動機と概要
マイクロサービスごとに存在するデータベース間で整合性を取る方法として、複数のトランザクション全体の分離性を保証せずに結果整合性を利用するパターンがあります。
しかし、分離性がないことによる並行処理の問題にどう対処するかは、そもそも分離性を保証することで何ができていたのかを正しく知っている必要があります。
そこで、改めて従来のトランザクションがどのようなものを保証しているか分離性を中心に整理したのが本記事になります。
トランザクションとは
トランザクションの役割
システムの安全性を保つためには、いくつかの障害に対処する必要があります。
- データベースへの読み書きの途中でアプリケーションがクラッシュし、途中で処理が終わる
- 複数のクライアントが同時にデータベースに書き込み、お互いの変更を上書きしてしまう
- データベースソフトウェアがクラッシュして保持した内容が失われる
これらの問題に対処するための仕組みが、トランザクションです。定義は以下になります。
トランザクションは、データベースをある一貫した状態から別の一貫した状態へ変更するアクションを1つに束ねたものである。
トランザクションは、全体の操作が全て完了した場合はコミット(commit)、全体のどれかが失敗した場合ば中断(abort)を行います。
そうすることによって、複数の操作が全て完了したか、全てキャンセルされたかを保証することができます。
ACID
トランザクションが保証する安全性は、それぞれの性質の頭文字を連ねたACIDという言葉で表現されます。
原子性 (atomicity)
トランザクションは、操作のまとまりを全て実行した状態か、全く実行していない状態かのどちらかにしか遷移させないことを示します。
つまり、トランザクションが障害のためにコミット(commit)できなければ、中断(abort)されそのトランザクション中に行われた書き込みは全て取り消される必要があります。
一貫性 (consistency)
トランザクションはデータの一貫性を保持する必要があることを示します。データの一貫性には、データベース内部の一貫性とそれ以外の一貫性があります。
データベース内部の一貫性には以下のようなものがあります。
- 全てのプライマリーキーはユニークである
- 参照するレコードが存在している
- 保持される値は指定した範囲である(nullを許容しない、ageカラムの値は120より少ないなど)
データベース内部だけでは維持できない一貫性は以下のようなものがあります。
- それぞれの部署の経費は予算を超えない
- 従業員の給与額は職能ごとの給与レンジ内におさまる
トリガーなどを使えばデータベース側でも実現できるものもありますが、基本的にはアプリケーション全体でデータの一貫性を保証する必要があります。
つまり一貫性は、原子性や分離性、永続性と異なり複数のトランザクションを実行するアプリケーションの責務になります。
したがって、厳密にはトランザクションはAIDを保証するだけで、アプリケーション全体でCを保証するための一部に過ぎません。
分離性 (isolation)
複数のトランザクションを同時に実行してそれぞれの結果に影響しないことを示します。
例えば、同時に実行された100円を引き出す二つのトランザクションを考えます。
口座の残高がちょうど100円で、どちらもまだ引き出していない場合はどちらのトランザクションも引き出し可能だと判断して実行します。
しかし残高は-100円になるのではなく、一方が実行した後にもう一方は失敗する必要があります。
これは、それぞれを直列に実行した場合と結果が異なります。
同時に実行しても、それぞれのトランザクションを重なりなく順番に実行した場合と同じ結果になることを直列可能(serializable)であると呼びます。この直列可能性(serializability)によって、複数のトランザクションが実行中でも、さもそれ以外は実行されていないかのように振る舞います。実際に直列で実行することはパフォーマンスを悪くするだけなので、各トランザクションがロックをセットすることで実現されます。
分離性は、この直列可能性を保証するものです。
しかし、実際にはパフォーマンス上のトレードオフから直列可能性は保証せずに弱い保証でトランザクションシステムは実現されることが多いです。
永続性 (durability)
トランザクションが一度コミットした内容は、システムが失敗しても復旧後に結果が失われないことを示します。
これは、更新内容をログとして残し、コミット内容が反映されているかどうか復旧時に確認することで実現されます。
並列に実行されるトランザクションの制御
分離性が保証されない場合の問題
ACIDのIの分離性は直列可能性によって保証されますが、実際にはパフォーマンス上の問題から弱い分離レベルが用いられます。
まず、分離性が保証されない場合どのような問題が生じるかを整理して、弱い分離レベルで何が防げないのかを確認します。
ダーティリード
コミットしていないトランザクションの変更を別のトランザクションが読み取ってしまうことをダーティリード(dirty read)と呼びます。
コミット前の別のトランザクションが変更したレコードを読み取っても、原子性によりロールバックされている可能性があるので実際に反映されていない可能性があります。
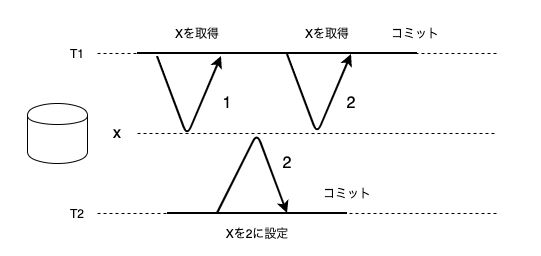
例えば、トランザクション1(以下、T1)が二回目のXへの読み取りをすると、コミットされていないトランザクション2(以下、T2)に更新された値(2)が返ってきます。
T2が中断された場合実際のXの値は1に戻っているので、誤った値を元にT1は処理を進めていることになります。
これを防ぐにはコミットされた値を読み取れるようにする必要があります。
ダーティライト
二つのトランザクションが同じレコードに対して書き込みを行った場合、先行するコミット前の書き込みを後続のトランザクションが上書きすることをダーティライト(dirty write)と呼びます。
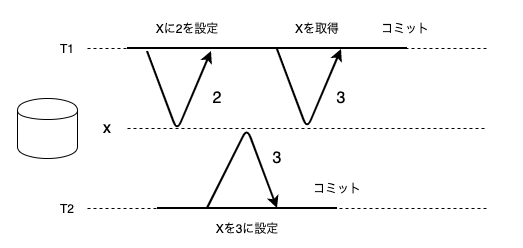
これを防ぐには二番目のトランザクションの書き込みは、最初の書き込みのトランザクションがコミットもしくは中断されるまで遅延される必要があります。
ノンリピータブルリード
トランザクションの中でレコードを読み取った後に別のトランザクションが同じレコードを更新しコミットした場合、二回目の同じレコードの読み取り結果が変わってしまいます。これをノンリピータブルリード(nonrepeatable read)あるいは読み取りスキュー(read skew)と呼びます。
ダーティリードとの違いは、別のトランザクションの更新がコミット済みだという点です。
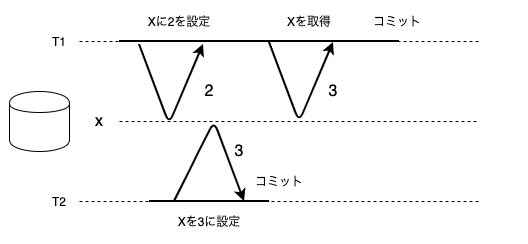
更新ロスト
二つのトランザクションが、値を読み取ってその値を元に書き戻す場合に、一方の書き戻しを上書きしてしまうことを更新ロストと呼びます。
これは、二つ目の書き戻しをする際に、一つ目の書き戻しの結果を踏まえていないため発生します。
例えば、ある口座の残高を確認して引き出す金額分引いた残高に更新するトランザクションを考えます。T1は残高が1000であることを確認し、300引き出すので700に更新しようとします。T2は残高が1000であることを確認し、200引き出すので800に更新しようとします。T2が残高を更新しようとした時には前提となっている値はT1に更新されていますが、それを無視して上書きします。

更新ロストを解決するには、主に三つの方針があります。
一つ目はデータベースで以下のようなアトミックな更新処理が提供されている場合は、実行時点でコミットされている値を元に変更分だけ明示して更新できます。
UPDATE accounts SET balance = balance - 200 WHERE id = 1;
そうすることで以下のように事前に値を読み取って値それ自体で更新する必要がなくなります。
SELECT balance FROM accounts WHERE id = 1;
/* balance is 1000 */
UPDATE accounts SET balance = 800 WHERE id = 1;
二つ目に読み取ってから書き込むまでの間、他のトランザクションによって書き込まれないように明示的に排他ロックを取得することができます。
三つ目にトランザクションマネージャが読み取った値と書き込みをコミットする時点で対象の値が変更されていないか自動で判定することもあります。
読み取った値が既に別のトランザクションによって更新されていた場合は、書き込みの前提となる値は古くなっているのでトランザクションは中断されます。
ファントムリード
トランザクション内でレコード群を読み取った後に、別のトランザクションがレコードの追加、削除をしてコミットすることで、以前の検索結果が過去のものになることがあります。
これをファントムリード(phantom reads)と呼びます。
ノンリピータブルリードは同じレコードの内容が別のトランザクションによって更新されてしまうことで起きますが、ファントムリードは検索結果のレコード群に追加されたり、削除される点で異なります。
例えば、口座と支店ごとの口座の残高の合計を持つ二つのテーブルを読み取るトランザクションを考えます。T1は支店Aの口座を読み取ると100と200が返ってきますが、支店ごとの残高の合計値を読み取ろうとすると350が返ってきます。これはその間にT2が新しい口座のレコードを追加し、支店ごとの残高の合計値を更新したからです。
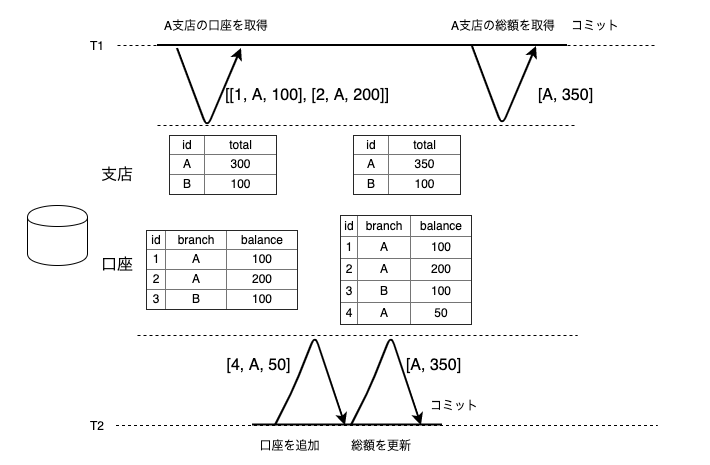
そしてファントムリードが発生すると以下のような処理があった場合、誤った検索結果を元に書き込みをしてしまいます。
- SELECTクエリで特定の条件を満たすレコードを検索する
- その結果を踏まえて書き込み(INSERT, UPDATE, DELETE)を行うか判断する
- 実際に書き込みをし、2の判断の前提となった条件が変わる
これをファントムリードによる書き込みスキュー(write skew)と呼びます。
後述するようにノンリピータブルリードは、スナップショット分離により解決できますが、ファントムリードによる書き込みスキューは回避することができません。
これを防ぐためには、T1が branch = A で口座を読み取った時に、その時点のその条件のレコードである1, 2の口座に対してではなく、その条件を満たすレコード全てをロックする必要があります。
そうすれば、T2が、 [4, A, 50]のレコードを挿入しようとするとロック待ちになるので、T1はT2の影響を受けずに済むからです。これは後述するSerializable分離レベルで実現されます。
分離レベル
ここでは主な分離レベルを確認していき、先ほどの並行性による問題がどのように解決されるのかを見ていきます。
Read Committed
Read Committed分離レベルは、writeロックはトランザクションが終わるまで解放されない一方で、readロックは読み取り操作が終わり次第解放します。readロックが取られているレコードに別のトランザクションからwriteロックを取ること(書き込み)ができないので、読み取ったレコードはコミット済みであることが保証されます。
またwriteロックが取られているレコードに別のトランザクションからwriteロックを取ることができないので、上書きするのはコミットされたレコードのみであることが保証されます。これらによって、ダーティリードとダーティライトを防ぐことができます。
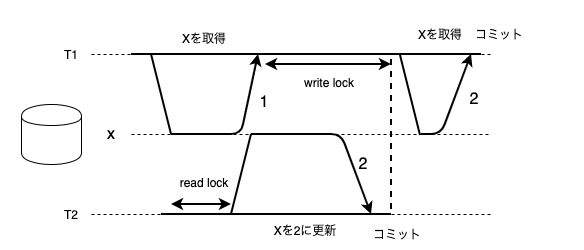
ダーティリードを防ぐ手段として、他のトランザクションのwriteロックを待つのではなく、書込みが行われたレコードに対してコミット済みの古い値と更新されたコミット前の値を両方保持しておくことができます。そうすると、コミット済みの値を読み取ることができるのでダーティリードを防ぎつつ、writeロックが解放されるまで読み取り待ちになることも回避できます。
しかし、読み取ってすぐにロックを解放するのでノンリピータブルリードの問題は回避することができません。
Snapshot
MVCC(multi-version concurrency controll)という手法によって、データベースは複数のコミット済みバージョンを管理することができます。
各バージョンはトランザクションIDやコピー元のトランザクションIDなどをメタデータとして持ちます。スナップショット分離では、トランザクションが開始すると、その時点でのコミット済みのバージョンを作成します。
これによって、他のトランザクションが書き込みをしてもトランザクション内では常に開始時のデータベースの状態を参照できるので、読み取りと書き込みでブロックが発生しなくなります。また、ノンリピータブルリードを回避することもできます。

さらに書き込みをコミットする際に、トランザクション開始時に撮ったスナップショットが既に変更されていた場合は、別のトランザクションが開始後に書き込みをコミットしたことになるので、トランザクションを中断します。そうすることで、更新ロストを回避することができます。
このように、スナップショット分離はread committedよりも強い同期を提供します。
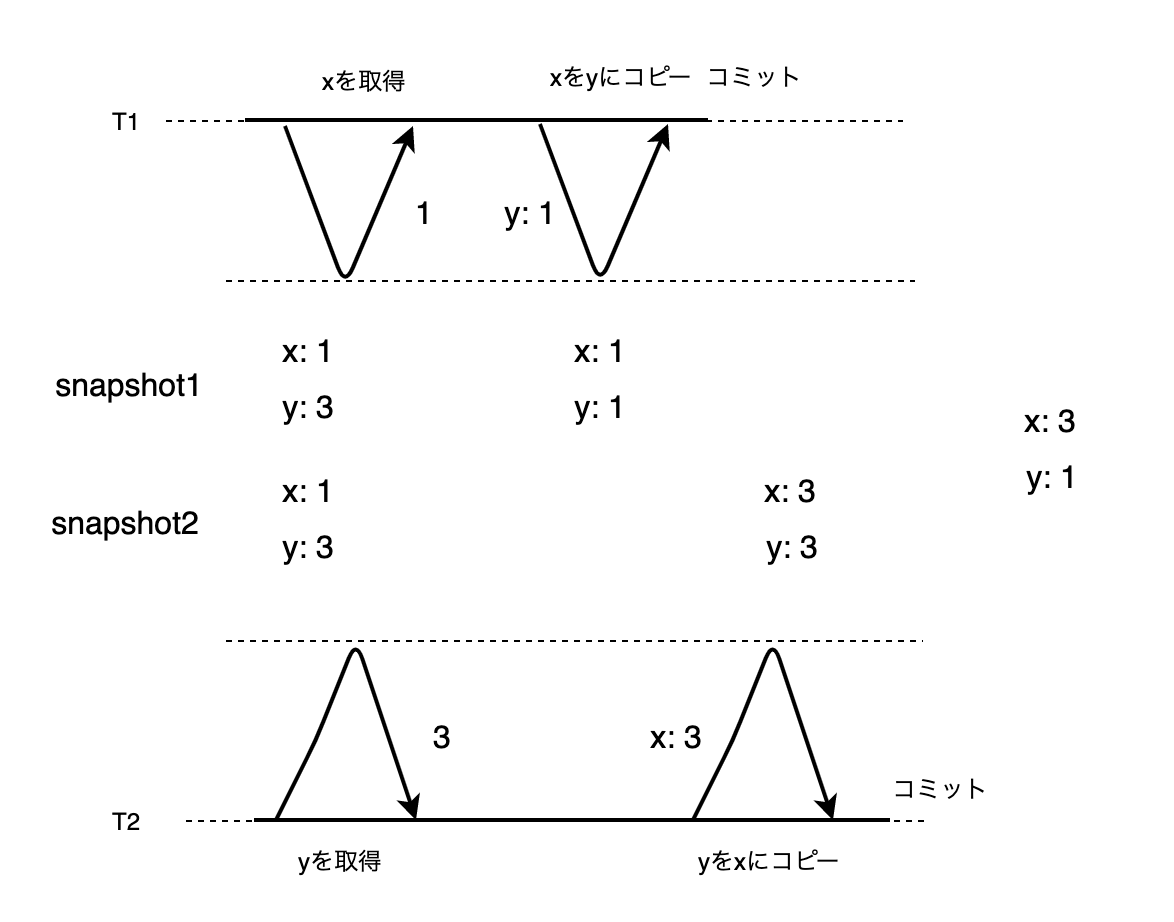
しかし、完全に直列可能ではありません。なぜならファントムリードによる書き込みスキューが発生し得るからです。
例えば、T1がxをyにコピーすると、yは1になります。T1がコミットする前のスナップショットを元にしたT2がyをxにコピーするとxは3になります。個別のx, yに関しては書き込みが重複していないので、中断されることはありません。しかし、直列でT1, T2の順に実行した場合は、最終的な結果はxとyが共に1となり、逆のT2, T1の場合はxとyが共に3になり、今回の結果と異なります。
Serializable
直列可能分離レベル(Serializable)は、最も強い分離レベルで並列でトランザクションを実行しても順番に実行された時と同じ結果になることを保証します。
直列可能分離レベルを実現するには、並列性を排除して順番にトランザクションを実行することもできますが、そうするとトランザクションの待ち時間が大きくなり過ぎてしまいます。そこで、ツーフェーズロック(two-phase locking)を用いて直列可能分離レベルを実現します。
ツーフェーズロックでは、共有ロックと排他ロックを使って以下のような仕組みで実現されます。
- トランザクションは、読み取り前に共有ロックを対象にセットしようとし、書き込み前に排他ロックをセットしようとする
- 共有ロックは排他ロックと衝突し、排他ロックは共有、排他ロックのどちらとも衝突する
- 対象のデータに衝突するロックがなければトランザクションはロックを実際にセットする
- ロックを獲得したトランザクションは終了までそのロックを保持する(どのロックもそれまでに解放できない)
必要な全てのロックを獲得するフェーズの後にそれらを解放するフェーズが続くことで、ノンリピータブルリードを回避することができます。またトランザクションが書き込んでコミットするまでは、別のトランザクションの読み取りは待たされるので、更新ロストや書き込みスキューも回避することができます。
例えば、二つのトランザクション(T1, T2)が口座の金額を読み取り、指定した金額が引き落とせるか確認し、問題なければ実際に引き落とします。
そして、T1によるレコードxへの共有ロック(読み取り)をr1(x)、排他ロック(書き込み)をw1(x)と表現します。T2の場合も同様です。T1が書き込み中はT2の読み取りは待たされるので、以下のような順番になります。
r1(x), w1(x), r2(x), w2(x)
これはT1, T2を直列で実行した場合と同じ結果になります。
しかし、以下の場合はデッドロック(deadlock)が発生します。
デッドロックとは、トランサクションが互いにロックの解放を待っており、ロックしあっている状態です。
r1(x), r2(x), w1(x), w2(x)
r1(x), r2(x), w2(x), w1(x)
いずれも、レコードxに対してT1, T2の共有ロックが取られ、トランザクションが終わるまで解放されません。
この状態で、書き込みのために排他ロックを取ろうとすると、別のトランザクションの共有ロックがあるため互いに解放待ちとなります。これを解消するには、システムがどちらかのトランザクションを中断させ、リトライさせる必要があります。
また、書き込みスキューを防ぐためには実際に読み取られたレコードに対してだけ共有ロックを取るのでは不十分です。
先ほどの例のように、読み取った後にレコードが追加、削除されるため、検索結果に影響の与えるレコード全てに対してロックを取る必要があるからです。
そのような将来の削除、追加も含めた検索結果にマッチする全てのレコードに共有ロックを取ることを、述語ロック(predicate locking)と呼びます。実際には述語ロックの代替として、その検索で使われるカラムのインデックスに共有ロックを取るインデックス範囲ロック(range locking)が利用されます。
デッドロック
トランサクションが全て互いにロックの解放を待っており、順番にロックしあっている状態をデッドロック(deadlock)と呼びます。
先ほど確認したように、分離レベルがSerializableの場合は一つのレコードに対して二つのトランザクションが共有ロックを取って、次に互いに書き込みしようとするとデッドロックが発生します。
r1(x), r2(y), w2(x), w1(y)
デッドロックの検出
デッドロックを発生しないようにするには、予め決められた順序でデータにアクセスするなどプログラミング方法に制限が必要になったり、トランザクションを実行する前に全てのロックを取得したりなどの並行性への制限が必要になります。
実際には、そうするのではなくデッドロックの発生を許容し、検出し一方を中断させてリトライする方法がとられます。
デッドロックの検出方法は主に以下の二つがあります。
1. timeout-bases detection
トランザクションが概ねかかる時間よりも長い時間かかっていた場合は、デッドロックとみなす検出方法です。以下の特徴があります。
- 実装が比較的簡単
- デッドロックしていないものも中断される
- タイムアウトになるまでデッドロックを許してしまう
2. graph-based detection
ロックを待たれているトランザクションへの有向グラフ(waits-for graph)で循環するとデッドロックとみなす検出方法です。

トランザクションが別のトランザクションへロック待ちが発生すると、待っているトランザクションのノードから待たせているトランザクションのノードへ矢印を伸ばします。デッドロックが発生しているときは、二つ以上のノードでロック待ちの矢印が循環します。それを定期的に確認することでデッドロックを検出します。
Victim Selection
デッドロックが起こった時に、ロックされているトランザクションの内一つを中断させる必要があり、それをvictimと呼びます。
victimは再度デッドロックを起こさないように、少し遅延させて再実行されます。
どのトランザクションをvictimに選ぶかはいくつか方法がありますが、再実行したトランザクションが再度デッドロックを起こさないように考慮する必要があります。このデッドロックと再実行の連鎖をcyclic restartと呼びます。
分散システムにおいては、複数のデータベースが異なるノード上に存在し、トランザクションがそれぞれにアクセスします。
その場合、従来通りそれぞれでロックをデータにアクセスする前に獲得しますが、デッドロックの検証に考慮が必要になります。
あるノードのデータベースに存在するレコードxをDBx、別のノードのデータベースに存在するレコードyをDByとします。
r1(x), r2(y), w1(y), w2(x)の場合、デッドロックになりますが、それぞれのデータベースではr1(x), w2(x) on DBx, r2(y), w1(y) on DByとなっており、ただロックを待っているだけにそれぞれから映ります。
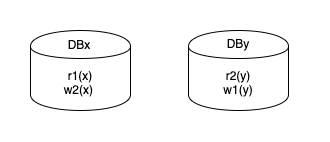
分散システムにおけるデッドロックの検出方法の一つとして、あるノードに検出する役割を担わせて、別のノードは自身のwaits-for graphを送り、それらを統合して全体のデッドロックを検出する方法があります。他には、timeout-bases detectionで検出することもでき、単体のシステムの場合と同じように利用できる点が利点になります。