去年のはこちら。
2025年振り返り
去年は以下だった。
- 業務でやったこと
- 個人の学習
- 就職活動
1年を通して副業が増えたり減ったりして、しかも記憶に残ったトピックに取り留めがなかった。去年は仕事と同じくらいプライベートも忙しかったので、技術の振り返りとプライベートの振り返りで分けて書いてみようと思う。
- 技術の振り返り
- プライベートの振り返り
- 今後について
技術の振り返り
AIコーディングを学んだ
去年まではそれほど使っていなかったが、今年に入ってから X での盛り上がりが加速したように感じ、最初は Cursor を使い始めた。
色々あって、今は Claude Code を使うことに落ち着いた。
普段の業務での開発プロセスとしては、Claude Code に以下の3ステップで進めてもらっている。
- Confluence / Jira の内容(実装のベースとなる要件や仕様)を Atlassian MCP 経由で読み込んでもらう
- 実装計画を立てて、(Claude Code と自分で)議論する
- 実装計画に基づいて、実装してもらう(テストコードを先に書くか後に書くかは気にしていない)
これは、Claude Code のベストプラクティスの記事を読んだときに、
Explore, plan, code, commit
- Ask Claude to read relevant files, images, or URLs
- Ask Claude to make a plan for how to approach a specific problem.
- Ask Claude to implement its solution in code.
- Ask Claude to commit the result and create a pull request.
Steps #1-#2 are crucial ... asking Claude to research and plan first significantly improves performance for problems requiring deeper thinking upfront.
日本語
探索、計画、コーディング、コミット
- Claude に関連ファイル、画像、URLを読み取るように指示する
- Claude に特定の問題に対するアプローチの方法を計画してもらう
- Claude にその解決策をコードで実装してもらう
- Claude に結果をコミットしてPRを作成してもらう
ステップ1と2は非常に重要です。...クロードに事前に調査と計画を立ててもらうことで、パフォーマンスが大幅に向上します。
とあり、これに従っていて、このプロンプトのテクニックがとても上手くいっているように感じる。
あとは、Claude Code をターミナル(iTerm2)上で実行しながら ChatGPTもChromeで開いて仕様、設計、実装などを相談しながら進めたりしている。
バイブコーディングをどのように行うかはいろんな意見があるように感じるが、自分のスタンスとしては、AIが理解できるようなオンボーディング環境の整備を行なっていくことで、コードレビューなどの開発プロセス内の人同士のコミュニケーションが減っていく方向性に進んで欲しい。
CLAUDE.md(AGENTS.md)、ドメイン知識・機能の仕様・オペレーション・コーディングルールに関するドキュメント、正しいスコープのチケット、自動テスト、リンターやフォーマッターなどが揃っているかどうかで、自分が書きたいコード、あるいは自分の期待を満たすコードをAIに出してもらえるかが決まるように思う。
実際には、コードの実装を進めたことで初めて明らかになる仕様が存在したり、モデルが読み取るコンテキストが増えれば増えるほどアウトプットの精度が不安定になってしまったりで、AIとのペアプログラミングをしながらの試行錯誤ではあるが、今後もこの方向性を意識して開発に取り組んでいくことで、AIのモデルの進化に応じたメリットを享受できるようにしていけるといいんじゃないかなーと思っている。
先の Claude Code ベストプラクティスのドキュメントにもあるが、git worktrees の活用など、キャッチアップができていないテクニックも多く、来年はもっと上手く使えるようになりたい。
ここら辺のスキルは組織や個人によってスキルの関心度合いと成熟度合いに差があるように思うので、自分がどういう風に向き合えば良いか悩ましいところでもある。
Jira を使った開発プロセスについて学んだ
これまで、いくつかの Jira を使っている会社で働いたことがありはしたのだが、(ただ単に自分がこれまで意識できていなかっただけかもしれないが、)これまで以上に Jira のより多くの機能を使うようになった。
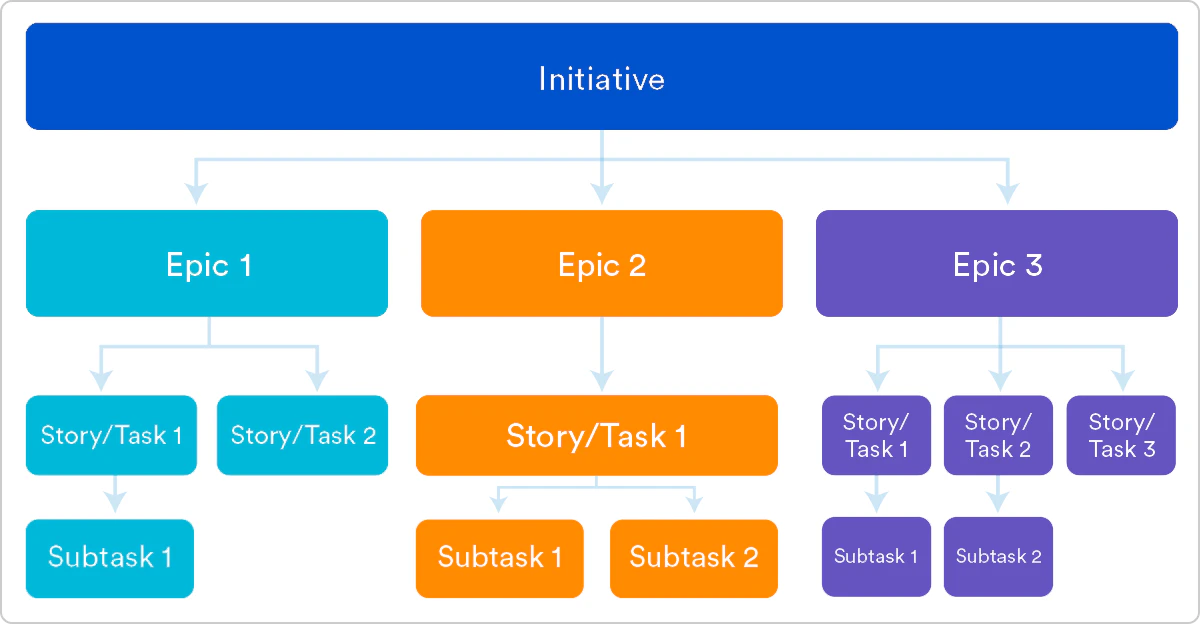
具体的には、(これは ChatGPT に Atlassian の記事をまとめてもらったのだが、)アジャイル開発の階層構造が存在していて、 Jira のチケットにもレベルが存在することを理解した。
| レベル | 説明 |
|---|---|
| Initiative | 複数の Epic を束ねる上位の目的・フォーカス領域。 事業・組織レベルの目標や成果を表し、「なぜそれを行うのか」を表す。 Jira では標準課題タイプではないが、Advanced Roadmaps やカスタム課題タイプとして用いられる。 |
| Epic | 複数の Story / Task を包含する大きな作業単位。 単一のストーリーでは提供できない価値を表し、通常は複数スプリントにまたがる。 関連する作業を束ねる論理的なコンテナ。 |
| Story(ユーザーストーリー) | ユーザーまたは利用者の視点で記述された、価値提供の最小単位。 原則 1 スプリント以内で完了可能なサイズであり、「誰が/何を/なぜ」を明確にする。 Epic に紐づき、プロダクトバックログやスプリントバックログに直接配置され、見積・計画・完了判定の対象となる。 |
| Task / Subtask | 実装・設定・調査などの作業単位。 Story と異なりユーザー価値そのものは持たないが、Story と並列に Epic 配下に配置される。 技術的対応や内部作業を表現するために使われることが多い。 |
※ 「ロードマップ」は、プロダクトの方向性と優先度を組織全体(POと開発チームだけでなく、経営層や他部門を含む)で共有するための資料。Initiative、Epicが紐づけられる。
階層構造の具体例1(KPI改善)
| レベル | 説明 | 実務に即した具体例 |
|---|---|---|
| Initiative | 組織戦略・事業目標 | 新規ユーザーの初回離脱率を Q2 までに 30% 改善する |
| Epic | 大きな成果・価値単位 | ログイン・サインアップ体験の改善 |
| Story ① | ユーザー価値単位 | 新規ユーザーとして、入力ミスがあっても何が間違っているかすぐ分かるようにしたい |
| Task | 入力項目ごとのバリデーションルールを定義する | |
| フロントエンドで即時バリデーションを実装する | ||
| エラーメッセージの文言をユーザー向けに改善する | ||
| Story ② | ユーザー価値単位 | 新規ユーザーとして、パスワード入力時に要件を事前に理解したい |
| Task | パスワード要件(文字数・文字種)を UI に表示する | |
| パスワード入力欄に表示/非表示切り替えを追加する | ||
| Story ③ | ユーザー価値単位 | 新規ユーザーとして、登録完了までに何ステップあるかを把握したい |
| Task | サインアップフローのステップ数を整理する | |
| 進捗インジケーター(Step UI)を実装する | ||
| Story ④ | ユーザー価値単位 | 新規ユーザーとして、認証メールが届かない場合でも手詰まりにならないようにしたい |
| Task | 認証メール再送 API を実装する | |
| 再送可能条件・回数制限を実装する | ||
| 再送時・失敗時の UI メッセージを実装する |
階層構造の具体例2(インフラ改善)
| レベル | 具体例 |
|---|---|
| Initiative | 障害検知までの平均時間(MTTD)を 10 分以内にする |
| Epic | API の監視とアラート設計の改善 |
| Story | 利用者として、障害が起きてもすぐ復旧してほしい |
| Task / Subtask | API レイテンシのメトリクスを追加する |
| エラーレートに基づくアラートを設定する | |
| アラート閾値を段階的に分ける | |
| 障害時の通知先(Slack / PagerDuty)を整理する |
階層構造の具体例3 (開発者体験改善)
| レベル | 具体例 |
|---|---|
| Initiative | 新規開発者の立ち上がり時間を 1 日以内にする |
| Epic | ローカル開発環境セットアップの簡略化 |
| Story | 開発者として、README を読めばすぐに開発を始めたい |
| Task / Subtask | ローカル環境構築手順を整理する |
| Docker Compose を導入する | |
| 初期データ投入用スクリプトを作成する | |
| セットアップ手順を README に反映する |
この Jira のアジャイルプロジェクト管理の階層構造にある程度基づくと、会社の毎期の経営レベルの目標から、1人の開発者の作業や工数の単位にある程度落とすことができる。
昨年までは業務委託として働いていて、自分は何年も毎期ごとの目標設定をすることがなかった。今年正社員になって、久しぶりに個人の毎期ごとの目標設定を持つようになった。
この目標設定が、自分の役職(ミドルのエンジニアなのか、シニアのエンジニアなのか、マネージャーなのか、etc) によって決まり、例えばシニアのエンジニアであれば今期2つの Epic を達成する、N個の Story を消化する、というような形で、組織の階層構造と Jira のアジャイルプロジェクト管理の階層構造に基づいてロードマップからブレイクダウンされた自分の目標が明確に設定することができる点はなるほどーとなった。
スタートアップだとタスク管理に Notion を使っているところも多い印象だが、今回の体験を経て、たとえ大規模組織ではなかったり厳密なスクラムの定義に沿う必要がないのだとしても、 Jira とアジャイルのプラクティスの上である程度プロダクト開発のライフサイクルが定義される方が個人的には好み、というスタンスになった。
少し話は逸れるが、Atlassian が提唱するアジャイル開発について ChatGPTと話していたら、どうやら以下のようなプラクティスが存在していそうなことがわかった。
- アジャイル開発において、顧客に機能のリリース日を約束することはできない。
- 顧客との契約上は target や best effort になる。
- POは、経営層や他部門に対してロードマップに基づく確定的なリリースの日付を約束できない。
- POの役割は、日付を断定することではなく、不確実性を管理し意思決定に必要な情報を提供すること。
- どの Initiative / Epic を優先するか
- 現時点での最も妥当なリリース見通し(予測)
- 不確実性・前提条件・リスクの言語化
- 状況が変わった場合に、その理由と影響の共有
- POの役割は、日付を断定することではなく、不確実性を管理し意思決定に必要な情報を提供すること。
- Epic に対して「何スプリントで必ず完了するか」を事前に確定的に約束しない。
- Epic の完了時期は、以下に基づく予測として算出される
- Epic 配下に分解された Story の見積り
- チームの過去実績(ベロシティ)
- この予測は、学習・変更・スコープ調整に応じて更新されるものであり、契約や確定期限として扱わない
- Epic の完了時期は、以下に基づく予測として算出される
- スプリントとリリースは別物。
- スプリント途中でもFeature Flagなどによって1日に複数回リリースされ、Storyもクローズされる。
- アジャイル開発において、QAは常に行われる。
- スプリント開始前段階で、 Story の受け入れ条件の明確化とテスト観点の洗い出しを行う。
- Story は受け入れ条件(Acceptance Criteria)を満たして初めて、 Done となる。
- スプリントの最後にまとめてテストを行わない。
- Story は実装視点ではなく、検証可能な価値単位で分解する。
これらのプラクティスの内容を踏まえて思ったのは、これは過去繰り返されてきた話題なのかもしれないが、
「人月と納期」 vs. 「アジャイル開発におけるリリース計画」
という観点で考えたとき、ビジネスサイドが「いつまでにどのようなものができるか」という期待を持つことからは避けられないように感じる一方、アジャイル開発のプラクティスはそれを曖昧にしてしまう印象を受ける。
納品のない受託開発 を提唱する企業もあったり、個人事業主の準委任契約もアジャイル的な考え方なのかなと思う。
というのもありつつ、1人の開発者としては、正確な見積もりを行うことは技術力が求められるスキルでもあると思うし、いつまでにどのようなものができるか、という期待に正しく応えられるようなコミュニケーションを目指すというか、仕事としてそこに説明責任を持っていくことは、大変だけれども大事なことだろうなー、と改めて思う一方、目標設定とグッドハートの法則(『指標が目標になると良い指標でなくなる』)の狭間を感じる。
開発プロセスに紐づくドキュメントについて学んだ
ドキュメントの扱いも会社によってまちまちのように感じるが、今の会社では大体以下で説明されているような感じで、ドキュメントの種類が存在しているところが良かった。
とくにこれまでの自分の経験では、社内ドキュメントとして PRD(Product Requirements Document / プロダクト要求定義書)が存在しないか、それらしいドキュメントがあったとしても網羅的な要求を示したものではなかったり、あるいは実質Figmaのデザイン自体が仕様となるかで、PMとデザイナーの責任の境界がわからなかったり、どこまで詰める必要があるのかわからずこちらでよしなに進めてしまったりしていたが、PRDがあると、プロダクトのマイルストーンとそのスコープ/ Epic の調整、仕様の矛盾、暗黙の前提や疑問、改善余地について、PMに対してPRDへのコメントという形でコミュニケーションを取ることができる。
軽く調べた感じだと、 Figma の社内で利用されていると思われる PRDが例として良さそうだった。
(Figma の PRD サンプルは Reddit を漁っていたら見つけた)
同様に、開発者向けのドキュメントのテンプレートも複数あると、要件定義が必要なのか、設計が必要なのか、実装の詳細が必要なのか、といったことが、ドキュメントごとに混在しなくて良い、と思う一方、開発者向けのドキュメントとしてはそこまで厳密に分ける必要はないのかも。
要は、開発チームの構成メンバーとしてPM・デザイナー・エンジニア・QAが存在している場合に、各メンバーの責任範囲が何で、疑問の種類に応じて誰にコミュニケーションを取るべきかが成果物(PRD、Figma、Design Doc、テスト仕様・設計書)ベースではっきりしていると、前提とするコンテキストが明確だし、職種間のコミュニケーションが取りやすくて良いなと思った。
また、このドキュメント運用プラクティスの前提として、少なくともプロジェクトの期間中は、各ドキュメントの作成者としての責任者が、自身の作成したドキュメントを途中で生じたフィードバックを反映しながら最新の内容に更新し続ける必要はあるため、各ドキュメントは書いて終わりではなく、離れられないという大変さはあるかなと思う。
またしてもやや話は逸れるが、ここまでで出てきたように、"責任" - 組織において"誰"が"何"に責任を持っているか、ということについては「DRI - Directly Responsible Individual(直接責任者)」、「RACI - Responsible(実行責任者), Accountable(説明責任者), Consulted(協議先), Informed(報告先)」、「Disagree and commit(異議はあってもコミットする)」とった考え方についても意識するようになった。
イベント駆動型アーキテクチャについて学んだ
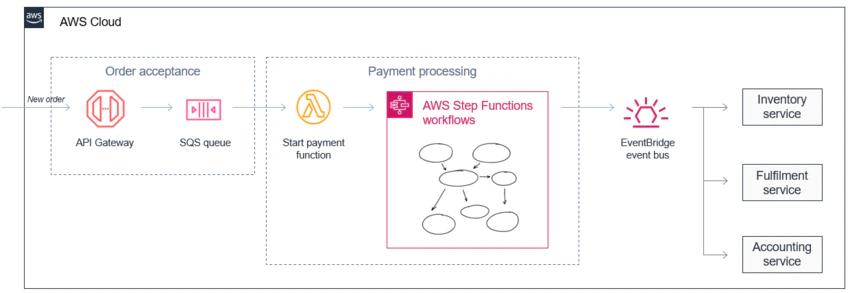
例えば以下は、AWSの『EDA (イベント駆動型アーキテクチャ) とは何ですか?』というドキュメントからの引用だが、
この例では、Order acceptance サービスは、SQS queue にメッセージをバッファリングすることで、大量の注文を格納できます。
Payment processing サービスは、支払い処理の複雑さから通常は処理が遅くなりますが、SQS queue から安定したメッセージストリームを取得できます。
Payment processing サービスは、 AWS Step Functions を使用して複雑な再試行やエラー処理ロジックをオーケストレーションし、数十万件もの注文に対応するアクティブな決済ワークフローを連携させることができます。
1年前の時点では、上記の説明が何を言っているのかよくわからなかった。
これを理解するには、先の引用の内、前提として以下の用語を理解しておく必要がある(ChatGPT と会話しながら作った雑な説明)。
A (Publisher) -> B -> C (Consumer)
のようにリクエストが流れる分散システムがある時、
-
ストリーム
- 継続的に生成されるイベントのデータ列。
- A により発生したイベントが B に蓄積され、 C はそれらを処理可能なデータ列として消費する。
-
バッファ
- B において、A と C の処理速度差を吸収するためにデータを一時的に保持する仕組み。
- C が B からイベントを取得する方式には、ポーリング型(pull)と通知型(push)がある。
Fluentd 実践入門 の1章における用語説明もわかりやすいので引用すると、
ログは、コンピュータシステムの動作中は継続的に発生し続けるデータです。
ログの期間に対する区切りは、多くの場合、人間の都合によるものです。
通常、ログとログの間に区切りはなく、ログは休みなく発生し続け、一つ一つのログが大量に連なって存在します。こういった種類のデータをストリームと呼びます。
継続的に発生するストリームを、発生した端から即座に集約する処理がストリーム転送です。
実際には、データが発生するはしから1件1件読み込むたびに個別に処理していたのでは、処理性能が極端に低下し、誰にとっても満足できないものになります。
これを避けるため、通常のストリーム処理系では、ある程度データのとりまとめや一時的な保存を行い、数件あるいは数秒、場合によってはもっと長い単位でデータをまとめて処理します。
このデータをまとめる場所をバッファ(buffer)、まとめる処理およびまとめたデータを扱う処理をバッファリング(buffering)と呼びます。
ストリームやバッファといった概念は、イベント駆動型アーキテクチャのプロジェクトを経験させてもらったり、担当サービスのデプロイのワークフローの洗い出しを行う中で Fluentd の概要について学んでいくうちに理解できるようになったが、おそらく大学の授業などでC言語やシステムプログラミングを学ぶ中で理解する概念なのだろうと思う。
自分はAWSからコンピュータを学んでいるキャリアなんだなーと感じる。
上記の用語の理解と各AWSサービスの特性を踏まえると、元の『EDA (イベント駆動型アーキテクチャ) とは何ですか?』というドキュメントの引用は以下のように説明し直すことができる。
Order acceptance サービスは、SQS queue にメッセージをバッファリングすることで、大量の注文を格納できます。
Order acceptance サービスは、注文リクエストが API Gateway に大量に送信されても、SQS queue を用意しておくことによって、それらのリクエストを直接 Start payment function の Lambda に渡さずに、一旦 SQS queue で保持し、SQS メッセージとして大量に積んでおく(= バッファリングする)ことができる。
Payment processing サービスは、支払い処理の複雑さから通常は処理が遅くなりますが、SQS queue から安定したメッセージストリームを取得できます。
Payment processing サービスの Lambda は、支払い処理の複雑な実装のせいで1件あたりの処理完了が遅くなり、さらに短時間に大量のリクエストが到着すると、 Lambda インスタンスが並列で多く立ち上がろうとして、同時実行数の上限(デフォルトでは同一アカウント・同一リージョンあたり1,000インスタンス)に達し429エラーを引き起こしてしまうことがある。しかし、前段に SQS queue があることによって、大量のリクエストを Lambda で即時に処理することなく、処理が完了して空きが出た分だけ、次のリクエストを Lambda の同時実行数の上限以内で段階的に処理できる。
Payment processing サービスは、 AWS Step Functions を使用して複雑な再試行やエラー処理ロジックをオーケストレーションし、数十万件もの注文に対応するアクティブな決済ワークフローを連携させることができます。
Payment processing サービスは、複数の Lambda からなる決済処理を、 AWS Step Functions を使用して呼び出すことによって、複数の Lambda の複雑な再試行(リトライ)やエラー処理ロジックを一連の処理の流れとして定義し、数十万件もの注文リクエストが来ても、それを並列で状態に応じて安全に処理できるような決済ワークフローとして扱うことができる。
...と説明し直してみたが、実際にコンソールの画面やドキュメントなどで各設定値を確認しないとピンと来ないかもしれない。
あとは SQS と Lambda の連携における設定値がしばらくよく理解できず、
- Lambda 関数に紐づく Event Source Mapping というリソースが SQS をポーリングしていて、
- Lambda 関数が SQS のメッセージを取得すると、SQS ではそのメッセージが不可視状態となり、
- Lambda 関数の処理が成功した場合、Event Source Mapping は SQS のメッセージを削除(DeleteMessage)するが、
- Lambda 関数の処理がエラーやタイムアウトで失敗した場合、ESM は SQS のメッセージを削除せず、SQS が Visibility Timeout (他のコンシューマから取得不可になる時間)の満了後にメッセージを再び可視化し、1. に戻って再処理(= リトライ)される
という仕組みをしばらくしてから理解できて、この仕様に基づくため、SQS の Visibility Timeout は Lambda 関数の最大実行時間(Timeout)よりも長く設定する必要がある(AWSの推奨では 6倍)、ということも理解できた。
また、Lambda の前段に SQS を置く構成のベストプラクティスとしては、 指定回数以上のエラーが発生した場合のメッセージの送り先となる デッドレターキュー(DLQ)としての SQS キューもセットで設計する必要があるようで、大量トラフィックかつ信頼性を高く保つ要件がなければ正直面倒だなーという感想も持った。信頼性と、増えるコンポーネントのチームとしての管理コストのトレードオフだと思う。
といったように(結局あまりわかりやすい説明にはなっていない気もするが)、AWSの各サービスも、プロジェクトで経験したものに関しては理解を深めやすいが、そうでないものに関しては実際はなかなか難しかったりする(手段として、外部の学習コミュニティで学ぶという方法は自分も採ったし、とても良いと思う)。
エンジニアのキャリアとしては、このようなアーキテクチャに触れる経験をたくさん積めることが高い設計力を持つために大事であると思う一方、そのようなプロジェクトで成果を上げるために、前提としての基礎知識を身につけておく重要性を感じる。
なお、このアーキテクチャの話は以下の記事にとてもよくまとまっていました。
そのほか
時間ができたら追記したい。
- 社内の輪読会でマスタリングAPIアーキテクチャを読んで、ストラングラーフィグ、ファサード・アダプタの各用語の意味と、それらを用いたモノリスからマイクロサービスへの変更のアプローチを学んだ
- 社内サービスの現状のアーキテクチャ評価のため
- モノリス vs マイクロサービスを考えるときに、要因はいろいろあるとは思うが、自分の中ではマルチテナントのアーキテクチャとノイジーネイバー問題がわかりやすい話として思い浮かぶ。
- RDS(Aurora ではない)を使用しているプロジェクトに入り、RDS と RDS Aurora の違いについて学んだ
- レガシーなデプロイフローのアーキテクチャ図と設定値の洗い出しとボトルネックを特定するドキュメントを書いた
- 新規プロジェクトのプライマリキー選定のための uuid v4, ulid, uuid v7の違いを調べた
- Auto Increment IDは予測可能なため uuid が採用される -> 時系列順にソート可能な ulid が誕生 -> uuid v7 でも時系列順にソート可能に、という歴史を理解した
-
認可モデル、とくにRBAC(Role-Based Access Control)のレベルについて学んだ
- この Oso Authorization Academy がとてもよいドキュメントで、ユーザー独自のカスタムロールはGitHubでもエンタープライズプラン以外でサポートしていないくらいに大変、という話も出てきたりで面白かった
- 認可の設計の前提としては、三大要素(actor / action / resource)と、2種類のインターフェイス(Enforcement / Decision)を理解しておくのが大事
- Oso 紹介記事の 認可のアーキテクチャに関する考察(Authorization Academy IIを読んで) - Zenn もわかりやすかった
- Rack Middleware のタマネギの層構造 について学んだ
- HonoXとアイランドアーキテクチャと、shadcn 等の React 系ライブラリとの組み合わせに挫折した
- HonoXでshadcn/uiを使用する - yossydev Blog などの先行事例はあったが、レンダリングがとても遅くなってしまいそれを解決できず、結局 Next.js に移行した
プライベートの振り返り
結婚した
これまでのプライベートでは、無駄に酒を飲んで朝まで過ごすようなことが多かったので、もっと家庭的なプライベート時間を増やしていかないと自分の心身の健康も含めて人生が良くなっていかないかも、と思ったことがきっかけだった。
YouTube で話題になっている結婚相談所を薦められて入って、無事半年くらいで結婚する運びとなった。
土日に2,3人ずつ、約3ヶ月で40-50人くらいとお見合いさせてもらって、とても忙しかったが、その中で自分はどんな人間でどんな人が合っていて、みたいなことを繰り返し振り返られたのは良い経験だったし、何より素敵な人と出会うことができたのでとても良かった。
都度友人にも進捗を報告して、お前にはこういう人が合うとか合わないとか言ってもらったり、メンサポもしてもらって、とても助けられた。
家を買った
元々買う計画は持っていなかったが、2人で都内に住むとなると賃貸の家賃もかなりかかってしまうし、予想に反して妻がペアローンを組んでくれることに前向きであったことから、『価格が下がりにくいマンション【7つの法則】』と、自分たちの好みに基づいてマンションを買うことにした。
- 「駅近」であること
- 単価の低い郊外より高い都心エリア
- 大規模マンションは得をする
- 当該地域で有名なマンション
- ファミリータイプのマンション
- 周辺の相場を見極めて「高すぎない」こと
- 景気拡大(インフレ傾向)のタイミングを見極めること
7つの法則にすべて当てはまり、自分たちの与信で購入可能で、なお相場に対して割安な物件を探すのは難しく(そもそも出てこないか業者がすぐに買い上げてしまう)、仲介からは資産性を重視すると中央区、江東区の物件がまだ上がりきってないが、自分たちの住みたいと思えるところを優先した方が良いと提案してもらったりもして、結局は業者売主の(レインズマーケットインフォメーションの成約価格やマンションレビューの販売履歴と照らし合わせて分析すると割高にも感じてしまう)リフォーム物件を購入した。
不動産仲介もいくつかのところと話したが、大手の仲介は売主への交渉も慣れていて自分たちの提案以上の指値で値下げに繋げてくれたり、ネット銀行と提携していて住宅ローンがサイト掲載のものよりも安い金利で契約できたりしたので、不動産系インフルエンサー経由の動線で「信頼できる仲介」の方を紹介してもらいそこから家を買うことも考えたのだが、(その仲介の方が悪いわけではなく)契約時の条件を比較した時に、大手のところはいいなーという感想を持った。この感想は購入体験が仲介の担当者や物件の状況によって様々になりそうなので、個人差は大きそう。
この経験を振り返って、本当はもっと条件の良い物件に住みたかったし、そのためにも子供部屋が必要になって住み替えを行う頃にはもっとお金が欲しいなーと思っている。
車の免許を取る(途中)
妻が旅行好きなので車の免許を早めに取って欲しいということで、自動車の教習所に通い始めた。自動車の教習所には指定教習所と届出教習所という2種類があり、届出教習所の場合は授業を受けるために通う必要がないらしい(技能試験のために運転の練習で教習所に行く必要はある)。
最短で取らせてくれそうな届出教習所があって、そこで芸能人とかも行く免許試験の対策学校を教えてもらったりもして、3日くらいの勉強で(ギリギリ)仮免の学科試験に合格できた。
芸能人とかも行く免許試験の対策学校
ここには午前8時からの試験当日の午前5時半ごろにタクシーで行った。サインがたくさんあった。
具体的に何をやったかというと、
- 50問x5回分の問題と回答・解説の読み上げ音声を聞く
- 問題の演習をして、間違った問題のみその場で先生に解説してもらう
- 2.の問題演習を3回分ほど行う
- 最後に、これまで間違えた問題をもう一度見直す
上記を合計2時間半くらいかけてやったのだが、すごい短時間で定着してびっくりした。ここに行ってなかったら間違いなく落ちてたと思う。
今後何かの試験勉強を自分でやるときの参考にしたい。
本試験もまだあるので、また落ちないように頑張りたい。
今後について
去年の目標はシニアエンジニアになることと、英語を伸ばすことだったが、幸いどちらも達成することができた。
英語は親切にコミュニケーションをとってくれる同僚のおかげで期待していた以上に伸びた気もするが、自信を持って仕事するためにはもっと伸ばしていく必要があると感じるのと、昇進については、スタッフエンジニアになろうとすると今の自分のパフォーマンスではどれだけ短くてももう2, 3年はかかるだろうと思う。
となると、今年は焦らず仕事面では次のステップへのチャンスを伺う、種を蒔いていく、足がかりにするような年にできればいいと思う。
去年の振り返りを自分で振り返ってみると、あれを学んだこれを学んだ、という書き方になっている。今年以降、あれをやったこれを達成した、という書き方ができるようになったり、他者・組織に与えたインパクトや合意形成についての内容に重きが移っていくと、会社の評価や自分の視座の観点でもよい働き方になっていっていると言えるんじゃないかなと思う。
ただ、そのためには自分のプロジェクトに対してはより高いオーナーシップを持って、インプット・アウトプット・コミュニケーションの"量"自体を増やしていく必要性を感じたりもする。
去年も同じようなことを言っているが、1年間とても忙しかったので、プライベートを優先して奥さんともっと遊んだりしたいのと、興味のあることを見つけてそれに時間をかけたりしたい気持ちもある。
今関係がないがうっすら興味のあることとして、Dify、 n8n を活用したりとか、FDEという職種の文脈で顧客企業の社内業務改善を行うのが儲かっている事例が多そうに思えて、今後お金を儲けていく方向性としてこっちに活路があったりしないだろうかと思ったりもする。が、このトレンドの移り変わりも見通せないのでどうだかなーと思い、強く注力したいものが(決められ)ない。
(Dify の開発元企業の FDE 求人を見てみても、必須・歓迎スキルとして Docker, AWS, Kubernetes, Terraform というワードが目に付き、求められるスキル的にはクラウドインフラ系なのだろうかと思うと、今の自分はバックエンドメインのエンジニアだし、注力の方向性がそれほど変わるわけではないのかなー、という気持ちもある。)
いずれにせよ先にも書いたように、次のステップや、もっとお金を稼いでいくことへのチャンスを伺う、種を蒔いていく、足がかりにするような年にしたいなと思う。
チームの方が40歳で亡くなってしまうことがあったり、生前その人やマネージャーと話したときも、年齢的には珍しくないことだと言われていて、そんなことからも、ライフイベントも大事にして、日々よい振り返りができるようにしていきたい。