以前、CSVファイルからTableau hyperファイルにPostgreSQLライクなCOPYコマンドで一括インサートする方法を投稿しましたが、今回は作成したhyperファイルで既存のtwbxファイル(Tableauパッケージドワークブック)のデータソースを更新する方法を紹介します。
なお、通常、twbxファイルのデータソースを更新する場合はTableau Desktopを開いてGUI操作する必要があります。
https://help.tableau.com/current/pro/desktop/ja-jp/save_savework_packagedworkbooks.htm
しかし、更新対象のパッケージドワークブックやデータソースが増えると非常に手間がかかるので、今回のようにCUIで更新するのが良いでしょう。
環境
- Python 3.7.6
- Tableau Desktop 2019.2.0
そもそもパッケージドワークブック(twbxファイル)とは
本題に入る前に、twbxファイルとはいったい何なのかを説明します。
結論から言うと、twbxファイルはtwbファイル(Tableauワークブック)とデータソース(hyperファイル)をzip圧縮したファイルです。
実際にtwbxファイルの中身を確認してみましょう。
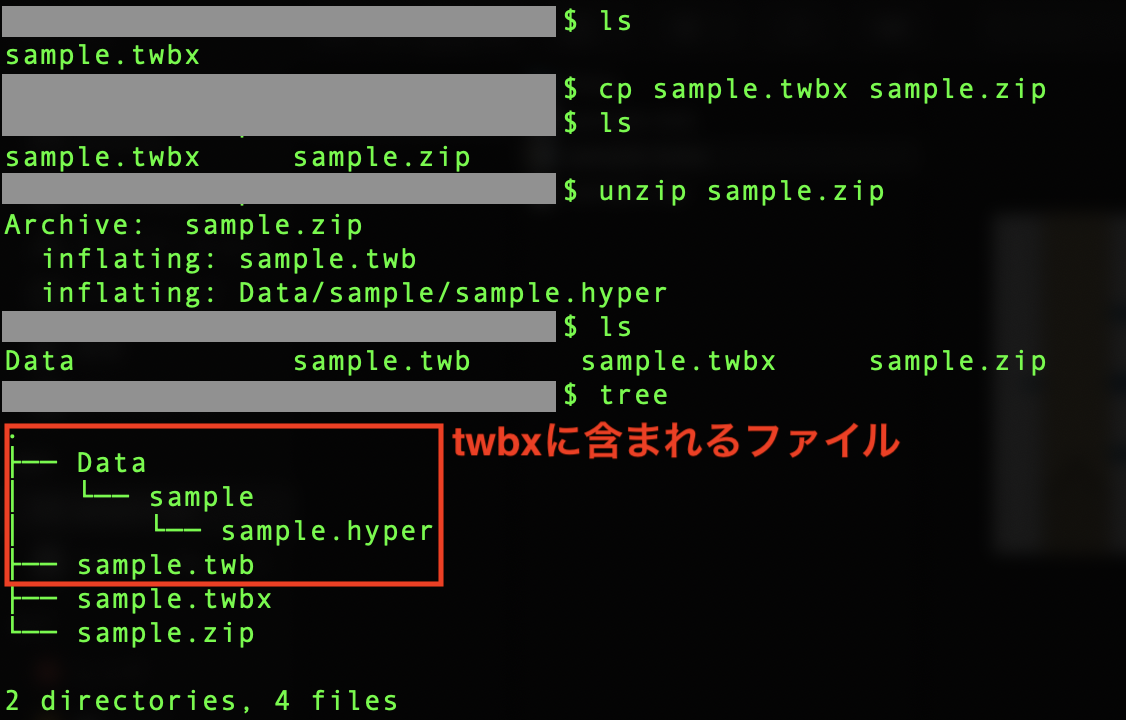
sample.twbxにsample.twbとData/sample/sample.hyperが含まれていることが分かります。
なので、逆に言えば、twbファイル(Tableauワークブック)とデータソース(hyperファイル)を適切なディレクトリ構造でzip圧縮すればtwbxファイルになるということです!
以下、このアイディアをもとに実装していきます。
準備
ディレクトリ構造
以下のディレクトリで実装していきます。
.
├── conf
│ └── update_conf.csv
├── input
│ ├── sales.csv
│ └── titanic.csv
├── output
│ ├── sales.hyper
│ └── titanic.hyper
├── src
│ └── update_twbx.py
├── twbx
│ └── sample.twbx
└── work
更新対象のtwbxファイルを.twbx/に配置
更新対象のtwbxファイル(sample.twbx)を.twbx/に配置します。
sample.twbxは2つのデータソース(hyperファイル)を参照して作られています。
なお、データソースはKaggleでお馴染みのTitanic(train.csv)とPredict Future Sales(sales_train.csv)です。
分かりやすいように、以下にファイル名をリネームしています。
- train.csv → titanic.csv
- sales_train.csv → sales.csv
更新したいデータソース(hyper)を.output/に配置
更新したいデータソース(hyperファイル)を.output/に配置します。
配置するファイルに関して以下に注意してください。
- 既存のtwbxが参照しているhyperファイルと同一であること
- 既存のtwbxが参照しているhyperファイルを漏れなく配置すること
更新設定を.conf/update_conf.csvに記載
以下を設定ファイル(.conf/update_conf.csv)に記載します。
- 更新対象のデータソース(hyper)が存在するディレクトリ
- 更新対象のパッケージドファイルパス(twbx)
- 更新先のパッケージドファイルパス(twbx)
datasource,update_target_twbx,create_target_twbx
./output,./twbx/sample.twbx,./twbx/output.twbx
スクリプト実装
準備後、Pythonスクリプトを実装します。
以下の処理フローを実装します。
- 更新対象のtwbxファイルを
./workにzip解凍 - データソースを更新対象で置換
- twbファイルとデータソースをzip圧縮
import csv
import zipfile
import os
import glob
import re
import shutil
work_dir = './work'
twbx_dir = './twbx'
# 更新対象のtwbxファイルパスを取得
with open('./conf/update_conf.csv') as f:
reader = csv.reader(f)
next(reader)
line_list = [row for row in reader]
for replace_dir, update_from, update_to in line_list:
# 更新対象のtwbxをwork dirに解凍
with zipfile.ZipFile(update_from) as existing_zip:
existing_zip.extractall(work_dir)
# twbx内のtwbファイル名を取得
for file_name in os.listdir(work_dir):
if 'twb' in file_name:
twb_file_name = file_name
twb_file_path = os.path.join(work_dir, twb_file_name)
# twbx内のhyperファイル格納dir
data_dir_regexp = os.path.join(work_dir, 'Data/*/*.hyper')
# twbx内のhyperファイルリストを取得
data_file_list = glob.glob(data_dir_regexp)
data_file_dict = {}
for data_file_path in data_file_list:
data_file_dict[re.sub(r'^.*/', '', data_file_path)] = data_file_path
replace_file_dict = {}
for replace_file_path in glob.glob(f'{replace_dir}*.hyper'):
replace_file_dict[re.sub(r'^.*/', '', replace_file_path)] = replace_file_path
# twbxに含まれるデータソースを更新
for key in data_file_dict.keys():
shutil.copy2(data_file_dict[key], replace_file_dict[key])
with zipfile.ZipFile(update_to, 'w', compression=zipfile.ZIP_DEFLATED) as new_zip:
new_zip.write(twb_file_path, arcname=twb_file_name)
for data_file_path in data_file_list:
data_file_name = re.sub(r'^.*/', '', data_file_path)
new_zip.write(data_file_path, arcname=data_file_name)
実行
以下を実行することで、パッケージドワークブックが更新できます。
python src/update_twbx.py
実行後、update_twbx_list.csvで指定した場所に更新済みのtwbxファイルが作られていることを確認でました!
最後に
今回はtwbxファイルをzip解凍してできたディレクトリ構造をそのまま踏襲しましたが、解凍後のtwbファイルのdatasourceタグを編集することで、任意のディレクトリにデータソースを配置することができます。
twbファイルの編集に関してはTableau Desktop(twbファイル)のDB接続情報をPythonで書き換える方法で紹介しています。