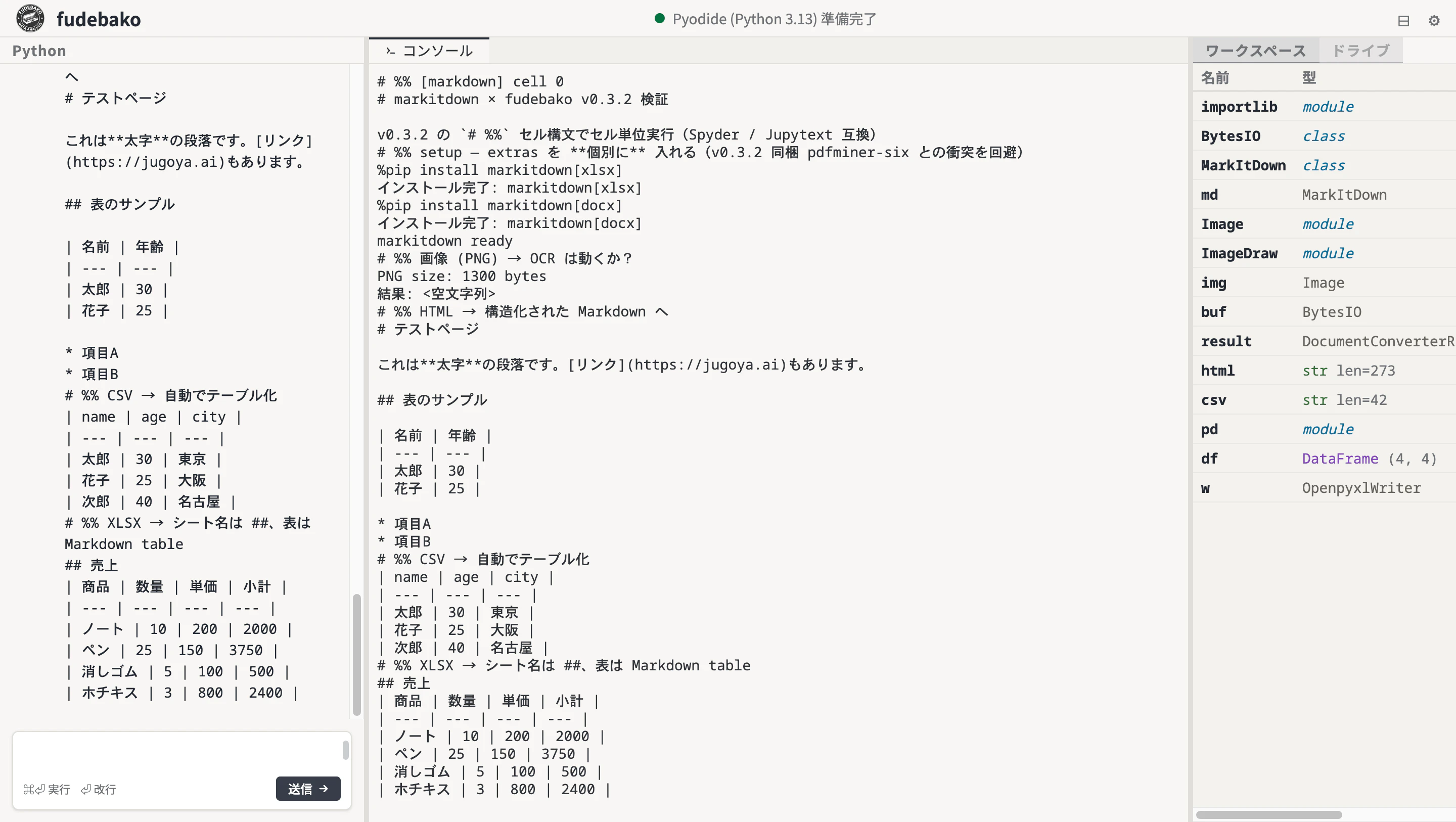
ここからが検証の本題。実際に各形式を変換した結果を見ていきます。
fudebako で画像 / HTML / CSV / XLSX を順次実行した様子がこちら。左パネルに変換結果が次々と出力されるので、挙動の違いが掴みやすいです。
3-1. HTML — もっとも素直に動く
<h1>/<h2> は #/## に、<table> は Markdown table に、<ul> はリストに、<a> はリンクに変換されます。これらは標準機能だけで綺麗に落ちてきます。
html = """<html><body>
<h1>テストページ</h1>
<p>これは<b>太字</b>の段落です。<a href="https://jugoya.ai">リンク</a>もあります。</p>
<h2>表のサンプル</h2>
<table>
<tr><th>名前</th><th>年齢</th></tr>
<tr><td>太郎</td><td>30</td></tr>
</table>
<ul><li>項目A</li><li>項目B</li></ul>
</body></html>"""
print(md.convert_stream(BytesIO(html.encode()), file_extension=".html").text_content)
# テストページ
これは**太字**の段落です。[リンク](https://jugoya.ai)もあります。
## 表のサンプル
| 名前 | 年齢 |
| --- | --- |
| 太郎 | 30 |
* 項目A
* 項目B
3-2. CSV — 自動でテーブル化
CSV を投げると、ヘッダ行を含めて Markdown table に変換されます。日本語も問題ありません。
csv = "name,age,city\n太郎,30,東京\n花子,25,大阪\n次郎,40,名古屋\n"
print(md.convert_stream(BytesIO(csv.encode()), file_extension=".csv").text_content)
| name | age | city |
| --- | --- | --- |
| 太郎 | 30 | 東京 |
| 花子 | 25 | 大阪 |
| 次郎 | 40 | 名古屋 |
3-3. XLSX — シート名が見出しに、表が table に
Excel は markitdown[xlsx] が必須です。シート名が ## シート名 の見出しになり、各シートの構造が Markdown table として出力されます。書式(色やフォント、セル結合)は全て消えますが、データ値とテーブル構造自体はしっかり残ります。
import pandas as pd
df = pd.DataFrame({
"商品": ["ノート", "ペン", "消しゴム", "ホチキス"],
"数量": [10, 25, 5, 3],
"単価": [200, 150, 100, 800],
})
df["小計"] = df["数量"] * df["単価"]
buf = BytesIO()
with pd.ExcelWriter(buf, engine="openpyxl") as w:
df.to_excel(w, index=False, sheet_name="売上")
buf.seek(0)
print(md.convert_stream(buf, file_extension=".xlsx").text_content)
## 売上
| 商品 | 数量 | 単価 | 小計 |
| --- | --- | --- | --- |
| ノート | 10 | 200 | 2000 |
| ペン | 25 | 150 | 3750 |
| 消しゴム | 5 | 100 | 500 |
| ホチキス | 3 | 800 | 2400 |
内部的には pandas.read_excel で読み込んで HTML 化する仕組みです。Excel の数式は計算結果のみが抽出される点には注意してください。
4. 部分的に動く形式 — PDF(プレーン 1 段組)
ここから雲行きが怪しくなります。まずは、ごく普通の「1 段組 PDF」。
左が元の PDF、右が変換後の Markdown です。

動くもの:
- 段落本文のテキスト(折り返しは維持)
-
•箇条書きと1. 2. 3.番号付きリスト - 「key: value」形式の単行情報
動かないもの:
-
見出しが Markdown の
#に変換されない — 「1. 経緯」のような見出しも単なるプレーンテキストとして出力される - テーブル: pdfplumber がセル単位で分割するため、Markdown table としては再構成されない。各セルの内容がただ縦に並ぶだけ
- footer: ページ番号が本文に混入する
PDF の変換エンジンは pdfplumber + pdfminer.six です。テキスト層を持たない「スキャン PDF」は完全に空の文字列が返ります。OCR のフォールバックは期待してはいけません。
5. 動かない形式 — 装飾された業務 PDF
検証していて一番ショックだったのがこれです。提案書や企画書など、いわゆる「会社で見る PDF」を投げると、無残な結果になるケースが多いです。

実例で起きた崩壊パターン:
- 2 列レイアウトが崩壊 — 左右の行が物理的に連結される。「HTML ファイル 1 個(約 100 MB)を社内ファイルサー ブラウザの標準サンドボックス内で...」のように、カラムを跨いで 1 行として連結されるため読解不能。
- table の行ズレ — セル内改行を別行と見なすため、データがバラバラに散る。
- ヘッダーバナーの無視 — 背景色付きのタイトル領域も、ただのプレーンテキストとして扱われ、見出し化されない。
- grid 構造の分断 — 4 列の key-value がテキスト折り返しでバラバラになる。
- footer の誤認 — 2 ページ目だけ「5 列テーブル」として誤認識されるなど、ノイズが混入する。
これは markitdown の責任というより、pdfplumber が複数列レイアウトを構造として認識できないのが原因です。装飾された業務資料は、安易に投げ込むと手動修正が必須になるレベルです。
6. 動かない形式 — 画像(OCR 機能はない)
「画像対応」と聞くと OCR を期待しますが、markitdown 単体にはローカル OCR 機能はありません。
PIL で「Hello, fudebako!」と描画した PNG を渡してみましたが、結果は空でした。
from PIL import Image, ImageDraw
img = Image.new("RGB", (400, 100), "white")
ImageDraw.Draw(img).text((20, 30), "Hello, fudebako!", fill="black")
buf = BytesIO(); img.save(buf, "PNG"); buf.seek(0)
result = md.convert_stream(buf, file_extension=".png")
print(repr(result.text_content))
# → ''
_image_converter.py を見ると、画像変換は EXIF メタデータの抽出のみ。本格的な OCR を使うには、OpenAI 互換の LLM client を渡す必要があります。
# OCR したいなら LLM client を渡す必要がある
md = MarkItDown(llm_client=openai_client, llm_model="gpt-4o-mini")
ちなみに、markitdown はファイル判定に Google 製の magika を使っており、これは ONNX Runtime に依存します。「ONNX があるなら OCR も?」と期待しましたが、ONNX はファイル判定用であって OCR には使われていません。
7. 動かない形式 — JSON
JSON も専用 converter はなく、そのまま出力されます。LLM に渡す分には困りませんが、テーブル化などはされません。
json_content = '{"users":[{"name":"太郎","age":30},{"name":"花子","age":25}]}'
print(md.convert_stream(BytesIO(json_content.encode()), file_extension=".json").text_content)
# → '{"users":[{"name":"太郎","age":30},{"name":"花子","age":25}]}'
ネストされた JSON を見やすい表にしたければ、pandas.json_normalize 等で整形してから XLSX に変換して渡すなどの工夫が必要です。
8. 結論:用途別の使い分け
今回の検証で感じた、現実的な使い分けは以下の通りです。
| 用途 | 評価 |
|---|---|
| HTML / CSV を LLM 用に整形 | ◎ そのまま使える |
| Excel の数値テーブルを Markdown 化 | ◎ 値だけ欲しいならベスト |
| Word の文書を Markdown 化 | ○ 段落・見出しは保持 |
| 1 段組のテキスト PDF を Markdown 化 | △ 段落 OK、表は崩れる、見出し化なし |
| 装飾された業務 PDF を Markdown 化 | ✗ 多段組・装飾は崩壊する。手動補完前提 |
| スキャン PDF / 画像内テキスト | ✗ OCR 機能ゼロ。LLM Vision API が必要 |
LLM の RAG 前処理として「とりあえず雑に Markdown 化する」用途には強力ですが、「PDF なら何でも綺麗になる」という過度な期待は禁物です。装飾が多い PDF は、変換結果をそのまま LLM に投げる前に、一度人間が目を通さないと事故ります。
おまけ — 検証コード全部入り
ここまで紹介したコードをまとめました。fudebako v0.3.3 を落として開き、コピペすればそのまま動きます。
# %% setup
%pip install markitdown[xlsx]
%pip install markitdown[docx]
from io import BytesIO
from markitdown import MarkItDown
md = MarkItDown()
# %% 画像 (PNG) — OCR は動くか?
from PIL import Image, ImageDraw
img = Image.new("RGB", (400, 100), "white")
ImageDraw.Draw(img).text((20, 30), "Hello, fudebako!", fill="black")
buf = BytesIO(); img.save(buf, "PNG"); buf.seek(0)
print("OCR result:", repr(md.convert_stream(buf, file_extension=".png").text_content))
# %% HTML
html = """<html><body>
<h1>テストページ</h1>
<p>これは<b>太字</b>の段落です。<a href="https://jugoya.ai">リンク</a>もあります。</p>
<h2>表のサンプル</h2>
<table><tr><th>名前</th><th>年齢</th></tr>
<tr><td>太郎</td><td>30</td></tr></table>
</body></html>"""
print(md.convert_stream(BytesIO(html.encode()), file_extension=".html").text_content)
# %% CSV
csv = "name,age,city\n太郎,30,東京\n花子,25,大阪\n"
print(md.convert_stream(BytesIO(csv.encode()), file_extension=".csv").text_content)
# %% XLSX
import pandas as pd
df = pd.DataFrame({"商品": ["ノート", "ペン"], "数量": [10, 25], "単価": [200, 150]})
df["小計"] = df["数量"] * df["単価"]
buf = BytesIO()
with pd.ExcelWriter(buf, engine="openpyxl") as w:
df.to_excel(w, index=False, sheet_name="売上")
buf.seek(0)
print(md.convert_stream(buf, file_extension=".xlsx").text_content)
参考リンク
検証は 2026-04-27 時点、markitdown は最新版、fudebako v0.3.3 で実施しました。