◎20190121情報追記:最新のPython3.7系だとExceptionが発生しないようです。Python3.6系だと以下のコードで動作します。
pandas.io.gbqは複雑な認証が不要で、プロジェクトIDだけでGoogle BigQuery(以下、BQと略します)を操作できます。
本ページでは、Pythonのpandas.io.gbq.read_gbqを使ってBQのテーブルを洗い替る方法を説明します。
なお「洗い替え」は、DELETE実行後にSELECT結果をINSERTすることと定義します。
pandas.io.gbqの標準的な使い方は以下に詳しくまとめられていると思います。
Python使いのためのBigQuery連携
なぜデータアップロード用のpandas.io.gbq.to_gbqを使わないのか?
そもそもread_gbqはSELECT結果をpandas.DataFrameに格納するメソッドであって、BQにデータをappendしたいならばto_gbqを使えば良いではないかと思われるかもしれません。
しかしこの場合だと、洗い替えするためにはBQからread_gbqを使ってデータをDataFrameに変換・保持した後に、to_gbqでBQにDataFrameをappendすることになります。
1万行に満たないような少量のレコード数ならばこれでも問題ありませんが、1000万行を超えた場合にはread_gbqでBQからデータを取得してDataFrame変換するのにかなり時間がかかってしまいます。
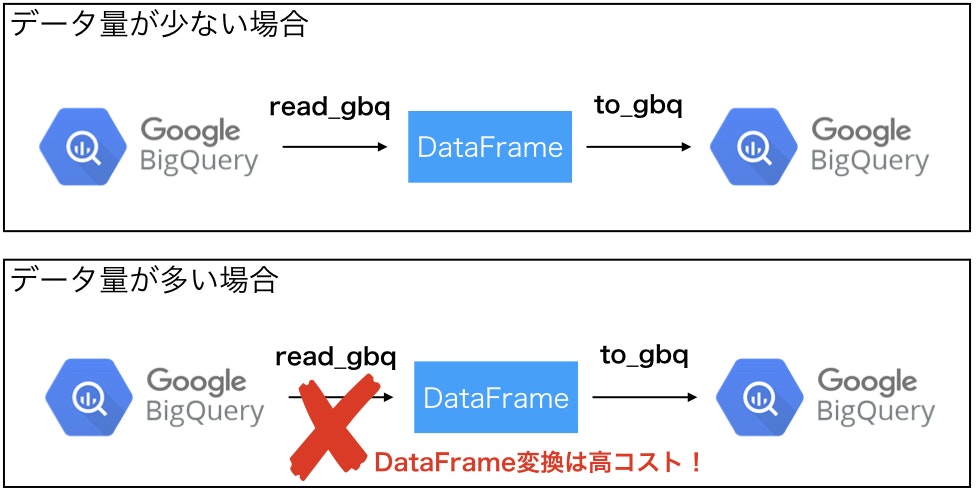
ここでヒントになるのが、read_gbqの実装ロジックが、BQのwebコンソール画面でのクエリ実行とほぼ同じということです。
ためしに、BQのwebコンソール上でSELECT結果をINSERTするクエリを実行すると高速に処理できるのがわかると思います。
いちいちBQからのデータ取得結果をDataFrameに変換・保持することなく、read_gbqを使って擬似的にwebコンソール上でのクエリ実行と同じ動きをさせようと試みました。
実装アイディア
pandas.DataFrameを介することなくread_gbqを使ってBQを洗い替えます。
read_gbqを本来とは異なる用途で使用するためエラーが発生しますが、今回の実装では特定のエラーをキャッチした場合に正常処理がされたと想定します。
DELETE実行
read_gbqのクエリにDELETE文をセットします。
以下のようなエラーが吐かれるので、例外処理でエラーをキャッチして処理を続行させます。
<class 'KeyError'>, KeyError('totalRows',), <traceback object at 0x10ed4dd08>
SELECT結果のINSERT実行
read_gbqのクエリにINSERT xxxx SELECT yyyyをセットします。
以下のようなエラーが吐かれるので、例外処理でエラーをキャッチして強制終了させます。
<class 'KeyError'>, KeyError('totalRows',), <traceback object at 0x10ed4dd08>
実装例
# coding:utf-8
import pandas as pd
import sys
####################
# 対象テーブル
####################
# Google BigQueryプロジェクトID
PROJECT_ID = '**********'
# スキーマ名
SCHEMA = '**********'
# 対象テーブルをcsvから取り込む
TARGET_TABLE = '**********'
####################
# クエリ定義
####################
# DELETE文作成
query_delete = '''
delete from {schema}.{table_nm} where 1=1
'''.format(
schema=SCHEMA,
table_nm=TARGET_TABLE
)
# SELECT~INSERT文作成
query_select_insert = '''
#standardSQL
insert {schema}.{table_nm} (col1,col2,...)
select * from xxxxxxxxxx.yyyyyyyyyy
'''.format(
schema=SCHEMA
, table_nm=TARGET_TABLE
)
try:
# DELETE文の実行
df = pd.read_gbq(
query_delete
, PROJECT_ID
, dialect='standard'
)
except KeyError:
try:
# SELECT~INSERT文の実行
df = pd.read_gbq(
query_select_insert
, PROJECT_ID
, dialect='standard'
)
except KeyError:
# システムを強制終了
sys.exit()