自己紹介
渋谷 充宏 @mshibuya
- 株式会社オプト データテクノロジー開発部 チームマネージャー
- 広告効果計測ツール「ADPLAN」 SREチームリーダー
- Ruby / Scala / インフラ
- https://github.com/mshibuya
- RailsAdmin/CarrierWave committer
- ScalaMatsuri2019に「Scalaライブラリを作る前に知っておきたいメンテナンスのこと」という内容で登壇します!!
アジェンダ
- この発表について
- これまでのあらすじ
- プラクティスたちとその振り返り
- まとめ
この発表について
今回は、SRE本で紹介されているうち重要だと考えるプラクティスについて、実際にやってみたりやろうとしてみたりした結果
- うまくいったこと
- うまくいかなかったこと
- こうすればよかったと思うこと
- こうしていきたいと考えていること
などを取り上げます
これまでのあらすじ
オプトで開発・運用している広告効果計測ツール「ADPLAN」の運用に課題感があり、2018年よりSREチームを新たに立ち上げました…という流れです。
その背景等は以前のSRE Lounge #5にて発表した「広告代理店でSREチームを立ち上げるためにやったこと」に詳しいので、そちらもあわせてご覧ください!
SRE本
言わずと知れたOreilly社刊「SRE-サイトリライアビリティエンジニアリング」のことです
SREチームを立ち上げるならメンバー全員が目を通している状態にしたいですね

今回取り上げるプラクティスたち
チームやプロセスとして取り組むものを中心に選んでいます
- エラーバジェット(3章)
- サービスレベル目標の策定(4章)
- トイルの削減(5章)
- オンコール対応(11章)
- インシデント管理(14章)
- ポストモーテム作成(15章)
エラーバジェット(3章)
- SREにおける重要な考え方
- 機能を開発しリリースすることと信頼性のバランスを取るためにある
エラーバジェットが提供するのは、1つの四半期内でサービスの信頼性がどの程度損なわれても許容できるかを示す、明確で客観的なメトリクスです。
とはいえ…
- 「システム落ちてもいいですよね?」って合意を取るのは難しい。少なくとも「落ちるリスクを負ってでも得たい何か」がないと受け入れられ難い
- そういう課題感があり、弊社ではまだ実践できていない
- 機能を開発しリリースする速度や、信頼性のためにリリースを差し止めた時間などをメトリクスとして可視化した上で、それらが改善していくこととセットにして導入していけたらよさそう
サービスレベル目標の策定(4章)
- 「SLO」と略される
- どの程度の品質のサービスを提供することを目指すのかについての目標値
- 似たやつ
- サービスレベル指標(SLI)
- サービスレベルアグリーメント(SLA)
絶対作りましょう
- SREというのは信頼性への取り組みなので、その目指されるべき信頼性を定義しないのはナンセンス
- 信頼性というのは無限にコストをかけ続けられるので、どのくらいのレベルで十分なのかが定義されていることが大事
- 状況に合わせ変化させていくことも大事と思うので、そろそろ改定したい(もう1年くらい経ってしまったし)
- SLO違反となることがビジネス上どんなインパクトをもたらすのか、とも紐づけた状態にできるといいな
トイルの削減(5章)
- SRE本的ではSREの活動の時間を「ソフトウェアエンジニアリング」「システムエンジニアリング」「トイル」「オーバーヘッド」の4つに分けている
- トイルとは、運用上必要となるオペレーションのこと。自動化可能であったり、長期的価値を持たなかったり、サービスの成長とともに増大する傾向を持っていたりする
- これを削減していくことはSREにとってとても大事。そうでなければ、未来の信頼性向上のためのエンジニアリングに時間を投資できなくなる
- GoogleではSREの作業時間のうちトイルが占める割合を50%以内に抑えるようにしている
やったこと
togglによる作業時間のモニタリング
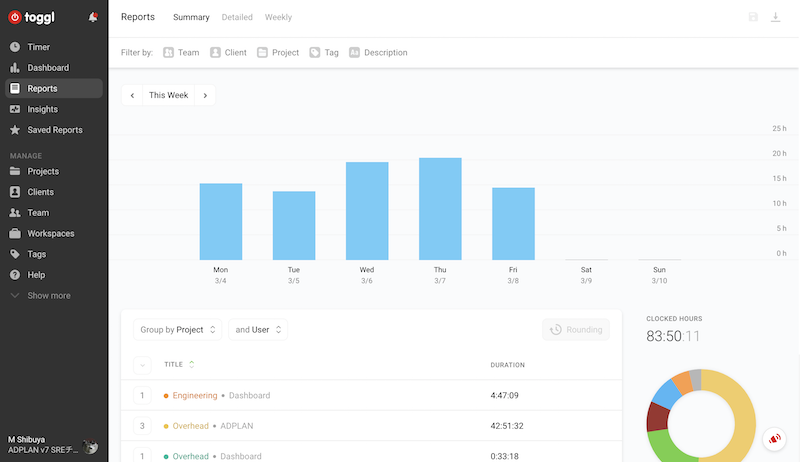
効果あった?
- toggl自体はなかなかよかった。常に何をすべき時間かを意識させられるので、漫然と時間を過ごしてしまうことが減る
- トイルを減らすことに役に立ったか、といわれるとよくわからない。そもそも作業時間のうち50%以上トイルになることはほぼ起きない
- 運用上「あのへん課題があるよね」ってなったら普通に改善タスクを積むので、トイルが増大してはじめて改善しなくちゃみたいなのはあまり起きにくいのかも?
- (そもそもオーバーヘッドの割合が大きくなり過ぎだったりしませんか…?)
オンコール対応(11章)
- 監視システムが発する緊急アラートを受け、問題を解消するアクション。SREが担う業務として代表的
- 弊社では勤務時間外も含むオンコール当番を1週間単位で回している。現状SREチームは3人なので、3週間に一回順番が回ってくる
「低すぎる運用負荷」問題
- 最近システムも安定してきており、緊急対応が必要なアラートが発生する頻度がかなりまれになった
- それ自体は好ましいことだが、緊急事態に対応できるスキルを磨く機会が減ることによりいざという時困ることが起こりそう
- 対策として、SREチームが担当する範囲を他プロダクトへも拡大することによって対応の頻度を上げ、適切な緊張感が保たれるような対応を進めている
インシデント管理(14章)
- SRE本では、緊急事態への対応を効果的にするためインシデント管理フレームワークをつくることを勧めている
- 責任の再帰的な分離
- インシデント指揮者・実行作業・コミュニケーション・計画
- 明確な司令所
- ライブインシデント状況ドキュメント
- はっきりとした引き継ぎ
- 責任の再帰的な分離
あんまりできてないです…
- 緊急事態にはみんなテンパってしまうのは明らかなので、有用性は認識している
- ただ、ちゃんと体制を作るのが大変そう。ただ作っただけでは定着もしないので、繰り返し訓練を行い無意識に出るレベルになっている必要がある
- 部分的にやるだけでもメリットは十分ありそうなので、このくらいから始めてみるのもよさそう
- インシデント宣言の条件・手段を決める
- 緊急事態におけるコミュニケーション場所(例:Slackチャンネルとか)を定義
- インシデント指揮者を選定することを明文化
ポストモーテム作成(15章)
- SREにとって欠かせないツール
- 発生したインシデントについて、以下のような内容を記録するためのもの
- インシデントとそのインパクト
- その緩和や解消のために行われたアクション
- 根本原因(群)
- インシデントの再発を避けるためのフォローアップのアクション
- Googleでは「非難のないポストモーテム」の文化を大切にしているそう
頑張って書いてます
- めちゃくちゃためになる。読んでも楽しい
- ポストモーテムの内容を使って障害事例レビュー会をやったりもしている
- どういうときにポストモーテムを書くべきかでたまに迷う
- 基本的にはユーザ影響があったときとかだが…
まとめ
- SRE本で取り上げられているプラクティスのうち、発表者が重要だと考えるものを取り上げました
- それらについて、弊社で実際に取り組んだり取り組もうとしてみたりした結果どうだったかをご紹介しました
- この発表が、皆様がSRE体制を構築しより信頼性を高めビジネス上の価値につなげていくための一助となれば幸いです
- オプトではSREをはじめエンジニア絶賛募集中です!