自己紹介
渋谷 充宏 @m4buya
- 株式会社オプト テクノロジー開発部 チームマネージャー
- Ruby / Scala / インフラ
- https://github.com/mshibuya
- RailsAdmin/CarrierWave committer
- ISUCON8本戦に「チーム人間性」で出場します!!
アジェンダ
- プロダクトについて
- SREチームの立ち上げ前
- SREチーム立ち上げにあたってやったこと
- 結果どうなったか
- 今後どうなっていきたいか
プロダクトについて
広告効果計測ツール「ADPLAN」
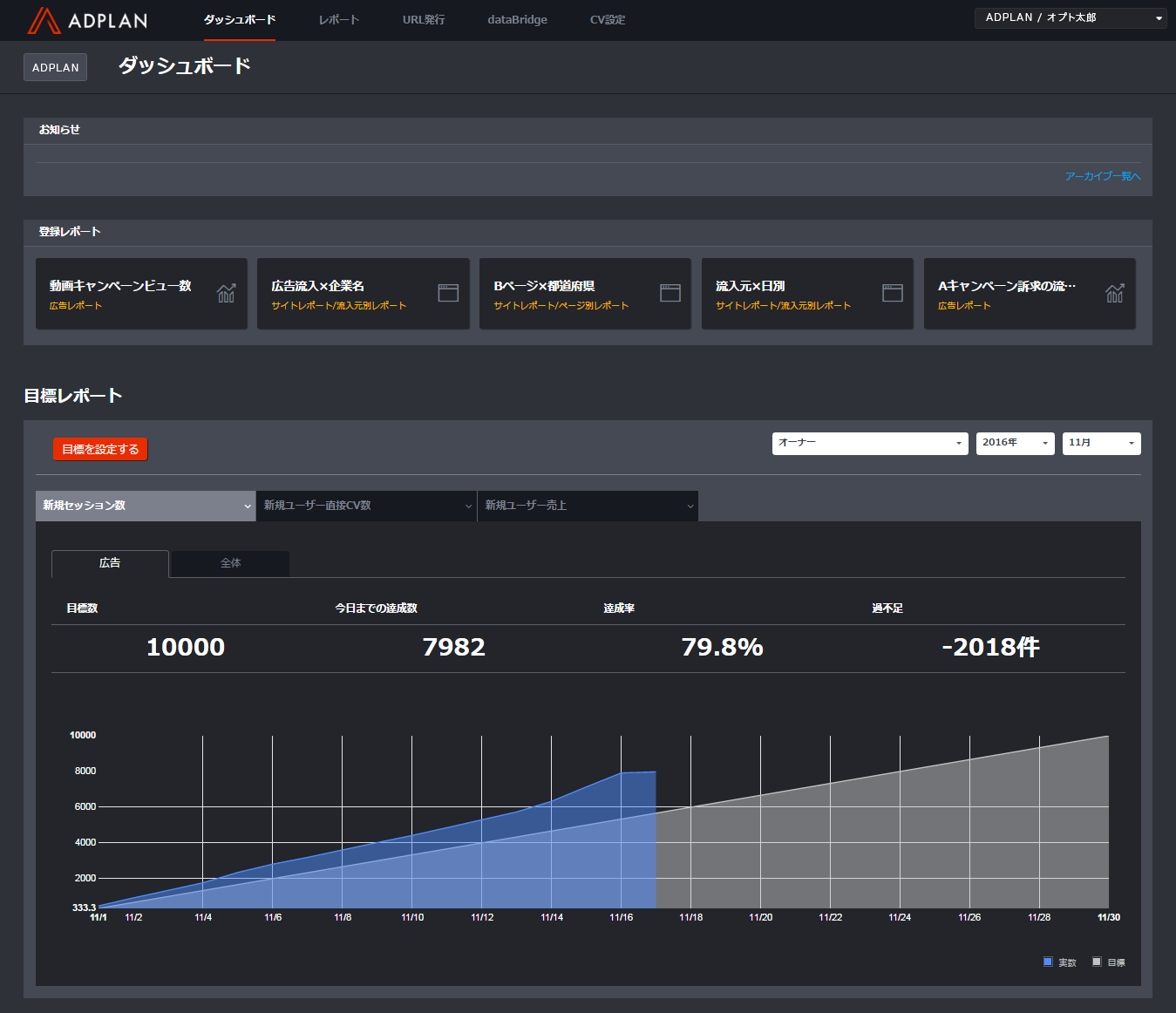
広告効果計測ツール「ADPLAN」
- 2000年にサービス開始した、広告効果計測ツールの草分け的存在
- その後更新を重ね、最新のバージョンは7。2016年9月サービスイン
- ユーザがバナー広告やリスティング広告をクリックし、お客さんのサイトに遷移し、商品を購入して…といった一連の行動を集計し、広告ごとにどのくらい成果が上がっているのかを示せる
プロダクトの特性
- 大きく計測・集計・画面の3部分に分かれる
- 計測部分は高信頼性が必要
- 特に、応答が返せなくなるのはデッドリンクとなってしまい最悪
- 集計は毎時行っており、遅延するとCS低下
アーキテクチャ
- AWS様サイトに掲載されているインタビュー記事(
AWS オプトで検索)
SREチームの立ち上げ前
体制
- 機能系開発チーム
- ユーザが求めていたりビジネス価値に直結する機能の開発
- 非機能系開発チーム
- パフォーマンス
- 信頼性
- セキュリティ
- インフラの維持管理も
SREチーム立ち上げ前の体制
- 開発当初よりInfrastructure as Codeなプラクティスは実践できていた
- 「システムに対し定常的なオペレーションが必要になるなら必ず自動化する。それゆえ運用タスクというのは発生しない」というポリシー
課題感
- 限られたメンバーしか緊急対応を担うことができない
- あまり自信がないから手を出せない→いつも同じ人が対応するのでノウハウが広まらないの悪循環
- 「ベストエフォートでの障害対応」では責任感頼みとなり、持続可能でない
- 他の開発タスクが優先され、信頼性向上が進まない
SREという考え方との出会い
- SRE本
- SRE Meetup Tokyo
運用タスクや障害は「運が悪ければ発生するもの」ではなく、「発生する前提で準備しておくべきもの」であるとの思いを強くした
立ち上げのためにやったこと
やったこと:組織として
- 3名のメンバーからなる独立したSREチームとして組織した
- 交代で時間外も含めた緊急対応当番を回すようにした
- 負担が増える分、評価に上乗せ
- 他チームとは独立したバックログを持ち、主体的に優先度を決められるようにした
やったこと:組織として
- 名刺の肩書きに「SRE」と入れた

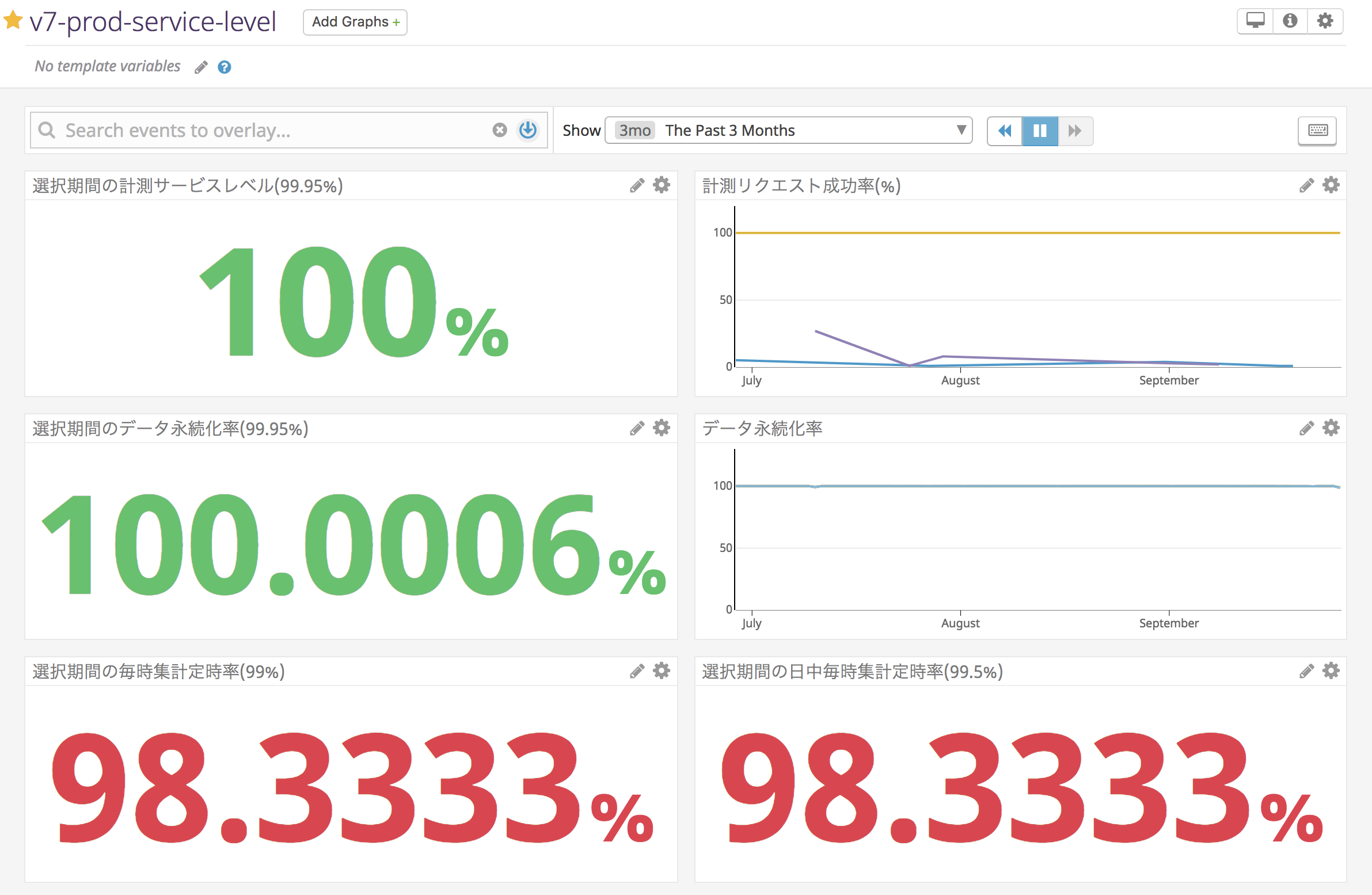
SLO策定
ビジネスインパクトや直近の実績値も踏まえ、妥当かつ客観的に計測可能なことを意識して設定
直近の3ヶ月間における
- 計測リクエスト成功率99.95%以上
- 計測データ永続化率99.95%以上
- 集計定時完了率99%以上
- うち、日中については定時完了率99.5%
- 日次集計・外部集計がすべてAM9:00までに完了
- 画面のリクエスト成功率99.9%以上
サービスレベル可視化
やったこと
- SRE本輪読会
- 障害対応トレーニング
- 障害事例共有会
やったこと:技術的に
信頼性関連の開発が大いに進展した
- デプロイシステムの微妙なところとか改善
- 監視周りの細かい調整
- セキュリティ(進行中)
結果どうなったか
- 3人のSREチーム内で緊急対応の当番を回せる体制を作れた
- 「オペレーションでカバーする」みたいなタスクが減り、より本質的な作業に使える時間が増えた
- 本番で緊急ではないちょっとした問題が起きている、みたいな時も機動的に対処がしやすくなった
- 「我々がシステムの信頼性を担っているんだ」というチーム感が生まれた(と思っている)
今後どうなっていきたいか
エラーバジェットの運用
サービスレベルは可視化されたものの、そこに現れた達成状況を次のアクションに反映させる、という点はまだこれから
- 問題部分の改善タスクの優先度を上げる
- 問題のあったコンポーネントをあまり触らないようにする
- 開発項目を先送りする。とはいえビジネス価値との兼ね合いも…
プロダクトチームを超えた展開
現状はひとつのプロダクトチームの中で閉じた取り組みであり、組織を横断するような取り組みとはなっていない
- とはいえプロダクトごとに技術スタックもモニタリングもまちまちで、プロダクト横断でできる部分はそんな多くなさそうな…?
ミッションの拡大
現状SREチームとして明確に責任を持っているのは「信頼性」のみ
- すなわち、一般にSREチームの守備範囲とされているパフォーマンスやコストなどについても信頼性に直結する部分しか見ていない
まとめ
- 手探り感は大きいものの、一定の成果は出せているはず
- 同じように手探りで運用のあり方を模索している皆様と情報交換したい!
- オプトではSREを含め、エンジニア絶賛募集中です!!