各リンク先を引用・意訳しながらまとめています。
SREとは
- SREとは、あなたが「運用・作業」に対してソフトウェアの問題に取り組むかのように捉えることそのものです。
What is Site Reliability Engineering (SRE)? - Google Site Reliability Engineering
- SRE原則の最終目標は、サービスを改善し、さらにユーザー体験を向上させること。
- SREという概念は、各指標がビジネスの目標と密接に結び付いたものであるべきだ、という考えから始まった。
SRE の基本(2021 年版): SLI、SLA、SLO の比較 - Google Cloud
- SREチームとその理念の提唱者であるベン・トレイナー(Ben Treynor)は、「SREとは、ソフトウェアエンジニアがシステム運用を設計したら、どのような組織になるか」を体現したものだと語っています。
- SREは「運用作業の多くを自動化する権限と能力を持つエンジニアが、運用の責任を負う」という運用組織の新しい在り方なのです。
米Google SREディレクターに聞く、運用管理の意義、価値、役割 - atmarkit
サイト リライアビリティ エンジニアリング (SRE) の概要 - Microsoft Docs
エンジニア必見!Sreへの第一歩 - slideshare
SRE の基本と組織への導入 〜 サービスレベル目標やエラー予算などサービスの信頼性に対する考え方〜
SREとはなにか [サイト リライアビリティ エンジニアリング] - sreake
[レポート] SRE の基本と組織への導入 〜サービスレベル目標やエラー予算などサービスの信頼性に対する考え方〜 #GoogleCloudDay - Classmethod
今更だけど、SREとは何かについてまとめる- Qiita
SRE的プラクティスのここがよかった/ダメだった集 - Qiita
CAMPFIRE SRE - note
SREが普及しない原因とSREを突き進める最初の一歩 - Qiita
SREエンタープライズロードマップ
SREの基本
- 何らかのサービス レベル目標(SLO)を決め(開発、事業部門の一部でない場合は、これらの部門のメンバーと共同で)、ほぼ毎月目標を達成していること
- 非難を伴わない障害報告書を記録するカルチャーがあること
- 本番環境におけるインシデントの管理プロセスが作られていること(これは全社的であることが望ましい)
SRE チームの評価に役立つレベル別チェック リスト - Google Cloud
1. SLO(サービスレベル目標)
- SLOは、サービス顧客の信頼性の目標レベルを設定します。
- このしきい値を下回ると、ユーザーは不平を言い始めたり、サービスの使用を停止したりする可能性があります。
- 最終的には、ユーザーの幸せが重要です。
- 幸せなユーザーはサービスを使用し、組織に収益をもたらし、カスタマーサポートチームに低い要求を課し、友人にサービスを推奨します。
- 私達は私達の顧客を幸せに保つために私達のサービスを信頼できる状態に保ちます。
Implementing SLOs - The Site Reliability Workbook
2. Postmortem(事後検証/障害報告書)
- 私たちの経験は、真に非難のない事後検証文化がより信頼性の高いシステムをもたらすことを示しています。
- 障害報告書が良い書き方をされており、それに基づいたアクションがあり、広く共有されるのであれば、組織の前向きな変化を推進し、繰り返しのサービス停止を防ぐための非常に効果的なツールになります。
Postmortem Culture: Learning from Failure - The Site Reliability Workbook
3. Incident Response(インシデントの管理プロセス)
- 私たちはどうしてもサービスの停止が発生してしまう不完全な世界に住んでいます。
- インシデントを解決するということは、影響を軽減したり、サービスを以前の状態に復元したりすることを意味します。
- インシデントの管理とは、インシデントに対応するチームの取り組みを効率的に調整し、インシデントの担当者とインシデントのプロセスに関心のある人の両方の間でコミュニケーションが行われるようにすることを意味します。
- インシデント管理の基本的な前提は、構造化された方法でインシデントに対応することです。
Incident Response - The Site Reliability Workbook
SREの原則
1. リスクの受容
- SREが正確には何を行うのか、またそれについてどのように推論するのかについて最も広い視野で理解したい場合は、「Embracing Risk(リスクを受け入れること)」 を参照してください。
- リスクのレンズを通してSREを見ていきます。つまり、その評価、管理、およびエラーバジェットの使用により、サービス管理に有用な中立的なアプローチを提供します。
2. SLO(Service Level Objective:サービスレベル目標)の定義
- Service Level Objectives(SLO)も、SREの基本的なコンセプトのうちのひとつです。
- 業界では一般的に、Service Level Agreements(SLA)という一般的な旗印の下に異なる概念をひとまとめにするため、これらの概念を明確に考えることが難しくなっています。
- 「Service Level Objectives(サービスレベル目標)」は、合意(Agreements)と指標(Indicators)を目標(Objectives)から切り離すことを試み、SREがこれらの各用語をどのように使用しているかを調べ、独自のアプリケーションに役立つメトリックを見つける方法に関するいくつかの推奨事項を提供します。
3. 分散システムモニタリング
- Google であろうと他の場所であろうと、監視は本番環境で適切な作業を行うために絶対に不可欠な要素です。
- サービスを監視できない場合、何が起こっているのかわかりません。
- また、何が起こっているのかがわからない場合は、信頼性がありません。
- 監視対象と監視方法に関する推奨事項や、実装に依存しないベスト プラクティスについては、 「分散システムの監視」をお読みください。
4. Toil(トイル)の削減
- 「Eliminating Toil(トイルの削減)」は SREの最も重要なタスクの1つであり、「トイルの削減」の主題です。
- 私たちはトイルを、永続的な価値を提供しない平凡で反復的な運用作業であり、サービスの成長に比例して拡大するものと定義しています。
5. 自動化の推進
- 「The Evolution of Automation at Google(Googleにおける自動化の推進)」 では、自動化に対するSREのアプローチを検証し、SREが自動化をどのように実装したか(成功した場合と失敗した場合)についていくつかのケーススタディを紹介します。
6. 適切なリリースエンジニアリング
- ほとんどの企業は、リリースエンジニアリングを後付けとして扱います。
- ただし、「Release Engineering(リリースエンジニアリング)」で学習するように、リリースエンジニアリングはシステム全体の安定性にとって重要なだけではありません。
- ほとんどの停止は、何らかの変更をプッシュすることによって発生しています。
- リリースエンジニアリングは、リリースの一貫性を確保するための最良の方法でもあります。
- ただし、「Release Engineering(リリースエンジニアリング)」で学習するように、リリースエンジニアリングはシステム全体の安定性にとって重要なだけではありません。
7. シンプルさ
- 信頼性指向のエンジニアリングだけでなく、あらゆる効果的なソフトウェアエンジニアリングの重要な原則であるシンプルさは、一度失われると取り戻すのが非常に困難な性質です。
- それにもかかわらず、古い格言にあるように、機能する複雑なシステムは、機能する単純なシステムから必然的に進化しました。
- 「Simplicity(シンプルさ)」は、このトピックについて詳しく見ていきます。
Part II. Principles - The Site Reliability Workbook
SRE原則:7つの基本ルール - dotcom-monitor
最近よく聞くSREって何? 定義から実践に向けたロードマップまで解説【デブサミ2021夏】 - CodeZine
SREの実践
Dickerson's Service Reliability Hierarchy(Dickersonのサービス信頼性の階層構造)
- Service Reliability Hierarchy(サービス信頼性の階層構造) を利用して、最も基本的なものから高度なものまで、サービスの信頼性を高める要素を見ていきます。

1. Monitoring(監視)
- 監視がなければ、サービスが機能しているかどうかさえわかりません。よく考えて設計された監視インフラストラクチャがなければ、盲目のまま飛び回っているようなものです。Webサイトを使用しようとするすべての人がエラーを受け取るかもしれませんしそうでないかもしれませんが、ユーザーが気づく前に問題を認識したいと考えています。ツールと哲学については「Practical Alerting from Time-Series Data(時系列データから生まれる実用的な監視)」で説明しています。
2. Incident Response(インシデント対応)
- SREはめったにオンコールを行いません。むしろ、オンコールサポートは、より大きなミッションを達成し、 実際に機能するか(そして失敗するか)について連絡を取り合うために使用するツールです。ポケベルを持ち歩かなくてよい方法が見つかれば、そうするでしょう。「Being On-Call(オンコールであること)」では、オンコールの義務と他の責任とのバランスをどのように取るかについて説明します。
3. Postmortem / Root Cause Analysis(ポストモーテムと根本原因分析)
- 私たちは、私たちのサービスによって提示された、新規のエキサイティングな問題のみがアラートされ、手動によって解決されることを目指しています。同じ問題を何度も何度も「修正」するのはひどく退屈です。実際、この考え方は、SREの哲学と従来の運用重視の環境との間の重要な差別化要因の1つです。
- 「Postmortem Culture: Learning from Failure(事後検証文化: 失敗から学ぶ)」で説明されているように、非難のない事後検証文化を構築することは、何が悪かったのか(そして何が正しかったのか!)を理解するための最初のステップです。
- その議論に関連して、「Tracking Outages(停止の追跡)」では、SREチームが最近の本番インシデント、その原因、およびそれらに対応して取られたアクションを追跡できるようにする、内部ツールである停止トラッカーについて簡単に説明します。
4. Testing + Release procedures(テストとリリース手順)
- 何がうまくいかない傾向があるかを理解したら、次のステップはそれを防ぐことです。テストスイートは、ソフトウェアが本番環境にリリースされる前に、特定のクラスのエラーを発生させないという保証を提供します。これらの最適な使用方法については、「Testing for Reliability(信頼性のためのテスト)」で説明されます。
5. Capacity Planning(キャパシティプランニング)
- 「Software Engineering in SRE(SREのソフトウェアエンジニアリング)」では、キャパシティプランニングを自動化するツールであるAuxonを使用したSREのソフトウェアエンジニアリングのケーススタディを提供します。
- 当然のことながら、キャパシティプランニングに従って、ロードバランシングにより、構築したキャパシティが適切に使用されていることが保証されます。
- 「Load Balancing at the Frontend(フロントエンドにおける負荷分散)」で、サービスへのリクエストがデータセンターに送信される方法について説明します。
- 次に、「Load Balancing in the Datacenter(データセンターにおける負荷分散)」と「Handling Overload(過負荷の処理)」で説明を続けます。
6. Development(開発)
- サイトリライアビリティエンジニアリングに対するGoogleのアプローチの重要な側面の1つは、組織内で大規模なシステム設計とソフトウェアエンジニアリング作業を行うことです。
7. Product(製品)
- 最終的には、信頼性のピラミッドを登っていくこと、実用的なプロダクトを手に入れることができました。「Reliable Product Launches at Scale(大規模な信頼性のあるプロダクトローンチ)」では、Googleがどのように信頼性の高い製品を大規模にローンチし、ユーザーに可能な限り最高の体験をゼロから提供しようとしているのかについて説明します。
Part III. Practices - The Site Reliability Workbook
SRE初級者チーム
- Google の SRE チームは、全部ではなくてもそのほとんどが、次のプラクティスと特長を確立しています。チームが置かれた環境にこれらの実現を阻むもっともな理由がないかぎり、私たちはこれらを、優れた SRE チームの基礎だと考えています。
- 人員の配置転換と採用のプランがあり、予算が承認されていること
- スタッフを配置したチームが何らかのサービスのオンコール サポートを担当するとともに、少なくともシステム運用の負荷(トイルの削減)の一部を担っていること
- リリース プロセス、サービスのセットアップとティアダウン(そして可能ならフェイルオーバー)のためのマニュアルを整備していること
- SLO の一部としてカナリア リリースを評価していること
- 必要なときのためにロールバック メカニズムを用意していること(ただし、たとえばモバイル アプリケーションが関係するときは簡単ではないことが考慮されます)
- 完全でなくても、運用手順書(プレイブック / ランブック)があること
- 少なくとも年 1 回は理論的な(ロールプレイングによる)ディザスタ リカバリ テストを実施していること
- SRE がプロジェクトの仕事を立案、実施していること(開発者の支持を必要としない運用負担軽減の取り組みなど、開発者から直接見えない部分でもかまいません)
- 次の項目も、発足したばかりの SRE チームで一般的になっているものです。こういうものがなければ、チームが不健全で持続可能性に問題がある兆候かもしれません。
- 定期的に(つまり毎週)インシデント対応手続きの訓練をする程度のオンコール
- SRE の統括責任者(つまり CTO)が審査、承認した SREチーム憲章
- 問題点や目標について議論し、情報を共有するための SREと開発リーダーの定例会議
- 開発とSREの共同作業によるプロジェクトの立案、実施。SRE の貢献とプラスの効果が開発のリーダーにも見えていなければなりません
SRE チームの評価に役立つレベル別チェックリスト - Google Cloud
SREの誤解
- 他の組織で見たおもな誤解は、早期の障害検出に重点を置いたSLO(Service Level Objective)や、あるいは過去のインシデントの金銭的保証に使用するSLA(Service Level Agreement)との混同、エラー予算を執行しない、SREチームの活動の少なくとも50パーセントをシステムやツールの改善に費やさず、“消防活動”という名の運用上の苦役に没頭させる、といったものだ。
Googleが解説 - 他社のSRE実践はなぜ誤りなのか - InfoQ
DevOpsとSREの違い
DevOpsが扱う5つの領域
- DevOpsが扱う5つの領域
- Reduce organizational silos(組織のサイロを削減する)
- Accept failure as normal(エラーが発生するのを前提とする)
- Implement gradual change(段階的に変更する)
- Leverage tooling and automation(ツールと自動化を活用する)
- Measure everything(全てを計測する)
- DevOpsはinterfaceであり、その実装がSREである = class SRE implements DevOps
| DevOps | SRE |
|---|---|
| 組織のサイロを削減する (= チーム間のコラボレーションの促進) |
権限をシェアする (= SREチームの権限を開発チームに委譲) |
| エラーが発生するのを前提とする (= システムは必ず壊れるものとして計画を立てる) |
エラーバジェット / ポストモーテム (= エラーの計画的受け入れ / 原因の究明) |
| 段階的に変更する (= 導入やロールバック、切り分けを簡単にする) |
カナリアリリース (= リリース時のリスクの削減) |
| ツールと自動化を活用する (= 効率化し、人為的なミスを減らす) |
共通ケースの自動化 (= トイルの削減) |
| 全てを計測する (= 上記4つの領域の成功させるため) |
トイルと信頼性(Reliability)の計測 (= 成果の確認とSLO/SLI/SLAの定義) |
DevOpsとSREの違いとは? - Visonal Engineering Blog
SREとDevOpsの違いはなにか - Sreake Blog
SRES VS DEVOPS – SREとDEVOPSの違いとは - DevSamurai
DevOps と SRE - coursera
SRE用語
SLO / SLA / SLI
SRE の基本(2021 年版): SLI、SLA、SLO の比較 - Google Cloud
SLA、SLO、SLI の比較: 相違点は何か? - ATLASSIAN
SLO
- Service Level Objective(サービスレベル目標)
- システムの可用性の正確な数値目標
1. サービスレベル目標(SLO) - Google Cloud
Service Level Objectives - The Site Reliability Workbook
Setting SLOs: a step-by-step guide - Google Cloud
The Art of SLOs - Google Site Reliability Engineering
これからはじめる 実践 SRE / SLO の監視をやってみよう - google-cloud-jp
- Googleの典型的なSLOは次のようなものだ。
- 1ヶ月間99.9パーセントの稼働率(1ヶ月のダウンタイムが43分)
- 1ヶ月間のHTTP要求の99.99パーセントが200 OKで成功する
- 50パーセントのHTTP要求が300ms以内に返答される
Googleが解説 - 他社のSRE実践はなぜ誤りなのか - InfoQ
SLO設定のための実践ガイド
- クリティカルユーザージャーニー(CUJ)をリストアップし、ビジネスへの影響によって並べ替える。
- ユーザーエクスペリエンスを最も正確に追跡するために、サービスレベル指標(SLI)として使用するメトリックを決定する。
- SLOとSLO測定期間を決定する。
- SLI、SLO、およびエラーバジェットコンソールを作成する。
- SLOアラートを作成する。
Setting SLOs: a step-by-step guide - Google Cloud
SLA
- SLA:Service Level Agreement(サービスレベル契約)
- 通常 SLA では、サービス可用性 SLO が一定期間に特定のレベルを満たすことをサービス ユーザーに約束する契約が規定されています。
- これを怠った場合は、なんらかのペナルティが課せられます。
- たとえば、その期間に顧客が支払ったサービス利用料金の一部払い戻しや、利用時間の無料延長などがあります。
2. サービスレベル契約(SLA) - Google Cloud
- SLAは、一般的にはユーザがすでにサービスに対して不満を抱いている場合に意味を持つものであるため、システムの信頼性を積極的に向上するものではない
Googleが解説 - 他社のSRE実践はなぜ誤りなのか - InfoQ
SLI
- Service Level Indicator(サービスレベル指標)
- サービスの動作を直接測定したもの
- たとえば、...サービスの信頼度を把握するには、SLI として成功したクエリと失敗したクエリの割合を測定できる必要があります。
- システムをゼロから構築する場合は、SLI と SLO を必ずシステム要件に含めてください。
- すでに本番環境システムがあり、SLI と SLO を明確に定義していない場合は、それを定義する作業が最優先になります。
3. サービスレベル指標(SLI) - Google Cloud
Tune up your SLI metrics: CRE life lessons - Google Cloud
一般的なSLIとしては以下があげられる
SLI 重要度 説明 リクエストのレイテンシ ◎ リクエストに対するレスポンスを返すまでにかかった時間 可用性 ◎ サービスが利用できる時間の比率。処理に成功した正常なリクエストの数の比較で計測されることが多い エラー率 ◯ 受信したリクエストに対する比率であらわされる場合が多い システムスループット ◯ 毎秒のリクエスト数 「注目しているサービスレベルを直接的に計測することが理想だが、望ましい計測値の取得や解釈が難しい場合は、代用の値を使う場合もある」
SLIの方程式
good events / valid events * 100
Setting SLOs: a step-by-step guide - Google Cloud
パフォーマンス指標
I/O
- I/O とは、コンピュータシステムと外部環境(ユーザー、ネットワーク、周辺機器など)との間のデータのやり取りのこと。
- 入力 (Input): システムが外部から受け取る信号やデータ。
- 出力 (Output): システムが外部へ送信する信号やデータ。
スループット
- 単位時間あたりにシステムが処理(転送、計算、リクエスト完了など)できる「データ量」または「操作回数」を示す指標。
- データ転送の場合、bps(bits per second)やBps(Bytes per second)などの単位で測定される。
- 一定期間内に処理されたリクエスト数や転送されたファイルサイズなど。
レイテンシ
- 特定の操作(例: I/Oの読み書き)の開始から完了までに要する時間、すなわち「遅延時間」を示す指標
- 単一の操作やリクエストに対して、処理開始から終了までに経過する時間を計測することで、システムの反応速度や即応性を評価する
パーセンタイル
- データを昇順に並べたとき、全体の中で特定の割合(%)のデータがその値以下となる「境界値」を示す統計指標。
- これにより、分布の中でどの位置にあるか(例:中央値や上位何%かなど)を評価できる。
- ユーザー体験の保証やパフォーマンスのボトルネックの検出に役立ち、SLAとしても利用される。
- 99.9パーセンタイル
- 値が「14.5s」の場合、全リクエストの99.9%が14.5s以内に完了していることを示す
- 99パーセンタイル
- 値が「14.5s」の場合、全データの99%が14.5s以内に完了していることを示す
- 95パーセンタイル
- 値が「14.5s」の場合、全データの95%が14.5s以内に完了していることを示す
- 50パーセンタイル(= 中央値)
- 値が「14.5s」の場合、全データの50%が14.5s以内に完了していることを示す
テイルレイテンシ
- 全体の中で最も遅い一定割合(例: 99パーセンタイルや99.9パーセンタイル)のリクエストにおける応答時間を示す指標。
- システム性能の評価や最適化の際、テイルレイテンシの低減は重要になる。
IOPS(Input/Output Per Second)
- 1秒間にシステムが処理できるI/O(読み込み、書き込みなど)の回数を示す指標。
- 数値が高いほど、より多くのI/O操作を短時間で処理できる性能があることを意味する
- 例: 「100 IOPSが保証されているストレージ」とは、理論上、1秒間に最大100回のI/O操作(例:ファイルの読み込みや書き込み)が可能であることを示す。
クリティカルユーザージャーニー
- (カスタマージャーニーの中で特に重要な数個の)"ユーザーにとって"重要な体験、期待。
- SLI/SLOを定義する前に、エンジニアだけでなくビジネスサイドも参加して検討・定義されるもの。
- SLIによって数値的に計測される。
- ユーザーが(最終的に)目的を達成するためにサービスと(何回か)行うやり取りのこと。
- 例1: 「ユーザーが購入手続きボタンをクリックし、カートが処理されて領収書が返されるレスポンスを待ちます。」
- 例2: 商品の一覧を確認できる、商品を検索できる、ほしい商品を購入できる、など
SLO の定義 - Google Cloud
これからはじめる 実践 SRE / SLO の監視をやってみよう
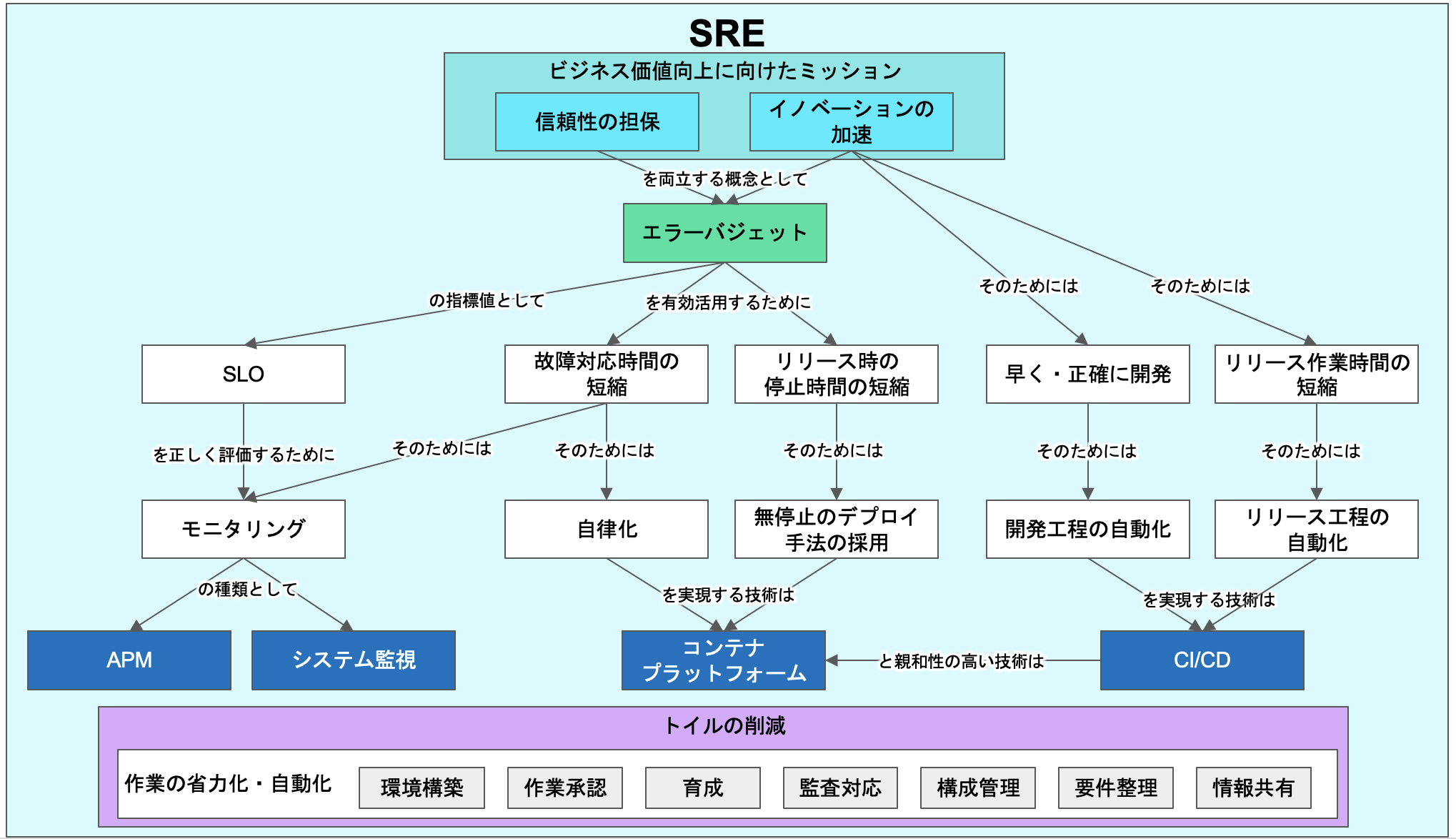
エラーバジェット
- 簡単に言うと、エラー バジェットは、ユーザーが不満を感じ始めるまでの一定の期間にサービスで累積できるエラーの量です。
- これをユーザーの忍耐度と考えることができますが、可用性やレイテンシなどサービスの特定のディメンションに適用されます。
メンテナンスの時間枠がエラー バジェットに与える影響 - SRE のヒント - Google Cloud
- エラーバジェット: 許容される信頼性の損失を表したもの。SLOを満たせなかった度合い。
MackerelでSLOとエラーバジェットを運用するためのツール shimesaba - KAYAC engineers' blog
- エラーバジェット(Error Budgets)とはエラーに対する予算であり、SLOに基づき算出される損失可能な信頼性である。
- サービスの計測された稼働時間がSLOを超えている、換言すればエラーバジェットがまだ残っている状態であれば、チームは新しいリリースをプッシュ(デプロイ)できる。
- エラーバジェットはプロダクトマネージャーによって規定される客観的なメトリクスであり、SREとプロダクト開発者の緊張を取り除くものである。
エラーバジェットとは - CAMPFIRE 開発チーム note
ポストモーテム
- SRE サイトリライアビリティエンジニアリング1によると、インシデントとそのインパクト、その緩和や解消のために行われたアクション、根本原因(群)、インシデントの再発を避けるためのフォローアップのアクションを記録するために書かれるドキュメントを指します。
- 言い換えると、失敗(障害)から学び、再発防止策を決める活動です。
- 「ポストモーテム」(postmortem=事後検証)とは、システムにインシデントが発生したことによる影響、緩和や解決のために取られた行動、インシデントの原因、再発防止策などをまとめた文書です。
SREチームでポストモーテムを1年半運用してみた - KAYAC engineers' blog
- ポストモーテム(Postmortem)とは想定外のインシデントが発生した後に書かれる内部向けの報告書である。
- ポストモーテムの目的は組織的な学習であり、インシデントの細部を明らかにするために非難のない文化を重視する。
- ポストモーテムは、インシデントとそのインパクト、その緩和や解消のために行われたアクション、根本原因(群)、インシデントの再発を避けるためのフォローアップのアクションを記録するために書かれる。
ポストモーテムとは - CAMPFIRE 開発チーム note
- ポストモーテムはプロジェクトマネジメントの文脈ではレトロスペクティブと同様に「振り返り」を意味しますが、SREの文脈ではいわゆる障害報告書を意味します。
ポストモーテムの文化 - エムティーアイ エンジニアリングブログ
ポストモーテムの取り組み - Wantedly Engineering Handbook
カナリアリリース
- カナリアリリースとは、新バージョンのアプリケーションをリリースする際、最初からすべてのユーザーに公開するのではなく、まず一部のユーザー(全体の1%など)に限定公開してテストを行い、所定の基準をクリアすることができれば、一般に向けて公開する手法です。
- カナリアリリースは、「ブルーグリーンデプロイメント」の一種です。ブルーグリーンデプロイメントに「テスト工程」を加えたものがカナリアリリースだといえます。
カナリアリリースとは?ブルーグリーンデプロイメントとの違いや実施方法を紹介 - SE Design
- ロールバックは早期に行い、頻繁に行うこと : この哲学に従うようにサービスを持っていけば、サービスの平均修復時間(MTTR)を削減できます。
- ロールアウトではカナリアを使うこと : どれだけテストや QA を実施したとしても、実稼働のトラフィック上でバイナリ リリースに問題が見つかることは少なくありません。効果的なカナリア戦略を取り入れ、正しく監視することで、問題の平均検知時間(MTTD)が短縮でき、影響を受けるユーザー数も大幅に削減できます。
カナリアのおかげで命拾い : CRE が現場で学んだこと - Google Cloud
- カナリアリリースとは新バージョンのアプリケーションをリリースする際に、従来バージョンのアプリケーションを並行稼働させ、一部のユーザーだけを新バージョンにアクセスさせる展開(デプロイ)手法のこと。新バージョンにアクセスするユーザーを炭鉱で毒ガスを検知する「カナリア」に見立てて、この名称が付けられた。
- GoogleやNetflixのようにWebサービスを提供している企業では、そのWebサービスに次々と改良が加えられ、1日に何度も新しいリリースがデプロイされています。
- しかし新しいリリースのデプロイはいきなり大規模に行われるわけではありません。リリースされるコードに対しては継続的デリバリのパイプラインの中で一通りの自動テストが行われ、ある程度の品質が保証されているはずです。
- しかし、それでも新しいリリースに何らかのバグなどが含まれている可能性を排除できません。
- そこで新規リリースはまず、本番環境全体に対していきなりデプロイされるのではなく、ごく一部のユーザーだけに利用されるように小さな割合でリリースされます。
- そしてしばらくその振る舞いが観察され、問題がないと判断されてから大規模にデプロイされるのです。
- 一般に、このような試験的なリリースを小規模に行うこと、あるいはその対象となるリリースは「Canary Release」(カナリアリリース)と呼ばれています。
GoogleとNetflix、カナリアリリース分析ツール「Kayenta」オープンソースで公開。新たにデプロイしたリリースに問題がないかを自動分析 - Publickey
- ZOZO API GatewayはURIパスベースのルーティング機能を提供し、ルーティング先であるターゲットをまとめたターゲットグループという単位でカナリアリリースの機能を提供します。
ZOZOTOWNマイクロサービスの段階的移行を支えるカナリアリリースとサービス間通信における信頼性向上の取り組み - ZOZO TECH BLOG
ブルーグリーンデプロイメント
- ブルーグリーンデプロイメントとは、新バージョンのアプリケーションを公開するにあたり、現バージョン(ブルー)と新バージョン(グリーン)の両方を並行して稼働させ、切り替えにより公開します。切り替えは一瞬でできるため、稼働停止時間なしに公開できるのがメリットです。
- ブルーグリーンデプロイメントでは、現バージョンから新バージョンへの切り替えは初めから全ユーザーに向けて行います。それに対してカナリアリリースでは、最初は一部ユーザーにのみ限定公開してテストを行い、テストをクリアして初めて全ユーザーに公開されます。
カナリアリリースとは?ブルーグリーンデプロイメントとの違いや実施方法を紹介 - SE Design
トイル
- トイル(Toil)とは直訳すれば「労苦」であり、プロダクションサービスを動作させることに関する作業で、手作業で繰り返し行われ、自動化することが可能であり、戦術的で長期的な価値を持たず、作業量がサービスの成長に比例するといった傾向を持つものを指す。
- SREにおける重要な概念の一つであり、SREは日常的にトイルに対応しつつも、最低50%以上はエンジニアリングに当てるべきであるとされる。
- 「トイルとは、手作業、繰り返される、自動化が可能、戦術的、長期的な価値がない、サービスの成長に比例して増加する、といった特徴を持つ作業です。」
- トイルの例としては次のようなものがあります。
- 割り当てリクエストの処理
- データベース スキーマ変更の適用
- 重要性の低いモニタリング アラートの確認
- プレイブックからのコマンドのコピーと貼り付け
トイルを洗い出す
- 測定すべきものをきちんと測定し始めれば、状況を示したうえで賛同を得ることができる、ということです。
- 作業の種類(割り当ての変更、本番環境へのリリースの移行、ACL の更新など)
- 作業の難易度: 容易(1 時間未満)、普通(数時間)、困難(数日)(経過時間ではなく実際の作業時間で判断)
- 作業者
- どのくらいの時間をトイルに費やしましたか。全体に占めるおおよその割合を、過去 4 週間の平均値でお答えください。
- 0~100%
- トイルに費やした時間の長さについてどの程度満足していますか。
- 非常に不満 / 普通 / まったく問題ない
- トイルの発生源として多いものを 3 つ教えてください。
- オンコール対応 / 割り込み / プッシュ / 許容量 / その他
- 四半期目標に長期のエンジニアリング プロジェクトが含まれていますか。
- はい / いいえ
- 「はい」の場合、どのくらいの時間をエンジニアリング プロジェクトに費やしましたか。全体に占めるおおよその割合を、過去 4 週間の平均値でお答えください(概算値でかまいません)。
- 0~100%
- 自動化のためのトイルに長期プロジェクトの作業時間を奪われるため、自動化できるのにそうしていないトイルがチーム内にありますか。ある場合は、下に記入してください。
- 自由回答
トイルを測定する
- さまざまな種類の作業にどのくらいの時間が費やされているのか、その概算値を定期的(毎月または 3 か月に 1 回が適当)に求めます。
- チケット、アンケート、オンコール インシデント対応別にパターンや傾向がないかを探し、費やされた作業時間の合計に基づいて優先順位を付けます。
- Google SRE 内では、トイルに割かれる SRE 1 人あたりの時間を 50% 未満に抑え、残りの 50% をエンジニアリング プロジェクトの作業用に確保することを目標にしています。
- トイルの割合が 50% のしきい値を超えていることが概算値からわかった場合は、この値を減らして作業の割合を健全な状態に戻すことを目標に、明確な作業計画を立てます。
トイルを解決する
- 簡単に自動化できるケースばかりではありません。また、すべてのトイルをなくすことを目指すべきでもありません。
- ほとんど行わないタスク(新しいロケーションへのサービスのデプロイなど)の自動化は難しい場合があります。
- というのも、再度同じタスクを行う頃には、自動化したときに使用した手順や想定した前提が変化している可能性があるからです。
- この種のトイルに多大な時間を費やしているとしたら、基盤アーキテクチャを変更することでそうした変動を小さくできないか検討してください。
- たとえば、システム管理に Infrastructure as Code(IaC)ソリューションを使用しているか、副次的な悪影響を与えずにその手順を何回も実行できるか、手順を検証するテストを行っているか、などです。
- 自動化の作業も他の本番環境システムと同様に扱います。
- SLO プラクティスを採用している組織の場合は、エラーバジェットの一部を使ってトイルを自動化してしまいましょう。
- 自動化に失敗した場合は事後調査を行い、ユーザー向けシステムの場合と同様に問題を修正します。
- 本番環境のインシデントも含め、どのような状況でも自動化を利用できるようにして、チームメンバーには各自の得意な作業をしてもらえるようにする必要があります。
- チケットを開いてサポートをリクエストする方法をユーザーがすでに知っている場合は、チケット システムを API として使用して自動化を行い、すべての作業をセルフサービスで行えるようにします。
- また、トイルは技術的なものばかりでなく習慣的なものでもあるため、この作業を行うのはトイル作業を明示的に割り当てられた人だけになるようにしてください。
- オンコール担当者がこの役目を引き受ける場合もありますが、当番制にしてエンジニアが順番で「チケット」や「割り込み」の処理にあたることもできます。
- このようにすると、それ以外のチームメンバーがプロジェクト作業を行う時間が確保されるうえ、トイルを明らかにして責任をもって対応するカルチャーが醸成されます。
SRE の原則に沿ったトイルの洗い出しとトラッキング - Google Cloud
サイロ化
- サイロとは「独立している」状態のことで、開発側・運用側のチーム同士がうまく連携できていない状態を指します。
- お互いの組織に溝があることで生じる弊害を無くすため、DevOpsでは組織のサイロ化の削減を大きな指針のひとつに掲げています。
SREとDevOpsの違いはなにか - Sreake Blog
- 技術が先行しすぎると専門性でチーム同士がサイロ化してしまい、組織の構造だけが先行してもチームで個別最適化しすぎてしまいます。
- 単に自動化すればよかったのか?単にチームを小さくすればよかったのか?否、技術と組織の思想が噛み合うことで、ようやくたった一歩だけ前進できるのです。
Self-Serviceとサイロ化と組織構造 / Self-Service, Siloing and Organizational Structure - SpeakerDeck
- N : そうですね。元々、ソフトウェアがコード化する前って開発と運用が同じ組織だったんですけど、コード化することによってその二つで開発組織、運用組織に分かれちゃいましたという経緯があって、開発部隊はたくさん機能をリリースしたいっていうのがあって、運用部隊は一方で安定した運用をしたい、なのでアクティブにサービス開発を進めたい開発チームと安定的にサービスを運用したい運用チームっていうのは根本的にモチベーションが逆行しちゃう。で、そこがコンフリクトの原因になって自分たちのやりたい思いっていうのがサービス自体に向かなくなってくるというのがサイロの一番の課題だと思っています。
e34fmの#3からSREについての概要を文字起こししてみた - Zenn
SRE Next
SRE NEXT 2022 ONLINEの発表資料まとめ - Qiita
【SRE Next 2020】発表資料まとめ - Qiita