訳あってTableauSDKのAPIリファレンスを見ていたところ、以下のような記載があってビックリしました。
Insert Data Directly from CSV Files
なんでも、PostgreSQLライクなCOPYコマンドを使って高速にTableau独自のデータ形式であるhyperファイルにレコードをインサートできるとのこと。
数年前にTableau Readerを定期的に配布するためにCSVファイルからtdeファイルを作成する処理を実装したことがあるのですが、SDKの仕様上、レコード単位でのインサートになるため大量データの処理にはかなり時間がかかった印象があります。
しかし、COPYコマンドでダイレクトにインサートできれば大量データでもサクッとTableauの独自ファイル(ここではhyper)を作れそうです。
今回はKaggleのTitanicデータセットの学習データ(CSVファイル)をCOPYコマンドを使ってhyperファイルにインサートしてみます。
コードはこちら
https://github.com/yolo-kiyoshi/csv2hyper
前提
- Mac OS Catalina 10.15.3
- Python 3.7
- tableauhyperapi 0.0.9746
API一式はpip install tableauhyperapiでインストールできます。
ディレクトリ構成
以下のディレクトリで実行しています。
.hyperファイルはdata/配下に作成されます。
.
├── data
│ └── train.csv # Titanic train
└── notebook
└── insert_test.ipynb
実装コード
まず、I/Oファイルを定義します。
# インサート元のCSVファイルパス
src_path = '../data/train.csv'
# 作成したいhyperファイルパス
dist_path = '../data/train.hyper'
次に、COPYコマンドでCSVからhyperにインサートします。
荒い説明ですが、「①hyperファイルを処理するセッションを作り」、「②仮想的にPostgreSQLライクなテーブルを作って」、「③CSVファイルから一括インサートし」、「④hyperファイルにテーブルごと吐き出す」感じです。
from tableauhyperapi import HyperProcess, Telemetry, Connection, CreateMode, NOT_NULLABLE, NULLABLE, SqlType, TableDefinition, escape_string_literal
# Hyperファイルを扱うためのセッションを作成
with HyperProcess(telemetry=Telemetry.SEND_USAGE_DATA_TO_TABLEAU) as hyper:
with Connection(
endpoint=hyper.endpoint,
database=dist_path,
create_mode=CreateMode.CREATE_AND_REPLACE
) as connection:
# テーブルを定義
table_def = TableDefinition(
table_name='train',
columns=[
TableDefinition.Column("PassengerId", SqlType.big_int(), NOT_NULLABLE),
TableDefinition.Column("Survived", SqlType.big_int(), NOT_NULLABLE),
TableDefinition.Column("Pclass", SqlType.big_int(), NOT_NULLABLE),
TableDefinition.Column("Name", SqlType.text(), NOT_NULLABLE),
TableDefinition.Column("Sex", SqlType.text(), NOT_NULLABLE),
TableDefinition.Column("Age", SqlType.double(), NULLABLE),
TableDefinition.Column("SibSp", SqlType.big_int(), NOT_NULLABLE),
TableDefinition.Column("Parch", SqlType.big_int(), NOT_NULLABLE),
TableDefinition.Column("Ticket", SqlType.text(), NOT_NULLABLE),
TableDefinition.Column("Fare", SqlType.double(), NULLABLE),
TableDefinition.Column("Cabin", SqlType.text(), NULLABLE),
TableDefinition.Column("Embarked", SqlType.text(), NULLABLE)
]
)
# テーブル定義をもとに仮想的にテーブル作成(default schemaはpublic)
connection.catalog.create_table(table_def)
# PostgreSQLライクにCOPYコマンドを実行
record_count = connection.execute_command(
command=f'''
COPY {table_def.table_name} from {escape_string_literal(src_path)} with (format csv, delimiter ',', header)
'''
)
print(f"The number of rows in table {table_def.table_name} is {record_count}.")
The number of rows in table "train" is 891.
処理後、data/train.hyperをTableauで見てみると...
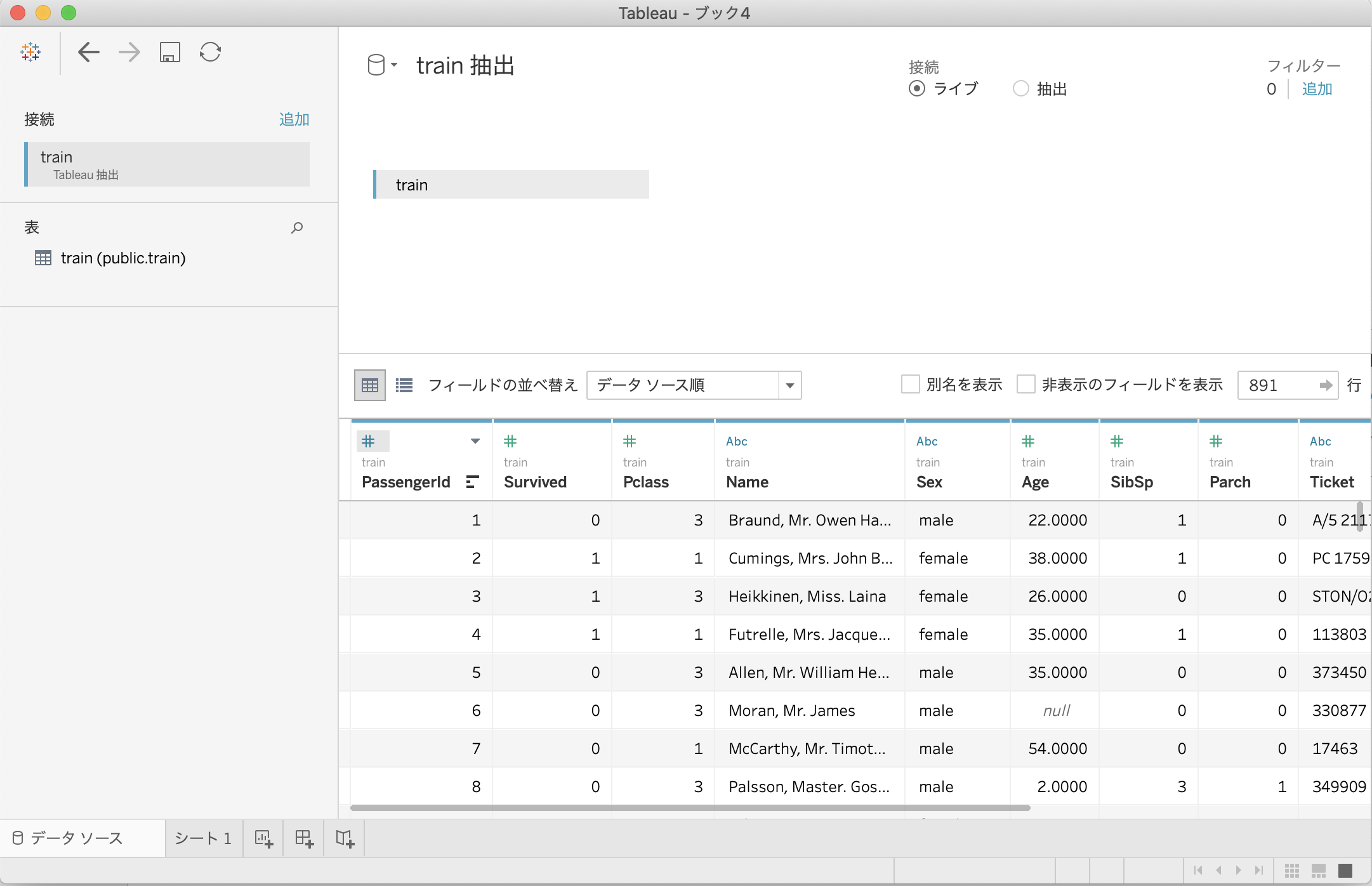
無事にhyperファイルを作成できていることを確認できました!
最後に
TableauSDKがここまで進化しているとは...感動しました。
Tableau Desktop、Tableau Serverをメインに利用している場合はhyperファイルを使う機会は滅多にないと思いますが、何らかの事情でTableau Readerなどを使ってレポートを配布しなければならないのであれば、かなり重宝するでしょう。
参考