0. データモデル
0-1. データモデルとは
- データモデルには、多くの種類があり、多くのアプリケーションは、幾つものデータモデルのレイヤーを積み重ねていくことによって表現される。
- アプリケーションのレイヤー
- 現実世界(人、組織、物、行動、金銭の流れなど)のモデル。
- 汎用的データモデル
- アプリケーションのレイヤーのデータ構造を保存するための、JSONやXMLドキュメント、リレーショナルデータベースのテーブル、あるいはグラフモデル。
- ストレージモデル
- 汎用的データを、メモリ、ディスク、ネットワーク上でバイト列として表現するモデル。これにより様々な方法でキューイング、検索、操作、処理できるようになる。
- 物理モデル
- ストレージのバイト列を電流や光のバルス、電磁気などで表現するモデル。
0-2. データの保存とクエリのための汎用的データモデル
0-2-1. リレーショナルデータモデル
- データをリレーション(SQLにおけるテーブル)で構成し、それぞれのリレーションは、順序なしのタプル(SQLにおける行)の集合。
- リレーショナルデータベースは、ビジネスデータの処理(トランザクション処理やバッチ処理)を起源とし、クリーンなインターフェースによって背後の実装の詳細を隠蔽することを目標とした。
- アプリケーション上のオブジェクトとテーブル上のデータモデルの間に、不整合・不一致(インピーダンスミスマッチ)が生じる。
-
スキーマオンライト
- スキーマは明示され、データベースは書き込まれるすべてのデータがそのスキーマに従っていることを保証する。
0-2-2. ドキュメントモデル
-
NoSQL(Not Only SQL)データベース が広まる。
- キー・バリュー型データベース
- Redis、DynamoDB
- カラム指向データベース
- Apache Cassandra、HBase
- ドキュメント指向データベース
- MongoDB、CouchDB
- グラフデータベース
- Neo4j、Amazon Neptune
- キー・バリュー型データベース
- リレーショナルデータモデルと比較して、以下のような特徴を持つ。
-
スケーラビリティ
- 巨大なデータセットや書き込みのスループット。
-
スキーマの柔軟性
- スキーマの制約がなく、動的で表現力に富む。
-
スケーラビリティ
-
スキーマオンリード
- データの構造は暗黙のものであり、データの読み取り時にのみ解釈される。※ スキーマレスというわけではないことに注意。
0-2-3. JSON
- 履歴書のような、ほぼそれ自体で完結するドキュメントであるデータ構造 には、JSONが適している。
- MongoDB、RethinkDBなどのドキュメント指向データベースはJSONをサポートしている。
- MySQL、PostgreSQLなどのリレーショナルデータベースでもJSON型がサポートされるようになった。
JSONのメリットとデメリット
| メリット | デメリット |
|---|---|
| ・スキーマが柔軟 である。 ・ローカリティに優れる。 ・RDBでは複数のクエリの実行か、複数の結合をした上でのクエリが必要な場合でも、JSONであれば(すべての情報が1箇所に集まっているため、)1度のクエリだけで十分 になる。 ・一度にドキュメントの大部分が必要になる場合にメリットになる。 |
・JSONでは1対多のツリー構造には結合が必要ないことから、多くのドキュメントデータベースでは 結合のサポートが弱い。 ・アプリケーションに機能が追加されていくにつれて結合が必要になることが多い ため、結合の処理がアプリケーション側で必要になり、多対多のリレーションが多く発生する場合には アプリケーションのコードが複雑になる。 ・非正規化(データを複製) するか、あるレコードから他のレコードへの 参照を自分で辿る 必要がある。 |
1. 単一のデータベースについて考える
1-1. DBMSのアーキテクチャの全体像
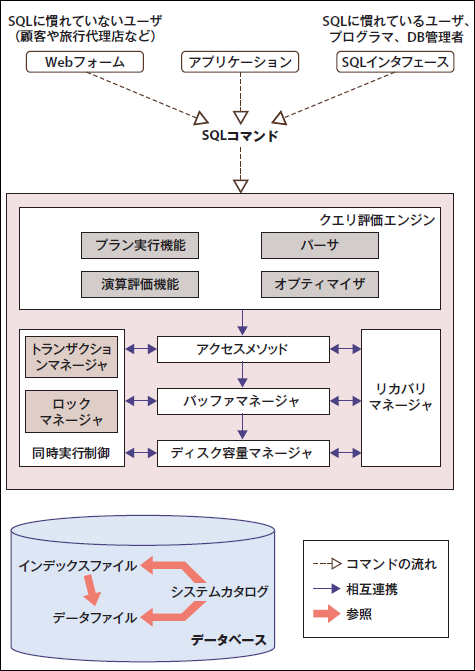
出典:『Database Management Systems 3rd ed.』(Raghu Ramakrishnan、Johannes Gehrke 著、McGraw Hill Higher Education、2002年、p.405)
第1回 記憶装置のトレードオフとバッファの考え方―すべてをとることができないとき (1) - gihyo.jp
1-2. クエリプロセッサ(クエリ評価エンジン)
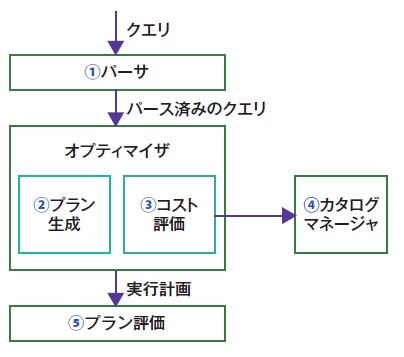
出典:『Database Management Systems 3rd ed.』(Raghu Ramakrishnan、Johannes Gehrke 著、McGraw Hill Higher Education、2002年、p.405)
第4回 クエリ評価エンジンと実行計画―“シェフおまかせ”はいつも美味しいのか(1) - gihyo.jp
クライアント(アプリケーションプログラムやSQLインタフェースなど)がSQLを記述して実行し、DBMSがSQLを受け取るところから始まる。
-
パーサ
- まずは受け取ったSQLのクエリを、パーサによって文法的に正しいかチェックする。
-
オプティマイザ
- 次に、オプティマイザが カタログマネージャが管理するテーブルやインデックスの統計情報を見て、プラン生成とコスト評価を行なったのち、最も低コストな実行計画を1つ決定する。
- EXPLAIN文を実行すると、実行計画を確認することができる。
-
プラン評価
- プラン評価で、実行計画を受け取って、DBMSが実行可能なコードへ変換し、実行する。
1-3. ストレージエンジン(データベースエンジン)
- データベースのアクセス処理(書き込みと読み出し)を行うプログラム。
- データの取得方法、保存方法、処理方法がストレージエンジンによって異なる。
- 同時実行制御 という、トランザクションマネージャやロックマネージャの機能を含む。
- MySQLのストレージエンジン
-
MyISAM
- 5.5未満でデフォルト
- トランザクション非対応 であったり、 テーブル単位でロック を行うため更新に不向きなどの問題があった。
-
InnoDB
- 5.5以降でデフォルト
- トランザクション対応 と 行ロック が備わっている。
-
MyISAM
第13章 クエリプロセッサ クエリプロセッサとは - SQL Server 7.0 リソースキット
第1回:MySQLストレージエンジンの概要 - ThinkIT
MySQLのストレージエンジンについて - Qiita
1-4. 利用用途の観点から見たデータベース(ストレージエンジン)の種類
-
OLTP(Online Transaction Processing / オンライントランザクション処理システム)
- トランザクションのワークロードに対して最適化されたストレージエンジン。
- 一般的にイメージするデータベース。
レコードの挿入や更新が、ユーザーの入力に基づいて行われる。- MySQL, PostgreSQL, Oracle Database
- インデックスを利用してデータの読み取りを行う。
- B-Tree, Hash index, SSTable(Sorted String Table)
- ランダムアクセスと低レイテンシの書き込みが求められる。
-
OLAP(Online Analytic Processing / オンライン分析処理システム)
- 分析のワークロードに対して最適化されたストレージエンジン。
- 分析目的で使われ、結果がビジネスインテリジェンス(BI)のために利用されるデータベース。データウェアハウス。
-
データウェアハウス
- Amazon Redshift, Google BigQuery, Snowflake
-
BIツール
- Tableau, Power BI, Looker
-
データウェアハウス
- 負荷が高く、データセットの大部分をスキャンするような、アドホックな(特定の)分析クエリがリードオンリーで実行される。
- OLTPのすべてのデータのコピーが、定期的なデータダンプや連続的な更新のストリームによって書き込まれる。
1-5. インデックス構造の種類
- インデックスとは、データベースから特定のキーの値を効率的に見つけるためのデータ構造のこと。
-
読み出しのクエリを高速にするが、書き込みを低速にする。
- そのためデフォルトで全てにインデックスをつけるようなことはしない。
- OLTPのインデックス構造は、以下の2つに分かれる
- ページ指向(B-Tree)
- log-structured
1-5-1. B-Tree(Bツリー)
- 自己平衡木(Self-Balanced Tree)であるデータ構造。
- 検索、挿入、削除が O(log n) で実行可能で、効率的。
- キーと値のペアをキーで ソートされた状態 で保持するため、範囲クエリも効率的。
- データベースは(メモリ上ではなく)ディスク上でページに分割され、ページ数が増えても木の高さがあまり増えない(深くならない)ため、ディスクアクセスが最小化 される。
- RDBMSでは、基本CREATE INDEX命令を実行するとB-Treeが1個作られる。
- 最も広く使われるインデックス構造。
- B-treeインデックスの活用例
- MySQL、PostgreSQLなどのRDB等
- B-treeインデックス入門 B-treeインデックスの構造 - Qiita
- データ構造とアルゴリズム入門1(データ構造・探索) 9. [データ構造] 二分探索木(Binary Search Tree) - Qiita
1-5-2. log-structured
-
ファイルへの追記と古くなったファイルの削除 を行うインデックス構造。
- 一度書かれたファイルは決して更新されない(レコードの追加とコンパクション操作の分離)。
- 比較的最近開発された。
- メリット
- 更新時のランダムアクセスを減らせる
- デメリット
- 書き込みの増幅が生じる。
- log-structuredインデックスの活用例
- SSSTable(Sorted String Table)というデータ構造を使ったデータベース
- Apache Cassandra、Google Bigtable
- LSM(Log-Structured Merge)ツリーというデータ構造を使ったデータベース
- RocksDB、LevelDB、Lucene
- SSSTable(Sorted String Table)というデータ構造を使ったデータベース
2. 複数のデータベースへの分散を考える
2-1. レプリケーション
- レプリケーションとは、データを複製すること。
- 同じデータを複数のマシンにコピーして保持する方法。
2-1-1. レプリケーションの目的
-
スケーラビリティ
- データの量、読み取りの負荷、書き込みの負荷が増大し、1台ののマシンでは処理が追いつかなくなった場合、複数のマシンに 負荷分散(Load Balancing) させることで、システム全体の性能を維持することができる。
-
耐障害性と高可用性
- 1台のマシン(あるいは複数のマシンやネットワーク、あるいはデータセンター全体)がダウンしてもアプリケーションが動作し続けるために、複数のマシンにデータを冗長的に保存し、他のマシンに動作を引き継がせることができる。
-
レイテンシを下げる
- ユーザーが世界中にいる場合、世界中の様々な場所にサーバーを配置して、それぞれのユーザーが地理的に近いデータセンターからレスポンスを受けられるようにできる。こうすることで、ユーザーが地球を半周してくるネットワークパケットを待たずにすむようになる。
2-1-2. レプリケーションの種類
- シングルリーダーレプリケーション
- 1つのレプリカ(リーダー)が書き込みを処理し、他のフォロワーレプリカがリーダーからデータをコピーして整合性を保つ。
- マルチリーダーレプリケーション
- 複数のレプリカ(リーダー)が書き込みを処理し、各リーダーが独自のデータ更新を行う。
- 可用性が向上するが、競合解決が必要になる。
- リーダーレスレプリケーション
- 特定のリーダーを設けず、全てのレプリカがデータの整合性を協調して保つ方法。
2-1-3. リーダーベースのレプリケーション(アクティブ/パッシブ、マスター/スレーブ)
- リーダーベースのレプリケーションでは、1つのレプリカ(リーダー、マスター、プライマリ)が書き込みを担当し、他のレプリカ(リードレプリカ、フォロワー、スレーブ、セカンダリ、ホットスタンバイ)がそのデータをコピーして同期する。
- リードレプリカは通常読み取り専用で、リーダーが書き込みを処理する。
2-1-4. Amazon RDSにおけるレプリケーションのイメージ
- Amazon RDSでは、シングルリーダーレプリケーションがよく使用される。
- メインとなるデータベース(プリマリ)があって、そこに読み書き(Read/Write)をする。
- 読み込み(Read)専用のデータベース(リードレプリカ)に、データを非同期レプリケーションする。
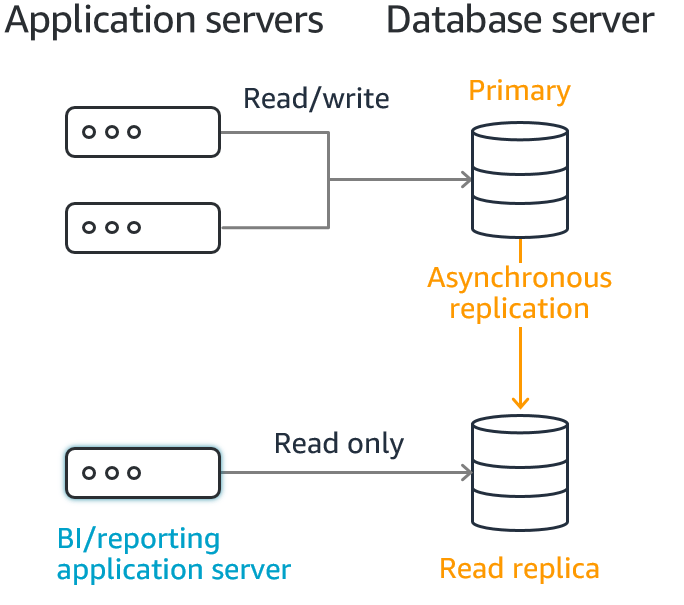
2-1-5. 同期レプリケーションと非同期レプリケーションのトレードオフ
| 同期レプリケーション | 非同期レプリケーション | |
|---|---|---|
| 概要 | データがプライマリでコミットされる前に、すべてのレプリカに対して変更が確実に反映されるまで待機する。 | プライマリが更新された時点で、すぐにクライアントにレスポンスを返す。 レプリカとの同期は、以下のような方法で行われる。 ・プライマリのトランザクション完了後にレプリカへデータ転送 ・バッチ処理による同期 ・レプリカによるポーリング |
| メリット | データの整合性(プライマリとレプリカのデータの一致)が保たれるため、レプリケーションラグが発生しない。 | レプリカの更新を待たないため、書き込みと読み込みのパフォーマンスや可用性が向上する。 |
| デメリット | ・書き込み処理の遅延。レイテンシが長くなり、パフォーマンスが低下する。 ・フェイルオーバー に時間がかかる。 |
・レプリケーションラグ により、レプリカから古いデータが返される可能性がある。 ・特にリアルタイム性が求められるシステムでは問題になる。 ・フェイルオーバー が行われると、データ損失の可能性がある。 |
用語の説明
-
レプリケーションラグ
- プリイマリでのデータ更新をリードレプリカへ反映(レプリケーション)する時の遅延が大きくなってしまった状況のこと。
-
フェイルオーバー
- プライマリで障害が発生した際、システムがレプリカをプリマリへ自動的に昇格させること。
2-2. パーティショニング(シャーディング)
- データベースを分割してデータを保存する方法。
- レプリケーション...全く同じデータのコピーを複数のマシンに持つ手法。
- パーティショニング...複数のマシンにデータを分割する手法。
- データは、「時間範囲(1時間、1日など)」、あるいは「キー範囲」などで分割する。
- 例:24時間ごとにログファイルを分割することで、該当日時のデータを見やすくするなど。
- 均等に負荷分散できているのであれば、良いパーティショニングと言える。
- 実際パーティショニングする時にはハッシュを使ったりとか、いろいろな手法がある。
2-2-1. パーティショニングの目的
-
スケーラビリティ向上
- クエリの負荷分散など。
- "良い"パーティショニングはデータとクエリの負荷をノード間で均等に分散させる
用語の説明
-
skew
- 偏りがある状態のこと。
-
ホットスポット
- 負荷集中しているパーティションのこと。
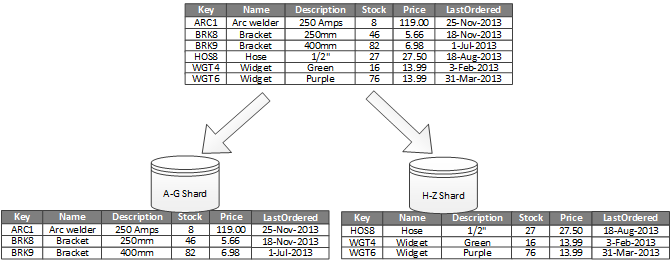
2-2-2. A-Zのアルファベットでパーティショニングする例
- 以下により負荷分散させている。
- KeyがA-Gの場合はA-Gシャードにデータを入れる。
- KeyがH-Zの場合はH-Zシャードにデータを入れる。
- 例えば、Keyが全体でA-Gであるデータしか存在せず、A-Gシャードにしかデータが存在しない場合、A-Gシャードは負荷が集中しているシャード(パーティション)であり、ホットスポットである。
製品在庫データが製品のKeyに基づいてシャーディング(分割)されます。
各シャードは、アルファベット順に編成された、連続する範囲のシャードKey (A-G および H-Z) のデータを保持します。シャーディングは負荷をより多くのコンピューターに分散するため、競合が減り、パフォーマンスが向上します。
2-3. トランザクション
- データベースの花形技術であり、アプリケーションが複数の読み書きを一つの論理的な単位としてまとめる方法。
- トランザクションの結果は、成功(コミット)または失敗(ロールバック)のいずれかになる。
2-3-1 トランザクションの満たすべき性質(ACID)
-
ACID
- トランザクションが満たすべき性質、安全性の保証を示す語。
- ACIDの実装はデータベースごとに異なるため、実際にどういった保証を期待できるかははっきりしない。
-
Atomicity(原子性)
- トランザクションの全ての操作が「全て実行されるか全く実行されない」ことを保証する性質。
- トランザクション中のすべての操作が、一つの不可分な単位として扱われる。
- 例: 銀行での資金移動では、送金元の口座からの引き落としと送金先の口座への入金が一つのトランザクションとして行われ、どちらか一方だけが実行されることはない。
- トランザクションの全ての操作が「全て実行されるか全く実行されない」ことを保証する性質。
-
Consistency(一貫性)
- トランザクションが開始される前と終了した後で、「データベースの状態が一貫したものとなる」ことを保証する性質。
- トランザクションが成功した場合、データベースは常に定義されたルールに従う正しい状態になる。
- 例: 資金移動のトランザクションにおいて、送金前後で合計金額が変わらない。
- トランザクションが開始される前と終了した後で、「データベースの状態が一貫したものとなる」ことを保証する性質。
-
Isolation(分離性)
- 並行して実行されるトランザクションが「互いに干渉せず、分離されている」ことを保証する性質。
- トランザクションが並行して実行される場合でも、他のトランザクションの中間状態を見ることはできない。
- 並行して実行されるトランザクションが「互いに干渉せず、分離されている」ことを保証する性質。
-
Durability(永続性)
- トランザクションが「成功した場合、結果が永続的に保存される」ことを保証する性質。
- システム障害が発生しても失われないこと。
- 例: 銀行の資金移動が成功した後でシステム障害が発生しても、送金元と送金先の口座の金額は更新されたままになる。
- トランザクションが「成功した場合、結果が永続的に保存される」ことを保証する性質。
2-3-2. ロック
- Isolation(分離性)、すなわち並行して実行されるトランザクションが「互いに干渉せず、分離されている」ことを実現するために、データベースでは、特定の動作を制限する ロック という仕組みを、自動的または明示的に使用することができる。
-
共有モードロック(Share lock)
- 同一行・テーブルに対して、複数のトランザクションが同時に取得できる ロック。
- 他のトランザクションが排他ロックを取得していた場合は、排他ロックの解放を待機してから共有ロックを取得する。
-
排他モードロック(Exclusive lock)
- 同一行・テーブルに対して、複数のトランザクションが同時に取得できない ロック。
- 1つのトランザクションだけがその行をロックして操作できる。
-
UPDATE、DELETE- 更新を行う行に対してデータベースが 自動的にロック を取得する。
-
SELECT ... FOR UPDATE- 節を付与することで、クエリが返す全ての行に対して 明示的にロック を取得することができる。
- どちらも、ロックを取得したトランザクション(BEGIN ~ COMMIT)が完了しそのロックを解放するまで、他のトランザクションが同じ行に対してロックを取得することを防ぐことができる。
/*
SELECT ... FOR UPDATE を実行した時点で、
指定したキャラクターに対するロックが取得され、
このトランザクションが完了するまで、
他のトランザクションは同じキャラクターを操作(= ロックを取得)できなくなる。
*/
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE;
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;
-
明示的ロック
-
テーブルレベルロック
-
DDL(
ALTER TABLEやDROP TABLEなど)を実行した時に、テーブル全体に対する書き込みを阻止する。
-
DDL(
-
行レベルロック
- トランザクションが特定の行を更新するときに取得されるロック。他のトランザクションによる同じ行への書き込みを阻止する。
- MySQL InnoDBでは、次の2種類の行ロックがある。
-
レコードロック:
- 特定の行への挿入を防ぐロック。
-
ギャップロック
- 範囲検索結果への挿入を防ぐロック。
-
SELECT ... FOR UPDATEなどで取得される。- Phantom Read を防止するために使用される。
-
レコードロック:
- PostgreSQLでは、
SELECT ... FOR UPDATEなどで特定の行への挿入が阻止される。- Phantom Read は防止されないため、トランザクション分離レベルを SERIALIZABLE にする必要がある。
-
テーブルレベルロック
-
MVCC(Multi-Version Concurrency Control)
- 行レベルロックを補完する仕組みで、行データの複数バージョンを保持することにより、読み取りと書き込みの競合を緩和する。
-
スナップショット分離 を実現する。
- トランザクションは、同一トランザクション内でロックを取得せず、一貫性のあるスナップショット(変更前のバージョン)を利用してデータを読み取る。
-
デッドロック
- トランザクションが 互いにロック解放を待ち続ける状態 のこと。
- データベースは、トランザクション間の デッドロックを自動的に検出し、いずれかのトランザクションを中断させる 。
-
カーソル固定(cursor stability)
- 値を読み取る際に排他ロックを取り、他のトランザクションがその値を読めないようにすること。
-
2PL(ツーフェーズロック)
- 最初のフェーズ(トランザクションの実行中)でロックを取得し、2番目のフェーズ(トランザクションの終了時点)ですべてのロックを解放すること。
- 共有モードと排他モードの2種類のロックを使用するが、デッドロックが発生しやすく、ロックの取得と解放のオーバーヘッドがあるためパフォーマンスが悪い。
2-3-3. Isolation(分離性)のレベル
-
トランザクション分離レベル(Transaction Isolation Level)
- Isolation(分離性)にはレベルがある。
- 「並行して実行されるトランザクションが どの程度分離されるか」のレベルを、データベースで制御できる。
- 米国国家規格協会(ANSI)によって定められた4つのレベルを選択できる。
-
READ UNCOMMITTED
- トランザクションは、他のトランザクションによって 未コミットの変更を読み取る ことが発生してしまう。
- ロック
- 読み取り時...取得しないか、最小限。
- 書き込み時...排他ロックを取得する。
- 使用例
- データの一貫性よりもパフォーマンスが重要な場合に使用される。
- 基本的に使用されることはない。
-
READ COMMITTED
- トランザクションは、他のトランザクションによって コミット済の変更のみを読み取る 。
= トランザクション内で同じ行を複数回読み取るときは、値が変わる可能性がある。 - ロック
- 読み取り時...短期間の共有ロックを取得する。
- 書き込み時...排他ロックを取得する。
- 使用例
- 多くのデータベースにおいてデフォルト。
- 一貫性とパフォーマンスのバランスが取れている。
- トランザクションは、他のトランザクションによって コミット済の変更のみを読み取る 。
-
REPEATABLE READ
- トランザクションは、 トランザクション開始時のスナップショットを常に読み取る。
= トランザクション内で同じ行を複数回読み取るときでも、常に同じ値を返す。 - ロック
- 読み取り時...短期間の共有ロックを取得する。
- 書き込み時...排他ロックを取得する。
- 使用例
- 長期間にわたるトランザクションや、複数回にわたる読み取りが重要なシナリオ。
- トランザクションは、 トランザクション開始時のスナップショットを常に読み取る。
-
SERIALIZABLE
- トランザクションは、他のトランザクションと 完全に分離 される。
= 直列に実行されるように見える。 - ロック
- 読み取り時...長期間の共有ロックを取得する。
- 書き込み時...長期間の排他ロックを取得する。
- 使用例
- データの完全な一貫性が要求されるシステム。
- トランザクションは、他のトランザクションと 完全に分離 される。
2-3-4. トランザクション分離レベルにおけるアノマリー(異常)
- 並行して実行されるトランザクション間では、 発生する可能性のある不整合や競合の状態 が存在する。
-
Dirty Write
- トランザクションの 書き込みで、他のトランザクションがコミットしていないデータを上書きしてしまう こと。
- 実際にはどの分離レベルでも発生しない。
-
Dirty Read
- トランザクションの 読み取りで、他のトランザクションがコミットしていないデータを見れてしまう こと。
-
Lost Update(更新競合)
- 複数のトランザクションが 同じデータを並行して更新し、更新が失われる こと。
-
Non-Repeatable Read 、 Read Skew(読み取りスキュー)
- 他のトランザクションがデータを更新・コミットした結果、 1つのトランザクション内の複数の読みとりで、異なるデータが読み取られる こと。
-
Write Skew(書き込みスキュー)
- 複数のトランザクションが同じ複数の値を読み取り、それらの一部を更新することによって生じる不整合。
-
Phantom Read
- 他のトランザクションによる書き込みのせいで、1つのトランザクション内で複数回、同じ条件の検索で、検索結果が異なってしまう こと。
- 特定の行を検索する場合は影響を受けないが、範囲検索の時にのみ生じるという点で、Non-Repeatable Read と異なる。
2-3-5. トランザクション分離レベルとアノマリーの対応表
| アノマリー→ レベル↓ |
Dirty Read | Non-repeatable Read | Phantom Read | Lost Update | Write Skew | 説明 |
|---|---|---|---|---|---|---|
| Read Uncommitted | ◯ | ◯ | ◯ | ◯ | ◯ | トランザクションは他のトランザクションの「未コミット」の変更を読み取ることができる |
| Read Committed | × | ◯ | ◯ | ◯ | ◯ | トランザクションは他のトランザクションの「コミット済み」の変更のみを読み取ることができる。 |
| Repeatable Read | × | × | ◯ (※ MySQL InnoDBの場合は発生しない) |
× | ◯ | 1つのトランザクションは同じ行を複数回読み取るときに、常に同じ結果を返す。 |
| Serializable | × | × | × | × | × | トランザクションは完全に分離され、直列に実行されるように見える。 |
2-3-6. MySQLとPostgreSQLのデフォルトのトランザクション分離レベル
- MySQL(InnoDB)
-
Repeatable Read 。
- 1トランザクション内での読み取り操作の一貫性が保証されており、Non-repeatable Read が発生しない。
- また、 InnoDB の Repeatable Read では、Phantom Read が発生しない。
-
Repeatable Read 。
- PostgreSQL
-
Read Committed。
- トランザクションは他のトランザクションのコミット済の変更のみを読み取ることができるため、 Dirty Read は発生しないが、 Non-repeatable Read が発生する可能性がある。
-
Read Committed。
- 17.7.2.1 Transaction Isolation Levels - MySQL 9.1 Reference Manual
- 13.2. Transaction Isolation - PostgreSQL 17
- トランザクションの分離性(isolation)の概要 - Qiita
- MySQL/Postgres におけるトランザクション分離レベルと発生するアノマリーを整理する - Zenn
- Isolation Levelの階層 - Qiita
- いろんなAnomaly - Qiita
- [RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説
2-4. 冪等性(idempotency)
- 同じ操作が繰り返されても、データの一貫性が保たれること。
- 前提として、アプリケーションは、リトライが起こる前提で設計する必要がある。
2-4-1. リトライが必要な例
- デプロイ時の通信遮断
-
タイムアウトやネットワーク障害
- その結果、クライアントからサーバーへのリクエスト(トランザクションのコミット)は成功したが、レスポンスが失敗した場合など
2-4-2. 冪等性を担保するための解決策
- リクエストにユニークなIDなどを付与することで、データベースに同じデータが登録されてしまうことを防ぐ。など
2-4-3. Saga
- 複数のサービスにまたがるトランザクションが連続的に実行され、一部のサービスでのみエラーが発生した場合に、トランザクションが成功したサービスと失敗したサービスでデータの一貫性、整合性を保つためのデザインパターン。
2-4-3-1. Sagaが有用な例
- 旅行予約システムでは、飛行機のチケット、ホテルの予約、レンタカーの手配など、複数のサービスにまたがるトランザクションが必要。飛行機のチケットを確保した後、ホテルの予約に失敗した場合、全体の予約をキャンセルする必要がある。
2-4-3-2. 解決策
-
補償トランザクション
- 一部のトランザクションでエラーが発生した場合に成功したトランザクションに対して実行する、過去の操作を取り消すためのトランザクションのこと。これにより、データの一貫性を保つことができる。
- リトライと冪等性のデザインパターン - Blog by Sadayuki Furuhashi
- サーバーレスにおけるべき等性の実装 (バッチ処理と分散トランザクション編) - builders.flash
参考
- データ指向アプリケーションデザイン
- 分散データシステム入門の決定版『データ指向アプリケーションデザイン』をたった30分で学んでみた#DataEngineeringStudy
- データベース研修(データベース基礎編)【ミクシィ22新卒技術研修】
- MySQL/Postgres におけるトランザクション分離レベルと発生するアノマリーを整理する - Zenn
- データベースとストレージのレプリケーション入門 / Intro-of-database-and-storage-replication - SpeakerDeck
- Rails Developers Meetup 2018 で「MySQL/InnoDB の裏側」を発表しました - あらびき日記